基于Hadoop的云计算算法研究
2013-09-25辛大欣
辛大欣,屈 伟
(西安工业大学 陕西 西安 710021)
随着信息技术的不断提高,信息和数据呈现几何级的增长,大量的数据需要处理。在这种环境下,单点存储的问题已逐步暴露。
区域问题:单点存储,使用户在外出需要克服相当大的网络延迟访问服务。同时,为了方便维修,升级等问题使得存储数据选择的位置变得相对困难。
灾难恢复问题:当系统崩溃后必须被恢复时,如果数据存储备份被破坏将导致灾难性的后果。假如盲目地支持多个备份,不仅本身就是一种资源浪费,而且多个数据备份之间的一致性和可用性也是一个棘手的问题。
可扩展性问题:单点存储在可扩展性方面有很多问题。每个额外需要增加的功能或者服务都需要重新对硬件软件的结构进行重新设计和配置。同时对于硬件的更新也会带来巨大的麻烦。
管理费用:单点存储需要很多额外的管理开销,如机房,服务集群功率消耗,以及专门的数据管理开销和人员的培训费用。据统计仅数据中心的碳排放量占碳的总排放量百分之二,排放量达到约35 000 000吨每年。
有些公司电力成本每年超过硬件投资。在电力分配中,服务器设备占52%的总能源消耗,冷却系统和电力系统各38%和9%,只有1%的照明系统。面对这种严峻的形势下,构建节能绿色数据中心已成为焦点。
云计算在节约能源方面的特点正好符合了”低碳节能”的思想。
1)通过使用云计算,提高了设备的利用资源,减少数据中心能耗,同时避免经济损失造成的闲置设备。云“自我服务”的计算架构将大大降低成本和管理,可以节省资源。
2)使用公共云服务,企业只需购买云计算服务,根据自己的需要,不需要购买电脑设备,尤其是不需要购置管理服务和数据中心的服务器,从而达到节约能耗的目的。
3)使用云桌面终端接入,没有笨重的机箱和风扇声。减少功率消耗,减少热量,每个用户平均耗电量小于25瓦,大大降低了能源消耗,每年可节省近70%的电力供应。
从上面可以看出云计算可以解决目前单点存储的局限性以,而且对于资源的节约有很好的效果。下面对于云计算中的3种方法进行研究。
1 在Hadoop云计算框架中的调度算法
1.1 FIFO算法
FIFO调度算法中所有的用户任务都被提交到一个队列中,然后由TaskTracker按照任务的优先级(比如提交时间的先后顺序)选择将被执行的任务。该算法的具体实现是Task Queue Sub Task Scheduler。具体而言,当一个 Sub Task Tracker工作的游刃有余,期待获得新的子任务的时候,Task Queue Sub Task Scheduler会按照各个任务的优先级,从最高优先级的任务开始分配子任务。而且,在给SubTaskTracker分配子任务时,还会为其留出余量,已被不时之需。这样的策略,基本思路就是一切为高优先级的任务服务,优先分配不说,同时还需保留有余力以备不时之需。
FIFO调度算法调度任务的基本原理。

图1 FIFO算法原理图Fig.1 FIFO algorithm principle diagram
FIFO易实现,且整个集群的调度开销较少。但是在FIFO调度算法中优先级不支持抢占,这就造成了优先级低的一些任务被阻塞的现象。FIFO调度算法最大的缺点是在存在大任务的情况下小任务响应时间较差,且忽略了不同用户不同任务间的需求差异,造成平台的整体性能和系统资源的利用率不高,甚至影响任务的执行。
1.2 公平调度算法
公平调度算法是由Facebook提出的一种新的任务调度算法,Facebook的初衷是让Hadoop的MapReduce计算框架能够更好的处理不同类型的任务并行执行的需求。
1)设计思想
公平调度算法的基本思想是最大化的保证系统中的任务平均分配系统的资源。当系统中只有一个任务执行时,它将独占整个集群并使用所有的计算资源。而一旦有其他的任务被提交,就会有 SubTaskTracker被释放并分配给新提交的任务,以保证所有的任务都能够获得大体相同的计算资源量。这就使得短任务能够在合理的时间内完成,同时又不会有长任务长期处于饥饿状态。
公平算法中的任务运行情况如图2所示。
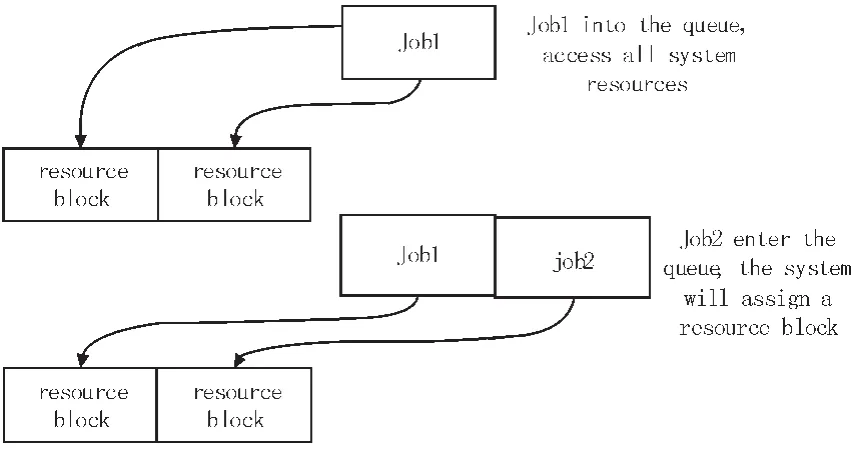
图2 公平调度算法原理图Fig.2 Fair scheduling algorithm principle diagram
由图2可以很明显地看出,与 FIFO算法相比,在有两个任务Job1和Job2在Hadoop集群中运行时,该算法能够让Job2在Job1未全部完成的情况下使用Job1完成部分空出来的SubTaskTracker,而不是像FIFO那样必须Job1全部完成后才能运行Job2。
2)具体实现
在公平算法中,用户提交的任务被进一步组织为能够公平共享资源的任务池,任务池中的任务可以平分那些分配给所在任务池的资源。在缺省情况下,公平调度算法会为每位用户建立一个单独的任务池,这使得所有用户都能够获得等量的资源份额而不论他提交了多少任务,这也解决了Facebook案例中难以平衡的不同种类用户任务的计算需求问题。当然,任务池的设定也可以根据其他指标,例如用户的Unix组属性等。
在实际应用中,任务和任务池通过 PoolManager类被赋予不同的权值并以此为依据获得相应比例的资源额度。该算法虽不再是严格的平均分配,但却更符合现实中的应用环境,使系统可以根据子任务的重要程度等各种因素合理的为不同用户的不同任务合理的分配系统资源,这有利于减少交互型任务的响应时间。在公平调度算法的具体实现中,有两个方面是关键:一个是如何计算每一个任务的公平份额;另一个就是当有SubTaskTracker空闲时应该选择执行哪个任务。公平调度算法的实现类图如图3所示。
3)公平调度算法优缺点
公平调度算法提供了最小共享额度方法。它支持任务分类调度,使不同类型的任务获得不同的资源分配,从而提高了服务质量(QOS)和动态调整并行数量,它使任务能够充分利用系统资源,提高系统的利用程度。它克服了FIFO算法上简单,不支持抢占,资源利用率低的缺点,但是它并没有考虑当前系统各节点的负载水平和实际的负载状态,导致节点实际负载不均衡,从而影响了整个系统的响应时间,而且配置文件配置的好坏直接影响到整个系统的性能。
1.3 计算能力调度算法(Capacity Scheduler)
计算能力调度算法是由Yahoo提出的任务调度算法,它提供了类似公平调度算法的功能,但在设计与实现上两者存在着很大差别。
1)设计思想
计算能力调度算法的思路是为各个队列中的任务模拟出具有指定计算能力的独立的 Hadoop集群资源,而不像公平调度算法那样试图在所有的任务间实现公平的资源分享。计算能力调度算法任务运行情况如图4所示。
2)具体实现
在计算能力调度算法的具体实现中,最关键的也是如何挑选合适的任务去执行。它在每个队列中的调度策略是采取基于优先级的FIFO算法。计算能力调度算法是非抢占式的。为了使同属于同一用户的任务不出现独占资源的情况,该算法对队列中同一用户提交的任务能够获得的资源百分比进行了强制限定。另外,计算能力调度支持内存密集型应用,能够有效地对Hadoop集群的内存资源进行管理。计算能力调度算法的实现类图如图5所示。
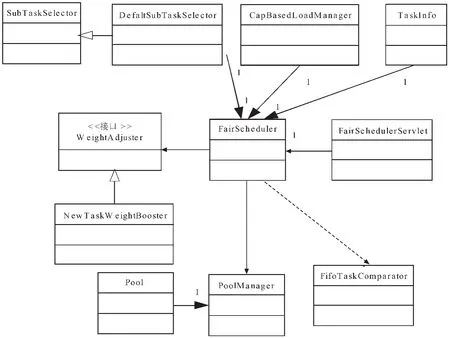
图3 公平调度算法类图Fig.3 Fair scheduling algorithm for Graphs
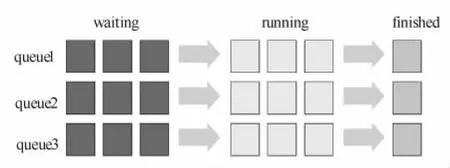
图4 计算能力调度算法任务运行图Fig.4 Calculation of capacity scheduling algorithm task operation diagram
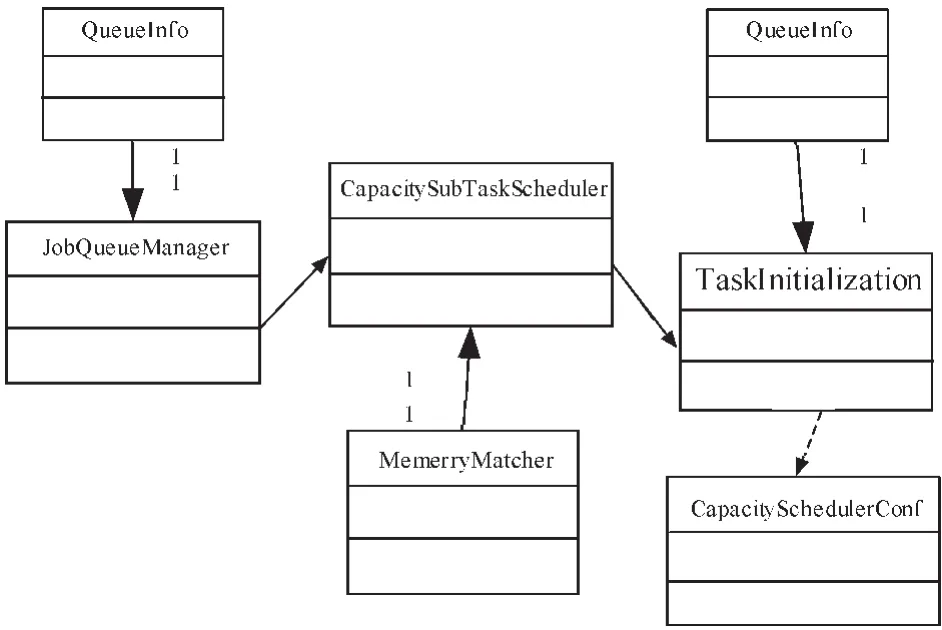
图5 计算能力调度算法的实现类图Fig.5 Calculation of capacity scheduling algorithm of the graph
3)计算能力调度算法优缺点
计算能力调度算法克服了FIFO算法简单而且资源利用率低的缺点,它支持多任务并行执行提高了资源利用率,通过动态调整资源分配从而提高了任务执行效率,但是计算能力调度算法中队列设置和队列组无法自动进行,用户需要了解系统信息进而对作业进行队列设置和队列选组,在大型系统中,这将成为提高系统整体性能的一大瓶颈。
2 总 结
通过在Hadoop平台下的分组任务试验结论,随着预算和截止时间增加,FIFO算法的任务完成数总体是增加的,但不是绝对递增。第4组比第3组完成的任务少,第6组比第5组完成的任务少,出现了预算和截止时间增加,任务完成数反而减少的现象。这主要是由于在无法全部完成任务的情况下,预算和截止时间的限制会对选择调度任务产生影响,以致整个调度完成后会产生任务完成数目减少的情况出现。比较得出,Fair scheduling,Capacity Scheduler算法随着预算和截止时间的增加,完成的任务总数逐渐递增。对于每组预算和截止时间参数,Capacity Scheduler算法的性能要好于Fair scheduling和FIFO两个算法,约有22.0%和10.6%的性能提高。
3 结 论
通过结合hadoop云存储平台下的算法模拟,说明在3种算法随着任务数逐渐增加Capacity Scheduler算法的性能要好于Fair scheduling和FIFO两个算法。验证结构如同初期预想,随着任务总数以及任务完成周期要求的不同,在云存储系统中选择适合用户算法对于用户完成任务的效率有很大的提升。
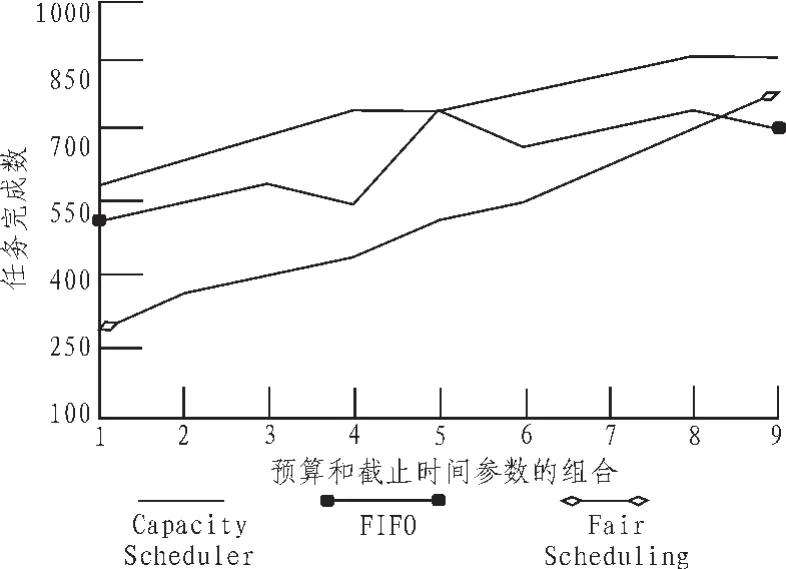
图6 试验结论效果对比图Fig.6 Effect comparison of test results
[1]刘晓茜.云计算数据中心及其调度机制研究 [D].北京:中国科技技术大学,2011.
[2]刘鹏著.云计算[M].北京:电子工业出版社,2010.
[3]熊乐.Google集群系统技术综述[J].中国科技信息,2009(9):126-127.
XIONG Le.Google cluster system technique in China[J].science and technology information,2009(9):126-127.
[4]胡文波,徐造林.分布式存储方案的设计与研究[J].计算机技术与发展,2010(4):65-68.
HU Wen-bo,XU Zao-lin.Design and research on distributed storage scheme[J].Computer Technology and The Development,2010(4):65-68.
[5]周姝.云计算之浅见[C]//2011国际信息技术与应用论坛论文集,2011.
[6]黄晓云.基于HDFS的云存储服务系统研究[D].大连:大连海事大学,2010.
