基于字符频率的字符串模式匹配算法的研究
2013-10-17巫喜红
巫喜红,凌 捷
WU Xi-hong1,LING Jie2
(1. 嘉应学院 计算机学院,梅州 514015;2. 广东工业大学 计算机学院,广州 510090)
0 引言
网络带给人们方便的同时也存在安全隐患,而入侵检测系统(IDS)也越来越广泛地应用到网络系统中,因为它是提高网络系统安全性的重要技术之一。目前,许多IDS都是依靠模式匹配技术来进行入侵检测的,但是,在进行入侵检测时,花费在模式匹配上的时间占到整个IDS总处理时间的30%,对于密集型的流量,这一消耗达到80%[1]。因此,模式匹配性能的提高成为解决IDS的关键技术。目前,国内外对于模式匹配算法已有不少的研究成果,比如典型的单模式算法有Brute Force算法[2]、Knuth-Morris-Pratt(KMP)算法[3]、Byoer-Moore(BM)算法[4]、Sunday算法[5],多模式算法主要有Aho_Corasick(AC)算法[6]、Wu_Mander算法[7]。这些算法在实际应用中忽略了字符串的特征,没有实际考虑到字符的频率情况,为此,本文提出了利用字符统计特征的算法,在扫描过程中利用某个频率字符去进行匹配,跳过了一系列无用的字符,从而提高匹配速度。
1 几种经典的模式匹配算法
设文本串T=T0……Tn-1,n为文本串的长度;模式串P=P0……Pm-1,m为模式串的长度,(n>>m);T和P都建立在有限字符集上,大小为σ。
对于文本串T和模式串P,在T中寻找等于P的子串,如果在T中存在等于P的子串,则称匹配成功,函数值返回为P中第一个字符相等的字符在主串T中的序号,否则称为匹配失败,这个搜索过程就是模式匹配。至于如何在T中寻找等于P的子串,各种算法各显神通,各有各的寻找方法,在此简要介绍4种经典匹配算法。
BF算法[2]是效率最低的算法,从左到右进行匹配。首先将T[1]与P[1]进行比较,若不同,就将T[2]与P[1]进行比较,……,否则从T[2]开始与P[1]进行比较,继续开始下一趟的比较,重复上述过程。
KMP算法是由BF改进后不产生回溯的一种算法,每当匹配过程中出现字符串比较不等时,不需回溯i指针,而是利用已经得到的“部分匹配”结果将模式向右滑动尽可能远的一段距离后,继续进行比较。
BM算法是把P同文本串进行比较时从右向左,当某趟匹配失败时,采用坏字符启发规则和好后缀启发规则计算模式串右移的距离,并取两者最大值来决定模式串的右移量,移动尽可能远的距离,直到匹配成功或文本串匹配结束,其匹配时从右至左进行。
Sunday算法采用BM算法中的坏字符启发规则,开始时P的最左边与T的最左边对齐,模式匹配过程中进行P与T的比较时,可以从左向右或从右向左进行比较,在发现不匹配时,选取当前匹配窗口的下一个字符来判断右移量以跳过尽可能多的字符,从而提高了匹配效率。其匹配时从右至左进行或者从左至右均可。
2 字符频率描述及其已有的应用
在网络的流量中,绝大部分的报文属于正常报文,鉴于此特征,考虑各字符在报文中出现的频率来实现算法。文献[8]给出了ASCII字符(频率分布程序)的频率分布表,如表1所示。
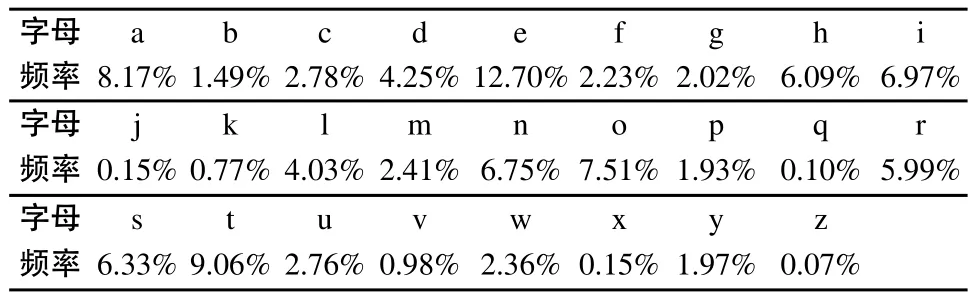
表1 英文字母频率表
根据表1中字母出现的频率值,从小到大排序后获得的字母顺序为:zqxjkvbpygfwmucldrhsnioate。
字符频率在模式匹配中的应用也有一些研究,如文献[1]是预处理T中所有出现字符的频率,并记录其在T中出现的位置,之后根据这些信息查找P在T中的位置,若找到,先匹配频率最低的,再匹配次低的,直到最后成功或遇到不匹配的字符。文献[9]尽可能选择失配率高度的字符进行比较,利用切分字符(T中不在模式字符串里出现而且在T中相对居中的字符)把T及T的子串不断地一分为二,直到找到P或没有长度大于或等于P的T的子串为止。文献[10]是把字符频率应用到Sunday算法的改进中,它在预处理阶段先确定P中最小频率值的某个字符及其在P中的位置,在匹配过程中只是第一次根据预处理阶段的信息进行匹配,第二次的右移距离还是采用Sunday算法的右移量进行跳转。文献[11]是在模式串中找出使用频率最低的和次低的两个汉字(或字符),将它们提取作为模式串的特征子串,其他汉字(或字符)做模糊处理。
以上各文献对字符频率在模式匹配算法中的应用各有千秋,在此提出另一种基于字符频率的模式匹配算法Characters-Frequency-Pattern-Matching算法,简称为CFPM,其思想是:1)在预处理阶段有两个任务,一是确定P中频率值最小的那个字符称为关键字符及其在P中的位置值,二是扫描T串,确定关键字符在T中的位置;2)匹配阶段,根据预处理阶段的信息,把关键字符与其在T中出现的位置进行一一对齐,并进行双向匹配。
3 CFPM算法
3.1 CFPM算法的预处理
在预处理阶段有两个任务,首先确定关键字符及其在P中的位置值,设计思路是:
1)输入P串,计算其长度m=strlen(P);
2)定义char *CF_value=″zqxjkvbpygfwmucldr hsnioate″,就是按照字母出现的频率值从小到大的排序;
3)从CF_value[0]开始寻找P中的每个字符,若没找到,则从CF_value[1]开始,直到找到为止,此时记录找到的字符即关键字符key_ch,并记录其在P中的位置。
其具体算法如下:
输入:P模式串;
定义:字符串的频率字符串CF_value,关键字符key_ch,key_ch在P中的位置pos,其它循环变量;
赋值:P的长度m;
功能:确定关键字符key_ch及其位置pos的值。

其次确定关键字符及其在P中的位置值,设计思路是:
1)输入T串,计算其长度n=strlen(T);
2)从T的第1个字符开始查找,若等于key_ch,则记录其位置在数字数组index[]当中。
其具体算法如下:
输入:T文本串
定义:数组index[],其下标值为num,num的初值为0;
功能:记录关键字符key_ch在T中的位置

3.2 CFPM算法的匹配过程
CFPM算法的匹配思路是进行双向匹配,即:以关键字符为始点,先进行向左匹配,再进行了向右匹配,当发现左部分失配时,直接进行下一轮的匹配,而不用进行右部分的匹配。当两部分均匹配成功,则输出匹配的位置,若不在成功,则输出失配的信息。具体算法描述如下:
1)i=0;
2)以T[index[i]]为起始点,进行T[index[i]-1]的字符与P[pos-j](j的初值是1)进行比较,若匹配,j加1不断地进行匹配,直到匹配至P[0];若出现第一个不匹配的字符,则结束左部分的匹配,执行4);否则执行3);(说明:此步骤是向左匹配)
3)进行T[index[i]+k](k的初值是1)的字符与P[pos+k]进行比较,若匹配,k加1不断地进行匹配,直到匹配至P[m-1];若出现第一个不匹配的字符,则结束右部分的匹配,执行4);否则执行5);
4)之后i加1,若i小于num,执行2),否则执行6);
5)若双向匹配成功,则输出匹配的位置;
6)结束匹配
其具体算法如下:
定义:定义向左、向右匹配的变量j,k,初值均为1;定义成功匹配的标志 flag,初值为0;
功能:确定P在T中的位置。


3.3 CFPM与典型算法的实例对比
对于CFPM算法,在此通过简单实例进行匹配演示,并将之与效率较高的BM算法、Sunday算法进行对比。
例如:T=”theykasenjoyformingworks”,P=”works”,现通过BM算法、Sunday算法、CFPM算法分别演示P在T中的实现,以对比CFPM算法的优越性。
1)BM算法的匹配演示
首先生成字符集C {k,o,r,s,w},BM_Bc函数值对应为{1,3,2,5,4},其余字符值均为5,其匹配过程如表2所示(表中的•表示不需要匹配的字符,粗体的字符表示匹配过的字符)。

表2 BM算法匹配过程
本例结果:匹配次数是7,匹配的字符个数是11。

表3 Sunday算法匹配过程
本例结果:匹配次数是5,匹配的字符个数是9。

表4 CFPM算法匹配过程
本例结果:匹配次数是2,匹配的字符个数是5,因为关键字符不需要再进行匹配。
2)Sunday算法的匹配演示
首先生成字符集C {k,o,r,s,w},Sunday_Bc函数值对应为{2,4,3,1,5},其余字符值均为6,其匹配过程如表3所示(表中的•表示不需要匹配的字符,粗体的字符表示匹配过的字符)。
3)CFPM算法的匹配演示
根据char *CF_value=″zqxjkvbpygfwmucldrhs nioate″,得P ="works"的关键字符key_ch= 'k',其在P中的位置pos=3。在T中查找key_ch的位置分别是index[0]=4,index[1]=22。之后根据这些信息进行左右匹配,其匹配过程如表4所示(表中的•表示不需要匹配的字符,包括key_ch,即字符 'k',只要把'k'与T[index[0]]对齐;粗体的字符表示匹配过的字符)。
从表2、表3和表4的结果可看出,CFPM算法在匹配次数和匹配的字符个数方面比BM算法、Sunday算法有明显的改进。
3.4 CFPM算法性能分析
CFPM算法在预处理阶段要进行两个任务,其一是确定key_ch在P中的位置,根据文献[8],在所有的ASCII码当中,26个小写字母出现的概率较高,所以在这一过程的时间复杂度是O(m);其二是在扫描T的过程中记录key_ch在T中的所有位置,这一过程定义了index[]数组,由于key_ch是P中概率最小的,所以index[]数组的长度远远小于n,这一过程的时间复杂度是O(n)。综合这两点,CFPM算法在预处理阶段的时间复杂度是O(m+n)。
CFPM算法在匹配阶段的跳跃次数完全取决于key_ch在T中出现的次数也就是index[]数组的大小,而算法在匹配最多次数是m-1(key_ch不需要进行匹配),假设key_ch的概率为p,则此阶段的时间的时间复杂度是p*O(m)。当字符集较大、关键字符出现概率越小时,复杂度越小,效率越高。
4 CFPM算法性能测试
为了检测CFPM算法的性能,随机抽取一段文本和一个模式串,在同一台计算机上实现BM算法、Sunday算法和CFPM算法。测试的操作系统用Windows XP,实现算法的软件是Visual C++6.0。测试文本如下:
Many networks are managed by a computer called a file server. A file server has a large-capacity hard disk and special software that manages access to flies on the network. It controls how data and database are shared among users on the network and how users access master copies of data and application software on the centralized hard disk. It is the file server's job to make sure that users don't accidentally try to update a file at the same time and scramble the data. The file server may also manage the access to an expensive piece of hardware such as a laser printer.
模式串为hardware。分别测试三种算法的匹配次数和匹配字符个数,结果如表5所示。
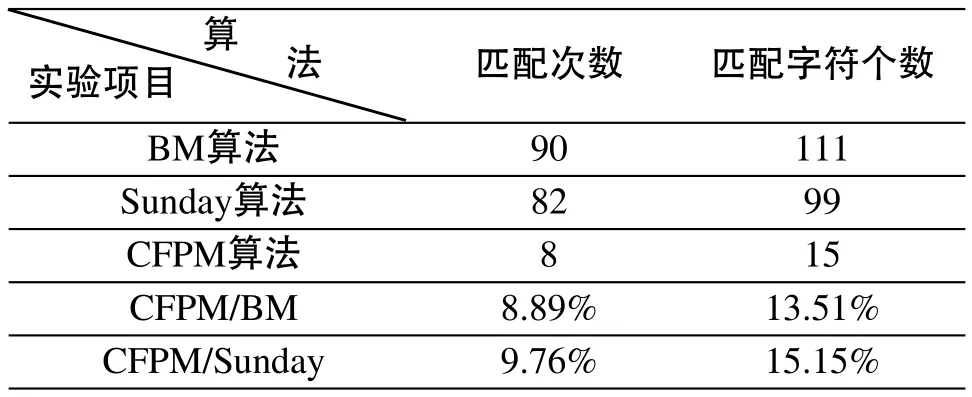
表5 BM算法、Sunday算法和CFPM算法的实验结果对比表
从表5可以看出:CFPM算法无论是在匹配次数还是匹配的字符个数方面,均比BM算法、Sunday算法有明显的优势,这是因为匹配时只选取P中字符频率最小的字符进行匹配,那么该字符在T中出现的次数也就最小,所需要右移的次数当然是最少的。另外,匹配时采用左右两部分比较方式,在一定程度上能够快速地判断是否匹配。因此,CFPM算法效率更高。
5 结束语
模式匹配算法效率高低由相关算法的移动距离决定,对于移动距离和匹配字符的顺序,各算法也大相径庭。BM算法由当前匹配窗口的末字符在P中的位置来决定下一轮的移动距离,匹配方向是从右向左,Sunday算法下一轮的移动距离则由当前匹配窗口的下一位字符在P中的位置来决定,本文提出的CFPM算法是与这两种算法不同,其移动距离是根据P中字符频率最低的字符在T中的位置来移动,匹配时是先匹配左边的,再匹配右边的。由于CFPM算法能够很大幅度地跳过坏字符,大大减少了移动的次数和比较的字符个数,减少了匹配时间,而且CFPM算法在编程方面容易实现,再加上入侵检测系统中模式匹配的成功率很低,所以更能提高匹配失败的概率。从总体上看,CFPM算法更符合入侵检测系统的需求,在入侵检测系统中更实用、更有效。
[1] 陈论,魏海平,王福威.一种面向入侵检测的模式匹配算法[J]. 辽宁石油化工大学学报.2009,29(1):69-72.
[2] 王成,刘金刚.一种改进的字符串匹配算法.计算机工程.2006,32(2):62-64.
[3] Knuth D E,Morris J H,Pratt V R. Fast pattern in strings.SIJM Journal on computing:1977,6(2):323-350.
[4] Boyer RS.Moore JS.A Fast String Searching Algorithm.Communications of the ACM,1977 20(10):762-772.
[5] SUNDAY D M.A very fast substring search algorithm.Communications of the ACM,1990,33(3):132-142.
[6] Aho A V,Corasick M J. Ef ficient String Matching: An Aid to Bibliographic Search[J].Communications of the ACM,1975,18(6):333-340.
[7] S. Wu. U.Manber. A Fast Algorithm For Multi-Pattern Searching.Technical Report TR-94-17.University of Arizona.,1994,1-11.
[8] http://zh.wikipedia.org/wiki/%E8%8B%B1%E6%96%87%E5%AD%97%E6%AF%8D.
[9] 邓一贵.基于字符频率及分治法的字符串模式匹配算法[J]. 计算机科学.2008,35(6):168-170.
[10] 万晓榆,杨波,樊自甫.改进的Sunday模式匹配算法[J].计算机工程.2009,35(7):125-126.
[11] 洪涛,侯整风.基于字频的模式匹配算法[J].微计算机信息.2010,26(11-3):188-189.
