应用半连接的分布式数据库查询优化算法
2013-09-18李川
李 川
(西安航空学院计算机工程系,西安 710077)
随着信息技术的高速发展,数据库技术已经广泛应用于当今社会的各行各业。特别是在生物学、农林业等领域,需要调查研究的数据量大,而且每个数据元组又包含了大量的属性。对于这些数据,各研究机构研究的内容和方向不尽相同。如何将这些数据做到既逻辑统一又合理分布是一个非常重要的问题。分布式数据库是物理上分布而逻辑上统一的系统。
将大规模数据(包括大规模关系或大规模元组)的数据库建立成分布式数据库系统,由于分布式数据库的分布性和冗余性使得数据查询操作变得复杂,因此如何提高查询效率成为分布式数据库研究的重要问题。本文针对大规模数据元组或较多记录的数据,建立分布式数据库模型,详细分析了分布式查询处理的目标、数据分片体系结构、查询优化方法及改进策略。
1 分布式数据库查询优化目标
分布式数据库不同于集中式数据库,查询处理除了考虑CPU代价和I/O代价之外,还应包括数据在网络上的传输代价
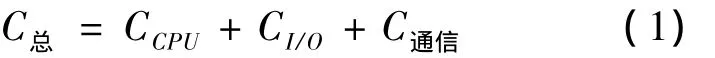
通信代价估算公式为
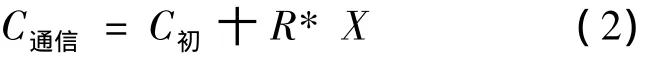
其中:C初为初始化的时间,单位为s;R为传输率,单位为 bit/s;X为需要传输的数据量,单位为 bit[1]。
分布式数据库系统的查询优化有2个准则[2]:一种准则以总代价最小为标准,例如在广域网分布式数据库系统中,忽略CCPU+CI/O,只考虑C通信;另一种准则以每次查询的响应时间最短为标准,一般应用在高速局域网分布式数据库中。
总之,分布式查询优化的准则是使通信费用最低和响应时间最短,即以最小的代价在最短的响应时间内获得需要的数据[3-4]。具体采用哪种准则需要根据具体的分布式数据系统网络结构而定。
2 分布式数据库数据分片
2.1 分布式数据库数据分片机制
数据分片是分布式数据库的重要特性。数据分片把关系按照用户需求有效划分成若干个片段,这些片段可以分布在不同站点上,但在逻辑上是一个整体。常见的分片方式为水平分片和垂直分片。水平分片是将关系按行横向以某种条件分为若干个子集;垂直分片是将关系按列竖向分为若干个子集。实际划分时采用水平分片或是垂直分片根据用户需求及网络的情况具体而定。在本文的应用中,一种植物的数据记录规模较大(超过104条),且数据元组规模也较大(超过200个属性列),由于各个研究机构研究的内容及侧重点均不同,因此不能单纯地采用水平分片或垂直分片,而应采用一种混合型的改进算法。
2.2 改进的分片机制
数据冗余可提高数据的可靠性和查询效率。首先,为保证数据可靠性,将所有数据存放在一个数据库,形成一个统一全面的数据库,该数据库为备用数据库。因为其数据规模较大,查询效率低,故一般不直接在该库中进行查找,将存放该数据的站点称为备用数据库站点;然后,根据植物的数据结构特征和研究机构的需求进行水平分片;最后,将水平分片得到的片段分别进行垂直分片。分片结构如图1所示。
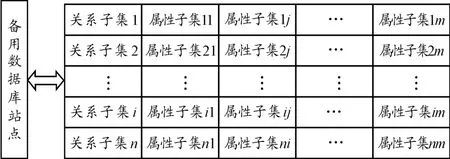
图1 带有冗余的大规模数据分布式数据库分片结构
3 基于半连接的查询优化算法研究
3.1 分布式数据库数据查询方法
分布式数据库查询过程一般分为4个步骤:查询分解、数据本地化、全局优化和局部优化。其中全局优化和局部优化是2个可以明显提高查询效率的过程。局部优化是在各站点的数据查询,该过程和普通集中式数据库的查询优化方法相同,故在此不再讨论。
在全局优化阶段,各个站点间的连接运算是产生代价的主要操作。而关于如何处理连接操作,以往的研究提出很多种算法,主要分为基于半连接的查询优化算法和基于直接连接的查询优化算法两大类。
基于直接连接的查询一般多用于高速局域网中。由于局域网的网络传输速度很快,因此可忽略数据传输的代价。所采用的方式为一次将所有数据传输,然后再进行查询。
基于半连接的查询常用于广域网环境下。广域网一般传输速度有限,所以减少2个站点进行连接时的传输代价是半连接查询优化的关键。通常2个站点间需要2次以上的数据传输,但总的数据传输量远小于传输整个关系的数据量。其基本原理是:在进行连接之前,先根据需求消除与连接无关的数据,减少作为连接的数据量,从而减小通信代价。虽然在连接之前所做的消除与连接无关数据的操作也会增加额外的代价,但与减小通信代价相比,还是很小的。
本文主要针对大规模数据广域网分布式数据进行库查询优化,所以重点研究基于半连接的查询优化。
3.2 改进的半连接查询优化算法
3.2.1 一般的半连接查询方法
半连接是投影和连接组成的一种关系代数运算。假设R1、R2是2个关系,分别位于站点S1、S2,而属性A1、A2分别在R1和R2上,半连接操作可表示为
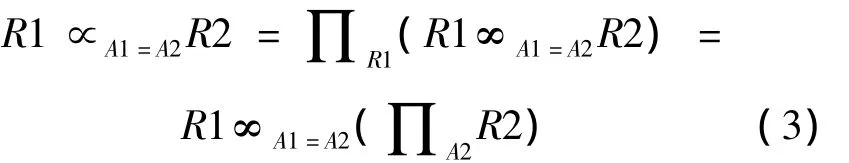
连接操作可表示为:
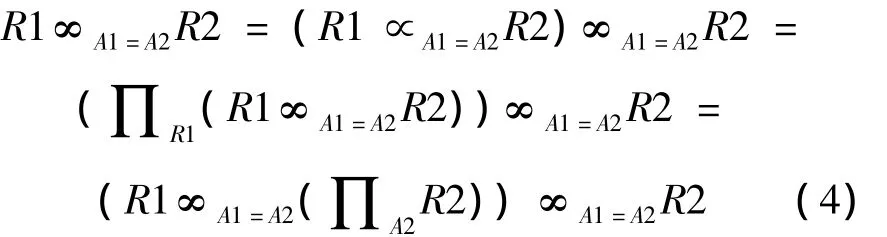
其中:∞表示连接操作,∝表示半连接操作,∏表示投影操作。
直接连接是将站点S2中的所有关系R2一次传输给站点S1,而半连接的执行过程如表1所示。

表1 半连接执行过程
在广域网分布式数据库系统中,只考虑通信代价,再次忽略网络的差异性,即式(2)中的C初和R都一样。下面根据式(2)计算比较使用直接连接和使用半连接方法实现的代价。
使用直接连接方法:
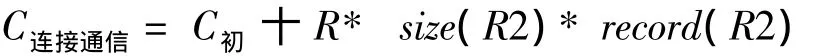
其中:size(R2)为R2元组的长度;record(R2)为R2的总记录数。
根据表1,使用半连接需要传输2次数据,分别为:
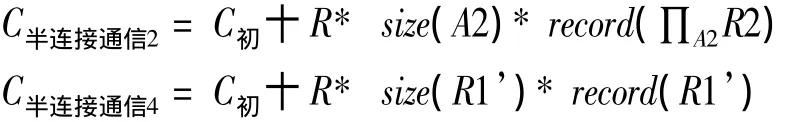
其中:size(A2)为关系R2中A2属性的长度;record(∏A2R2)为关系R2中属性A2上投影运算后的记录数;size(R1’)为关系R1’元组的长度,即R1的长度;record(R’)为关系R1’的记录数。
半连接的总代价为

在大规模数据记录多字段的数据库结构下,容易得出
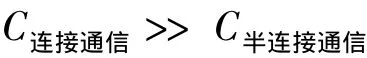
因此,在广域网中通过半连接的查询方式可大大减小通信代价。
3.2.2 改进的半连接查询优化
在一般的半连接查询中,连接代价主要是2次传输的代价。其中的第一次传输,即由站点S2将∏A2R2从S2传输到站点S1,因为只有一个属性,所以相对于大规模数据而言其传输的数据量较少;第二次传输,即由站点S1将R1’传输到站点S2,需要传输的数据元组长度为R1的长度,记录个数为R1’的记录数。这样,当R1长度很长,R1’记录很多时,该次传输的数据量仍然相当大,即带来了较大通信代价。由此提出一种改进的半连接查询方法。
首先,介绍改进半连接查询中涉及到的几个概念和理论。
定理1 连接运算的交换律。
假设有关系 R1和关系 R2,那么 R1∞R2=R2∞R1,即连接运算满足交换律。
定义1 关系元组比Rsize。
假设有关系 R1和关系 R2,那么 Rsize=size(R1)/size(R2),称为关系R1和R2的关系元组比。
定义2 关系记录比Rrecord。
假设有关系 R1和关系 R2,那么 Rrecord=record(R1)/record(R2),称为关系R1和 R2的关系记录比。
定义3 关系数据比Rdata。
假设有关系R1和关系R2,那么Rdata=Rsize*Rrecord,称为关系R1和R2的关系数据比。
由于关系R1的记录数和R1’的记录数一般情况下是成正比的,所以可认为:
当Rdata>1时,即站点S1上的数据量大于站点S2上的数据量;
当Rdata<1时,即站点S1上的数据量小于站点S2上的数据量;
当满足第2种情况时,采用一般的半连接方法是比较合适的,但当满足第1种情况的时候,显然采用一般半连接的传输代价较大。由于连接运算满足交换律,所以可将传输的内容改为将R2’从站点S2传输到站点S1,由此降低了传输代价。改进的半连接查询算法过程描述见表2。

表2 改进半连接查询算法过程
3.2.3 算法性能比较
假设关系R1和R2的关系结构如表3所示。

表3 关系结构
根据表3得关系数据比为2,按照改进的半连接查询,计算所需数据如表4所示。
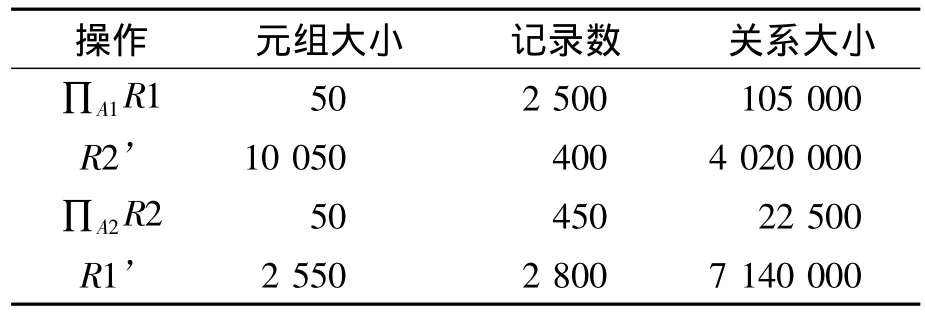
表4 改进半连接查询计算数据
由此可以得出2种算法的代价。
一般半连接查询代价:
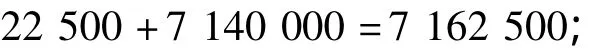
改进半连接查询代价:

改进半连接查询算法在数据传输之前,先进行数据关系大小比较(比较所产生的代价可忽略),保证了实际传输数据比较小,从而降低了传输代价。
4 结束语
本文主要分析和研究了分布式数据库的特点、查询优化目标、数据分片机制、查询优化的算法等。提出了在广域网中大规模数据的分布式数据库改进的数据分片模型及改进半连接查询算法。通过实例分析表明:改进半连接查询算法极大地降低了传输代价,提高了查询效率。
由于本文提出的改进半连接查询优化算法是基于广域网的大规模数据,因此在高速局域网或者数据规模不大的情况下该算法并不适用。在进行连接操作时,当要连接的2个数据关系大小差异较大时,采用该算法较适合,反之使用该算法意义不大。另外,本文认为在某一关系上投影操作之后,关系记录数与原关系记录数成正比,这在有些情况下是无法满足的,因此也会对改进算法带来负面影响。
[1]石小艳.分布式数据库中的查询策略与查询优化[J].计算机与网络,2010(30):244-245.
[2]姜爱福,李长云.分布式查询优化的技术实现[J].计算技术与自动化,2005(1):72-74.
[3]陈钟.一种改进的分布式数据库查询优化算法[J].计算机应用,2008(28):233 -235.
[4]陈世保.基于直接连接的分布式数据库查询优化实现方法研究[J].计算机时代,2011(7):17-20.
