基于多传感器视听融合的三维目标跟踪
2013-10-22刘丽娟刘国栋
刘丽娟,刘国栋
(江南大学物联网工程学院,江苏无锡 214122)
0 引言
由于现在不断增长的安全需求,目标跟踪的研究日益受到重视。目前的跟踪技术主要是利用完全基于声音或视觉传感器,音频定位具有精度差而覆盖面广的特点,视觉跟踪具有定位精度高而受摄录角度限制的特点,以至于在复杂环境下难以取得理想的跟踪效果。这时由2只或多只传感器获得的信息相结合有更大的优势。
德国Erlnagne Nurem berg大学远程通信实验室在实验中采用卡尔曼滤波来融合音频和视频信息,在一个模拟铁道上得到的跟踪结果好于单独使用音频或视频信息的跟踪[1]。但是由于其假设的线性动力学和一个单峰高斯后验概率密度,卡尔曼融合法受到了严重的限制。瑞士DalleMolel感知人工智能研究所Daniel Gatica-perez等人进一步考虑了音频信息和视频信息的差异,提出了采用重要性函数粒子滤波器(ISPF)进行音频信息和视频信息的融合[2]。这种方法改善了跟踪效果,但增加了计算成本,降低了系统的速度。由美国微软研究院的Mahttew J Beal等人提出的融合方法[3],采用隐变量概率图的方式来分别描述音频信息和视频信息,根据贝叶斯(Bayes)准则,采用EM算法来取得最大后验概率,并同时得到人物的位置估计。虽然,贝叶斯方法的原理非常简单,功能强大,其在实践中的主要缺点是计算量大,主要用于执行在一个非常高维空间的随机变量。
本文在这些研究的基础上,提出了一种利用音频和视频信息在三维空间直接跟踪目标的新方法,音频和视觉信息利用TRIBES算法以一种新的方式融合[4],这种方法比现有的方法具有更快、更精确的跟踪性能。
1 基于GCC PHAT的声源定位
声源定位系统目的是提供表示系统原点和被跟踪对象相对角的方位角φ。假设一个单一的声源与消声平面波在低不相关噪声和低回响情况下传播。这个波被距离为b的2个麦克风收集。麦克风信号x1(t)和x2(t)可表示为[5]

其中,T为时间,s(t)为被定位的信号源,TTDOA为2只传感器之间的延迟,n1(t),n2(t)为假设不相关噪声信号和广义平稳过程,延迟T可以通过计算广义互相关函数(GCC)Rx1x2(T)来估计,Rx1x2(T)由下式信号的交叉功率谱密度的傅立叶逆变换给出,即

式中A(ω)为一个过滤函数,假设观测时间是无限制的,T再次表示频域的信号X1(ω)和时X2(ω)之间的延迟。将A(ω)进行相位变换(PHAT)如下

该滤波器的功能是使GCC更加适合检测狭窄频带信号和增强抗混响。从信号s(t)得到的估计延迟T^TDOA,通过以下方式得到最大搜索

最后,用以下公式得到需要的角度φ
式中c为声度,b为2只传感器之间的距离。
2 基于CAMshift的视觉目标定位
CAMshift[6]是基于均值偏移(mean shift)的算法。这里的均值偏移是指用一个非参数的方法来检测概率密度分布模式,利用一个递归过程收敛于最接近的平稳点。
CAMshift算法通过调节搜索窗口的大小来扩展均值偏移方法。通过扩展,这个方法可以应用到图像序列,这个图像序列中包括一个不断变化跟踪的颜色分布的形状。
CAMshift算法适用于立体视觉系统的左帧和右帧,得到2个中心点(xcl,ycl)和(xcr,ycr)。然后,左边的中心点(xcl,ycl)通过一个二维块匹配搜索在右边的框架搜索。这个搜索用到二维归一化互相关数R(x,y)。在右侧R(x,y)最大值的位置表示对应的左侧框架中相对于CAMshift的中心点(xcl,ycl)的MPr=(xMPr,yMPr),它在逻辑上表示在左侧的对应点,即MPl=(xMPl,yMPl)=(xcl,ycl)。
3 视听信息融合与目标跟踪
融合模块的任务是结合音频和视频算法得到的信息,来提供跟踪对象在当前三维位置相对于系统原点的坐标估计值。在本节,将阐述这种基于TRIBES的融合技术。
TRIBES融合方法中,在一个相对于视听系统原点的坐标系统,每个粒子M代表一个在三维空间中的位置,即M(x,y,z)。其基本思路是,最小化成本或适应度函数F(x),且F:∈Rn→R,使用动态粒子群。通过在参数空间x∈Ω⊂R″中搜索最优解。它的改进之处主要是,它不需要用户给定任何参数,包括粒子数、粒子拓扑等均是根据算法性能自动确定。
随着,从音频系统和视觉系统得到的位置信息,在三维空间中移动的粒子可以通过分别计算在音频系统中的最佳角度和视频系统中的最佳欧氏距离,来确定在当前位置的一个适合度函数。
1)音频:为了评估一个固定粒子在当前位置音频系统获得的方位角,本文引入一个音频距离变量Daudio。这个变量表示按弧度的角距离,即音频方位角和当前位置与音频系统原点之间的角度之间的距离,如图1所示。Daudio的距离通过π规范化,表示α与φ之间最大的角度差

其中,Zm和Xm分别为粒子位置在X和Z的坐标。因为音频角度φ为方位角,所以,Xm/Ym等效方位角α的切线。
2)视觉:为了评价粒子相对于立体视觉系统的当前位置,粒子被投影在左侧和右侧框架上,这样就能分别产生左侧和右侧的投影点ml=(xml,yml)和mr=(xml,ymr)。使用一个校准的立体摄像系统,通过以下方式获得的投影

其中,Pl和Pr是左帧和右帧的投影矩阵,计算公式为

假设左图像平面原点Ol被视为该系统的原点,矩阵[I|o]和[R|t]描述了在均匀坐标系统中左帧和右帧之间的单应性。R和t分别表示旋转矩阵和翻译向量。KKl和KKr表示相机矩阵。
归一化值Dleft和Dright代表一个粒子M在当前位置在左右图像帧的投影,即ml和mr与相应的视觉系统中本地化点即MPl和MPr之间的欧氏距离,计算公式为
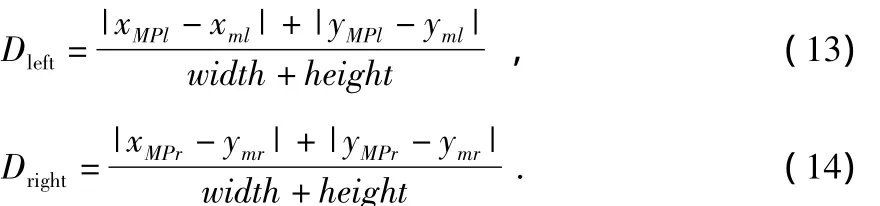
其中,width和height分别为左帧和右帧的宽度和高度,如图1所示。
3)适应度函数:根据算法TRIBES,每颗粒子通过每一次迭代中计算其适应度函数F来测试其在当前位置的质量。这个函数必须最小化,因此,当粒子的位置靠近要跟踪对象的解空间时,函数会减小。相对于基于视频的定位模块,距离Dleft和Dright测量位置质量。同样,相对于基于音频的模块,Daudio直接测量质量。因此,适当的适应度函数F被定义为3个距离值的加权的总和

图1 粒子群跟踪系统模型Fig 1 TRIBES tracking system model

其中,waudio,wleft,wright分别为每个组件的加权系数。
TRIBES算法提供了一个跟踪对象的3D位置估计。当迭代次数达到预定义的最大数量或者适应度函数F达到最小值Fmin时,即趋同标准满足了,TRIBES算法将停止迭代。此时,全局极值的3D位置gbestTRS(X,Y,Z)已经恰好表示跟踪对象的当前位置。
4 实验
在本节中,将基于卡尔曼的融合算法,与基于TRIBES算法在速度和准确性两方面进行了比较。为了测试和评估的跟踪器,要通过立体照相机和立体麦克风系统来获得一个人在某区域的移动和谈话的音频和视频数据。所用的硬件包括2个FireWire相机和2个AKG全方位麦克风。在第一次执行时,视频以每秒15帧和分辨率640像素 ×480像素拍摄。音频材料使用采样频率为44 100 Hz来记录。对于一个单一的音频计算步骤,文中捕捉和处理每个麦克风的4~8个窗口,一个FFT窗口长度1 024样本和50%重叠的音频流。这将导致最大的104.48 ms的时间帧。此外,利用突变体开发框架,实现了TRIBES系统和卡尔曼系统的一个优化版本。它使多线程执行不同的模块,允许有效地使用处理器的内核。这个版本允许每秒30帧的在线测试。该跟踪器实现了在C++中使用OpenCV库和使用FFTW库计算快速傅立叶变换。
4.1 速 度
测试卡尔曼算法和TRIBES算法在不同电脑上的平均计算时间,以ms为单位。
由表1可见,在计算时间方面TRIBES算法只比卡尔曼算法略少,因为视觉系统运行2个CAMshift跟踪器需要多于执行时间的60%。没有优化的话,视觉系统计算方位角的时间高达30%。这些预处理时间将被添加到卡尔曼和TRIBES融合技术中,卡尔曼和TRIBES算法的模块跟踪执行时间都将少于10%。在基于突变的实现中,卡尔曼和TRIBES模块都需要2 ms的平均计算时间和整个跟踪系统相机的帧率。
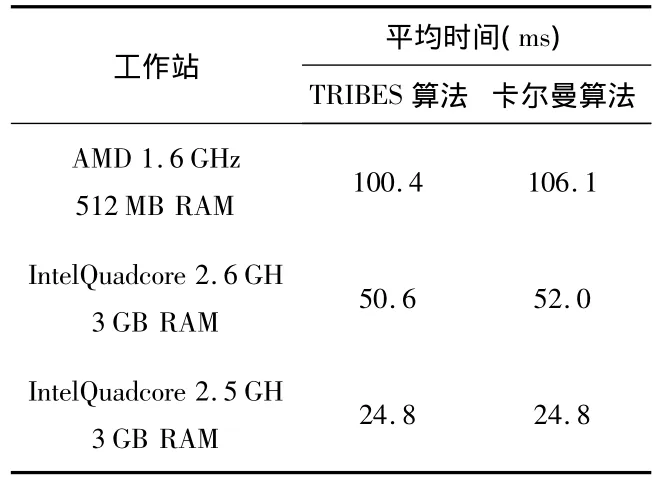
表1 卡尔曼算法和TRIBES算法平均时间比较Tab 1 Average time comparison of Kalman and TRIBES algorithm
4.2 准确性
竞争算法的突变体进行了在线测试。要获得在X和Z方向的精确的真实的数据和证据,本文使用SICK LM210激光雷达追加记录跟踪对象的位置。激光雷达每100 m提供一个位置估计,其角分辨率是0.5°和在Z方向的精确度是0.015 m。用TRIBES算法和卡尔曼跟踪器估计当前位置在X和Z的坐标,并与用激光雷达得到的位置比较。如图2所示X和Z的位置。通过测试,移动物体随着时间推移在Z坐标的位置,如图3所示。在每一个激光雷达测量步骤里,激光雷达、卡尔曼和TRIBES跟踪器记录位置。本文对不同的移动物体进行多次测试,以产生类似的结果。
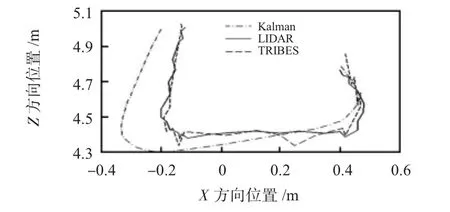
图2 X和Z的位置跟踪Fig 2 X and Z position tracking

图3 Z坐标位置跟踪Fig 3 Position tracking in Z coordinate
表2给出了由TRIBES跟踪系统和参考卡尔曼系统跟踪得到的在X和Z方向的平均值和最大误差还有平均欧氏误差。
结果表明:虽然在缓慢运动时卡尔曼系统比TRIBES算法提供了更加平滑的轨道,但是,TRIBES算法跟踪可以更快地适应位置的变化。当目标的速度和方向不断变化时,TRIBES算法跟踪器的跟踪误差非常小。

表2 TRIBES算法和卡尔曼算法结果比较Tab 2 Results comparison of TRIBES and Kalman algorithm
5 结论
本文提出了一种新的基于视听信息融合的3D目标跟踪系统,以TRIBES为基础的融合方法的速度性能比现存最简单的卡尔曼跟踪更快。因此,它的速度性能更超越耗时的粒子滤波或贝叶斯推理等复杂方法。该算法的另一个优点是,当目标的速度和方向不断变化时,它的跟踪误差非常小。
[1] Strobel N,Spors S,Rabenstein R.Joint audiovideo object localization and tracking[J].IEEE Signal Processing Magazine,2001,18(1):22 -31.
[2] Krahnstoever N,Yeasin M,Sharma R.Automatic acquisition and initialization of articulated models[J].Machine Vision and Applications,2003,14(4):218 -228.
[3] Jaina K,Chen Y.Pores and ridges:High-resolution fingerprint match using level 3 features[J].IEEE Pattern Analysis Machine Intelligence,2007,29(1):15 -27.
[4] Cooren Y,Clerc M,Siarry P.MO-TRIBES,an adaptive multiobjective particle swarm optimization algorithm[J].Comput Optim Appl,2011,49(2):379 -400.
[5] 王春艳,樊官民,孟 杰.基于广义互相关函数的声波阵列时延估计算法[J].电声技术,2010,34(8):36 -39.
[6] 申铉京,张 博.基于图像矩信息的 Camshift视觉跟踪方法[J].北京工业大学学报,2012,38(1):105-109.
