基于分布式计算的电信联机采集系统设计
2013-10-15康尚钦叶何亮
康尚钦,李 军,叶何亮,李 嫚
(1.中国电信股份有限公司广东研究院网络发展研究部,广东 广州 510630;2.中国电信集团公司企业信息化事业部,北京 100032)
0 引言
随着电信全业务运营的发展和移动互联网时代的到来,电信运营商传统的联机采集系统正面临着海量数据采集和处理的压力。运营商需根据业务需求和运营管理需要,构建集约、高效的联机采集系统[1]。本文研究如何通过分布式计算技术实现电信联机采集系统的采集提速和处理能力提升,以及建设运营成本的降低。
1 电信计费采集系统的现状
计费采集系统从各个交换网元和业务平台采集话单、账单等数据,完成处理、分拣,并提供给HotBilling、结算等系统进行后续处理。计费数据采集的方式分为在线采集、联机采集、离线采集三种。联机采集是数据采集的主要方式。联机采集是指计费系统直接通过网络实现联网采集后付费数据源的采集方式,包括采集任务管理、采集上传/下发、数据校验、记录采集日志、提交数据处理、回退处理等过程。
目前部分省级电信运营商的联机采集系统存在硬件老化、设备分散、采集环节过多等问题,影响了话单的实时性,也给运营维护提出了较高的要求。随着移动业务和增值业务的迅猛发展以及行业竞争的日益加剧,对计费实时性的要求越来越高,实现联机采集系统的采集提速和集约运营成为紧迫的需求。在联机采集系统集中和提速过程中,面临一些问题有待解决:
(1)采集周期缩短,则单点采集能力需要提高数倍,并要将单文件串行处理变成并行处理,对采集进程性能要求很高。
(2)采集系统集中后,需要完成以前数百个采集节点的采集任务,系统负荷急剧升高,同时峰值负荷将提高至数十倍。
(3)采集进程、话单处理进程、分发进程需要同时并发,整个系统的并发进程数较多,系统资源均衡难度较大。
(4)所有话单数据集中存储,并发访问,易出现磁盘I/O瓶颈。
2 相关技术介绍
分布式计算技术将需要大量运算的问题分解成许多小的部分,把这些部分分配给许多计算节点去处理,最后把这些节点的计算结果综合起来形成答案。分布式计算技术实现了分散资源的共享和跨计算节点的任务调度,为提升系统处理能力和横向扩展能力提供了一种很好的方法。
Hadoop是Apache软件基金会管理的一个项目,它是Google开发的用来支持互联网级数据处理的MapReduce编程模型和底层文件系统GFS的开源实现[2]。Hadoop可以在大量廉价的硬件设备组成的集群上运行应用程序,为应用程序提供一组稳定可靠的接口,旨在构建一个低成本、高可靠性和高扩展性的分布式系统。
Hadoop主要由 Hadoop Common、HDFS、MapReduce 等子项目组成[3]。MapReduce[4]计算模型的出现极大地简化了分布式程序的编写,使用户可以脱离细节的困扰,集中精力于任务本身的描述和实现。HDFS[5]是一个分布式文件系统,设计用来部署在廉价的硬件上,提供高容量、高容错性、高吞吐量的数据存储。
3 基于分布式计算的电信联机采集系统架构
3.1 Hadoop分布式计算框架在电信联机系统的应用可行性分析
Hadoop分布式计算框架可以很好地解决联机采集系统集中和提速遇到的问题,主要体现在以下几个方面:
(1)采用Hadoop框架将数百个CPU内核组成强大的集群服务平台[6],可以将系统的采集处理能力提升至单机的数百倍。
(2)采用Map-Reduce方式,可以将采集负荷压力分散到数百个独立节点,大大提升系统峰值处理能力[7]。
(3)通过Job均衡器方式可以调度所有进程的资源使用情况,从而保证采集资源合理使用,各个进程平滑运行。
(4)利用HDFS技术,实现话单数据多节点分散存储模式[8],每块磁盘保证独立访问,从而避免了磁盘I/O瓶颈[9],同时整个系统的I/O带宽扩展数十倍。
3.2 系统逻辑和部署架构
“分布式联机采集系统”利用分布式计算平台的并行计算和分散存储的优势,实现并行话单采集、并行话单处理以及文件分布式存储,提高了整个采集流程的计算处理能力,同时提升了文件大批量读写性能,从而提高了联机采集系统的速度和效率。
分布式联机采集系统逻辑架构如图1所示。系统主要由云计算[10]引擎、联机采集云计算模块和云采集管理监控三部分组成。云计算引擎(Hadoop)分为HDFS、Map/Reduce和HIVE三部分,分别实现分布式文件系统、分布式并行编程与执行、数据摘要与查询[11]。联机采集云计算模块包括文件云存储处理、采集并行、话单处理、数据分发子模块,以及相应的策略模板管理。云采集管理监控模块包括对系统性能、告警、配置、日志、用户的管理,以及对底层引擎文件存储、作业性能的管理和对HDFS、Map/Reduce的监控。
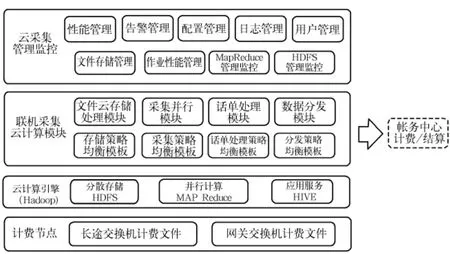
图1 分布式联机采集系统逻辑架构
系统的部署架构如图2所示,采用全省集中的一级模式。服务器按用途可分为采集组、管理组和分发组。采集组配置了3台名称节点和66台数据节点。管理组配置了1台管理服务器,用于采集业务及系统参数的配置管理;配置了1台话单服务器,用于话单处理、话单查询及业务监控。分发组配置了2台分发服务器和1台磁盘阵列,可以在线存储1个月的计费文件,用于系统数据分发。其中,2台分发服务器采用负荷分担、互为备份的工作方式,同时主/备分发服务器通过SCSI电缆连接到RAID5磁盘阵列。

图2 分布式联机采集系统部署架构
3.3 分布式采集与处理流程
分布式联机采集系统的主要处理流程如图3所示,分为配置采集作业、采集任务Map/Reduce、采集功能执行、采集文件存储、采集性能报告5个阶段。

图3 分布式联机采集系统处理流程
在配置采集作业阶段,分布式联机采集系统根据联机采集的业务要求,使用JobConf进行作业配置文件并制定采集任务功能Jar包,然后通过JobClient提交采集作业。
在采集任务Map/Reduce阶段,系统由JobTracker负责将一个采集作业(Job)分配为多个采集任务(Task),根据各个节点的资源情况,JobTracker将Map/Reduce任务分配到各个 DataNode,并由 Task-Tracker调用Map子任务,完成计费文件的并行采集。
在采集功能执行阶段,由于不同类型的交换机对应的采集功能以及协议有所区别,因此需要将不同交换机采集功能模块封装在Utility库中,从而支持所有交换机采集功能。TaskTracker将启动采集任务中对应的Jar功能包,Jar功能包将根据采集任务中配置的交换机类型,调用Utility库中对应的采集模块,执行采集流程,实现交换机计费文件的联机采集。
在采集文件存储阶段,系统将不同采集任务(Task)采集到的CDR文件,存储于内存虚拟的本地缓存区(Buffer),TaskTracker调用Reduce任务,自动扫描缓存区,将采集完成的CDR文件进行数据分发并存储到HDFS系统,并向JobTracker汇报。
采集完成后,系统会报告采集任务执行情况,可用于监控和运营分析。报告内容包含:
(1)采集性能,包含平均采集时长、最短采集时长、最长采集时长;
(2)预处理性能,包含平均时长、最短时长、最长时长;
(3)分发性能,包含平均时长、最短时长、最长时长;
(4)告警信息,包含告警信息、告警类型、告警时间、告警确认人和短信派发人。
4 系统应用效果分析
通过以上的研究,可以看到,与传统的集中处理型联机采集系统方案相比,基于分布式计算的联机采集系统方案具有以下优点:
(1)提高了数据的可靠性。
基于分布式计算的联机采集系统实现了话单数据的多副本存储,并放置在集群的不同节点上,在提高数据访问性能的同时,使话单数据的保存更加安全,即使某个节点的数据因故障出现丢失,也不会破坏话单数据的完整性。
(2)提高了采集处理的时效性。
由于采用了分散存储、分散处理的模式,避免了集中处理模式下的数据传输和处理性能瓶颈,话单采集处理的时效性会有较大提升。测试表明,原有75%以上的采集节点采集周期接近15分钟甚至更长,引入分布式采集系统后,可将采集周期缩短至5分钟,针对部分交换机采用虚拟内存技术,可以将采集周期缩短至1分钟。
(3)提高了系统的可扩展性。
集中处理型联机采集系统通常需要通过垂直扩展的方式实现服务器处理能力提升,升级成本大于部署更多相对便宜的服务器,同时性能提升幅度也有一定的上限。基于Hadoop的系统可以方便地通过增加数据节点提升处理能力,实现灵活、快速的水平扩展[12]。
(4)降低了建设和运营成本。
集中处理型联机采集系统方案需要配置高性能的小型机及磁盘阵列。分布式联机采集系统的节点服务器、管理服务器可部署在PC服务器上,数据节点可采用工控机,数据存储在本机硬盘上。在相当的计算和存储能力下,分布式联机采集系统方案的建设投资约为集中处理型采集系统方案的三分之一。
原有联采设备包括采集机124台、磁盘阵列37台、管理终端22台,共计183台。分布式联机采集系统方案含服务器73台,大大减少了设备数量,一方面降低了维护管理难度和人员需求,另一方面减少了设备能耗。
(5)便于话单数据分析与挖掘。
利用Hadoop上的数据仓库Hive[13],可以实现高效的海量话单数据查询,还可以分析用户话务特征,分析竞争对手用户的行为习惯,为产品套餐设计、维系挽留和市场开拓[14]提供有效、及时的数据支撑。
5 结束语
利用Hadoop分布式计算框架可以构建低成本、高存储能力和高处理能力的联机采集系统,有效提升采集速度,并可提供海量话单数据的在线查询及数据挖掘能力,为企业业务发展提供有效数据支撑。
[1]姚文胜,李嫚,乔宏明,等.云计算在运营商IT支撑系统领域的应用研究[J].移动通信,2010,34(11):52-57.
[2]Apache.Hadoop[EB/OL].URL:http://hadoop.apache.org/,2012-09-07.
[3]程莹,张云勇,徐雷,等.基于Hadoop及关系型数据库的海量数据分析研究[J].电信科学,2010(11):47-50.
[4]Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters[C]//Proc.of OSDI’04.Boston,MA,USA,2004:10.
[5]Apache.Hadoop Distributed Filesystem[EB/OL].http://hadoop.apache.org/hdfs/,2012-09-07.
[6]曾理,王以群.Hadoop集群和单机数据处理的耗时对比实验[J].硅谷,2009(19):55-56.
[7]陈全,邓倩妮.云计算及其关键技术[J].计算机应用,2009,29(9):2562-2567.
[8]Apache.HDFS Architecture[EB/OL].http://hadoop.apache.org/common/docs/current/hdfs_design.html,2012-09-07.
[9]李云桃.基干Hadoop的海量数据处理系统的设计与实现[D].哈尔滨:哈尔滨工业大学,2009.
[10]Wikipedia.Cloud Computing[EB/OL].http://en.wikipedia.org/wiki/Cloud_computing,2011-12-20.
[11]Apache.Hadoop Cluster Setup[EB/OL].http://hadoop.apache.org/common/docs/current/cluster_setup,2012-09-07.
[12]Tom White.Hadoop:The Definitive Guide[M].O’Reilly,2010.
[13]程苗,陈华平.基于Hadoop的Web日志挖掘[J].计算机工程,2011,37(11):37-39.
[14]贾文娟.基于Hive分布式计算与数据挖掘的关联性营销的设计与实现[D].北京:北京交通大学,2011.
