KD-90普及型个人高性能计算机系统设计与性能优化
2013-11-26罗秋明陈国良
蔡 晔,刘 刚,毛 睿,罗秋明,陈国良
深圳大学国家高性能中心深圳分中心,深圳大学计算机与软件学院,深圳518060
高性能计算机是衡量国家综合国力的重要标志之一,是国家信息化建设的根本保证.目前世界上最快的机器为美国能源部的“红杉”[1-2],峰值性能20 132万亿次,Linpack实测性能为16 324万亿次/秒.中国高端高性能计算机的计算能力已达到千万亿次量级的世界先进水平.主要代表有“天河-1A”[3],峰值性能达 4 700万亿次/秒,Linpack实测性能达2 566万亿次/秒;以及曙光 “星云”[4],其峰值性能达1 296万亿次/秒,Linpack实测性能达749万亿次/秒.采用国产处理器的高性能计算机系统也达到了较高水平,典型代表为“神威蓝光”[5],采用了国产申威1 600处理器,峰值计算
1 KD-90系统组成与结构
速度达1 070万亿次/秒浮点计算,Linpack实测性能为796万亿次/秒.千万亿次以上的高端高性能计算机主要为国家战略服务,但这种昂贵的计算资源集中部署的模式,以及建设和运营维护的成本都不利于高性能计算的普及与推广.
深圳大学国家高性能计算中心深圳分中心主要研制计算规模达万亿次的普及型个人高性能计算机(popular high ferformance computer,PHPC)[6]系统,坚持走高性能计算机普及化和服务于我国经济建设自主创新之路.该中心与其合作单位联合研制了一系列高性能计算机及推广应用型号[11],包括KD-50、KD-60、SD-1、SD-2 和KD-90 等[7-10],目标是逐渐把万亿次高性能计算带到个人和桌面,实现高性能计算的普及运用.国外类似研究主要有美国纽约州立大学石溪分校基于量子器件研制的PeT(personal teraflops computer)桌面万亿次机、Ohio Supercomputer Center[12]的蓝领计算和NVIDA 的Telsa[13]等个人超级计算机.
本文报道了国产PHPC研究的最新进展KD-90万亿次机的设计和相关性能优化工作.KD-90整体采用了SMP→CC-NUMA→Cluster 3级并行体系结构,其技术创新点是:① 采用高密度组装技术,在微波炉大小的空间内实现了万亿次高性能计算机系统的结构设计,是一款真正意义上的移动个人高性能计算机;②计算核心采用国产龙芯3B 8核处理器,应用矢量部件加速技术搭建了一种通用处理器与向量协处理器相结合的编程模型,并结合体系结构特点来优化系统;③采用通用协议与专用协议结合的互连网络硬件设计,实现了CC-NUMA机群架构关键技术的突破.
KD-90系统由5个计算节点、1个系统背板、1个前置龙芯服务器及1个定制机箱组成.计算节点采用双路CC-NUMA结构,5个计算节点总计集成10个以龙芯3B 8核处理器为核心的处理单元,当处理器工作主频为800 MHz时,峰值计算能力可达万亿次(1 Tflops);背板上集成了自主研发的超多端口千兆以太网交换芯片(hyper-multiport gigabit ethernet switch,HMGES),实现计算节点之间、计算节点与前置服务器之间的互连,及基于远程web的带外监控管理系统;前置服务器也采用龙芯3B处理器设计,提供系统引导、磁盘存储、用户登录及任务调度等功能;所有组件都集成在一个445 mm×465 mm×580 mm的微波炉大小的定制机箱内.KD-90机箱结构见图1.

图1 KD-90机箱结构Fig.1 The Chassis structure of KD-90
龙芯3B在体系结构设计时,为减少片上互连复杂性,内部8核设计采用2个4核SMP节点在片上互连的方式,SMP节点共享一个本地存储器,并通过内部互连访问另一节点的存储器,因此龙芯3B是一个典型的片上CC-NUMA系统.如图2,为满足芯片内8个处理器核心的通讯需求,每个处理器(PE1~PE10)都有4路千兆串行通讯链路与背板连接,同一计算节点内的两个处理器同时还通过HT(HyperTransport)总线直接在主板上互连,该方法可用于节点内部的互连优化,或配置成一个16核的两级CC-NUMA结构.因此,系统整体是一个SMP→CC-NUMA→Cluster 3级并行体系结构,其中SMP和CC-NUMA这两个并行层次在芯片内部实现,CC-NUMA集群在系统级实现.

图2 KD-90系统结构与组成Fig.2 The architecture of KD-90 PHPC system
2 KD-90系统设计
2.1 计算节点设计
KD-90的计算节点采用双路8核CC-NUMA结构,如图3.计算节点在一块电路板上设计集成2个结构相同的龙芯3B 8核处理器单元和1个监控单元.处理单元由龙芯3B 8核处理器、北桥芯片、I/O Hub芯片和2个双路串行千兆以太网Serdes控制器等组成.每个处理单元用1片龙芯3B处理器实现1个双节点的非均匀访存多处理器系统(CCNUMA)结构,支持32 Gbit DDR3内存,以串口作为显示和调试终端.计算结点内两个处理单元通过HT总线互连通道进行内部互连,结点外通过千兆通信链路连接到系统互连交换机,从而与其他计算节点一起构成一个CC-NUMA集群结构.

图3 KD-90计算节点结构Fig.3 The computing node architecture of KD-90
2.2 系统互连
互连系统采用自主研发的超多端口千兆以太网交换(hyper-multiport gigabit ethernet switch,HMGES)芯片.该芯片基于FPGA,具有以下特点:
1)通用协议与专用协议结合的互连网络硬件设计.这种设计支持两套联络层协议,一套完全兼容802.3规范中定义的MAC层协议;另一套多虚通(virtual channel)链路协议.每个虚通道在交换芯片内部的接收端和发送端都有专用缓冲区.利用多个虚通道,可减少队头阻塞,提高系统吞吐率.
2)虚切入交换(virtual cut-through switching).HMGES采用虚切入的交换方式,所得交换延迟极低,性能可达到单级交换延迟不大于200 ns.
3)支持栅障(barrier).HMGES利用专用硬件模块来支持barrier操作,其交换机芯片内部有专门用于barrier操作的虚通道,用户将barrier消息包发送到该通道,然后从该通道获得执行完毕的消息.
4)FPGA预留与龙芯3B处理器的HT互连接口,未来可通过扩展实现更高层次MPP级别的互连.
2.3 监控管理系统
为保证KD-90系统的可靠性以及系统状态监视,设计一种基于远程web界面的监控管理系统,由独立的电源供电.监控系统由位于底板上的监控单元和分布在各处理板上的监控电路组成(图4).

图4 KD-90监控管理系统Fig.4 The monitor and management circuit of KD-90
3 KD-90系统性能优化
Linpack是基于双精度计算求解稠密线性方程组Ax=b来衡量计算机浮点计算性能的基准测试软件.该软件现有3个版本:Linpack n=100求解规模为100阶的方程组;Linpack n=1 000求解规模为1 000的方程组;HPL(high performance Linpack)求解任意规模的线性代数方程组.HPL是当前Top500高性能计算机测评的重要标准.
为提高KD-90系统的Linpack性能,可从龙芯3B体系结构特点和操作系统内核两方面来优化KD-90系统性能.
3.1 基于龙芯3B体系结构的GotoBLAS库优化
HPL测试的主要运算是通过调用BLAS库的基本函数来实现的,结合龙芯3B体系结构特点对所用的GotoBLAS库进行优化.
3.1.1 向量化
龙芯3B处理器提供一组256 bit的向量浮点寄存器堆及一组针对这一寄存器堆的向量计算与访存指令,使用这些指令中向量乘加指令、128 bit访存指令与256 bit寄存器堆可实现对矩阵的向量化.
1)向量乘加指令.在支持乘加操作的龙芯3B处理器上,可把分开的乘法和加法指令合并成乘加操作,以减少指令数.使用向量乘加指令可将原有的乘法和加法计算指令减至1/8.
2)128 bit向量访存指令.通过使用128 bit访存指令,将普通的64 bit访存指令替换为128 bit访存指令,可减少50%数目的load和store指令,加快数据存取和拷贝速度.另外还可减少正常访存指令数,空出指令槽发射预取指令,减少L1cache的缺失,从而带来更大的性能提升.
3.1.2 循环展开
通过使用128 bit访存指令,在L1cache命中的情况平均每个周期可读取2个双精度型数据(8 bit).4发射的流水线中有2个支持乘加指令的浮点部件,即平均每个周期可做2个乘加操作,此时访存成了性能提升的瓶颈,解决办法是通过循环展开使每次读取的数据进行尽可能多次的运算.
HPL最主要的矩阵乘法子函数DGEMM(C=C+AB)的基本操作是,每次读取1行A和1列B以求出对应位置的C值,在这种情况下每次读取1个A值和1个B值做1次乘加运算,效率很低.改进后的做法是:内循环每轮同时读取2行A和2列B并计算12×12的C,即每次读取24个A值和24个B值进行12×12×2/4=72次向量乘加运算.读取24个A值和24个B值用时24个时钟周期,72次乘加运算耗时36个时钟周期.系统中36个向量寄存器用来存储C值,24个寄存器分两组,每组12个,用来存储A值和B值(每组中A和B都有6个),第1组取数后运算,运算同时第2组取数,随之运算,运算同时第1组又取数,两组寄存器如此轮流交替,以解决写后读的数据相关性.按此方法操作,运算时间可掩盖读取下一组A和B的时间,因此在cache命中的情况下流水线不会停顿,效率近100%.
3.1.3 指令调度
指令调度可通过调节指令次序减少流水线等待时间.在传统的单流水线处理器上,指令调度的主要工作是尽量在具有数据相关的指令间插入其他无关指令来避免流水线空转.
龙芯3号多发射和无序执行的特性使指令调度变得复杂.测试发现,有时即使是调整两条无数据相关指令的次序,也会严重影响整个流水线的运行.根据龙芯3号上4发射的特点,如果定点指令不足,可用空操作nop(在龙芯3号上nop被视为定点操作)填充,在每条取数指令后面跟着两条浮点运算指令和1条定点指令,可使4发射的流水线严格按照理想情况(每个周期发射1条取数指令、1条定点指令和2条浮点指令)来发射指令,尽量提高系统的IPC(instructions per cycle).
3.1.4 数据预取技术
利用龙芯3B系列提供的cache锁机制将一块连续地址锁在2/3级cache中,通过配置转置模块的寄存器并利用外部DMA可以实现从内存到L2cache的预取;利用其提供的4个向量DMA通道,可实现数据从2/3级cache和内存到浮点寄存器堆的读写操作,其具体实现过程为:
由于每个节点仅有1个转置模块,所以根据DGEMM函数访存的特点,在计算当前C0+=A0B0的同时,将下次用到的数据A1通过转置模块预取到被锁住的连续地址空间中,将C1通过一个向量读通道从内存直接预取到一组浮点寄存器堆中,而在下次计算C1+=A1B1前,需用拷贝函数将B1拷贝到被锁住的连续地址空间中,计算C1的同时通过DMA写通道将C0写回内存(行主序的话预取B1而拷贝A1);计算时,每次都是取1列A和1行B到1组浮点寄存器中进行计算,而在计算的同时将下一列A和下一行B通过另外两个DMA读通道从锁住的L2cache中预取到下一组浮点寄存器中.
3.2 操作系统设计及优化
KD-90操作系统设计及优化主要包括:
1)基于龙芯3号8核处理器,实现了维护全局cache一致性的CC-NUMA多核操作系统.操作系统在为应用程序分配内存时,优先从处理器亲和性强的本地存储器中分配,使访问其他节点存储器的几率大大降低,提高了系统效率.一则减少了并行程序的访存冲突,另则提高了数据访问的局部性,降低程序访存延迟,优化了系统性能.
2)基于CC-NUMA系统,优化了节点间的距离矩阵,提高了本地节点内存访问的命中率,减少了远端节点内存访问的次数,实现节点间内存访问次数的均衡.
3)实现了大块连续物理内存的申请.传统的内存分配函数,只能保证虚拟地址连续,无法保证物理地址连续,尤其在需要大块连续物理内存时,传统的内存分配函数无能为力.通过在操作系统启动时保留一块物理内存,同时在操作系统中添加一个修改页表的函数,完成用户地址和保留的物理内存地址之间映射关系的建立,最终实现了用户态的内存分配函数,可申请到大块连续的物理内存.
4)二级cache锁策略.通过把数据和指令锁到cache,降低了cache缺失率,从而提高了应用程序的性能.为提高Linpack性能,提升cache命中率,把需频繁访问的数据矩阵锁到二级cache,使该数据不会被替换出二级cache,直到整个程序运行结束.当二级cache收到DMA写请求时,若被写区域在二级cache中命中且被锁住,则DMA写将直接更新列到二级cache而非内存.对于DMA设备来说,使用锁cache机制把缓冲区锁到二级cache,可提高输入/输出(input/output,IO)访问性能.
5)利用大页降低TLB失效率.Linux内核保留出大约6 Gbyte的内存空间存放Linpack程序中的大量数据,应用程序通过调用重映射操作将程序映射到此空间中.系统将该空间做16 Mbyte的大页面映射,以此降低Linpack中相关操作的TLB失效率,提高Linpack的性能.16 Mbyte的大页为龙芯处理器TLB可映射的最大页面,而系统页大小通常为16 kbyte,因此16 Mbyte的页映射可大大降低TLB失效率.
4 性能评估
4.1 互连性能
采用PMB 2.2软件测试MPI系统的全局性能,分别对不同规模的计算节点进行测试.测试16 384 byte的SendRecv以及 Allreduce、Reduce、Allgather、Allgatherv、Alltoall、Bcast和Barrier的函数性能,得到相应规模的带宽或延迟.其中,Allreduce函数通过带宽来评估性能,其他函数通过延迟来评估性能.
表1给出在8处理单元时,KD-90定制互连系统(HMGES)工作在以太网协议兼容模式时,与KD-60采用的商用千兆以太网络的互连性能对比.
由表1可知,设计定制的互连系统(HMGES)的MPI全局性能表现优越,与KD-60系统采用的商用千兆以太网络相比较,16 384 bit的SendRecv带宽增加了 2.29倍.Allreduce、Reduce、Allgather、Allgatherv、Alltoall、Bcast和Barrier函数的延迟最多降低74.2%,最少降低50.8%.

表1 HMGES和千兆互连网络的性能对比Table1 Performance comparison of HMGES and GE
4.2 Linpack性能
测试单处理器在8 Gbyte内存,DDR3内存主频为466 MHz,CPU主频为800 MHz条件下,采用相关优化方法取得的Linpack性能数据如表2.
由表2可知,采用体系结构的优化方法后效果明显,单核 Linpack效率提升30%,单处理器(CC-NUMA节点)Linpack效率提升28%.在此基础上,优化操作系统可进一步将Linpack效率提升4%~5%.数据表明,单处理器和单核之间Linpack效率相差10%,说明处理器内部CC-NUMA结构对Linpack的性能有一定影响,操作系统内存管理的优化空间还较大.

表2 优化方法性能评测Table2 Performance evaluation of optimization methods
表3给出KD-90整机在目前阶段性工作取得的Linpack性能测试结果.由表3可见,在矩阵大小为107 520时,Linpack测试性能最佳,达25.99%.
目前整机Linpack效率尚未达到理想目标,一般整机效率只比单节点低约10%(如KD-50和KD-60),但在实际应用中,低于30%,表明国产处理器在软硬件协同优化中还有很多工作要做.下一步我们将继续深入优化,使Linpack效率有望达50%左右.主要优化方法包括:每个CPU可使用网络接口数由1个增至4个;将中断平衡分布到4个核,提高I/O处理效率;进一步提高单节点Linpack性能,如系统内存可使用64 kbyte大页,寻求新的DGEMM(矩阵乘)算法及每个CPU可使用更大的内存等.
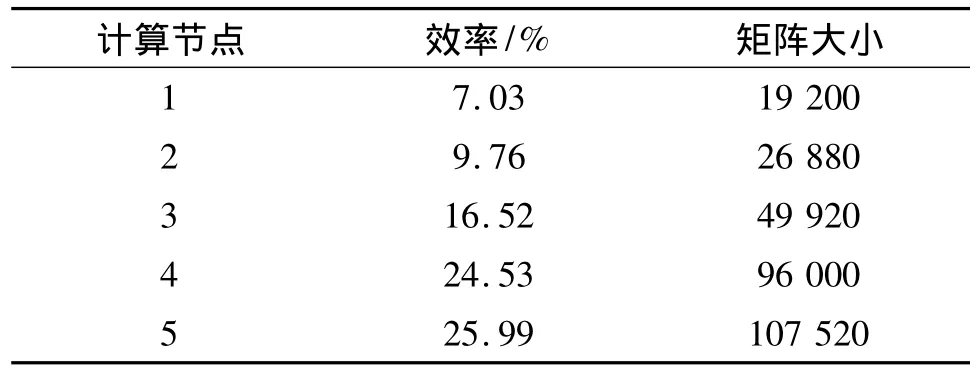
表3 整机Linpack性能Table3 System Linpack performance
结 语
KD-90的系统硬件具有完全自主知识产权,采用CC-NUMA机群架构及高密度组装技术,在单一机箱中集成了系统全部的功能部件.其中,前置服务器和计算节点均采用了中国自主设计的龙芯3B 8核处理器;主要互连部件采用了自主研发的面向高性能计算的超多端口千兆以太网交换芯片.整机运行功耗低于900 W,体积为0.12 m3,与微波炉相仿,实现了高能效、可移动的桌面高性能计算.
KD-90的成功研制提高了国产高性能计算机领域的自主创新能力,推动了龙芯系列处理器在高性能计算领域和服务器市场的应用,在KD系列高性能计算机的研制中实现了桌面化应用.
/References:
[1]Dong C,Noel A E,Heidelberger P,et al.The IBM blue Gene/Q interconnection fabric [J].IEEE Micro,2012,32(1):32-43.
[2]Haring R A,Ohmacht M,Fox T W,et al.The IBM blue Gene/Q compute chip [J].IEEE Micro,2012,32(2):48-60.
[3]Yang Xuejun,Liao Xiangke,Song Junqiang,et al.The TianHe-1A supercomputer:its hardware and software[J].Journal of Computer Science and Technology,2011,26(3):344-351.
[4]Sun Ninghui,Xing Jing,Huo Zhigang,et al.Dawning nebulae:a petaflops supereomputer with a heterogeneous structure[J].Journal of Computer Science and Technology,201l,26(3):352-362.
[5]Zhang Yunquan,Sun Jiachang,Yuan Guoxing,et al.China HPC 2011:State of the Art Analysis and Perspective[J].E-Science Technology&Application,2012,3(1):89-96.(in Chinese)张云泉,孙家昶,袁国兴,等.2011年中国高性能计算机发展现状分析与展望[J].科研信息化技术与应用,2012,3(1):89-96.
[6]Sun Ninghui,Chen Guoliang.PHPC:a spreading kind of high performance computer[J].Journal of University of Science and Technology of China,2008,38(7):745-752.(in Chinese)孙凝晖,陈国良.PHPC:一种普及型高性能计算机[J].中国科学技术大学学报,2008,38(7):745-752.
[7]Zhang Junxia,Zhang Huanjie,Li Huiming.Design of tera flops high performance computer KD-50-I based on Loongson 2F CPU [J].Journal of University of Science and Technology of China,2008,38(1):105-108.(in Chinese)张俊霞,张焕杰,李会民.基于龙芯2F的国产万亿次高性能计算机KD-50-I的研制 [J].中国科学技术大学学报,2008,38(1):105-108.
[8]Zhang Junxia,Li Chunshen,Zhang Huanjie.KD-50-IE:an enhanced high performance computer[J].Journal of University of Science and Technology of China,2009,39(8):894-896.(in Chinese)张俊霞,李春生,张焕杰,等.KD-50-I-E:一台增强型高性能计算机 [J].中国科学技术大学学报,2009,39(8):894-896.
[9]Gu Naijie,Li Kai,Chen Guoliang,et al.Optimization of BLAS based on Loongson 2F architecture[J].Journal of University of Science and Technology of China,2008,38(7):854-859.(in Chinese)顾乃杰,李 凯,陈国良,等.基于龙芯2F体系结构的BLAS库优化 [J].中国科学技术大学学报,2008,38(7):854-859.
[10]Wu Chao,Sun Guangzhong,Chen Guoliang,et al.Linpack benchmark test on KD-50-I high performance computer[C]//The International Symposium on Parallel Architectures,Algorithms and Programming.Hefei(China):IEEE Press,2008:177-188.
[11]Chen Guoliang,Cai Ye,Luo Qiuming.Optimization of BLAS based on Loongson 2F architecture[J].Journal of Shenzhen University Science and Engineering,2011,28(6):471-477.(in Chinese)陈国良,蔡 晔,罗秋明.国产个人高性能计算机系统研制[J].深圳大学学报理工版,2011,28(6):471-477.
[12]Ohio Supercomputer Center.Blue collar computing [EB/OL](2004-07-01)[2004-09-01].http://www.osc.edu/bluecollarcomputing/.
[13]Cray Inc.Cray CX1 Tesla GPU Computing Blade [EB/OL](2009-01-01)[2009-03-01].http://www.cray.com/Assets/PDF/products/cx1/CX1.
