碎纸片的拼接复原
2013-10-17王勇勇曹晨雅李韶伟
王勇勇,赵 锋,曹晨雅,李韶伟
(台州学院 数学与信息工程学院,浙江 临海 317000)
1 引言
破碎文件的拼接在司法物证复原、历史文献修复以及军事情报获取等领域都有着重要的应用。然而,大量的纸质物证复原工作目前基本上都是以手工方式完成的,准确率较高,但效率很低。目前,德国等发达国家对破碎文件的自动修复技术已经进行了相当长的研究。而在国内,还没有类似研究成果问世。因此,通过设计相应的算法软件,开展对碎纸自动拼接技术的研究具有重要的现实意义。本文的目标是利用复原模型设计算法辅助的方法对碎纸机切碎的纸片进行拼接、复原。
本文主要讨论以下问题:
问题1.对于来自同一页印刷文字文件的碎纸机破碎纸片(仅纵切),建立碎纸片拼接复原模型和算法。
问题2.设计既纵切又横切的碎纸片拼接复原模型和算法。
问题3.设计双面打印文件的碎纸片的拼接复原模型与算法。
本文数据来源于2013年全国大学生数学建模竞赛的A题。
2 变量说明和名词解释
二值化:由于本题中所有碎纸片都是黑白的,因此将图片中灰度值>200的像素点的灰度值赋值为0,即确定该像素点是白色的。将图片中灰度值<200的像素点的灰度值赋值为1,即确定该像素点是黑色的。
最佳匹配:根据所有图片的左右两侧边缘像素形成2个列向量,元素逐个进行比较是否相同,一直进行到最后一对元素,找到匹配最好的一对边缘。
匹配系数:对所有图片的两个边缘灰度值的列矩阵中的元素,进行逐个比较,相同记为1,否则记为0,取1的总数称为匹配系数。
人工干预:在程序实现最佳匹配过程中,可能出现一个对多个的情况,此时需要进行人工干预。
行首(尾)图片:每一行的左(右)侧首张图片。找左边:根据纸张左侧空白的特点,查找碎片左侧空白像素点,从而确定行首图片。找右边:根据纸张右侧空白的特点,查找碎片右侧空白像素点,从而确定行尾图片。
3 问题分析与求解
3.1 问题一的算法设计
问题一的数据量较大,仅考虑纵向匹配,中英文的碎纸张拼接复原都可按以下步骤程序自动匹配完成:
第一步:读取所有图片左、右两侧像素点的灰度值。
第二步:将图片像素点的灰度值进行二值化处理得到像素。由图片的左、右两侧像素确定的左列矩阵I11和右列矩阵I22。
第三步:分别将图片左列矩阵I11中的元素与分别于其余18个图片右列矩阵I22中的元素,进行逐个点比较,相同的记录为1,不同的记录为0,一直进行到最后一对元素。记录得到一个新的矩阵I31。同理将图片右列矩阵与其余18个图片进行匹配,从而确定匹配系数。
第四步:根据第三步得到的匹配系数可以得到一个19×19的矩阵M。根据矩阵M中行向量每个元素都为0可以确定行首图片。
第五步:根据第四步确定的行首图片,通过矩阵M的元素(即各个图片间的匹配系数)确定剩余图片的顺序。从而,完成19个碎纸片的纵向拼接。
3.2 问题二算法设计
3.2.1 “行高”的定义
1.中文字体“行高”的定义:
纵向投影一张图片得到一列像素点的灰度值,将灰度值进行二值化处理,得后一个列向量L,根据以下流程,确定中文字体“行高”h的值:
注:70为图片中文字距与行距按上述处理后,在列向量L中元素的个数L(i)为L列向量第i个元素。
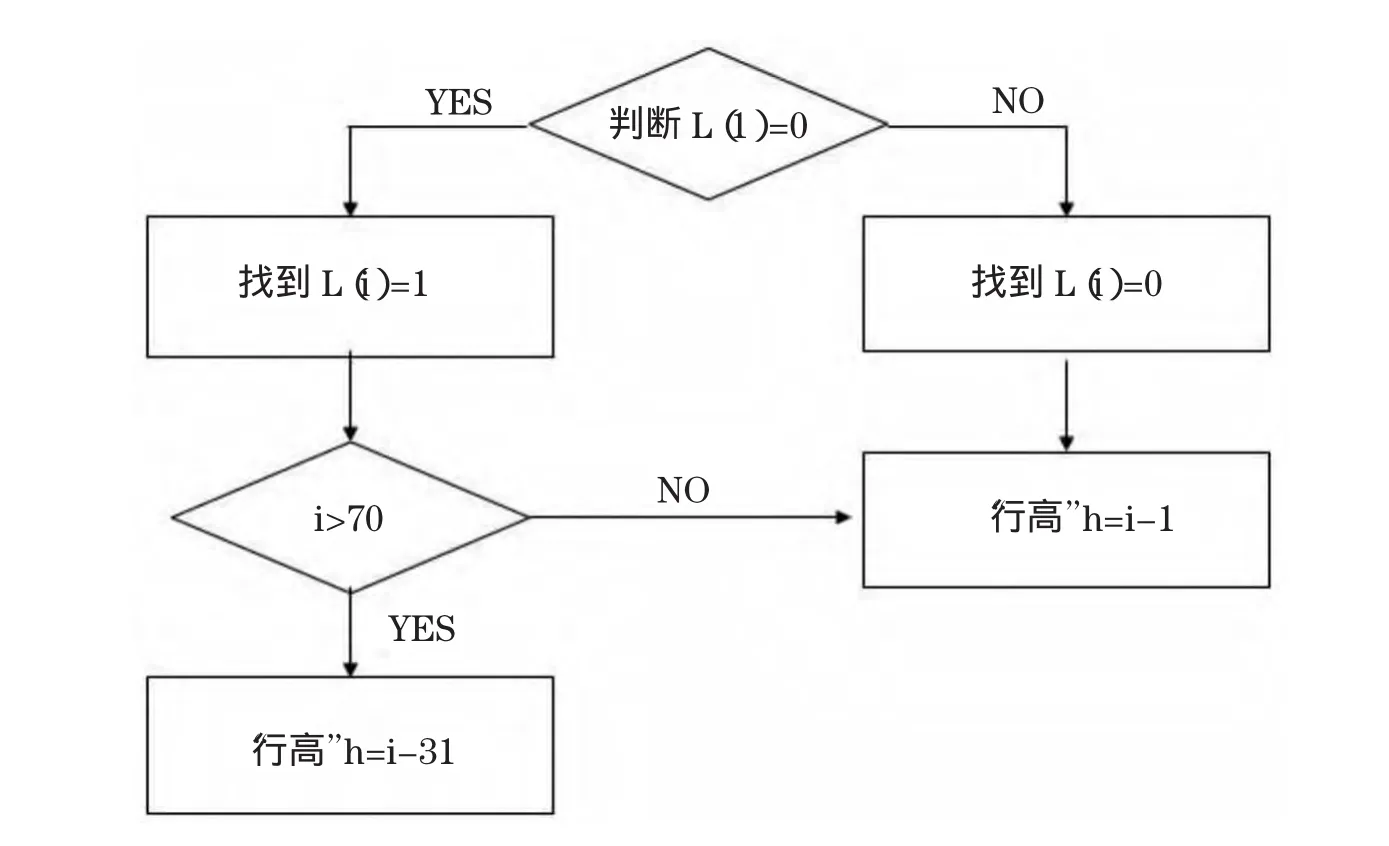
图1 确定中文行高的算法流程图
根据该流程图可以将所有图片分成以下三种类型

图2.1

图2.2

图2.3
图 2.1 类型一:图片顶部是文字,即 L(1)=1,h=i-1;
图 2.2 类型二:图片顶部是空白,即 L(1)=0,h=i-1;
图2.3类型三:图片顶部是空白,即L(1)=0,h=i-31.
2.英文“行高”的定义:
纵向投影一张图片得到一列像素点的灰度值,将灰度值分成两类,一类灰度值较小的赋值为0,灰度值较大的赋值为1,如下图所示。

图3 英文碎纸片的“行高”确定示意图
与确定中文“行高”h的原理相同,此时取i=64,其余不变。(注:64为图片中每个英文都覆盖的“中间带”的高度与行间距之和)
同理,若某碎纸片是双面的,可确定此碎纸片有两个“行高”数值x和y,定义问题三中的需要用到的“二维行高”。
3.2.2 问题二的算法设计
由于不能通过直接的左右匹配获得碎纸片的前后位置,因此我们提取各碎纸片的“行高”信息作为碎纸片的类别标志,区分碎纸片的类别,通过图2所示的算法步骤编写的运算程序,极大的提高了匹配的精确度。
第一步:提取所有图片每行像素点的灰度值并进行二值化处理
第二步:根据行首图片左侧像素点都为0这一特征,在所有图片中确定11个行首图像。
第三步:根据“行高”的特征进行分类,一共可以分成11类,每类19个图片(即同一行上所有图片为一类)。
第四步:将每组中的图片采用与问题一相类似的方法进行纵向拼接。但是由于每个图片的左、右两侧边缘的像素相对“问题一”来说减少了较多,所以此次纵向拼接可能出现误差。在此处需要加入人工干预,拼接出11行完整的文字图片。
第五步:通过程序的运行,可匹配出若干行碎块。加一次人工干预,可获得11行完整图片。
第六步:根据纵向拼接得到的11行的图片的进行横向拼接。由于图片上下边缘的像素点为可能0,所以在进行横向拼接时,需要再次人工干预。
3.3 问题三的算法设计
“二维行高”的定义:设a面的“行高”为x,b面的“行高”为y。
第一步:提取所有图片每行像素点的灰度值并进行二值化处理。
第二步:用matlab软件计算依次对每张图片进行“找左边”,同时将提取出来的这些图片的反面“找右边”,如003a、009b等图片,并比较它们找的左边与右边是否相等;若提取出来的图片的a、b面的边相等,那么,可以确定满足找左边的图片作为完整图片的最左侧,相应的,满足找右边的图片可以作为完整图片背面的最右侧;最终的到11张“行首图片”。
第三步:从第二步提取出来的“行首图片”中任意选择11张图片,根据他们的特征——“二维行高(x,y)”作为标准,进行分类,其次,用这11张图片的反面来检验之前的分类,形成了22组图片,使得分类的结果更加的精确可靠。
第四步:取上述22组图片中的其中一组的图片,运用matlab软件,使这些图片依次匹配,在进行匹配的同时,也对这些图像的反面进行匹配,从而提高了匹配的正确率。如:000a与002b匹配时,需要同时进行000b与002a匹配。
第五步:由于“二维行高”中的x和y有可能会出现相等的可能,那么,我们需要进行人工干预,对其进行匹配。
第六步:根据上面的步骤,我们得到了11张行的图片(22面),再用计算机程序对每一行进行横向匹配。
第七步:由于有一些行的图片正反两面上或下同时为段落分隔处(即为空白部分,无法用计算机进行匹配),那么,我们需要进行人工干预,对其进行匹配。
4 模型的评价及改进
由于文字的多样性,分割情况的复杂性,信息的丢失残缺等诸多原因,文字碎片的复原是一个十分困难的过程。但是其完全依靠手工或计算机进行拼接,不是效率低就是准确率低,所以两者必须结合起来。因此较好的算法应该具备以下特点:
1.由于“行高”的引入,复原准确率得到很大提高;
2.自动化程度高,即人工干预量小;
3.通用性好,尽可能试用多种分割模式下的碎片。
根据所给出的算法及其运行效果,本文的算法较符合上述三个特点,所以基本上在复原2013全国大学生数学建模赛题A题所提供的数据碎纸片的效果较好,其人工干预只涉及到碎块的拼接和结果的校对这两个环节上。当然碎纸片拼接复原模型算法上还有以下几种的改进可能:
1.关联度定义的改进,基于多种文字分割情况的分析、归类,尽可能设计出反映正确匹配的有效指标;将单一指标扩展成多重指标体系,提高指标精确度;
2.建立文字、单词、短语甚至常用语句的样本库,通过程序将拼凑结果与标准样本进行对比,提高正误判别能力;
3.设计一种通用的算法,即使碎片中同时含有中文、英文以及其他的符号运算,字体字号不同,也可以在较少的人工干预情况之下自动地将碎片拼接成完整的图片;
4.在现实情况中,需要复原的不仅是二维的文字信息,还有可能是三维的物体,例考古中的陶瓷碎片。因此我们需要对三维图形进行新一轮的讨论和分析,得到一个较精确的算法和程序。
[1]罗智中.基于文字特征的文档碎纸片半自动拼接[J]. 计算机工程与应用,2012,48(5):1-4.
[2]刘金根,吴志鹏.一种基于特征区域分割的图像拼接算法[J].西安电子科技大学学报,2002,29(6):769-770.
[3]朱延娟,周来水.二维非规则碎片的匹配算法[J]. 计算机工程,2007,33(24):290-294.
