基于二进制串的Trie索引树分词词典机制的研究
2013-10-15丰继林王茂发张艳霞陈福明陈新房潘志安
韩 莹,丰继林,袁 静,王茂发,张艳霞,陈福明,陈新房,潘志安
(1.防灾科技学院灾害信息工程系,北京 101601;2.清华大学计算机科学与技术系,北京 100084)
0 引言
中文信息处理存在分词问题,分词的基础需要一个足够大的词库,要知道一个汉字串是不是一个词,就需要查询词库,如果能在词库中查询到,就认为是一个词。分词词典是汉语自动分词系统的一个基本组成部分[1],在汉语信息处理的过程中需要频繁地查询词典来确认某个汉字串是不是词,因此汉语词典机构组织级查询速率对整个系统的效率有很大影响。中文自动分词系统的研究已经有很多年了,目前已经形成了一些成熟的汉语词典机制及查询算法。常用的有线性索引机制、倒排索引机制、哈希索引机制、各种索引树及混合模式。线性索引机制和倒排索引机制属于静态索引表,不利于添加和删除等更新操作,只能用顺序法或折半法查询数据。哈希索引机制是在表项的存储位置与它的关键码之间建立一个确定的对应函数关系Hash(),使得每个关键码与结构中的一个唯一的存储位置对应[2]。对于Hash结构来说,关键在于如何设计一个好的哈希函数,尽量减少冲突。Douglas C.Schmidt提出一种很好的散列函数算法[3],该算法保证得到每一个Hash值都是唯一的。但是这种算法目前来说还有缺陷,实验结果显示,随着数据增大,空间浪费会非常多。搜索索引机制包括B树和Trie树结构等,结构相对比较复杂,但是如果结构设计得很好,查询的效率也非常高。基于这两种方法,还有一些变种的算法[4-7]。另外文献[8]中采用的是二级散列索引机制来组织和构造机器翻译词典。文献[9]指出了几种常用的词典构造机制:整词二分词典查询机制、Trie索引树词典查询机制、逐字二分词典查询机制。文献[10]中提出了基于双字哈希机制的词典查询方法。文献[11]采用了四字哈希机制。文献[4]中提出了一种基于PATRICIAtree的汉语词典查询机制。文献[12]提出了两种汉语词典快速查询机制:双数组Trie索引机制、双编码机制。基于Trie索引树原理,本文先简单介绍Trie索引树,然后提出一种改进的基于Trie索引树的词典查询机制。
1 Trie索引树
Trie树是搜索树的一种,可以组织成有效的数据索引机制。它是一个确定的有限状态自动机,搜索树中的每个结点代表一个状态,根据输入不同的变量,状态作出相应的转移。面向英文的Trie索引树大多是以26个字母作为关键字,树中的每个结点包含相同的指针,是一棵26叉Trie树,如图1所示。
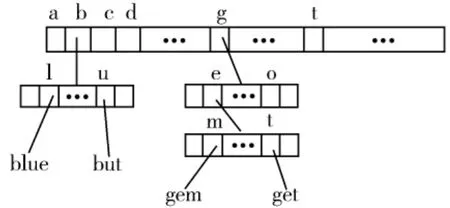
图1 Trie索引树结构
Trie树的一种存储方式是使用链表结点,这种方式在空间复杂度上降低为O(n),但是缺点在于数据结构复杂,查询效率较低[13]。传统上的有限状态自动机多采用转换表来实现,其列表示自动机的不同状态,行表示转换变量,但是对于词典查询来说,转换表的不足之处在于稀疏的数据导致了很多的空间浪费,其空间复杂度为O(n2)。一方面为了保证查询的效率,另一方面又要使占用的空间较少,前人提出了4个数组来表示DFA的方法,之后又对其进行了改进,提出了用3个线性数组来表示Trie树的方法。文献[14]在上述基础上做出了又一次改进,用两个线性数组来表示,即双数组Trie[15]。构造完双数组之后,查询就变得比较方便。查询的汉字串有几个字,就将该汉字串分别转换为相应的编码,在编码基础上做加法运算,即可以查询词库判断该汉字串是不是一个词语。在汉语词汇中,对常用词典(人民日报)的统计发现,在108783个词汇中,51%为2字词,31%为3字词,13%为4字词,3%左右为单字词,多出4字以上的词汇只占2%左右[16],因此双数组查询算法的效率是极高的。
2 基于二进制串的Trie索引树
基于Trie索引树结构的思想,本文提出一种改进的词典索引机制。基本思想如下:
2.1 对汉字串处理转换成二进制串的处理
信息在计算机中都是以二进制的方式存储的,每个汉字在计算机中的编码就对应于一组二进制串,本文把对汉字串的处理转化成对二进制串的处理。
2.2 对二进制串进行等长切分
可以对任意一个二进制串分成长度均为m(m>=2bit&&m<=16bit)的几段,在最后一段中,如果长度不够m,自动补0使该段长度为m。例如一个汉字串含有2个汉字,共有32bit,每5bit分成一段,则被分成7段,最后一度长度为2bit,自动在后面加3个0,使其达到5个bit的长度。
对于m的值,如果取值小,使用的空间少,但是增加索引的级别,即所创建的Trie树层次多,增加查询开销;如果取值太大,所建的Trie树层次少,查询速度快,但是耗费的空间非常大。应该根据词库中词的特点及实际的问题需求,为m选择一个合适值。
以m=8为例,即对待处理的汉字串的二进制串选取每8bit为一段,每段视为无符号数,求出其值,最大值为255,那么表示的数据范围是0~255。
例如:词语“作风”的GBK内码是D7F7B7E7,对应的二进制串11010111111101111011011111100111,把该二进制每8bit分成一段,得到的是11010111、11110111、10110111、11100111,把每一段看成无符号数,计算其十进制值为 215,247,183,231。
2.3 索引树结点结构
索引树中的每个结点都是以如图2所示结构为基本元素构成的哈希索引表。

图2 Trie索引树结点结构
标志位flag:标识词语是否结束,如果结束为1,否则为0;初值均为0。
指针:指向其孩子结点,初值均为空。
上述对二进制串分段后计算出来的无符号值作为在结点的哈希索引表中的地址,因为8bit二进制串最大能表示出来的无符号数值为256,因此结点的哈希索引表长为256,所得到的索引树是一棵256叉树。
结点所在的哈希索引表中的元素结构定义如下:
typedef struct tag_word_node{//哈希索引表中元素的结构类型
struct tag_word_node* next_tb;
int flag;
}word_node_t;
#define MAX_TABLE_SIZE 256
word_node_t g_table[MAX_TABLE_SIZE];//全局变量,作为根结点。
以m=8bit为例,部分词语构成的Trie索引树结构图如图3所示。

图3 基于Trie索引树的分词词典机制
3 实验结果及分析
实验环境为 Intel-I3、4G内存、64位操作系统Window 7。
在程序测试时,测试词库使用的是含有339095不限词长的基本通用词表,空间分析与时间分析如下。
分别对m取不同的值做了相应的分析,当m>=9的时候,测试程序提示内存不足,所以实验中只分析了m在2~8之间的值。以m=8为例来说明,当m=8的时候,所建立的256叉Trie树共有532113个结点,每个结点是一个含有256个元素的哈希索引表,哈希索引表表中的每个元素是一个含有一个标志符和一个指向其孩子结点的指针构成,计算出来所含的字节数是 1,089,767,424。
在本系统中,查询词语与词条的多少没有关系,只与词条本身的长度有关系。以m=8为例,如果要查找一个汉字个数为3的词条,需要计算6次索引值就能确认该词在词库中是不是存在。
选取几个具有代表性的m的值,表1显示了当m分别取不同值时的结点数和所耗的空间大小,查询时间为把含有339095个词条的测试词库中所有的词条查询一遍所耗费的平均总时间。

表1 m 取不同值时的空间分析和时间分析
4 结束语
本文在分析了Trie树结构之后,根据信息在计算机以二进制串存储的特点,把对文本信息处理改为对二进制串的处理,建立Trie树的分词词典机制。虽然这种Trie存储结构没有双数组Trie树的查询速度快,但是这种结构更灵活,可以适用于不同的语言。在实际处理过程中,二进制的串与串之间有很多相同的前缀,实际耗费的空间并不多;并且该词典机制不受词数量的限制,词语的数量越多,空间利用率越高。这种分词词典机制不受语言限制,也不受词库大小的限制,是一个功能强大的大容量词典机制。
[1]孙茂松,邹嘉彦.汉语自动分词研究中的若干理论问题[J].语言文字应用,1995(4):40-46.
[2]殷人昆,陶永雷,谢若阳,等.数据结构:用面向对象方法与C++描述[M].北京:清华大学出版社,1999.
[3]Douglas Schmidt.GPERF:A Perfect Hash Function Generator[EB/OL].http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.34.1056,2012-08-03.
[4]杨文峰,陈光英,李星.基于PATRICIA Tree的汉语自动分词词典机制[J].中文信息学报,2001,15(3):44-49.
[5]温滔,朱巧明,吕强.一种快速汉语分词算法[J].计算机工程,2004,30(19):119-120,128.
[6]吴胜远.一种汉语分词方法[J].计算机研究与发展,1996,33(4):306-311.
[7]Kazuhiro M,El-Sayed A,Masao F,et al.Fast and compact updating algorithms of a double-array structure[J].Information Sciences,2004,159(1-2):53-67.
[8]王秀坤,李政,简幼良,等.基于Hash方法的机器翻译词典的组织与构造[J].大连理工大学学报,1996,36(3):352-355.
[9]孙茂松,左正平,黄昌宁.汉语自动分词词典机制的实验研究[J].中文信息学报,2000,14(1):1-6.
[10]李庆虎,陈玉健,孙家广.一种中文分词词典新机制——双字哈希机制[J].中文信息学报,2003,17(4):13-l8.
[11]张培颖,李村合.一种中文分词词典新机制——四字哈希机制[J].微型电脑应用,2006,22(10):35-36,55.
[12]李江波,周强,陈袒舜.汉语词典的快速查询算法研究[J].中文信息学报,2006,20(5):31-39.
[13]严蔚敏,吴伟民.数据结构[M].北京:清华大学出版社,1992.
[14]Aoe J.An efficient digital search algorithm by using a double-array structure[J].IEEE Transactions on Software Engineering.1989,15(9):1066-1077.
[15]Theppitak Karoonboonyanan.An Implementation of Double-Array Trie[EB/OL].http://linux.thai.net/~ thep/datrie/datrie.html,2010-09-25.
[16]吴晶晶,荆继武,聂晓峰,等.一种快速中文分词词典机制[J].中国科学院研究生院学报,2009,26(5):703-711.
