海量数据过滤系统中匹配算法的研究
2013-09-17梁威,叶猛
梁 威,叶 猛
(1.光纤通信技术和网络国家重点实验室,湖北武汉430074;2.武汉邮电科学研究院通信与信息系统,湖北武汉430074;3.武汉虹旭信息技术有限责任公司安全产品部,湖北武汉 430074)
随着网络技术的迅猛发展,网络违法犯罪行为与日俱增。不法分子常常利用互联网进行一些违法犯罪活动,如传播色情信息、暴力信息和反动信息等,这些行为会严重扰乱社会次序,给人们的日常生活带来极大危害[1]。因此,如何有效剔除不相关信息和不良信息,已经成为新的研究热点。互联网中数据过滤系统的出现正是为了应对上述问题。过滤系统的性能低下会导致网络违法犯罪行为不能够被及时发现并制止,因此提升过滤系统的性能十分必要。
模式匹配算法是数据过滤系统的关键技术,因此其效率的高低间接地影响着互联网的安全。然而在实际应用的数据过滤系统中,所采用的模式匹配算法的效率不尽如人意,使得过滤过程耗费大量时间,互联网的安全因此无法得到保障。
本文提出了一种改进的AC-BM匹配算法,该算法能够充分利用匹配过程中匹配失败的信息,以达到每一次跳跃中跳跃尽量大的距离,从而使算法的执行更加快速。将此算法应用于数据过滤系统中,能够明显改善过滤系统的性能,使得过滤系统能够应对当前海量的数据环境,广大网民能够更加安全地享受互联网。
1 模式匹配算法简介
1.1 单模式匹配算法
经典的单模式匹配算法包括KMP算法[2]、BM算法等。下面主要简要分析这两种算法。
KMP算法由3个人共同提出,K,M,P分别是3人名字的首个字母。该算法是在BF算法的基础上改进而来。KMP算法创造性地消除了指针回溯,利用已经匹配的字符来确定下一次搜索的开始位置,进而将模式串移动后继续进行匹配。时间复杂度由BF算法中的O(mn)降低为O(m+n)。
BM算法因其由Boyer和Moore提出而得名,该算法的基本思想是从待匹配文本的右边向左边依次进行比较。当某趟比较过程中失配情况发生时,该算法会利用坏字符和好后缀信息实现跳跃,这种方式能够很大程度上降低字符比较的次数,理想状态下,算法的时间复杂度可达O(n/m)。
总的来说,BM算法相比KMP算法简单,效率更高,实用性也更强,是目前单模式匹配算法中最优的算法。实践证明,BM算法执行速度比 KMP算法速度快3~5倍,但在短模式串情况下,BM算法的优势就没那么明显了。同时,模式集规模较大时,BM算法的效率难以满足实际要求。再者,它使用了两个数组,预处理开销大。
1.2 多模式匹配算法
1.2.1 AC算法
Aho—Corasick自动机算法[3](AC算法)是多字符串匹配中经典的算法,1975年产生于贝尔实验室,可被看作是KMP算法的改进,而它的创造性在于它在进行匹配之前对模式集进行处理,使得匹配效率不再受到模式集合规模的制约。对模式集进行处理的预先处理实质上就是创建3个表的过程,它们分别是goto表、fail表和output表。goto表可以理解为模式集的状态转换表,当goto表无法查询到时使用fail表,而output表则是用来记录当前位置是否成功匹配某种模式。此算法的时间复杂度可达O(n),并且时间复杂度与模式串的数目和长度无关。
AC多模匹配算法具有如下特点:
1)算法相对简单、效率高(一次扫描可以完成所有模式的匹配)。
2)与模式串长度和待匹配文本内容没有关联。
3)适用范围广(算法适用任意字符)。
该算法的不足之处在于它对内存空间需求比较大。一旦匹配模式集合规模庞大,内存空间使用量会急剧增加,甚至可能导致系统崩溃。
1.2.2 AC-BM算法
AC算法的最突出的特点就是一次扫描可以匹配所有模式,BM算法最突出的特点在于它能够通过跳跃匹配降低比较次数。AC-BM算法的本质就是将这两个算法的优点结合产生的一种新的算法。
同AC算法一样,AC-BM算法会在匹配之前对模式集合进行预先处理,匹配时,采取自后向前的方法,一旦模式确定在适当的地方,从左到右判断是否匹配成功。
在此过程中,借用了BM算法的好前缀跳转(Good Prefix Shift)和坏字符跳转(Bad Character Shift)技术。
所谓好前缀跳转,就是当待匹配字符与模式树某个模式中的字符A不匹配时,利用字符A之前已匹配的字符串S查询模式树,计算距该模式树中下一个出现字符串S的距离L1,将模式树向前移动L1后继续进行匹配。
坏字符跳转,就是当待匹配字符与模式树某个模式中的字符A不匹配时,计算该模式树中距离下一个A字符的距离L2,将模式树向前移动L2后继续进行匹配。如果字符A在模式树中不存在,那么移动距离可以达到最小字符串长度。
AC-BM算法结合多模式匹配AC和单模式匹配BM两者的优点,即一次扫描过程完成所有模式的匹配又可以在模式匹配的过程中跳过不必要的字符匹配过程,因此AC-BM算法具有更高的匹配效率。它的这些优点可以有效提高数据过滤系统的性能。但是,AC—BM算法的效率仍然无法使当前过滤系统的性能足以应对海量的数据环境,因此需要对AC—BM算法进行进一步改进和优化,使它能够给过滤系统的性能带来提升。
2 AC-BM算法的改进
进一步提高模式匹配算法效率的主要途径是利用模式串匹配失败时可以获取的信息以进一步增大跳跃距离。受BMH算法思想的启发,减少好后缀跳转的比较步骤后,算法的实际性能并不比BM算法差,相反,在某些情况下性能比BM算法优越[4]。因此,可以通过简化AC-BM算法的复杂性,同时对坏字符跳转进行改进,形成一种新的算法。
该算法的核心思想是:匹配的过程中模式串从左向右依次进行比较,当匹配过程中遇到失配字符时,继续判断文本后一字符是否存在于模式树中,如果当前字符和后一字符不存在于模式树当中,就可以直接跳过模式树最小字符串长度加1再进行比较。相比AC-BM算法,突破了无法跳跃大于最大字符串长度的限制,从而减少了比较的次数。如果在模式串中,则跳转到下一个同时出现当前字符和下一字符的位置。
与AC-BM的坏字节相比,在失配的情况下,采用两个字节来查找下一个匹配的位置,无疑加大了失配时的跳跃距离。此外,省去了好前缀跳转步骤,简化了算法,提升了效率。
算法的整个过程可以按时间先后分为模式集的预先处理阶段和字符的匹配阶段。下面将对这两个阶段的处理过程进行介绍。
2.1 预处理阶段
假设待匹配的文本字符串为Text,长度为N,模式字符串为P,模式个数为k,字符集合为Σ,模式集合中最短模式的长度为Lmin。模式集合的预处理阶段首先将模式集合P中所有模式按照AC算法的预处理方式构成模式树,之后再构造一个跳跃数组skip[x1][x2](x1和x2为字符集Σ上的字符)。
2.2 匹配阶段
从树的根字符开始逐个与文本字符串Text进行比较,如果出现了不匹配字符,读取文本字符串Text字符T(i)的下一字符T(i+1),在skip表中查找下一个出现T[i]T[i+1]的位置。若找不到,则移动模式树,将模式树向右移动Lmin+1,若找到,则移动模式树相应距离,与第一次出现T[i]T[i+1]字符的位置对齐。当整个文本字符搜索完成或者匹配成功时返回匹配结果。
改进的AC-BM算法对应的伪代码将展示该算法的具体实现过程,如下:

算法的改进主要体现在:
1)利用两个元素来定位跳转位置,能够加大失配时的移动距离,从而减少比较次数。
2)修改了坏字符跳转距离的计算方法,使其只与当前匹配字符有关,而与当前节点无关。
对偶句在我国古代文学作品中是极得作家青睐的,它句式整齐,读起来朗朗上口。据笔者统计,《卜算子》中不仅对偶句数众多,且对偶形式丰富多样。
3)取消了好前缀跳转的计算,计算得到了简化,效率相应得到提升。
3 算法性能测试
3.1 测试环境
测试中硬件环境是采用:CPU Intel Pentium 4,主频1.70 GHz,内存2 Gbyte,redhat 9.0平台上进行测试。算法用C语言实现,编译器采用gcc version 4.1.2,优化开关全部打开。
3.2 测试结果
3.2.1 时间测试
时间测试主要的目的是为了比较各个算法在外部环境相同的情况下处理不同模式集合所需的时间。
首先测试模式数量和匹配时间之间的关系。测试过程中选择的模式长度为20 byte,记录4种算法完成匹配过程所耗时间数据,根据测试数据绘制匹配时间-模式数量图。图1中显示,改进算法相比其他3种算法在模式数量较小和模式数量较大的情况下性能都得到了较大改善,与预期结果一致。
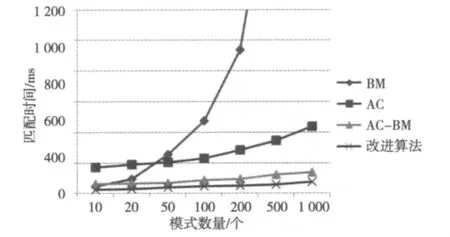
图1 匹配时间-模式数量曲线
接着测试模式长度和匹配时间之间的关系。模式数量固定在1 000个的情况下,记录4种算法完成匹配过程所耗时间数据,根据测试数据绘制匹配时间-模式长度关系图。图2中显示,改进算法相比其他3种算法在长模式和短模式的情况下性能都得到了较大改善,与预期结果一致。
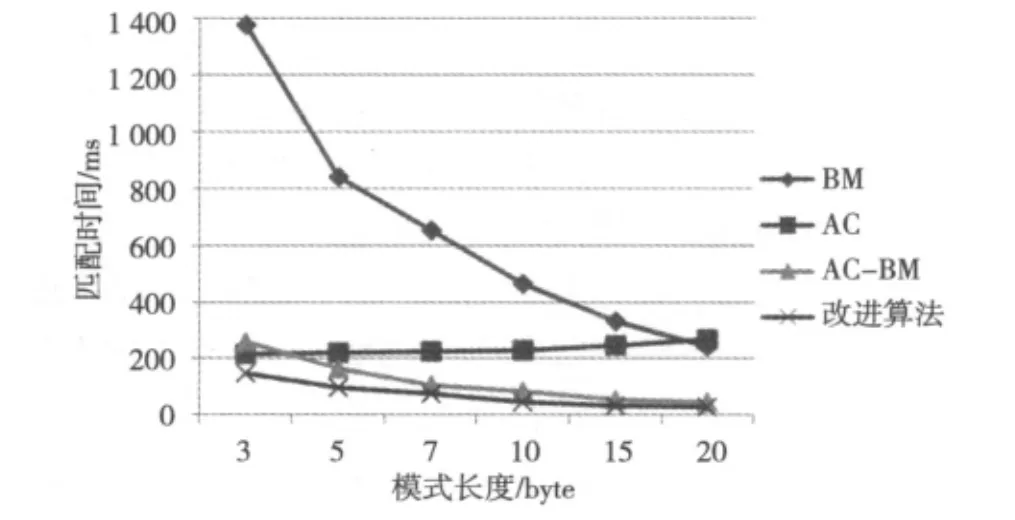
图2 匹配时间-模式长度曲线
3.2.2 空间测试

图3 不同算法的内存消耗
通过对各个算法进行时间和空间的测试可以得出如下结论:
1)改进的匹配效率不受模式个数的限制。
2)改进的匹配算法在模式长度较小和较大时匹配效率都较高,能够很好地抵抗短模式长度带来的性能低下。
3)改进的算法对消耗内存资源的消耗并没有很大的增长。
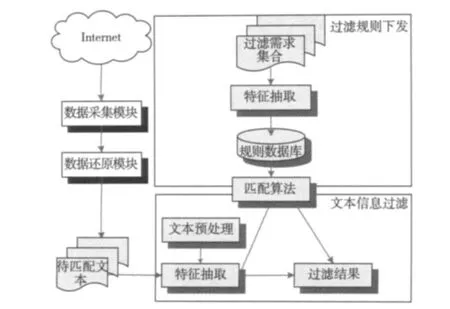
图4 内容过滤系统的一般模型
4 改进算法在内容过滤系统中的应用
数据过滤系统是保护网络安全的一道重要防线,它通过对网络数据内容进行匹配,能够有效发现不良信息及违法信息,即时阻止其在网络中的传播和蔓延,从而保证网络的安全。内容过滤系统处理的对象主要是文本数据,在互联网中,需要处理的文本数据量非常的庞大,因此对内容过滤系统的性能要求很高。
内容过滤系统根据功能可以划分为3个模块(图4),分别为数据采集模块、数据还原模块和过滤模块。采集模块负责将网络中传输的MAC帧进行处理,还原出TCP和UDP流。TCP和UDP流经过还原模块后得到大量的文本数据,之后发送给过滤模块进行文本过滤。
过滤模块的工作过程分为两个阶段,首先匹配算法的预处理阶段,会将用户的需求以规则串的形式构建状态机和规则相应的失配跳跃表skip,在信息匹配阶段,系统会对待过滤的文本数据进行预先处理,之后对文本信息进行匹配,实时将匹配结果发送给用户。
5 小结
本文通过对各种匹配算法进行分析,进而提出了一种改进的算法。改进的算法在进行模式匹配时执行速度得到了明显提升。尽管空间上比AC-BM算法增加了一些额外开销,但它使得数据过滤系统的性能得到较大提升,综合考虑,这种空间换时间的方法是值得的。
:
[1]耿金秀.浅谈计算机网络安全防范措施[J].中国科技信息,2011(8):110-111.
[2]朱娇娇,叶猛.多模式匹配及其改进算法在协议识别中的应用[J].电视技术,2012,36(7):60-63.
[3]KUNTH D E,MORRIS J H,PRATT V R.Fast pattern matching in strings[J].SIAM Journal on Computing,1977,6(2):323-350.
[4]NIGEL HR.Practical fast searching in strings[J].Software Practice and Experience,1980,10(6):501-506.
