面向维吾尔语电话交谈式语音识别的词典设计方法研究
2013-12-14潘接林颜永红
李 鑫,侯 炜,计 哲,潘接林,颜永红
(1.中国科学院大学,北京100049;2.中国科学院声学研究所,北京100190;3.中国科学院语言声学与内容理解重点实验室,北京100190;4.国家计算机网络与信息安全管理中心,北京100029)
0 引言
语音识别技术的目标是将人的语音自动转换为文字。近年来,该技术不断进步,开始从实验室走向实用,出现了语音搜索服务、语音输入法、家电的语音控制及音频文件的关键词检测等应用。典型的基于统计的语音识别系统一般由特征提取模块、声学模型、语言模型、发音词典和解码器5个部分构成。其中,发音词典用于提供语言模型建模单元以及该单元对应的音素序列。在汉语或英语语音识别中,通常从文本语料中选择高频词语作为词典单元。
维吾尔语是一种黏着语,具有复杂的形态结构。在维吾尔语中,可以通过在词干后不断结合附加成分构成新的词语。如果从文本语料中选择高频词语构成词典,识别系统的集外词比例将远大于相同词典规模的英语系统。为了缓解黏着语语音识别中集外词过多的问题,通常选择分解词语得到的子词作为语言模型建模单元。近十年来,在黏着语一遍识别系统的开发中,围绕词语分解方法和子词单元选择出现了大量的研究。对于匈牙利语,Szarvas[1]等使用该语言的形态分析器将词语分解为语素,并采用这种语法语素作为识别单元。对于芬兰语,Hirsimäki[2]等采用最小描述长度准则对词语进行无监督切分,并使用切分得到的统计子词作为识别单元。对于韩语,Kwon[3]等实现了基于语素的识别系统,并通过基于规则或统计的语素合并来进一步提高系统性能。在土耳其语语音识别研究中,Hacioglu[4]等实现了基于语素和基于统计子词的识别系统,并根据互信息对相邻子词进行有选择的合并,从而增加子词语言模型的上下文长度;ArIsoy[5]等构造了同时包含词语、词干-词尾和语素的解码词典来发挥不同识别单元各自的优点;Sak[6]等通过将土耳其语形态分析器与识别系统的加权有限状态转录机进行复合来提高词典对文本的覆盖率。这些基于子词的识别系统缓解了词语系统集外词过多的问题,使识别器的性能得到了改善。
在维吾尔语形态分析研究方面,早克热·卡德尔[7]等实现了基于有限状态自动机的名词形态分析工具,可以将形态变化之后的名词分解为词干和附加成分;阿孜古丽·夏力甫[8]等采用同样的思路实现了处理动词体范畴形态变化的有限状态自动机。目前尚未出现可自由获得的完整的维吾尔语形态分析器,这给实现基于语素的语音识别系统带来了困难。在维吾尔语语音识别方面,Tursun[9]等建立了维吾尔语朗读语音数据库和文本语料库,并使用HTK实现了基于词语的语音识别系统,该工作还未涉及词典单元的选择问题。
Xerox Finite State Tools(XFST)[10]是一套有限状态工具包,提供创建和操作有限状态转录机的高级语言及编译环境。在本文中,我们使用该工具包开发了基于有限状态转录机的维吾尔语形态分析器,可用于将词语分解为词干和附加成分。赫尔辛基大学开发的基于最小描述长度准则的词语切分工具Morfessor 1.0[11]可用于将维吾尔语词语分解为统计子词。我们分别选择词语、语素和统计子词作为词典单元构建语音识别系统,并在电话交谈式语音转写任务上比较各个系统的性能。在此基础上,我们提出了一种根据词形在声学模型训练数据识别结果上的错误音素总数确定该词形最佳分解结果的方法。该方法可用于开发语素-统计子词联合词典,进一步提高识别器的性能。
1 维吾尔语的特点
维吾尔语是一种黏着语,可以通过不断在词干后结合附加成分构成新的词语。词干和附加成分统称为语素。附加成分按其作用可以分为构词附加成分和构形附加成分2类。构词附加成分表示词汇意义,结合在词干后能构成新词;构形附加成分只表示纯粹的语法意义,结合在词干后构成一个词的不同形态。构形附加成分结合在名词词干后可以表示数、领属人称和格的语法意义,结合在形容词词干后可以表示级的语法意义,结合在动词词干后可以表示式、体、时和人称的语法意义。表1给出了这2种附加成分与词干结合的例子。在本文中,我们使用拉丁维吾尔文字母拼写维吾尔语词语。

表1 词干结合不同种类附加成分构成词语的例子Tab.1 Examples of adding different kinds of suffixes to the stem
从表1中的例子可以看出,词干结合构词附加成分形成的词语类似于汉语或英语中的词语,而结合构形附加成分形成的词语则对应于汉语或英语中的词组。构形附加成分的存在是维吾尔语中出现大量不同词形的原因。我们统计不同规模的维吾尔语和英语电话谈话文本中出现的词形总数,得到的曲线如图1所示。从图1中可以看出,随着语料规模的扩大,维吾尔语文本中不同词形数目的增长速度明显超过英语。当文本规模达到2.13 M词语时,维吾尔语文本中包含的不同词形有212.3 K,远大于英语的22.4 K。
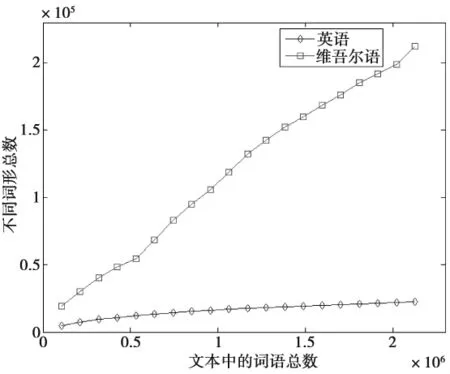
图1 维语和英语电话谈话文本中不同词形总数的比较Fig.1 Comparison of the word type number in Uyghur and English text corpus
在维吾尔语中,表示同一语法意义的构形附加成分一般具有多种变体。在词干结合附加成分的过程中,变体使用要遵循的规则包括元音和谐、辅音和谐和元音弱化。根据元音和谐规则,最后一个音节中带有前/后元音的词干要结合同一语法意义附加成分中带有前/后元音的变体,带有圆/展唇元音的词干要结合同一语法意义附加成分中带有圆/展唇元音的变体。根据辅音和谐规则,结尾是清/浊辅音的词干要结合同一语法意义附加成分中清/浊辅音开头的变体。根据元音弱化规则,词干结合附加成分后保持开音节或变为开音节时,最后一个音节中的a或e弱化为i。这些拼写规则使得词干结合附加成分时需要考虑连接边界的发音特点,增加了形态分析的难度。
2 维吾尔语词语分解
2.1 基于形态分析的词语分解
我们使用工具包XFST开发基于有限状态转录机的维吾尔语形态分析器,它的功能是将输入的词语分解为对应的词干和构形附加成分。为了构造该形态分析器,我们需要准备的知识包括:①词干和附加成分列表;②附加成分结合顺序;③词干结合附加成分时词语的拼写规则。我们的词干列表来自新疆师范大学的“现代维语语法语义词汇词性标记集”,共有词干97 934条,附加成分列表来自文献[12],共有附加成分225条。根据文献[12]的叙述,当名词发生形态变化时,附加成分的结合顺序是词干[数][领属人称][格];当形容词发生形态变化时,附加成分的结合顺序是词干[级];当动词发生形态变化时,附加成分的结合顺序是词干[能动-非能动][肯定-否定][体][时][人称]。我们用 XFST提供的高级语言lexc描述附加成分的结合顺序,并用工具包中的“read lexc”命令将源文件编译为有限状态转录机。词干结合附加成分时需要满足的拼写规则包括元音和谐、辅音和谐和元音弱化。我们用XFST提供的“替换规则”描述这些拼写规则,然后用工具包中的“define”和“read regex”命令将文件编译为有限状态转录机。在得到描述结合顺序和描述拼写规则的有限状态转录机之后,我们使用工具包提供的命令对它们进行复合操作,得到维吾尔语形态分析器。
图2给出了词语kitablirim(我的那些书)在形态分析器中对应的有限状态网络。在进行词语分解时,首先使用工具包中的“apply up”命令将kitablirim映射为词汇层上的语素序列kitab+Noun+Pl+P1sg,然后用命令“apply down”将该序列映射为表层上的语素序列 kitab +lir+im。“kitab”、“+lir”和“+im”可用作语素词典的词典单元。
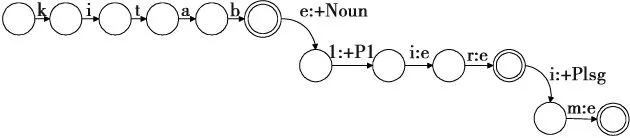
图2 形态分析器中kitablirim对应的有限状态转录机Fig.2 Finite state transducer for kitablirim in the morphological analyzer
2.2 基于统计的词语分解
Morfessor 是赫尔辛基大学开发的基于数据驱动的词语分解工具,最初用于芬兰语的统计形态分析。该工具使用最小描述长度准则对词语进行无监督切分,得到类似于词干和附加成分的统计子词。这一分解方法不需要语言学知识,只需要词形和它们在训练文本中出现的次数。我们使用该工具对维吾尔语词语进行基于统计的分解。例如,对于词语kitablirim(我的那些书),统计分解的结果是kitab+lirim。“kitab”、“+lirim”可用作统计子词词典的词典单元。
2.3 分解方法联合
基于形态分析的词语分解生成具有实际意义的词干和附加成分。附加成分一般长度较短,用作词典单元会增大解码时的混淆。基于统计的方法在词语分解过程中考虑了训练文本的1元语言模型概率,可以避免生成长度过短的子词。基于统计的词语分解不需要语言学知识,而基于形态分析的方法在分解过程中考虑了附加成分的结合顺序,生成的语素序列满足语法规则。为了利用不同识别单元各自的优势,我们设计同时包含语素和统计子词的联合词典。由于电话谈话领域的文本是通过人工标注电话交谈式语音得到,所以,文本中每个句子都有对应的语音文件。我们考虑根据声学模型训练数据的识别结果对每个词形选择最有助于提高系统性能的分解方法。我们分别选择语素和统计子词作为语言模型建模单元构建识别器,并对声学模型训练数据进行解码。对于训练数据中的每个句子,我们在音素级别将识别结果与标注对齐,使得二者间的编辑距离最小。由于维吾尔语中音素与字母存在一一对应的关系,所以词语对应的字母序列即为音素序列。我们使用(1)式统计词形W在整个训练数据上对应的错误音素总数L(W)。
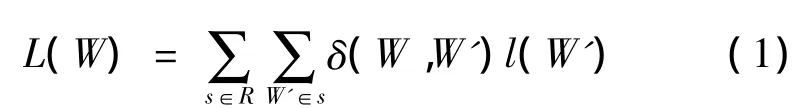
(1)式中:R表示声学模型训练数据对应的标注文本;s表示R中一条句子;W'是s中的词语;l(W')是W'对应的错误音素数目。当W与W'相同时,δ(W,W')的值为1;当W与W'不同时,δ(W,W')的值为0。对于词形W,在得到语素系统结果中的错误音素总数Lmorpheme(W)和统计子词系统结果中的错误音素总数Lstatistical(W)后,我们将L(W)较小的系统对应的方法用于W的分解,从而实现2种分解方法的联合。
3 声学模型和语言模型
我们使用200 h电话交谈式语音训练声学模型。声学特征选择39维感知线性预测系数(perceptual linear prediction,PLP),它是通过对52维系数(13维基本系数以及1阶、2阶、3阶差分)进行异方差线性判别分析后得到。声学模型采用基于决策树进行状态聚类的三音子模型,共包含6 964个隐马尔可夫模型状态,每个状态对应的高斯混合模型包含32个分量。声学模型参数通过最大似然估计得到。在比较不同词典单元对应的识别器性能时,我们使用相同的声学模型。用于训练语言模型的语料包括电话谈话语料和通用语料。其中,电话谈话语料是声学模型训练数据对应的标注文本,共包含35万条句子;通用语料来自小说、散文、报纸和网页,共包含139万条句子。对于不同的词典单元,我们使用SRILM工具包训练相应的3元语言模型。在构建语言模型时,首先,我们分别用标注文本和通用语料训练电话谈话领域的语言模型和通用语言模型,然后,通过线性插值的方法把它们合并为最终的语言模型。插值系数通过最小化电话谈话领域文本的困惑度得到。
4 实验结果和分析
4.1 不同词典单元对应的识别性能
在文献[13]中,Hain从文本中选择最频繁的55K词语作为英语电话交谈式语音识别系统的词表大小。我们将55K视为语音识别任务的典型词表大小。在第3节描述的电话谈话语料和通用语料中共有不同词形736K。我们使用第2节提到的方法对词语进行基于形态分析和基于统计的分解,得到语料的语素表示形式和统计子词表示形式。语素语料中共有不同单元491K,统计子词语料中共有不同单元279K。我们从词语文本中选择最高频的55K,150K和200K个单元构成词典,实现3套基于词语的识别系统;我们分别从语素文本和统计子词文本中选择55K个单元构成词典,实现基于语素和统计子词的识别系统各一套。表2给出了这些识别系统在1 h电话交谈式语音测试集上的集外词(out of vocabulary,OOV)比例和音素错误率。根据文献[14],对于词语系统,OOV指词典中未包含的词语在测试集里所占的比例;对于语素或统计子词系统,OOV指无法由词典中的单元连接而成的词语在测试集里所占的比例。根据文献[2],我们使用音素错误率作为评价识别器性能的指标。
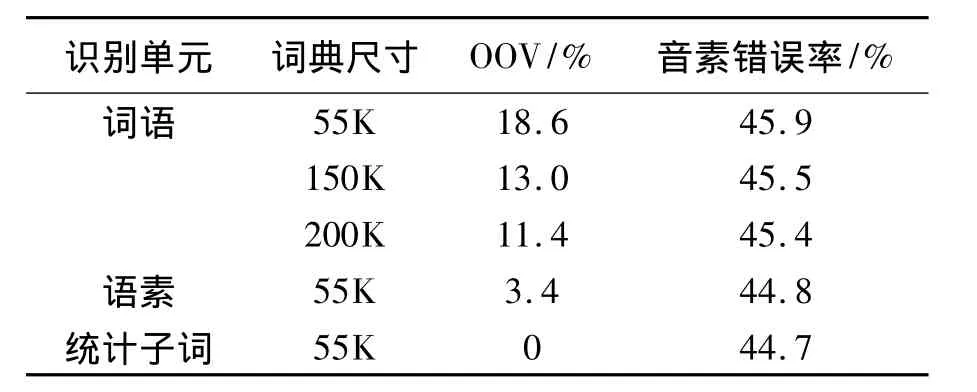
表2 不同词典单元对应的识别结果Tab.2 Experiment results of different lexicon units
对于词语系统,当词典大小从55K增加到150K时,测试集上的OOV从18.6%下降到13.0%,音素错误率从45.9%下降到45.5%。词典大小为200K的词语系统在测试集上的音素错误率为45.4%,与150K词语系统的结果没有显著差别。这些结果说明,在构建基于词语的维吾尔语语音识别系统时,适用于英语或汉语系统的典型词典大小不能充分覆盖测试语音。扩大词典规模可以降低词语系统的OOV,从而使音素错误率得到一定的降低。
当词典大小选择55K时,与词语系统相比,语素系统在测试集上获得了1.1%的音素错误率下降,统计子词系统获得了1.2%的音素错误率下降,这些结果均超过200K词语系统0.5%的音素错误率下降。语素系统和统计子词系统的识别结果之间没有显著差别。实验结果表明,与扩大词典规模相比,将词语分解为语素或统计子词能更有效地降低测试集上的OOV,提高系统的识别性能。
4.2 语素-统计子词联合系统的识别性能
我们用4.1中实现的语素系统和统计子词系统对声学模型训练数据进行解码,然后将识别结果与标注在音素级别对齐,使二者之间的编辑距离最小。我们使用(1)式计算声学模型训练数据中每种词形W在2套识别结果中的错误音素总数Lmorpheme(W)和Lstatistical(W)。声学模型训练数据中共包含不同词形212.3K,其中Lmorpheme(W)<Lstatistical(W)的词形有64.4K,Lstatistical(W)<Lmorpheme(W)的词形有63.3K,Lmorpheme(W)=Lstatistical(W)的词形有71.5K。对于识别结果中错误音素总数不同的词形我们选择L(W)较小的系统对应的分解结果;对于L(W)相同或声学模型训练数据中未出现的词形,我们既可以选择基于形态分析的分解结果,也可以选择基于统计的分解结果。我们对无法确定分解方法的词形分别使用基于形态分析的分解和基于统计的分解,实现2套词典大小为55K的语素-统计子词联合系统。我们在4.1中提到的测试集上进行实验,2套识别系统对应的实验结果如表3所示。
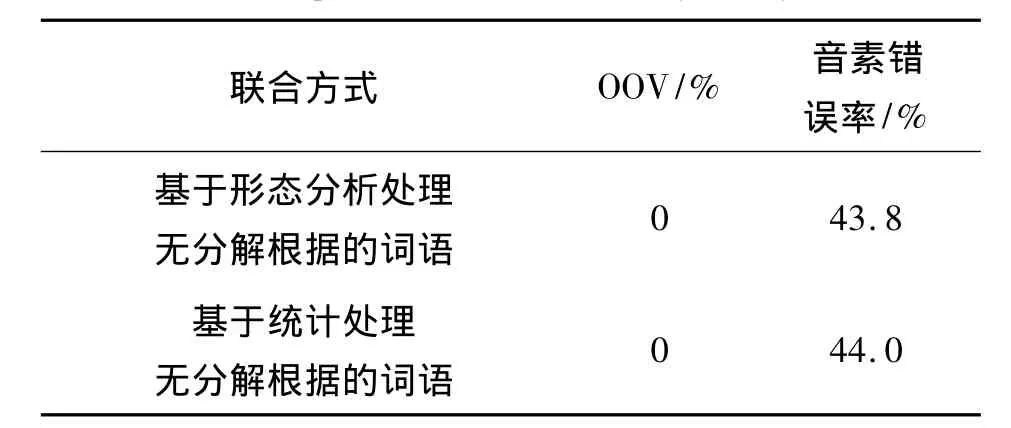
表3 语素-统计子词联合系统对应的识别结果Tab.3 Experiment results of the hybrid systems
从表3的结果可以看出,对没有分解根据的词形采用不同处理方式的系统之间识别结果无显著差别。与4.1中性能最好的统计子词系统相比,性能最好的语素-统计子词联合系统使测试集上的音素错误率从44.7%下降到43.8%。该结果表明,2.3节中的词典联合方法不但保持了语素词典和统计子词词典对测试集覆盖充分的优点,还挑选出了2部词典中最有利于识别性能提升的单元。
5 结束语
在本文中,首先介绍了维吾尔语的黏着性以及由此引发的词表大小无限扩张的问题。接着我们给出了基于形态分析和基于统计的词语分解方法,可以将词语分解为语素或统计子词。我们分别使用词语、语素和统计子词作为识别单元构建语音识别系统,在电话交谈式语音转写任务上对各系统的性能进行了比较。实验结果表明,语素或统计子词的运用缓解了词语系统集外词过多的问题。在词典大小为55K时,与词语系统相比,语素系统和统计子词系统分别获得了1.1%和1.2%的音素错误率降低。
语素系统与统计子词系统之间存在互补性。为了利用这2种系统各自的优势,我们提出了根据2种系统在声学模型训练数据上的音素错误率差别进行系统联合的方法。实验结果表明,联合词典不但保持了语素词典或统计子词词典对语料覆盖充分的特点,还降低了词典单元之间的混淆,从而使系统性能得到进一步的提高。在接下来的工作中,我们将进一步研究无法从解码结果中获得分解根据的词语的处理方法。
[1]SZARVAS M,FURUI S.Finite State Transducer based Modeling of Morphosyntax with Application to Hungarian LVCSR[C]//ICASSP 2003.[s.l.]:Conference Publications,2003:368-371.
[2]HIRSIMÄKI T,CREUTZ M,SIIVOLA V,et al.Unlimited Vocabulary Speech Recognition with Morph Language Models Applied to Finnish [J].Computer Speech and Language,2006,20(4):515-541.
[3]KWON O,PARK J.Korean Large Vocabulary Continuous Speech Recognition with Morpheme-based Recognition Units[J].Speech Communication,2003,39(3-4):287-300.
[4]HACIOGLU K,PELLOM B.On Lexicon Creation for Turkish LVCSR [C]//Eurospeech 2003.[s.l.]:Conference Publications,2003:1165-1168.
[5]ARISOY E,DUTˇAGACI H,ARSLAN L M.A Unified Language Model for Large Vocabulary Continuous Speech Recognition of Turkish [J].Signal Process,2006,86(10):2844-2862.
[6]SAK H,SARAÇLAR M,GÜNGÖR T.Morphology-based and Sub-word Language Modeling for Turkish Speech Recognition [C].//ICASSP 2010. [s.l.]:Conference Publications,2010:5402-5405.
[7]早克热·卡德尔,艾山·吾买尔,吐尔根·依布拉音,等.维吾尔语名词构形词缀有限状态自动机的构造[J]. 中文信息学报,2009,23(6):116-121.ZAOKERE K,AISHAN W,TUERGEN Y,et al.Uyghur Noun Inflectional Suffix DFA Generation[J].Journal of Chinese Information Processing,2009,23(6):116-121.
[8]阿孜古丽·夏力甫,早克热·卡德尔,吐尔根·依布拉音.维吾尔语动词体范畴的有限状态自动机的构建[J]. 中文信息学报,2012,26(4):61-65.ARZUGUL X,ZOKRE K,TURGHUN Y.Generating the Finite State Machines of Uyghur Verb Aspect Categories[J].Journal of Chinese Information Processing,2012,26(4):61-65.
[9]TURSUN N,SILAMU W.Large Vocabulary Continuous Speech Recognition in Uyghur:Data Preparation and Experimental Results[C]//ISCSLP 2008.[s.l.]:Conference Publications,2008:1-4.
[10]BEESLEY K R,KARTTUNEN L.Finite State Morphology[M].Stanford,CA,USA:CSLI Publications,2003.
[11]CREUTZ M,LAGUS K.Unsupervised Morpheme Segmentation and Morphology Induction from Text Corpora U-sing Morfessor 1.0[M].Helsinki University of Technology:Publications in Computer and Information Science,2005.
[12]易坤琇,高士杰.维吾尔语语法[M].北京:中央民族大学出版社,1998.
[13]HAIN T,WOODLAND P C,EVERMANN G,et al.Automatic Transcription of Conversational Telephone Speech[J].IEEE Trans on Acoustics,Speech,and Signal Processing,2005,13(6):1173-1185.
[14]ARISOY E,CAN D,PARLAK S,et al.Turkish Broadcast News Transcription and Retrieval[J].IEEE Trans on Acoustics,Speech,and Signal Processing,2009,17(5):874-883.
