MPI环境下二维流动的并行计算
2013-10-15符栋良
符栋良
(上海市特种设备监督检验技术研究院)
基于PC机群的并行计算是当前国际上计算机科学与应用领域中引人注目的课题之一,该领域的研究在我国现阶段科研条件下有着很强的现实意义。在诸如预测模型的构造和模拟、工程设计和自动化、能源勘探、医学、军事以及基础理论研究等领域,都对计算提出了极高的具有挑战性的要求,所以对并行计算有很迫切的需求。
1 并行计算环境
1.1 MPI并行环境介绍
本文采用的网络并行环境是MPI(message passing interface),MPI是目前最重要的实现消息传递的并行编程环境之一,它具有移植性好、功能强大、效率高等多种优点[1]。具体地讲,MPI就是提供了并行库。这样,原来的串行编译器能够继续使用,编程者只需要在原来的串行程序中加入对并行库的调用,就可以实现并行程序设计。在MPI-1中共有128个调用接口,在MPI-2中有287个。应该说MPI是比较庞大的,想完全掌握这么多的调用很困难。但是,从理论上说,MPI所有的通信功能可以用它的6个基本的调用来实现,掌握了这6个调用,就可以实现所有的消息传递并行程序的功能。因此,下面介绍这6个最基本的调用[1]。
(1) MPI初始化
MPI_Init()
MPI_Init是MPI程序的第一个调用,它完成MPI程序所有的初始化工作,是所有MPI程序的第一条可执行语句。
(2) MPI结束
MPI_Finalize()
MPI_Finalize是MPI程序的最后一个调用,它结束MPI程序的运行,是MPI程序的最后一条可执行语句。
(3)当前进程标识
MPI_Comm_rank(comm,rank)
comm——该进程所在的通信域
rank——调用进程在comm中的标识号
这一语句用来返回调用给定的通信域中的进程标识号。有了这一标识号,不同的进程就可以将自身和其它的进程区别开来,从而实现各进程的并行和协作。
(4)通信域包含的进程数
MPI_Comm_size(comm,size)
comm——通信域
size——通信域comm内包括的进程数
这一调用返回给定的通信域中所包括的进程的个数,不同的进程通过这一调用得知在给定的通信域中一共有多少个进程在并行执行。
(5) 消息发送
MPI_Send(buf,count,datatype,dest,tag,comm)
buf——发送缓冲区的起始地址
count——将发送的数据的个数
datatype——发送数据的数据类型
dest——目的进程标识号
tag——消息标志
comm——通信域
MPI_Send将发送缓冲区中的count个datatype数据类型的数据发送到目的进程,目的进程在通信域中的标识号是dest,本次发送的消息标志是tag。使用这一标志,就可以把本次发送的消息和本进程向同一目的进程发送的其它消息区别开来。
MPI_Send操作指定的发送缓冲区是由count个类型为datatype的连续数据空间组成,起始地址为buf。注意这里不是以字节计数,而是以数据类型为单位指定消息的长度,这样就独立于具体的实现并且更接近于用户的观点。其中datatype数据类型可以是MPI的预定义类型,也可以是用户自定义的类型。通过使用不同的数据类型调用MPI_Send,可以发送不同类型的数据。
(6) 消息接收
MPI_Recv(buf,count,datatype,source,tag,comm,status)
buf——接收缓冲区的起始地址
count——最多可接收的数据的个数
datatype——接收数据的数据类型
source——所接收的数据的来源,即发送数据的进程标识号
tag——消息标识,与相应的发送操作的标示相匹配
comm——本进程和发送进程所在的通信域status——返回状态
MPI_Recv从指定的进程source接收消息,并且该消息的数据类型、消息标识和本接收进程指定的datatype、tag相一致,接收到的消息所包含的数据元素的个数最多不能超过count。
接收缓冲区是由count个类型为datatype的连续元素空间组成,由datatype指定其类型,起始地址为buf。接收到消息的长度必须小于或等于接收缓冲区的长度,这是因为如果接收到的数据过大,MPI没有截断,接收缓冲区会发生溢出错误,因此编程者要保证接收缓冲区的长度不小于发送数据的长度。如果一个短于接收缓冲区的消息到达,那么只有相应于这个消息的那些地址被修改。count可以是零,这种情况下消息的数据部分是空的。其中datatype数据类型可以是MPI的预定义类型,也可以是用户自定义的类型。通过指定不同的数据类型调用MPI_Recv,可以接收不同类型的数据。
1.2 MPI并行平台搭建介绍
在服务器和客户机上都安装软件包MPICH.NT.1.2.0.4。安装内容包括:远程调用的程序、运行时动态连接库和MPI程序的启动程序。
使用编译器进行并行程序编译链接,在使用其编译程序前,增加一个Fortran项目环境,点击菜单Project→Settings…,进行下面的操作。
(1) 在setting for中, 选择Win32 debug。
①选择Fortran标签:在Category一栏中选择“External Procedures”; 在 “Argument Passing” 一栏中选择 “C,By Reference”; 在 “String Length Argument”一栏中选择 “After All Args”。
②选择Link标签:在Category一栏中选择“General”; 在 Object/library modules中 , 添 加ws2_32.lib、 mpichd.lib、 pmpichd.lib、 romiod.lib,各库文件间用空格分开。
(2) 在setting for中, 选择Win32 release。
①选择Fortran标签:在Category一栏中选择“External Procedures”; 在 “Argument Passing” 一栏中选择 “C,By Reference”; 在 “String Length Argument”一栏中选择 “After All Args”。
②选择Link标签:在Category一栏中选择“General”; 在 Object/library modules中 , 添 加ws2_32.lib、 mpich.lib、 pmpich.lib、 romio.lib, 各库文件间用空格分开。
(3) 点击菜单 File→Save Fortran Environment。
这样就可以在以后程序设计时方便地使用这一编译环境。
在每台机器上都启动了RemoteShellServer,为了减少以后的维护,将这个服务设为自动。
用配置文件的方式在多台机器上启动,纯文本配置文件的格式如下:
exe<可执行文件的全路径及名称>[可选参数]
[hosts可执行文件的全路径及名称]
<主机名2>#n2[可执行文件的全路径及名称] <主机名3>#n3[可执行文件的全路径及名称] ……
其中,n1、n2、n3表示在对应机器上启动的进程数,若主机后的 [可执行文件的全路径及名称] 不填,则默认使用exe那一行所指定的文件;若每台主机都独立地列出可执行文件的全路径及名称,则exe那一行的内容也可空白。
1.3 并行方案
本文在PC网络中实现上述过程时采用了客户机/服务器模式 (Client/Server Mode)[2]。 客户机/服务器模式是网络通信中使用的主要的相互作用模型。可以这样来说,服务器是提供服务的软件或进程,而客户机则是接受服务的软件或进程。
根据客户机/服务器模型的特点,我们可以安排每个客户机进程 (一台PC机运行1到2个客户机进程)负责一个子区域的计算。客户机在迭代若干步后,首先要把一些相关的交界面信息传给服务器进程,然后服务器会根据Neumann条件得到新一轮的交界面信息,最后服务器会把这些新得到的信息传给相关的客户机。
2 具体算例[3-6]
算例一:方形空腔二维层流驱动流。
(1) 物理模型
图1所示为带移动顶盖的方形空腔二维层流驱动流。雷诺数Reynolds分别取100和1000。

图1 方形空腔二维层流驱动流
(2) 区域划分
将方形空腔计算区域平均分为上下两块,其生成的网格图如图2所示。

图2 方形空腔网格图
(3) 计算结果
图3、图4所示为采用D-N分区计算所得的方形空腔内二维层流驱动流的流线分布图。

图3 方形空腔网格图 (Re=100)
算例二:90°弯管内二维流动问题。
(1) 物理模型
图5为90°弯管示意图。入口速度取抛物线分布, Reynolds数取790,出口条件按局部单向化处理。
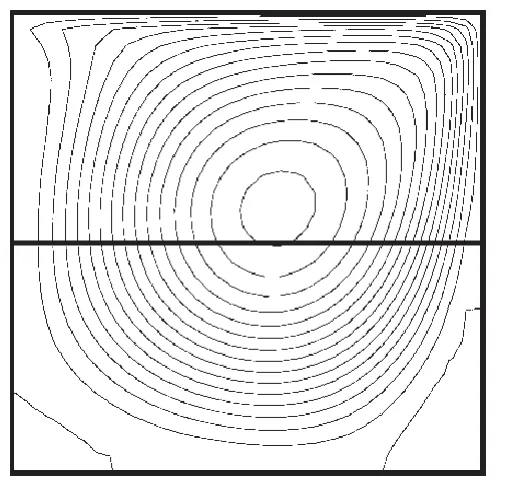
图4 方形空腔网格图 (Re=1000)

图 5 90°弯管
(2) 区域划分
将整个计算区域分成3块。其中,入口段部分网格大小为19×7,中间部分网格大小为19×10,出口段部分网格大小为19×7。90°弯管网格图如图6所示。

图6 90°弯管网格图
(3) 计算结果
图7为90°弯管内速度矢量图。
表1和表2对比了单机求解和多机并行求解的效率。

图7 90°弯管内速度矢量图

表1 方形空腔内分区并行计算的并行效率

表2 90°弯管内分区并行计算的并行效率
以上两个算例是使用区域分解算法对二维流动问题进行数值模拟,从中我们也可以验证该算法具有很好的物理真实性和良好的区域耦合性,证明用D-N算法来实现流场的分区数值计算是可行的。可以看出,使用区域分解法在MPI环境下并行求解二维流动问题,有较高的加速比和较好的并行效率。其计算时间也远低于同规模问题的单机串行计算时间。说明使用区域分解法在基于MPI网络的个人微机并行环境下,对求解流动问题有着很好的效果和前景。
[1] 郁志辉.高性能计算并行编程技术 [M] .北京:清华大学出版社,2001.
[2] 陆霄露.基于PC网络求解复杂三维流动的分区并行方法 [D] .上海:上海交通大学,2003.
[3] 陶文铨.计算传热学的近代进展 [M] .北京:科学出版社,2000.
[4] 周力行.湍流气粒两相流动和燃烧的理论与数值模拟[M] .北京:科学出版社,1994.
[5] 蒲砢.关于气固两相流数值计算模型的探讨 [J] .重庆建筑高等专科学校学报,2000,10(4):1-4.
[6] Patankar SV.郭宽良译.传热和流体流动的数值方法[M] .北京:科学出版社,1984.
