结构化P2P网络上基于类别树的索引机制
2013-09-11兰明敬胡建伟
兰明敬,胡建伟
(解放军信息工程大学 信息工程学院,河南 郑州450002)
0 引 言
DHT机制具有单值映射的特点,即为实体选取一个关键字,系统通过哈希算法将关键字一对一映射为空间标识,使用此标识与结点标识相匹配以决定存储位置;发现过程中,若选取的关键字与存储过程使用的关键字相等,则能够快速定位到存储点,取出实体信息;若不相等,则无法查找到实体。但很多情况下,人们无法准确描述所搜索的目标,无法给出实体存储时所使用的关键字,只能给出搜索目标的大致特征描述。
一般的解决方法是使用多个关键字存储实体,增大发现概率,同时建立集中式服务器存储关键字信息用于模糊检索。这种方法一定程度上损失了P2P技术的优势,重新带来单点失效和性能瓶颈风险,并可能涉及到版权问题。人们还利用语义思想来改善结构化P2P系统的搜索[1-3],文献 [2]提出了一种向量空间模型,首先将描述实体的多个关键词向量化,然后再使用哈希函数处理该向量,得到一个空间标识符;检索文档时,将检索关键词进行同样的向量化操作,通过比较两个向量的相似程度来判断两文档是否匹配。相对于传统的关键字相等,这种机制在一定程度上扩充了搜索关键字检索的范围,但距离模糊搜索还有一定差距,其缺陷主要体现在两个方面:一是受限于标识符长度,一个特征向量中包含的特征词数目是十分有限的,当搜索关键字与特征向量中的特征词差别较大时即难以成功检索;二是特征词的选取和向量距离计算算法较为复杂,不合适的特征词选取和距离计算算法将严重降低检索效果。
本文在传统的Kademlia算法基础上进行改进,提出了一种基于类别树的、静态和动态描述相结合的索引机制。归纳应用系统涉及到的实体类别建立类别树,依据类别树形成结点、实体以及查询所需的标识,使得结点组织、实体存储、结点和实体发现均围绕类别分布、实施。为每个类别编制描述该类别实体特征的静态描述,实体发现过程中,先使用关键字列表检索类别的静态描述,综合考虑关键字匹配情况、树结点深度、结点祖先匹配程度、查询者喜好等各类因素,得到若干最为满足查询需求的类别,将查询聚焦到类别对应的若干P2P结点上。得到正确结果时,发现算法将查询所用关键字添加到对应类别的动态描述中,以此在发现过程中进一步过滤不满足查询需求的目标结点,使查询始终围绕关键字列表进行,逐步收敛到满足需求的P2P结点上。
为不引起混淆,将改进后的P2P结构简称为SKad。SKad由若干结点组成,结点是互联网上的主机,结点间相互路由形成P2P覆盖网络。Skad可用于分享书籍、文献、影音、程序等电子文件,实体是描述这些文件的信息单元,也是Skad存储、管理的基本元素。
1 类别树和类别静态、动态描述
在搭建P2P系统之前,搭建者需要充分分析应用特征,归纳系统涉及到的实体类别,建立类别树。
类别树的结构及例子如图1、图2所示,树结点 (C)枚举了给定P2P系统中可能存储的所有实体的类别,树结点间的父子关系等价于对应类别的包含关系。

树结点表示为:C= (cn,sd,ddi)。其中cn为类别名;sd为类别的静态描述;ddp为动态描述标识,用于查找类别的动态描述。
静态描述(sd)记录了本类别所涵盖实体的详细特征,直接存储在对应的树结点中。实体存储、发现过程中,算法首先依据描述实体的关键字列表,检索类别树中各类别的静态描述,获得若干与实体相匹配的类别,以此定位实体的存储结点,缩减查询范围。P2P系统搭建者需要在建立类别树的同时,为每个类别编制详细的静态描述。可通过互联网搜索引擎或其他途径,搜集某类别相关的各类文字描述,整理、合到该类别的静态描述中。静态描述的格式可以是字符串文本,也可以是数据库或其他格式,前提是该格式能够支持上述关键字检索过程,且易于增量式扩充。
静态描述存储在类别树中,而类别树则和其他实体一样存储在P2P网络中 (如图3所示)。一般情况下,类别树使用一个全局唯一且公开的标识符,以单一文件的方式存储在P2P中。若类别树较大,也可按类别划分为若干子树,分布存储在P2P中。划分的数目不宜过多,过多的子树将带来更多的流量开销和管理负担。

图3 类别树和类别描述存储方法
在系统运行过程中,类别树结构应较为固定。类别树应具有明确且固定的分类方法,系统运行过程中,分类方法不能改变,类别树中已经存在树结点的名称、动态描述标识以及树结点间的连接关系不能改变。类别树创建者(或其他人)可低频度地、增量式地更新完善类别树,包括增加树结点,丰富类别静态描述信息。尽管不是所有应用都满足上述要求,但大部分的、常见的互联网P2P应用都是满足此要求的。比如音乐、软件分享类应用,不难确定一种可用的、无需经常改变、易于维护的音乐、软件分类方法。
动态描述同样记录了类别所包含实体的特征,差别在于动态描述是在系统运行过程中由发现算法动态地生成并不断扩充的。类别树按其动态描述标识 (ddp),分散存储在P2P网络中 (如图3所示),其存储格式也应支持关键字检索以及增量式扩充。类别树创建者在建立类别树的同时应为每个类别设定相应的动态描述标识,此标识一般为从类别树根到所在类别的路径向量经过编码得到的二进制串,动态描述标识直接存储在类别树的树结点中。
实体存储、发现过程中,算法得到下一跳结点列表时,使用描述实体的关键字列表检索下一跳结点对应类别的动态描述,判断该结点是否符合实体特征,进一步缩减路由目标,提高结点和实体发现效果。
2 结点和实体标识
结点和实体标识决定了P2P网络拓扑结构和实体存储位置,本文中,实体和结点的标识均来源于类别树。
实体标识的产生方法为:从实体相关信息 (如音乐文件的名称、作者、描述信息)中抽取若干有代表性的关键字,遍历类别树各结点,检索结点的静态描述和动态描述文本,获得与实体相匹配的树结点列表;从列表中选择一个匹配度最高的结点,设为Cij,则实体标识eid为
eid =hash (cn1,cn2,…,cni,en)
其中cn1、cn2、…、cni为类别树从根结点到Cij结点路径上各树结点的结点名;en为实体名称;hash是哈希函数,将字符串转变二进制码。哈希函数与具体的P2P系统相关,本文中不做要求,但建议类别相近的实体,其标识距离也应相近,这样会使得实体按照类别聚集,从而使P2P网络具有更好的收敛特性,采用合适的搜索算法可以有效降低一次查询所需的消息交换次数。
参考以下条件并采用加权的方式,从匹配的树结点列表中选择最匹配的树结点:树结点静态、动态描述文本中,与关键词匹配的词汇数越多则树结点匹配度越高;深度越大则树结点匹配度越高;父结点越匹配则树结点匹配度越高;越多祖先结点匹配则树结点匹配度越高。选择树结点的过程就是依据类别树对实体进行分类的过程,为使这种分类更为精确,可让人参与到最优结点的选择过程中,即由程序给出推荐的树结点列表,由实体发布者从中选择一个最合适的。
结点标识的产生过程与实体标识类似,不同之处在于由于结点没有适于检索类别树的描述信息,因此在优先考虑路径较深树结点的前提下,采用随机的方法为结点分配树结点,设为Cij,结点标识nid为:nid =hash (cn1,cn2,…,cni,nn),nn为结点名称。
将与实体/结点相匹配并用于生成实体/结点标识的类别,称为该实体/结点的所属类别。
3 发现算法
以结点发现为核心的发现算法,是新增、更新、检索结点和实体等管理过程的基础,下面以实体发现过程为例,阐述基于类别树和静态、动态描述的发现算法。
实体发现过程可划分为生成检索和查找实体两个阶段:
生成检索阶段:①拆分用户的检索请求,得到描述待发现实体的关键字列表keys= {key,key2,…};②使用上述关键字列表遍历类别树,检索树结点的静态描述描述,得到若干匹配的树结点,从中选取k个匹配度较高的树结点。k为系统参数,k越大则查全率越高但消耗的带宽和计算资源也越多;③依据上述k个树结点生成实体标识列表ids= {id1,id2,…,idk};④使用实体标识列表和关键字生成k个查询请求reqs= {req1,req2,…,reqi,… },其中reqi= (idi,keys)。每个请求中均附带完整的关键字列表,此列表用于在查询过程中进一步过滤不满足条件的路由目标 (见查找实体阶段第3步);⑤分别使用上述查询请求查找实体。
查找实体阶段:①访问P2P的任一结点提交查询请求,称此结点为起始点;②依据路由算法,起始点返回若干备选下一跳结点;③考察查询点和备选下一跳结点,从中选取p个更为匹配的结点形成下一跳结点列表。p为并行度,更大的并行度意味着更全面的查询结果和更大的计算、带宽消耗。选择下一跳结点的方法有两种:一是结点id与请求id距离更小;二是结点描述与请求中的关键字列表更为匹配。可综合考虑上述两种方法得到更优的下一跳结点列表;④分别向下一跳结点列表中的结点提交查询请求,得到更多的备选下一跳结点;依据步骤3的方法,从中选择p个更为匹配的结点形成新的下一跳结点列表;循环此步骤,直至下一跳结点列表不再变化;⑤访问下一跳结点列表中的结点,从其实体表中获取备选实体。依据步骤3中的选择方法,选择若干更为匹配的实体返回给查询者。
上述过程中可以明显地看出类别树、静态描述和动态描述的作用。类别树将实体、结点与类别关联起来,形成按类别的实体、结点分布。静态描述用在检索阶段,依托静态描述,以字符串匹配的方式且同时使用多个关键字,检索类别树,综合考虑匹配数目、树结点深度、祖先匹配度甚至和人工选择结合在一起,优选出若干用于查询的标识。而传统算法只能够对单一关键字进行哈希运算产生单一标识,多个关键字分别产生不同的标识符,相互之间完全独立。
在传统算法中,查询所用的标识符与被查询的目标结点是一一对应的,前者一旦确定,后者则相应地也被确定,查询过程只是按路由算法找到标识符对应的这个目标点。而本文中,检索阶段将查询聚焦到与关键字相匹配的若干类别上,查询这些类别对应P2P结点的过程中,使用关键字列表检索下一跳结点的动态描述,修正查询路线,使得查询过程始终围绕关键字进行,不断收敛到与关键字最为匹配的结点上。
查询者在每次查询过程中都要去访问类别树、静态描述和相关类别的动态描述,可采用两种方法降低此过程所需要的带宽开销。对于类别树以及存储在树结点中的静态描述,由于其唯一性且变动频率较小,因此可将其内置到P2P软件中,定期更新即可,无需每次查询都去存储点下载。对于动态描述,考虑到其动态且分散存储的特点,可在P2P系统软件中增加动态描述更新、检索模块,与系统软件一起部署在所有的P2P结点上,需要检索动态描述时,查询者只需发送检索请求至对应的存储点即可。
4 实 验
依据上述方法,我们对p2psim仿真环境进行改造,设计并实现了一个原型系统 (简称SKad)。在Skad存储了若干书籍、文献信息,就信息检索效果做了与Kademlia的对比测试。表1罗列了测试环境及数据构成。
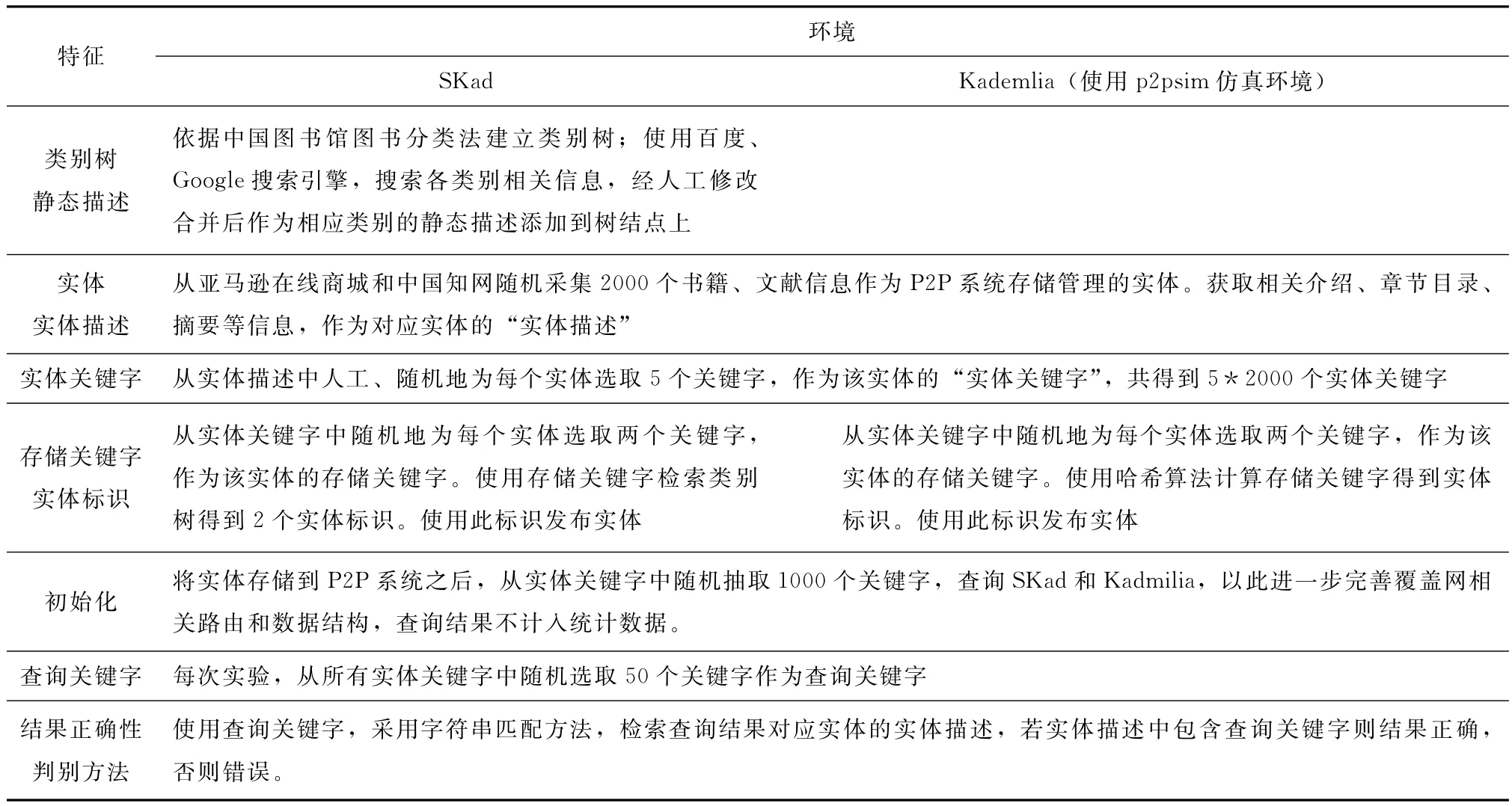
表1 测试环境及数据构成
依托上述环境共进行了五次试验,分别编号为实验1、实验2、…、实验5,各实验得到的总正确结果如图4所示。

图4 总正确结果对比
实验结果显示SKad正确结果明显高于Kademlia,这是符合预期的,因为Skad支持模糊检索而Kademlia只能进行精确匹配。
下面就实验3结果数据进行具体分析。图5描述了本次实验每次查询Skad和Kademlia分别得到的正确结果数。可以看到,50次查询中Kademlia共得到21个正确结果,正确率为0.42;每次查询的正确结果数大多为0、1,很少达到2;结果为非零的查询有20次。对于Kademlia来说,某个查询关键字能否得到有效结果取决于此关键字是否是某实体发布时所使用的关键字。在本实验中,实体发布时所使用的关键字是从5*2000个关键字中随机选取的2*2000个关键字;而查询关键字是从5*2000个关键字中随机选取的50个关键字;因此,对于每个查询关键字来说,其等同于发布关键字的概率为0.4。基于此,查询关键字能够查得结果的概率为0.4,这与实验结果相符。第9次查询结果数为2,这意味着存在两个使用同样关键字进行存储的实体。

图5 实验3正确查询结果对比
观察Skad的查询结果,正确结果数为305,平均每次查询得到6.1个正确结果,显然,在类别树和静态、动态描述的辅助下,Skad查询效果得到显著提升。但同时Skad的正确结果数目波动较大,第21次查询结果数为39,第33次查询结果数为0。考察第21次查询,此次查询选取的查询关键字为 “医疗”,对比类别树可以发现,这种关键字具有较大的覆盖范围,描述医疗类别的书籍和文献都满足条件,因此得到了大量的查询结果。而第33次查询使用的关键字为 “洞室衬护”,此关键字出现在文献 “岩石流变力学及其工程应用研究的若干进展”的摘要中,考察类别树我们发现在此关键字既非类别结点,也未出现在静态描述中,也没有使用此关键字存储或查询过SKad(即未加入动态描述中),故此次查询没有得到正确结果。查询结果的这种波动现象反映出Skad的特点,即SKad的查询效果与类别树结构是否合理、静态描述是否完善、动态描述是否充分、查询关键字选取是否合理等因素紧密相关,第1、2点是系统构建者需要考虑的问题,构建一个较完善合理的类别树、编制详细的类别描述可有效提高查询效果;第3点取决于系统的运行时间和使用频度,运行时机越长,经历的查询越多,则系统累积的动态描述越充分;第4点取决于P2P系统查询者,按照人们的行为习惯,人们往往并不是随机选择关键字,而是选取那些与所查目标关系较为紧密,能够直观描述所查目标的词汇作为查询关键字,这有助于提升Skad发现效果。
5 结束语
本文提出一种基于类别树的、静态和动态相结合的索引机制。类别树中归纳了系统所存储实体的类别,用于形成结点、实体以及查询所需的标识,使得结点组织、实体存储、结点和实体发现均围绕类别分布、实施。静态描述用于依据关键字为结点、实体和查询请求选择类别,选择过程是模糊的,采用字符串匹配的方式,综合考虑各关键字匹配程度、树结点深度、祖先结点匹配程度、查询者喜好等各因素,能够取得充分的、满足查询需求的若干实体类别。当查询成功时,系统会搜集查询所用关键字,累积到对应类别的动态描述中,用于丰富类别描述信息,在查询过程中动态地过滤不满足请求的类别结点,使查询始终围绕查询关键字,不断收敛到满足需求的类别上。
本文同时给出了类别树和静态描述、动态描述的生成时机、管理方法。
本文提出的基于类别树的、静态和动态描述相结合的索引机制,适用于能够对所存储实体进行明确分类的应用领域,实现了结构化P2P中的模糊检索功能。无需集中式索引服务器,无需大量的索引管理工作,有效避免单点失效和性能瓶颈问题。实验证明,本方法相对于传统的结构化P2P网络,具有较好的查询效果。算法已在某服务计算平台中成功应用,此平台已通过验收并连续运行近一年。
今后,我们将研究、测试类别树的结构对网络拓扑和网络负载的影响,同时寻求合适的分词算法,应用到关键字与类别描述文本的匹配过程中,提高检索效果。
[1]Zhu X S.Research on semantic peer-to-peer overlay route model[J].Computer Engineering,2008,43 (13):110-112.
[2]Wang Z X,Zhang D L,Liu L.Study on semantic-supporting search in P2P [J].Computer Engineering and Applications,2007,43 (3):8-11.
[3]Zhang Y J,Gu J H,Wang X Z.A hierarchical P2Psemantic overlay network architecture based on topic and physical proximity [J].Journal of Electronics &Information Technology,2008,30 (8).
[4]Wang C Z,Yang N,Chen H W.Improving lookup performance based on kademlia [C]// Proc of the Second International Conference on Networks Security,Wireless Communications and Trusted Computing,2010:446-449.
[5]Chand R,Cosnard M,Liquori L.Powerful resource discovery for Arigatoni overlay network [J].Future Generation Computer Systems,2008,24 (1):31-38.
[6]Stevens T,Wauters T,Develder C,et al.Analysis of an anycast based overlay system for scalable service discovery and execution [J].Computer Networks,2010,54 (1):97-111.
[7]Liu Z Z,Wang H M,Zhou B.A two layered P2Pmodel for semantic service discovery [J].Journal of Software,2007,18(8):1922-1932.
[8]Wu W M,Wu Y J,Zhao W Y.Chord-based semantic web service discovery [J].Acta Electronica Sinica,2007,35 (B12):152-155.
[9]Zhang Y,Huang H,Yang D,et al.Bring QoS to P2P-based semantic service discovery for the universal network [J].Personal and Ubiquitous Computing,2009,13 (7):471-477.
[10]Di Stefano A,Morana G,Zito D.A P2Pstrategy for QoS discovery and SLA negotiation in grid environment [J].Future Generation Computer Systems,2009,25 (8):862-875.
[11]Zhou J,Dou W.A QoS-aware service selection approach on P2Pnetwork for dynamic cross-organizational workflow development [C]//Proc of the International Conference on Web Information Systems and Mining.Berlin:Springer-Verlag,2009:289-298.
[12]Xie C G,Guo D K,Chen H H.Research on service discovery protocol of global information grid based on peer-to-peer network [J].Computer Engineering,2007,33 (2):97-98.
