基于APRIORI算法和OLAP的关联规则对图书信息分类模型的设计
2013-11-20毛敬玉
毛 敬 玉
(兰州职业技术学院,甘肃 兰州 730070)
1 APRIORI算法和OLAP
数据挖掘是近年来研究数据库领域的热点之一。在众多数据挖掘方法中,关联规则是数据挖掘中的重要研究对象。它最典型的应用就是在大量的数据库信息中发现新的有用的信息。APRIORI算法是一种使用很广泛的挖掘布尔关联规则频繁项集的算法,是关联规则挖掘算法中的经典算法之一。它的基本思想是:首先找出所有的项集,这些项集出现的频繁性至少要与预定义的最小支持度一致。然后由这些频集生成强关联规则,这些规则必须满足最小支持度与最小可信度。然后使用第1步找到的项集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则在右部只有一项,这里采用的是中规则的定义。一旦这些规则被生成,那么只有那些大于用户所给定的最小可信度的规则才会被留下来。为了生成所有频繁项集,使用了递归的方法。 程序如下:
algorithm apriori(T)
C1←init-pass(T)
while (k=2;Fk-1≠¢;k++)do
Ck←candidate-gen(Fk-1)
while each transaction t∈T do
while each condidate c∈Ck do
if c is contained int
then c.count++
end if
end while
end while
end while
return F←UkFk
OLAP联机分析处理技术是目前数据仓库中数据多维分析的使用最多的验证型工具。OLAP系统采用数据存储方案为物化数据立方体,以空间代价来换取时间效率。对关联规则挖掘来说,挖掘过程中大量所需的中间数据已经被物化在数据立方体中而无需重新计算,由此可以节约大量的数据挖掘时间。
图书行业在其发展过程中,积累了大量的各种图书的流通信息,以往的信息管理系统缺少寻找大量数据间的有用的、隐含的和潜在的信息能力,如何有效利用APRIPRI算法和OLAP关联规则,从海量的数据中挖掘出有实用价值的信息,并在图书管理过程中将其转化为效益,是图书管理者们的急迫任务之一。本文将根据APRIORI算法的特点对OLAP数据立方体维度、度量值等方面设计进行充分考虑,设计出能高效地为关联规则挖掘程序提供更多的中间数据,以此为基石,通过现存的图书关系数据库和实际的图书信息数据,生成数据立方体并进行关联规则的挖掘。

2 APRIORI算法在图书系统数据挖掘中的应用
随着专业的不断分支发展,人们对于专业学习的不断深入和细化,图书在图书营销或图书馆建设过程中都积累了大量的图书信息数据,并且这个数据与日俱增。如何处理和如何深入其内部获取有用的信息,研究人员进行了大量的探索,而人们也不再只停留在对数据的简单操作上转而开始思考和探索如何从海量的数据中提取藏在数据背后的、潜在的知识或信息为最终的决策提供有力的数据支持。例如图书馆藏书的分类整理、图书市场的运营管理决策、电子图书馆建设过程中对于图书的选择等等。
我们可以按图2流程来进行:

2.1 OLAP引擎和数据立方体
从图1我们可以看出,OLAP引擎和数据立方体是不同的两个模块,但是两者的关系很密切。数据立方体为OLAP引擎提供数据存储,OLAP引擎为数据立方体提供I/O接口操作和其他数据立方体操作。
2.2 维度表和事实表的设计
在整个数据挖掘过程中,需要用到事实表和维度表。事实表是数据仓库架构中的中央表,它包含连接事实与维度表之间的数字度量值和关键字。事实数据表包含描述运作过程中特定事件的数据。维度表可以是用户用来分析数据的窗口。维度表中包含事实数据表中事实记录的特性,有些提供描述性特性信息,有些指定如何汇总事实数据表特性数据,以便提供有用的信息给分析者,维度表包含帮助汇总数据的特性的层次结构。
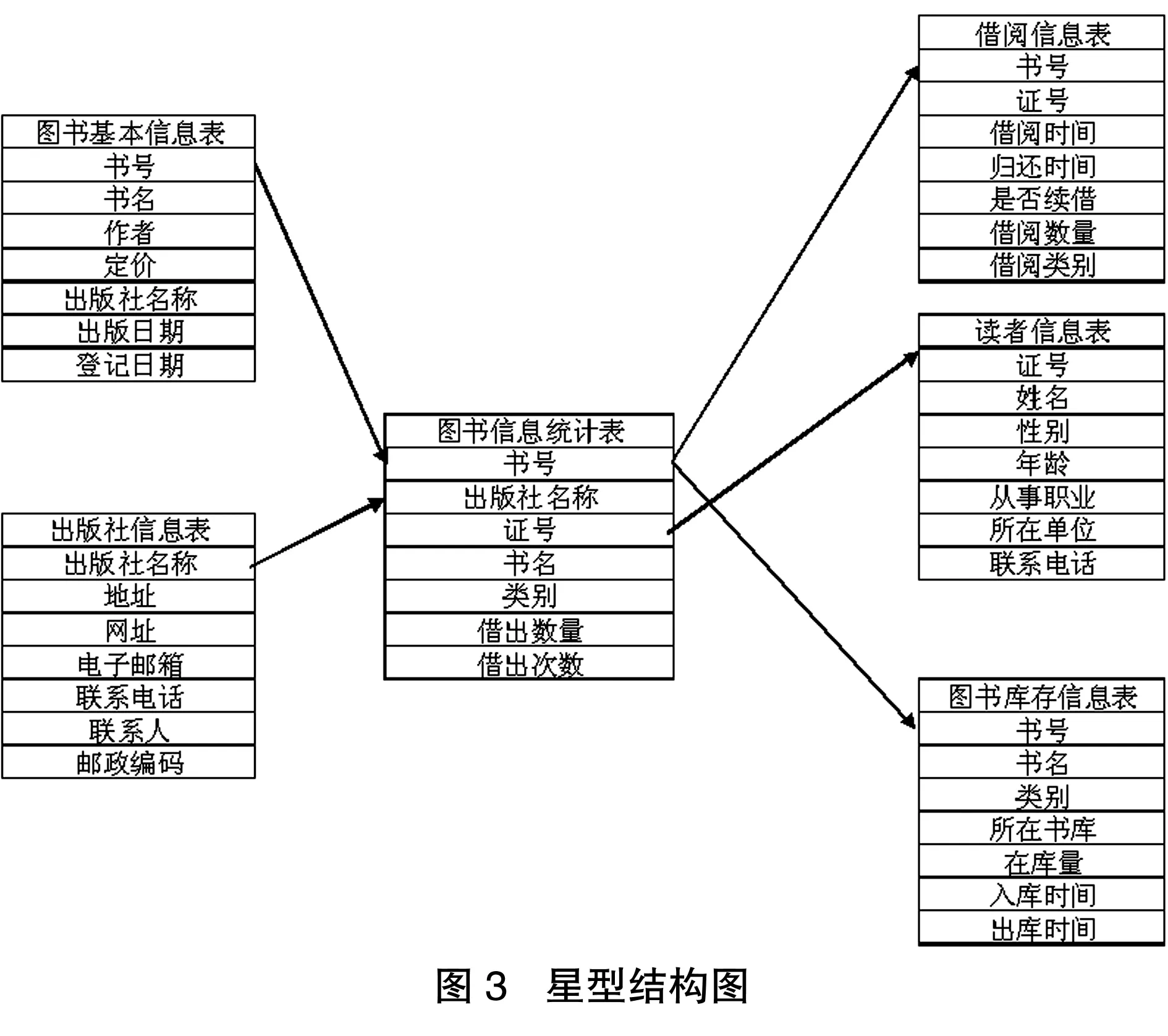
我们给每一个信息表建立一张对应的维度表,为了避免重复,我们需要给这些维度表重新用一个序号来标识,同时建立一张事实表,以各维度表的主关键字为关键字,并建立一个事实表的关键字序号,形成一个相应的星型结构,如图3所示。
以图书馆管理为例,我们需要用到的主要的数据表有以下内容:

图书基本信息表书号书名作者定价出版社名称出版日期登记日期图书库存信息表书号书名类别所存书库在库量入库时间出库时间出版社信息出版社名称地址网址电子邮箱联系电话联系人邮政编码借阅信息表书号证号借阅时间归还日期是否续借借阅数量借阅类别读者基本信息表证号姓名性别年龄从事职业所在单位联系电话
这些表格产生的维度表构成的星型结构图如下:
APRIORI算法存在以下两个比较明显的缺陷。首先,有可能产生大量的候选集;其次,需要重复扫描数据仓库中的数据,在挖掘过程中会因迭代产生候选项集用来统计其支持度而花费大量的时间。为了节约运算时间,我们需要将算法加以改进来提高效率,改进的算法描述如下:
任何长度为k的事务都不可能包含(k+1)-项子集。对原始事务数据库中的每一个事务进行第一次扫描并计数后,立即删除长度为1的当前事务,因为该事务不会对后面的频繁2-项集的生成起作用,所以以后的操作不再需要该事务了。在进行第二次扫描并对2-项集计数之后,立即删除长度为2的事务。这样,第二遍扫描的事务数据库就被压缩了,从而提高了算法的效率。该方法可以应用到以后的每一趟扫描中,即在对候选k-项集计数之后,立即删除长度为k的事务。
procedure apriori-whb(Lk-l,min-sup)
forall items l1∈Lk-l
forall items l2∈Lk-l
if ((l1[1]=l2[1])∧...∧(l1[k-2]=l2[k-2])∧l1[k-1] C=l1⨁l2 //连接两个项集 if has-infrequent-item set(C,Lk-l) delete C else Ck=Ck∨{C} end if Dk=whb-del(Dk-l,Lk-l)//删除不满足条件项集,减少下次扫描DB的记录次数 end if return Ck procedure whb-del(Lk-l,Dk-l) forall items l1∈Dk-l if |l1| end if if l1≮Lk-l then delete l1 end if return Dk procedure has-infrequent-sub set(C,Lk-l) forall (K-1)subset s of C if s¢Lk-l then return true else return false end if L1={large l-itemsets}//D中的L项集 for(k=2;Lk-l≠⟩;k++)do begin Ck=apriori-gen(Lk-l,minsup) forall transaction t∈D do begin Ct=subset(Ck,t)//t所包含的候选项集 forall candidate c∈Ct do c.count++ end Lk={c∈Ck|c.count≥minsup} end answer=UkLk 本文主要介绍了基于APRIORI算法和OLAP的关联规则对图书信息分类模型的设计,为图书馆或者学校图书管理提供了很好的技术支持,使图书管理和图书分类变得越来越简单,越来越方便。 参考文献: [1][美]陈封能,斯坦巴赫,库玛尔.数据挖掘导论[M].北京:人民邮电出版社,2011. [2]董琳.数据挖掘实用机器学习技术[M].北京:机械工业出版社,2006. [3]林杰斌.数据挖掘与OLAP理论与实务[M].北京:清华大学出版社,2003. [4]何玉洁,张俊超.数据仓库与OLAP实践教程[M].北京:清华大学出版社,2008.3 结语
