多语料库中汉语四字格的切分和识别研究
2013-10-15徐润华曲维光陈小荷王东波
徐润华,曲维光,陈小荷,王东波
(1.金陵科技学院人文学院,江苏 南京210038;2.南京师范大学 计算机科学与技术学院,江苏 南京210046;3.南京师范大学 文学院,江苏 南京210097;4.南京农业大学 信息科学技术学院,江苏 南京210095)
1 前言
“四字格”这个术语最早由陆志韦先生[1]提出,是指由四个汉字组成的一种独特语言格式。在汉语言文学发展的历史中,四字格的形式起着非常重要的作用,四字格形式在语音、语法、构词、语用、修辞等方面都对汉语产生了深刻的影响。四字格不仅在字数、结构、韵律等方面有着独特的优势[2],它还有着深厚的文化土壤,从老子的“千里之行,始于足下”到孔子的“学而不厌,诲人不倦”,名人名言多见四字警句。
四字格结构的能产性和派生性极强,利用四字格派生出新词语的模式,在汉语言发展史上一直起着积极的作用,推动着汉语的发展。直到今天,利用四字格模式创造出的新词数量在现代汉语词汇中仍然呈上升趋势,四字词语的数量有增无减。杨晓黎[3]通过统计得出结论认为“在新词语中双音节优势已经让位于四音节词语了”。在信息化迅猛发展的今天,可以很容易地获取大规模语料,对四字格结构的研究不能仅仅局限于文献和理论,而应该将目光更多地投向语料库,投向大量真实文本中的四字格。
语料库中的四字格所面临的最大问题是,同一个词在文本中是否保持了相同的切分形式。如果不能很好地解决四字格的切分和识别工作,会给汉语的自动分词工作带来麻烦。目前,自然语言处理尚缺乏对汉语四字格的专门性研究,本文希望通过对语料库中汉语四字格的研究,给自然语言处理领域的自动分词工作,以及在自动分词基础上进行的语料深加工、句法分析、话语理解等后续任务带来有益的帮助。
2 语料库中四字格的分类
不同语料库中的四字格由于语料来源、语言风格、切分原则等方面的差异而呈现出多样性和特殊性。为了能更好地揭示出语料库中四字格的全貌,引入多个语料库来进行四字格的研究十分有必要。本文研究所选用的分词语料库是Sighan中文分词竞赛的部分训练语料①语料来源网址:http://www.sighan.org:北京大学《人民日报》分词语料库、微软亚洲研究院中文分词语料库、中国国家语委中文分词语料库这三个简体中文分词语料库。选取三个不同的语料库来进行四字格的分类工作,可以更全面地考察多语料库中的四字格并在此基础上进一步比较各个语料库之间的四字格切分特点。
2.1 语料库中四字格的筛选
语料库中的四字格,通常指的是那些结构稳定、意义凝固、可独立运用且长度为四的词语。因此在分词语料库中,四字格最直观的形式特征就是它的长度。但长度为四的分词单位,并不一定都是四字格。其中包含了相当数量的“非四字格”却长度为四的分词单位。这些“非四字格”分词单位主要由数字串、命名实体等构成。例如,数字串或含数字串的词串:“七八千元”、“五十余篇”;人名和地名,尤其以音译词居多,如“莎拉波娃”、“巴勒斯坦”;机构名如“顺天集团”、“西康铁路”等。这些四字长的分词单位是不能归入到四字格范畴中去的。这里需要说明一下成语。成语多是四字格[4],它结构稳定基本不存在切分不一致的情况。而且作为一个封闭的类别,对成语进行识别也较为容易。基于成语的结构稳定、容易识别的特点,为了更直接地针对开放性、派生性强的四字格结构进行研究,成语也没有被纳入本文研究的四字格范畴之内。
通过筛选、去除上述成分之后,北京大学《人民日报》1998年1月分词语料库中四字格筛选后数量为2830条;微软亚洲研究院中文分词语料库中四字格筛选后数量为2739条;中国教育部国家语委分词语料库中四字格筛选后数量为1999条。
2.2 语料库中四字格的分类方法
周荐[5]把四字格分为“陈述式”、“偏正式”、“述宾式”等八种类型。本文提出的四字格的分类方法,并不单纯从语法层面去分析四字格的结构,而是更偏重于为计算机处理四字格切分、识别任务而服务的一种分类方法,所以对四字格结构内部的组成关系并不十分关注。分词语料库中的四字格,按照四字格的构词模式,大致可以分为“词语构成型”、“结构构成型”、“固定结构型”这三种类型,如表1所示。
词语构成型,指的是那些内部构成方式简单易于观察,在语料库中常常切分成两种稳定切分形式的四字格,例如,“工薪阶层”,或者切分为一个完整的四字格结构,或者就是切分为“工薪 阶层”的形式。词语构成型还可以细分为“‘2+2’式”和“‘3+1’或‘1+3’式”,两者都是从音段组合规律上对四字格所进行的划分[6]。

表1 四字格的构词模式
结构构成型四字格的内部结构复杂,在语料库中切分形式不稳定,例如,“各负其责”,可能出现“各负 其责”的形式,也可能出现“各 负 其 责”的形式。当四字格被切分成形如“锅 碗 瓢 盆”这样处于同一层次的四个单音节词时,则称之为“四字骈语”[7]。词语构成型的四字格内部全部是由词构成,而结构构成型的四字格内部不全是由词构成,它可能是“结构”+“词”的形式,例如,“大饱耳福”;也可能是“结构”+“结构”的形式,例如,“笔简意深”,这种前后结构形式对称的四字格也称为并列式四字格[8]。
固定结构型,指的是用法固定结构稳定不可变的一些四字格,常见于一些表示转折或条件关系的四字格,例如“不管怎样”、“也就是说”等。
3 语料库中四字格的切分
3.1 四字格切分不一致的问题

图1 四字格切分不一致类型的对应关系
分词语料库中的切分不一致现象一直是中文信息处理领域的难点。四字格的切分不一致现象是整个分词语料库中分词不一致研究工作的重要组成部分之一。四字格也属于分词单位,冯志伟[9]认为:“四字成语和习惯用语,各成分意义结合紧密,难以拆开,不切分”,但是在实际的分词过程中,四字格往往不被切分成一个完整的分词单位,而是被“切碎”了:例如,“倾而不倒”这个四字格,在语料库中既出现过“倾_而_不_倒”这样的切分实例,也出现过“倾_而_不倒”这样的切分实例。切分不一致大大降低了分词的精度,影响了自然语言处理的后续工作。切分不一致问题若得不到较好解决,将会对汉语自动分词、分词规范统一、语料库建设等方面造成影响。
除了成语之外,没有被词典收录的四字惯用语、习语,都可以算作多词表达的一种[10]。多词表达需要从整体上把握多词合成后所表达的意义,而四字格切分不一致的现状会给多词表达的相关研究带来困难。
3.2 四字格切分不一致的类型
对于一个四字格而言,只要它在分词语料库中没有被切分成一个四字长的分词单位,就认为它被切碎了。在理论上,切碎了的四字格可以是各种各样的形式,但无论这些四字格的切分不一致结果多么纷繁复杂,最终都可以归结到三种四字格的切分不一致类型中:被切分成两个词(2型四字格)、被切分成三个词(3型四字格)、被切分成四个词(4型四字格)。一个四字长的分词单位,所有可能的切分形式,都包含于这三种切分不一致类型中。
分词语料库中四字格的三种切分不一致类型,和本文前述的从四字格构词模式角度提出的四字格分类体系是对应的。2型四字格对应的是词语构成型四字格,3型四字格和4型四字格对应的是结构构成型四字格,其中3型四字格对应于结构构成型四字格中的“‘结构’+‘词’式”。具体的对应关系如图1所示。
3.3 语料库中四字格切分不一致的提取实验
四字格切分不一致的提取工作,就是要找出语料库内部和语料库之间某个特定四字格所有不同的切分形式。例如,北京大学语料库中有这样一个四字格:“惩恶扬善”,在别的语料库中出现了“惩_恶_扬_善”和“惩恶_扬善”两种切分形式,切分不一致提取工作就需要把这两种不同的切分形式都找出来。为了能够发现所有的切分不一致情况,提取算法需要同时检索这六个不同的切分串:“惩恶_扬善”、“惩_恶扬善”、“惩恶扬_善”、“惩_恶_扬善”、“惩恶_扬_善”、“惩_恶_扬_善”。这其实就包含了“惩恶扬善”这个四字格所有可能的切分形式。
(1)实验方案及数据
本实验考察了三个语料库之间的四字格切分不一致数据,同时也对三个语料库各自内部的四字格切分不一致数据进行了统计。考察了四字格切分不一致的三种类型(2型、3型、4型四字格),以及每种类型的类别数(types)和实例数(tokens)这两个统计量。统计数据如表2和表3所示,数据示例如表4所示。
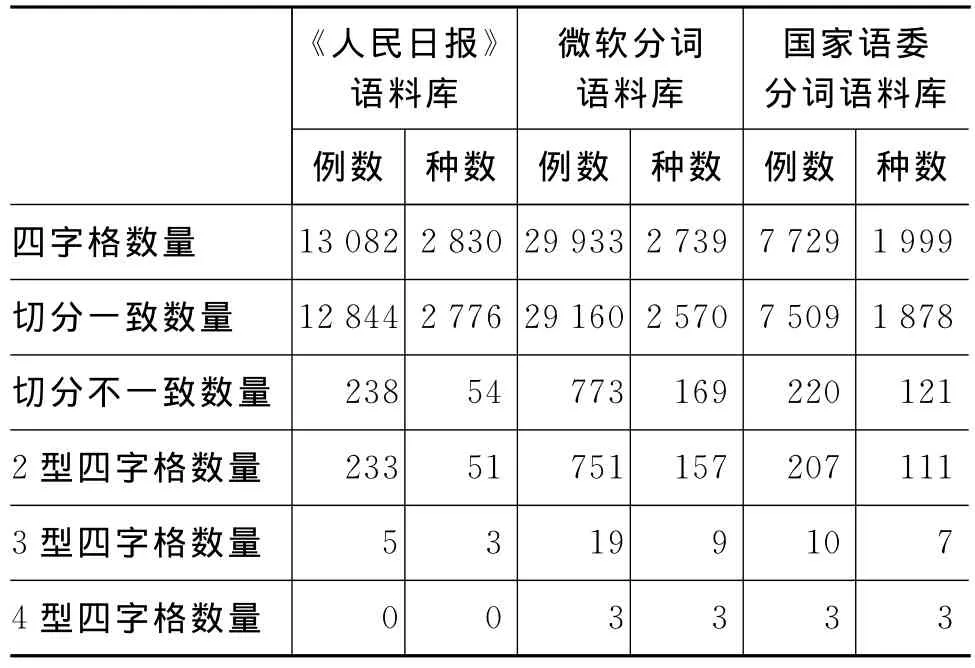
表2 分词语料库内部的四字格切分不一致数据

表3 分词语料库之间的四字格切分不一致数据
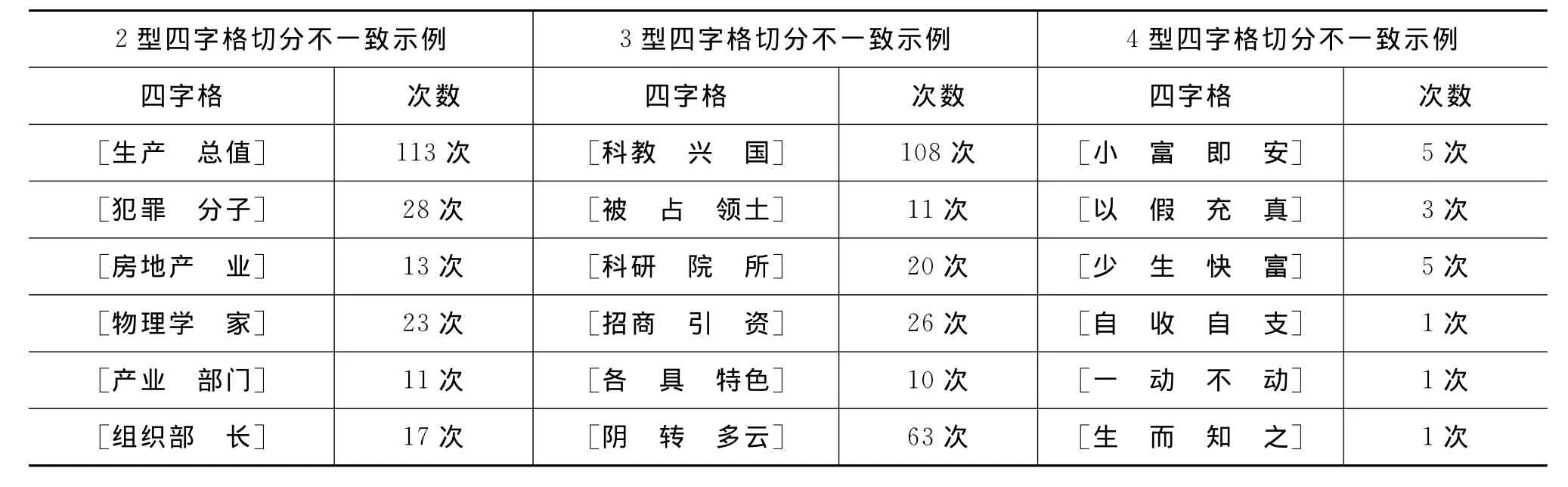
表4 语料库中四字格切分不一致的数据示例
(2)实验分析
观察数据可以看出,三个语料库内部的四字格切分不一致数量要远少于三个语料库之间的四字格切分不一致数量。例如,国家语言文字工作委员会语料库内部的四字格切分不一致例数仅有220例,而语委语料库和微软语料库之间的切分不一致例数却多达7055例。这也和直觉相符:一个语料库内部的切分方式和切分原则相对稳定,而不同语料库之间的切分方式和切分原则差异较大。
在进行分词语料库之间四字格切分不一致的比较时,四字格切分一致数量和切分不一致数量的比例是衡量两个语料库之间四字格切分相似程度的一个重要依据。通过计算“四字格切分不一致数量/四字格切分一致数量”的值可以发现,《人民日报》语料库和国家语委语料库之间的这个比值为(311+445)/(845+806)=45.8%,是所有语料库之间的最低值,说明这两个语料库之间的四字格切分方式最接近;《人民日报》语料库和微软亚洲研究院语料库之间的这个比值为(855+615)/(1041+960)=73.5%,是所有语料库之间的最高值,说明这两个语料库之间在四字格的切分问题上“分歧”最多。
4 语料库中四字格的识别
分词语料库中的四字格分为两类:一类是未被切碎、可以利用词长或者词性信息直接找到的、形如“_茶饭不思_”形式的四字格;另一类,是被切碎成若干更小长度的分词单位、无法在语料库直接找到、形如“_如_诗_如_画_”形式的四字格。四字格识别研究所要针对的正是第二类四字格。
被切碎了的四字格又分为两种,一种是在某个语料库中被切碎,但在其他语料库中未被切碎的四字格;另一种是在各个语料库中都被切碎,但确实应当被切分为一个分词单位的四字格。对于前者的识别,只需通过建立一个简单的四字格实例词表即可实现;而对于后者,我们无法在语料库中找到匹配实例,要识别出这些四字格,就必须要借助于统计模型来训练大量数据、机器学习四字格的结构特征并以此对四字格进行自动标注。
4.1 CRF的训练语料获取
条件随机场(Conditional Random Field,CRF)是一种用于在给定输入节点值时计算指定输出结点值的条件概率的无向图模型,是一个基于统计的序列标注和分割的方法[11]。目前,CRF广泛应用于自然语言处理的各个方面,特别是在序列化标注例如词性标注任务中,CRF表现优异。我们可以把四字格的识别过程想像为一种特殊的词性标注:给每个分词单位一个标记,该标记用于表明分词单位是或者不是四字格的成分之一。把连续出现的有四字格标记的分词单位找出来,当它们的词长相加正好为四的时候,就可以认为这是一个四字格。
CRF模型需要大量做过人工标注的语料用于训练。单靠人力去发现语料库中被切碎了的四字格并对其进行四字格信息的标注,是一项极其耗时耗力的工作。一种可行的方法是,利用不同语料库之间四字格的切分不一致数据来实现四字格训练语料的自动获取。例如,有语料库A和B,在语料库A中可以找到四字格“为国分忧”,而它在语料库B中则被切成了“为_国_分忧”,那么“为_国_分忧”这个切分实例就可以成为CRF模型训练语料的一部分。采用这种思路来自动获取训练语料,上文关于四字格切分不一致的统计结果就可以直接为CRF模型的训练过程提供大量数据。
俞士汶[12]提出,形如“调查_研究”、“总结_经验”这样的“四个字短语,通常应切分”。2型四字格均由两个词语构成,结构方式上趋近于词组,在语料库中的切分不一致情况多属于切分粗细的问题,而非切分正误的问题。因此,本研究的四字格识别工作只把3型四字格和4型四字格作为识别对象。去除2型四字格的切分不一致结果,只保留切分成3型和4型四字格的切分不一致结果,本文研究选取的三个分词语料库中共有2742例四字格切分不一致数据。如表5所示。
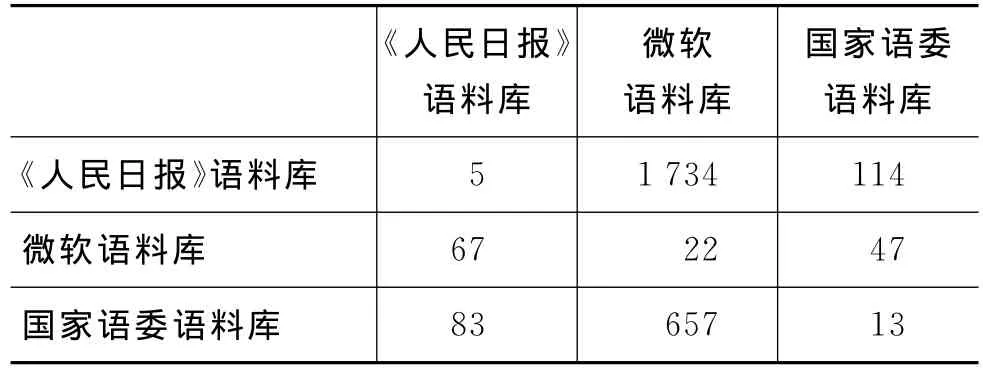
表5 切分成3型和4型的四字格切分不一致数据(例数)
除了四字格本身,还需要提供四字格的上下文语境信息用于CRF模型训练,即真正用于CRF模型训练的,是包含了四字格的句子,而不是单独的四字格本身。对应于2742个四字格切分不一致实例,用于CRF模型训练的包含四字格的句子也是2742个。
4.2 CRF的特征列和模板定制

图2 四字格的特征列
按照CRF模型的语料格式要求,针对3型四字格和4型四字格这两种识别对象,给出两种四字格特征列,如图2所示。图中的第一列是文本,第二列是词性标记和词长信息,第三列是四字格标记。“none”表示该词不是四字格成分,“head_3”、“body_3”、“tail_3”或“head_4”、“body1_4、body2_4”、“tail_4”分别表示该词是四字格成分的首部、中部、尾部,后面的数字“3”或“4”表示该四字格被切碎成了3个或者4个部分。
CRF模型是一个通用工具,用户需要定制自己的特征模板。模板的基本格式为%x[行、列],它用于确定输入数据中的一个词例。行,表示%x相对于当前词例的行数;列,表示%x在列上的绝对列数。以训练语料中的“阳光/n走遍/v它/r不/d为/p人/n知/v的/u另/r一/m 面/n”这句话来示例特征模板,假设当前词为“为”,本研究所采用的CRF特征训练模板如图3所示。

图3 特征模板示例
4.3 基于CRF模型的四字格识别实验
基于CRF模型的识别实验采用的训练语料是北京大学《人民日报》1998年1月语料、微软亚洲研究院中文分词语料、中国国家语委分词语料。封闭测试语料选用的是北京大学《人民日报》1998年1月语料,开放测试语料选用的是北京大学《人民日报》1998年2~6月语料,实验结果如表6和表7所示。

表61998年1月至6月北京大学《人民日报》语料库中的四字识别结果

表71998年1月至6月北京大学《人民日报》语料库识别结果中的3、4型四字格分布
作为开放测试语料,1998年2月至6月的《人民日报》语料并未参与到四字格切分不一致数据的获取过程中,但利用CRF模型对其进行的四字格识别实验仍然取得了93%以上的正确率,甚至部分超过了封闭测试的效果;表7列出了半年《人民日报》语料中识别出的3、4型四字格分布,可以看出识别出的被切碎四字格的数量较多、分布平均,3型四字格和4型四字格之间的比例也趋于平衡没有明显的偏重,这些都表明了,利用四字格切分不一致数据并辅以CRF模型来识别四字格的方法能行之有效地解决多语料库中四字格的识别难题。
识别得到的四字格中,有些可以在北京大学、国家语委、微软三个训练语料库中找到完全匹配的实例,例如,
持续不断 从头做起
催人泪下 多党合作
凡此种种 蜂拥而来
干旱少雨 公布于众
但这些四字格只占识别得到的2229例四字格中很小的一部分,占比最多的国家语委语料库也只有3.8%;绝大多数识别得到的四字格在三个训练语料库中都找不到与之完全匹配的实例,换言之都被切碎了,例如,
冰封雪盖 官去室空
船推浪移 肩扛手提
车毁人伤 肩扛背驮
房倒屋塌 以短养长
这部分识别出的四字格是无法通过查找匹配实例来识别的,也进一步验证了本研究引入统计模型参与识别工作的必要性。相关数据详见表8。

表8 四字格识别结果在三个语料库中是否有匹配实例的分布数据
5 结语
本文的研究对象是语料库中的四字格,本文着重对“四字格的分类”、“四字格的切分”、“四字格的识别”这三个问题进行了深入研究。如图4所示。

图4 四字格研究框架
通过抽取不同分词语料库中的四字格并进行筛选、分类,本文解决了第一个问题;利用筛选、分类的结果,在不同语料库中寻找它们所有的切分形式,分析归纳这些四字格切分形式上的特点,本文解决了第二个问题;利用不同语料库间四字格的切分不一致结果,在分词语料库中实现了对四字格的识别工作,至此本文解决了第三个问题。通过实验表明,多语料库中的四字格识别正确率可以达到93%以上。
本研究依然有许多尚未完成或亟需改善之处:四字格分类体系仍显粗糙;研究所使用的分词语料库规模有待扩大;四字格资源需要继续补充和完善。下一步工作考虑引入语法、语义方面的知识来进一步提高四字格特别是可派生型四字格的识别效果。
[1]陆志韦.汉语的并立四字格[J].语文研究,1956,(1):45-82.
[2]马国凡.四字格论[J].内蒙古师范大学学报,1987,(3):51-58.
[3]杨晓黎.四音节新词语及其成因[J].江淮论坛,1996,(4):100-103.
[4]莫彭龄.“四字格”与成语修辞[J].常州工学院学报,2003(3):54-58.
[5]周荐.论四字语和三字语[J].语文研究,1997,(4):26-31.
[6]鞠君.四字格中“1+3”音段和“3+1”音段组合规律初探[J].汉语学习,1995,(1):37-39.
[7]安华林.“四字骈语”初探[J].信阳师范学院学报,2001,(1):79-82.
[8]时秀娟.浅析汉语并列式四字格结构及其理据性[J].莱阳农学院学报,2001,(3):44-47.
[9]冯志伟.确定切词单位的某些非语法因素[J].中文信息学报,2001,(5):8-14.
[10]刘荣、王弈凯:2011:《利用统计量和语言学规则提取多字词表达[J].太原理工大学学报,2011,(3):133-137.
[11]Lafferty,J.McCallum,A.Pereira,F.,Conditional random fields:Probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the 18th International Conference on Machine Learning(ICML 2001),2001:282-289.
[12]俞士汶,段慧明,朱学锋,等.北京大学现代汉语语料库基本加工规范[J].中文信息学报,2002,(5):49-64.
