基于并行分量译码的分段拟合Turbo码译码﹡
2013-09-25陶玥琛宋春林宋超凡
陶玥琛, 宋春林, 柏 亮, 宋超凡
(①同济大学 电子与信息工程学院,上海 201804;②中国航天科工四院红峰控制公司,湖北 孝感 432000)
0 引言
Turbo码[1]因其优异的译码性能,被3GPP写入LTE/LTE-A标准信道编码[2]。但在实际应用中,由于MAP算法复杂度高,须在接收整个序列后才开始译码;其译码使用迭代译码,故Turbo码在误码率和译码延迟性能两方面上存在矛盾,传统译码算法在实时业务中应用受限。
为解决上述问题,学者们进行了大量研究改进。在算法方面,Log-MAP算法对MAP算法进行对数变换,较 MAP算法更易实现。在结构方面,SW-Log-MAP算法引入滑动窗,后向度量建立和前向度量递推同时进行,减小延迟;由此发展出基于前后子译码器状态度量估计的overlap算法和NII算法[3];Radix-4算法[4]将两步状态转移合并,一时刻完成两比特的译码。可以看到,简化算法和减小延迟是研究Turbo码的一个重要课题。
基于此,为实现译码性能和延迟的均衡,在译码结构方面,文中提出了一种并行分量译码器译码结构,可减小每次迭代译码的时间。在译码算法方面,文中提出了一种分段线性拟合Log-MAP算法,用加法、乘法及查表等运算取代指数和对数运算,可降低运算复杂度。最终,新方案在Visual C++环境下仿真实现,获得了较好的效果,与传统的串行DEC结合Log-MAP译码算法相比误码率性能相当,且节省了一半的迭代译码时间,更适合Turbo码在实时场景中的应用。
1 Turbo码译码结构
Turbo码采用基于最大后验概率的译码器迭代译码的方法,通过两个分量译码器之间软信息的交换来提高译码性能。译码时,子译码器间的软信息相互传递,循环迭代完成译码[5-7]。Turbo码的常见译码结构如图1所示。
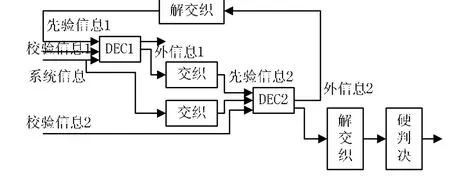
图1 Turbo码译码结构
Turbo码译码过程为:第一次迭代,系统信息、校验信息1进入DEC1,令先验信息1初始为0,DEC1根据某个译码算法完成译码,生成外信息1。外信息1经交织后,作为DEC2的先验信息2。而接收的信息序列经交织,作为DEC2的系统信息。DEC2利用先验信息2、系统信息及校验信息2完成译码,得到外信息 2。此时,第一次迭代完成。外信息2经解交织后得到DEC1的先验信息进入下一迭代运算,继续上述译码过程。当达到最大迭代次数时,经解交织、硬判决得到译码输出序列。
译码器间交换的软信息称为外信息 Le(xk),定义外信息的绝对值均值为:

如图2和图3所示,观察在不同迭代次数后,Le1(xk)和 Le2(xk)的绝对值均值的变化趋势。

图2 L e1 ( xk)变化趋势
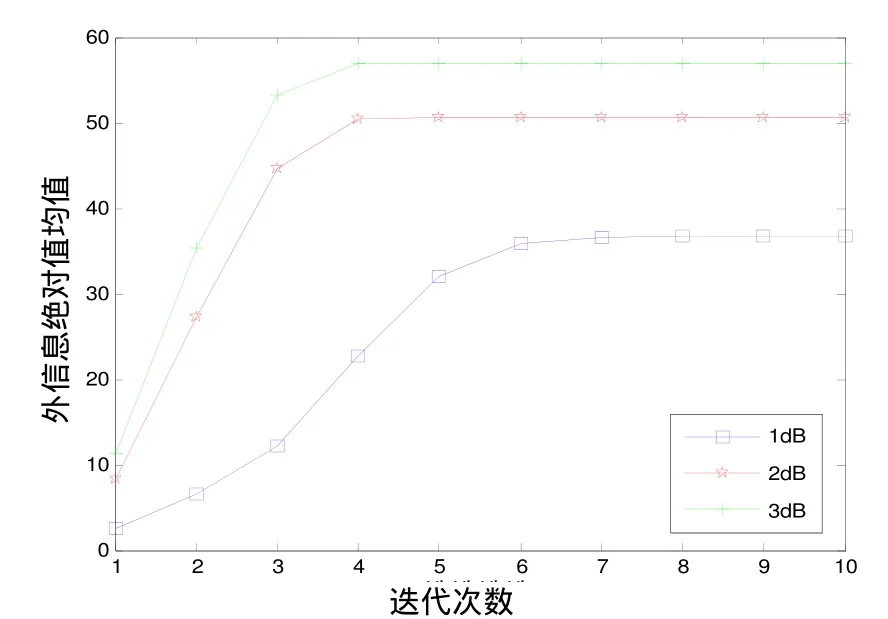
图3 L e2 ( xk)变化趋势
可看到,在前期迭代中, Le1(xk)和 Le2(xk)的绝对值均值的增长趋势明显;而在到达一定迭代次数后,增长逐渐放缓,并趋于收敛到一个极限值。在迭代过程中, Le1(xk)和 Le2(xk)的变化趋势和幅值基本保持一致。
2 并行DEC译码结构
在上节迭代译码过程中,两译码器是串行关系,当DEC1译码时,DEC2是空闲的,反之亦然。这里存在着硬件资源闲置的问题。根据上述分析,在迭代过程中, Le1(xk)和 Le2(xk)的变化趋势和幅值基本一致。故文中尝试将DEC1与DEC2改为并行,其结构如图4所示。

图4 并行DEC译码结构
并行DEC译码过程为:第一次迭代,系统信息、校验信息1和交织的系统信息、校验信息2分别进入DEC1、DEC2,分别令先验信息1和先验信息2为0,DEC1和DEC2同时译码,得到外信息1和外信息2。然后对外信息1和外信息2分别交织和解交织,得到带入下次迭代的先验信息2和先验信息1。此时,第一次迭代。如上述过程迭代译码,当达到最大迭代次数时,经解交织、硬判决得到译码输出序列。
对于一次迭代时间,相对传统译码结构,并行DEC译码结构节约了一半的时间,两译码器同时工作,避免了硬件资源闲置的问题;两次迭代译码之间,交叉传递外信息,充分利用了Turbo编码提供的校验信息。
3 Log-MAP算法的相关函数
Log-MAP算法将MAP算法中的变量作对数变换,把变量的乘法转成加法,从而简化运算[8-10]。
首先,对前向、后向状态度量和分支度量进行对数变换:
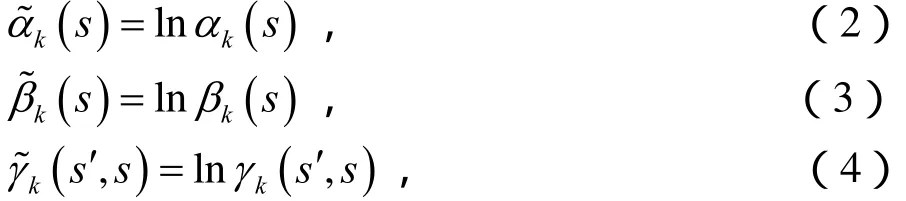
定义算子 m ax*(⋅):

对于两个变量的情况,算子变形为:

因此,得到:

最终

在Log-MAP算法中,用大量 m ax* ( )计算前后向度量和对数似然比,简化了运算。但由公式(6),max* ( )运算依然复杂。
在下文中,定义ln(1 + e-x-y)为相关函数。观察其曲线特性,以(x - y)为横坐标,如图5所示。
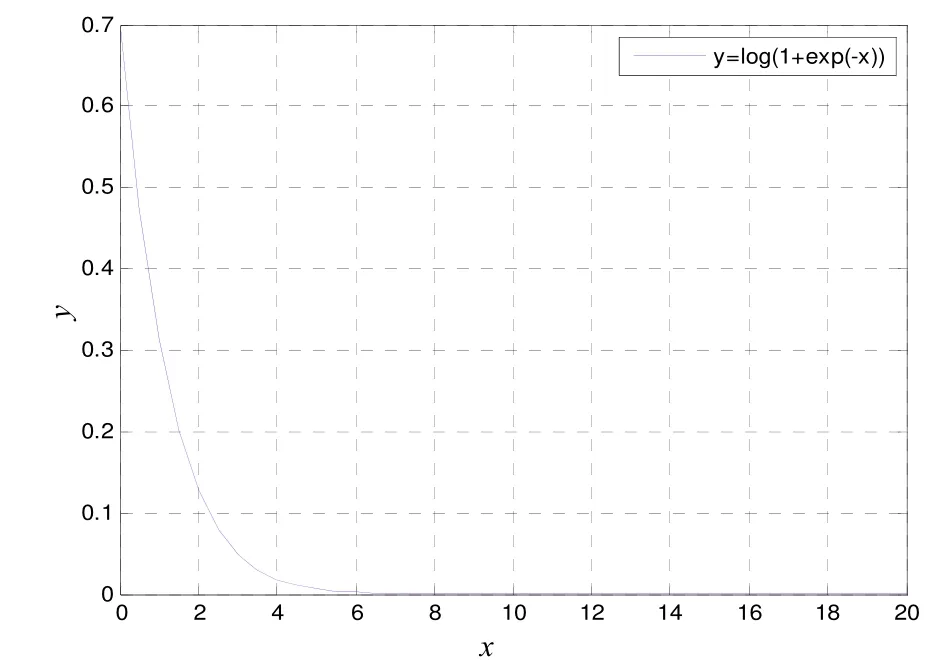
图5 相关函数的曲线特性
可看到,在[5, +∞ )区间,相关函数值近似为0。假如使用分段线性函数对相关函数的其他部分做近似,在不同区间用不同斜率进行逼近,则能提高对相关函数描述的精确性,且线性函数的复杂度大大降低。
拟合的流程如下。
Step1:选择拟合区间。这里对[0,1 ),[1,2 ),[2,3),[3, 4),[4, 5)区间分别拟合,对[5, + ∞ )区间作0处理。
Step2:对各区间取点,步长0.25,采用最小二乘法作线性拟合,得到线性方程。
Step3:将分段拟合函数代入 Log-MAP算法,max* ( )算子括号内有8个变量(根据3GPP标准,编码器有8种状态),应用公式(6)需采用迭代方式。
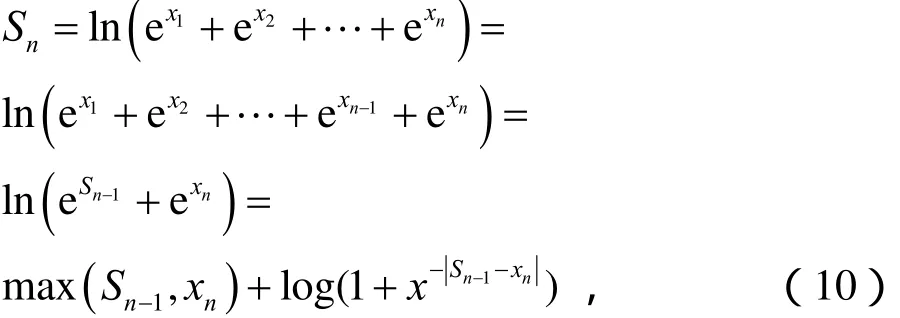

表1 基于分区间的拟合函数
分段拟合函数的逼近程度如图6所示,分段线性函数可很好地描摹相关函数的曲线特性。
图6 分段拟合函数对相关函数的逼近
4 仿真分析
基于 3GPP标准,比较各算法的误码率性能差异。算法仿真在Visual C++ 2005环境中进行,并调用Matlab绘图功能实现。算法仿真链路结构如图7所示。译码性能仿真参数如表2所示。
如图8所示,在不同迭代次数下,采用Log-MAP算法,比较传统译码结构和并行DEC译码结构的性能。可看到,在不同迭代次数下,二者误码率性能相当,一致性好。在译码时间上,并行DEC译码结构节省一半的时间,大大降低译码延迟。
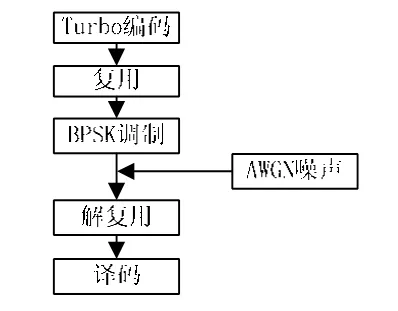
图7 算法仿真链路结构

表2 仿真环境参数

图8 译码性能仿真(帧长440 bit)
如图 9所示,在不同帧长下,比较传统结构Log-MAP算法和并行DEC分段拟合算法的性能。
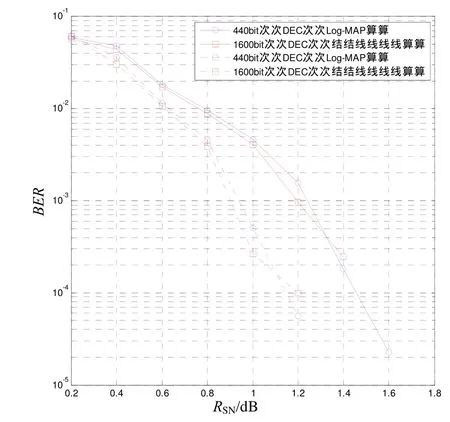
图9 译码性能仿真(迭代3次)
从图9可看到,在不同帧长下,二者误码率一致性较好,新方案保证了低误码率,同时降低了运算复杂度和译码延迟。
5 结语
仿真表明,文中提出的并行分量译码并结合分段拟合算法可在误码率性能上达到与 Log-MAP算法相当的水平,且在迭代时间上缩短一半,在译码性能、运算复杂度和译码延迟方面均获得较好效果。这可为适应LTE-A等大吞吐量、实时的高速译码器的设计及硬件实现提供一种选择,为Turbo码在深空通信、数字水印[11]等方面的应用提供参考。
[1] BERROU C, GLAVIUX A, THITIMAJSHIMA P. Near Shannon Limit Error-correcting Coding and Decoding: Turbocodes(1)[C]//Proc. ICC’93. Geneva: IEEE,1993:1064-1074.
[2] 3GPP TS 36.212 V8.8.0, Multiplexing and Channel Coding[S].Geneva:3GPP,2009.
[3] WU D,ASGHAR R,HUANG Y L,et al.Implementation of Ahigh-speed Parallel Turbo Decoder for 3GPP LTE Terminals[C]//ASICON ’09. Changsha: IEEE,2009:481-484.
[4] CHUANG H T,TSENG K H,FANG W C.Ahigh-throughput Radix-4 Log-MAP Decoder with Lowcomplexity LLR Architecture[C]//VLSI Design, Automation and Test.Hsinchu:IEEE,2009:231-234.
[5] LI Xiangling,WANG Ke,XU Zhao.LPM-Turbo Decoding Structure based on Simulink[C]//WiCOM. Chengdu:IEEE,2010:1-4.
[6] YOO I, KIM B,PARK I C.Immediate Exchange of Extrinsic Information for High-throughput Turbo Decoding[J].IEEE Communication Letters, 2012,16(12):2048-2051.
[7] 赵运杰,宋春林,刘晓林,等.基于外信息收敛的Turbo码译码优化算法[J].通信技术,2012,45(05):4-7.
[8] 邱宁,李强,程建,等.基于常数的混合Log-MAP Turbo译码算法[J].西安邮电学院学报,2012,17(06):52-55.
[9] 王萍,宋荣方.一种 Turbo迭代译码的联合自适应方案[J].南京邮电大学学报,2012,32(04):14-18.
[10] 黄盛刚,李挥,安辉耀,等.WCDMA/HSDPA系统中的Turbo译码器设计与优化[J].通信技术,2010,43(02):119-121.
[11] 瞿伟,蒋兴浩,孙锬锋.基于 Q-DCT 域实时视频水印的版权保护方案[J].信息安全与通信保密,2010(02):70-72.
