相似度技术在资料信息化中的应用研究
2013-09-25张德龙
张德龙,杨 鹏
(内蒙古气象信息中心 内蒙古 呼和浩特 010051)
我国有器测以来,积累了大量的观测气象资料,是气候研究、决策规划的珍贵资源。其大部分以纸质形式记录,大量观测资料均存储在各类报表或自记纸上。为了对历史资料的进一步应用,需要把报表上的资料录入成电子数据。然而在录入过程中可能存在同一台站不同年代,或不同台站间数据相互拷贝的情况。在这种情况下,如果能通过计算机自动、快速地在大量录入文件中检查哪些部分是相同的,就时间而言可完成人工几乎不可能完成的任务,然后在选出的文件中再进行人工参与,大大的减少了审核人员的工作量。
目前,内容相似度度量的技术主要有:属性计数技术和结构度量技术。由于属性计数技术没有考虑文件的结构,只是统计了文件中一些属性信息,所以随着文件复制种类的不断提高(如从不同文件中各选一些组合成文件),其度量结果的准确性就会下降。1976年,Halstead[1]首先提出了用属性计数的方法检测文件的拷贝问题,1977年,Ottenstein[2]使用Halstead的方法设计了最早的自动文件拷贝检测系统。结构度量技术考虑了文件的结构特征,度量结果比较真实地反映了文件之间的相似性。 Plague[3],Sim[4],YAP3[5]等拷贝检测系统无一例外的都使用了结构度量技术。由于国外大部分成功的拷贝检查系统都采用了结构度量技术,所以本研究结构度量技术。首先对文件作预处理,去掉对相似度度量结果没有影响的部分,接着扫描经预处理后的文件,并对其作简单的语法分析,将其转换为表示文件结构的标记字符串,再通过特定的匹配算法对得到的字符串作比较,并给出它们之间匹配程度的数值表示,以此作为文件数据相似度的度量值。该值越大说明文件数据越相似,存在拷贝的可能性也越高。
1 相关算法及技术介绍
文件相似度度量技术中,结构度量技术是通过比较文件的结构来度量文件数据间的相似度。结构度量技术中,首先将源文件转换为标记串序列,然后通过字符串匹配算法比较得到的标记串,并根据匹配结果给出文件数据相似度的数值表示。这里用到的字符串匹配算法称为结构比较算法,本研究也将采用该算法来匹配表示文件结构的标记串。在讨论Running Karp-Rabin Greedy String Tiling算法。算法中用到的几个基本概念:1)文本串(也称主串),指要在其中查找子字符串的较长的字符串,用T表示;2)模式串(也称模式),指需要在文本串T中查找的字符串,用P表示。通常,文本串T是较长的字符串,而模式串P是较短的字符串。
1.1 Running Karp-Rabin Greedy String Tiling
1.1.1 算法描述和伪代码
Running Karp-Rabin Greedy String Tiling算法是基于非常有名的字符串匹配算法Karp-Rabin[6]。受基于映射(散列)排序技术的启发,1987年图灵奖获得者Karp教授和著名学者Rabin教授合作,在IBM研究与发展杂志上介绍了一种直观、快速的Karp-Rabin串匹配随机算法(简称KR算法)。算法十分简单,但是却非常有效。该算法的基本思想是把长度为m的模式串看作是一个键(key),而把文本串中每m个字符也看作是一个键。如果能够定义一个散列函数把这些键都映射为它们对应的散列值,那么显然只有那些与模式串具有相同散列值的文本字段才有可能与模式串匹配,这是一个必要条件。Karp和Rabin给出了在线性时间内计算散列函数的有效方法。
通过以下方法修改字符串匹配算法KR,RKR-GST算法扩展了原来的GST[7]算法:
不对整个模式串计算一个单独的散列值,而是对每一个长度为w从Pw到Pm+w-1未作记号的模式串的子串计算一个散列值。同样,计算未作记号从Tn到Tn+w-1文本串子串的散列值。前面已经提到,该计算可以在线性时间内完成。
比较上一步得出的每一个模式串和文本串的散列值。如果相等,表明两个子串可能匹配,接着通过逐个比较每一个标记来检查是否匹配。这样,利用映射表通过散列值的比较将时间复杂度从O(n2)减少到了一个常量时间。
这里的参数w被称为搜索长度,且在算法的每一次循环后将逐步减少,直到等于最小匹配长度。
以下给出了RKR-GST算法的最高层伪代码。该算法很简单,因为它是基于GST算法的,所以类似于Greedy String Tiling算法。算法的主要不同是scanpattern步骤,RKR-GST是在确定的大小上找到所有的最大匹配。

在RKR-GST最高层算法中,首先是给搜索长度赋了一个初值,这是该算法与GST算法之间的另一个不同点。算法的主要循环从scanpattern过程开始,这个过程返回w的一个新值。如果找到了一个较长的最大匹配,算法自动从一个等于新长度的搜索长度重新开始。否则,算法接着开始执行这样一个过程,该过程为找到的最大匹配中所有未作记号的标记作记号。这个作记号的过程是通过markstrings过程完成的。作记号过程结束后,如果w的值被更新为比最小匹配长度更小的新值,算法就结束了。否则,算法从w的这个新值开始继续执行。

以上是scanpattern过程的伪代码,这个过程的主要部分就是散列过程。scanpattern过程扫描文本文档中从Tn到Tn+w-1的文本串中未作记号的字符串并为其产生散列值。当这个过程执行完成后,会生成所有未作记号的标记的映射表,所有未作记号的子串的长度都等于w。随后,为每一个从Pm到Pm+w-1的模式串生成散列值,并将其与文本串的散列值作比较,即在前一步中产生的映射表中查找每一个模式串的散列值,如果找到了一个相等的,算法就试图扩展这个匹配。相等的子串(有相同散列值的标记串)的检测过程从模式扫描过程延期到了算法标记过程。推论结果显示,KR的散列过程很少发生冲突,且算法标记过程中逐个元素的匹配也很有效。这个过程返回找到的最大匹配的长度。
用于记录最大匹配的数据结构是双向队列。每个队列记录相同长度的最大匹配,队列列表的次序是按匹配长度递减排列。每个队列里用一个指针指向最近添加的最大匹配,因为很有可能下一个最大匹配的匹配长度与最后一个记录的相同或相近,因此可以很方便地被记录到该队列的最后或接近该队列的队列里。
以下描述了markstrings过程的伪代码。除了使用了一个比线性链表更合适的队列外,该算法使用了和GST算法相同的结构。此外,像前面讨论的一样,该过程中也作了相等字符串的测试。为了检查散列值相等的那些子串是否真正的相等,文件从scanpattern过程进入到了markstring过程,此外,散列值相等的子串通过逐个元素的比较后也不一定能保证是相等的字符串。

只要子串相等,算法就为属于它们的所有标记作上记号。与GST算法相比较,如果出现了封闭,则最大匹配的未作记号部分就被定义了。如果这个未作记号的部分大于等于搜索长度,则被记录进最大匹配列表里。这样做是为了确保未作记号的部分在markstrings过程中被选择并被作上记号。
1.1.2 KR散列值的计算
像前面讨论中多次提到的一样,散列值的计算能在常量时间内完成。Karp-Rabin算法是这样定义散列函数的[8-9]:假设文本串T与模式串P中出现的字符集合为Σ,设集合的大小为s,那么可以把字符串看作是一个s进制的数,也就是说,当模式串P=p1p2p3…pm时,则P可以数值化为:

此时,可以找到一个较大的素数q,定义P的散列函数为:
Hash(P′)=mod(P′,q)=mod(p1×sm-1+p2×sm-2+…+pm,q) (2)同理,对于文本串,也可以对其中长为m的一段执行上述操作,如果假设文本串为T=t1t2t3…tn,可以在其中找到一个整数 k,取 T 其中的 T(k)=tk+1tk+2tk+3…tk+m,对于这一段进行 s进制的数值化为:

同理如果往后移动一个位置,则有:

显然,T′(k+1)与 T′(k)满足这样的关系:
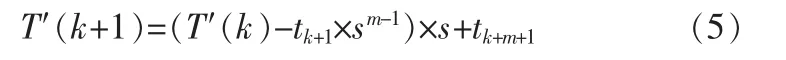
所以如果求得了 Hash(T′(k)),根据求模运算的性质,则右移一位得到的字符串子段满足:
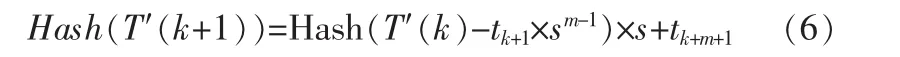
上面式子通常可以用公式 Hash (T′(k)-tk+1*sm-1)*s+tk+m+1计算得到,如果得到的值比q大,那么只需要再做一次取模运算就可以了。同时,由于Hash(sm)在比较中常常用到,所以可以先对其进行预处理,在需要的时候直接调用即可。
假设X=xr,xr+1,…,xr+n是从r开始的 n+1个字符组成的字符串,而且,假设d是标记字母表的基,q是一个大的素数,则散列值Xy按下列公式计算:
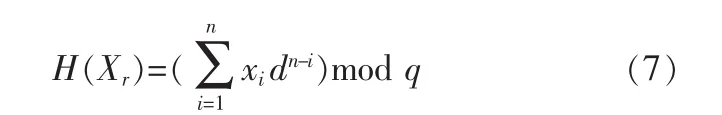
到此为止,计算散列值的过程H的时间复杂度也没有太多的改善。然而,Xr+1的散列值则可按如下公式求出:

如果散列值H(Xr)存在的话,式(8)就可在常量时间内计算出来。
1.1.3 RKR-GST时间复杂度分析
像前面讨论的一样,最坏情况下,RKR-GST算法的时间复杂度和GST算法一样,仍然是O(n3)。然而,算法的平均时间复杂度却在O(n)和O(n2)之间。使用曲线拟合法,Wise经实验得出的平均复杂度为O(n1.12),非常接近线性时间。因此,实际上RKR-GST算法改善了算法的时间复杂度。
2.2 对RKR-GST算法的一点改进
通过前面的分析可知,当两个标记串的KR散列值相同时,再通过逐个字符的比较来判断两个标记串是否匹配。很显然,这是使用的蛮力(Brute Force)字符串匹配算法(简称BF算法),最坏情况下该算法的时间复杂度为O(mn)。为了改进[10-11]其时间复杂度,所以考虑使用KMP算法[11-12],KMP算法的时间复杂度为O(m+n),这里m和n分别为模式串和文本串的长度。下面简单介绍一下KMP算法。
KMP(Knuth-Morris-Pratt)算法是 BF的一种改进算法,其核心思想是:在发生失配时,文本串不需要回溯,而是利用已经得到的“部分匹配”的结果将模式串向右“滑动”尽可能远的距离,继续进行比较。这里要强调的是,模式串不一定向右移动一个字符的位置,右移也不一定必须从模式串起点处重新试匹配,即模式串一次可以右移多个字符的位置,右移后可以从模式串起点后的某处开始试匹配。
假设发生失配时,P[i]≠T[j],1≤i≤m,1≤j≤n。 则下一轮比较时,P[i]应与T[next[j]]对齐往后比较:
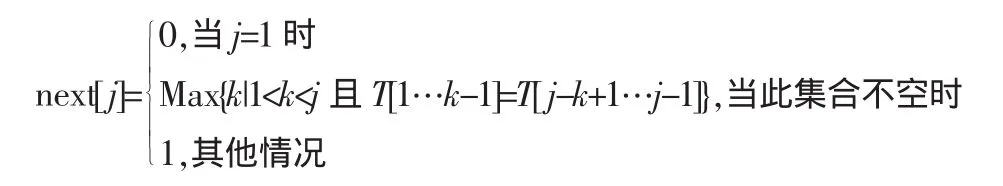
根据j的取值可以得到next[i]的结果,从而获得向右滑动的距离。
2 实际问题处理
利用相似度技术对内蒙古全区119个台站从建站到2010年的地面历史资料所有要素进行同站间不同年代数据,相邻台站各年代数据进行控制,如下例
|1969-02-02|A054***.F69|54***.F79|1979-02-12|水汽压|13天|
表示54***站1969年2月2日开始有13天的水汽压记录和1979年2月22日开始的13天记录完全相同,需要核对报表,确认是否存在录入拷贝的问题。
|1998-12-09|A05****.D98|54***|2001-12-05|A054***.D01|气压|12 天|
|2001-01-12|A05****.J01|54102|2004-01-21|A054***.J04|水汽压|2天|
|1984-12-13|A054***.D84|55***|1984-12-16||A055***.D84温度|12天|
表示不同台站在某些年月存在连续若干天记录相同的问题,通过核对原始报表确认其录入的数据是否正确。
3 结 论
通过全内蒙古全区119个台站从建站到2010年约6 000个站月资料数字化文件台站参数、要素方式位、要素等方面相似度的检查,我区台站参数检测疑误1 970条,方式位疑误检测53 852条,要素检测疑误1 6991条。存在的问题主要是要素02时与08时整月要素值相同;要素缺少记录;定时风风速个位非零和风向8方位;方式位变化的问题和台站参数变化的问题。通过自动度量不仅可以帮助审核人员节省大量的工作时间,也减轻了工作量,同时对其他行业的数字化工作也具有重要的借鉴意义。
[1]Halstead M H.Elements of software science[M].North Holland,New York,1977(17):5-7.
[2]Ottenstein K J.An algorithmic approach to the detection and prevention of plagiarism[J].ACM SIGCSE Bulletin,1976,8(4):30-41.
[3]Whale G.Identification of program similarity in large populations[J].The Computer Journal,1990,33(2):140-146.
[4]Gitchell D,Tran N.Sim:A utility for detecting similarity in computer programs[C]//In Proceedings of the 30th SIGCSE Technical Symposium,March 1999.
[5]Wise,Michael J.YAP3:Improved Detection of Similarities in Computer Program and other Texts[M].Department of Computer Science, University of Sydney, 2003.
[6]张文典,任冬伟.程序拷贝判定系统[J].小型微型计算机系统,1988,9(10):34-39.
ZHANG Wen-dian,REN Dong-wei.The judgment system of program copies[J].Journal of Chinese Computer System,1988,9(10):34-39.
[7]于海英.字符串相似度度量中LCS和GST算法比较[J].电子科技,2011(3):101-103,124.
YU Hai-ying.The comparison of the LCS algorithm with the GST algorithm in strings similarity metrics[J].Electronic Science and Technology,2011(3):101-103,124.
[8]Faidhi,J A W,Robinson S K.An empirical approach for detecting program similarity within a university programming environment[J].Computers and Education,1987,11(1):11-19.
[9]Grier,Sam.A Tool that Detects Plagiarism in Pascal Programs.Twelfth SIGCSE Technical Symposium[J].St Louis, Missouri,1981:15-20.
[10]Verco K L,Wise M J.Software for detecting suspected plagiarism:comparing structure and attribute-counting systems[J].Computer Science, University of Sydney,1996:3-5.
[11]Donaldson,John L,LancasterA M,etal.A Plagiarism Detection System[M].Twelfth SIGCSE Technical Symposium,St Louis,Missouri,1981:21-25.
[12]党红云,蒋品群,何婷婷.一种改进的KMP算法在不良网站信息过滤中的应用[J].现代电子技术,2012(1):110-112,116.
DANG Hong-yun,JIANG Pin-qun,HE Ting-ting.Application of an improved KMP algorithm in bad website information filtering[J].Modern Electronics Technique,2012(1):110-112,116.
