基于无锁队列算法的报文分发流水线模型
2013-08-20白正张宏宇王萍
白正 张宏宇 王萍
1中国电子科技集团第二十八研究所 江苏 210007
2海军指挥所 北京 100841
3北航指挥所 山东 266000
0 引言
随着网络速度的不断提升和计算机处理性能的不断提高,对计算机网络报文的处理能力也迅速增加,传统的基于顺序报文处理机制已经不能满足应用对网络的需求。为了适应这样的变化趋势,网络报文接收分发在设计和实现上必须具备更快的处理速度和分发的性能。
基于多核处理器和多处理器系统的并行处理架构成为报文分发处理的必然选择。在各种并行处理模型中,流水线模型在处理网络报文分发中是一种高效的模型。
在流水线处理模型中,各个处理阶段间需要通过设置适当的缓冲数据区,这些处理阶段之间的缓冲就构成了流水线。缓冲数据区的读写效率在很大程度上影响整个流水线系统的吞吐率。
本文采用了生产者/消费者队列模型来描述流水线各处理阶段之间的缓冲数据区读写问题,采用无锁队列操作算法提高系统的效率,满足数据线性化要求和非阻塞属性。
1 模型描述及性能指标
1.1 流水线模型
报文分发软件对于每个数据报文的处理过程可以分为网络报文接收、套接字异步消息、数据报文分发和业务报文通告四个阶段。网络报文的接收由Socket套接字完成;套接字异步消息通过设置Socket套接字异步事件或者异步IO信号;数据报文的分发主要是根据应用层协议区分各类报文的类型分发至各业务程序;业务报文通告是通知业务程序数据已经准备完毕,可以获取数据进行相应处理。因此可以将此流水线分成四级流水线模型(如图1所示)。

图1 报文分发软件流水线模型
根据流水线模型相对顺序模型的加速比公式 Speedup=kn/(k+n-1)(其中n为连续处理n条报文,k为流水线级数)可知,加速比主要由流水线级数决定。
1.2 生产者/消费者队列
在流水线模型中,报文队列是流水段之间的共享数据结构。这是一个典型的生产者/消费者(producer/consumer)队列结构。整个生产/消费模型信息流程关系如图2所示。
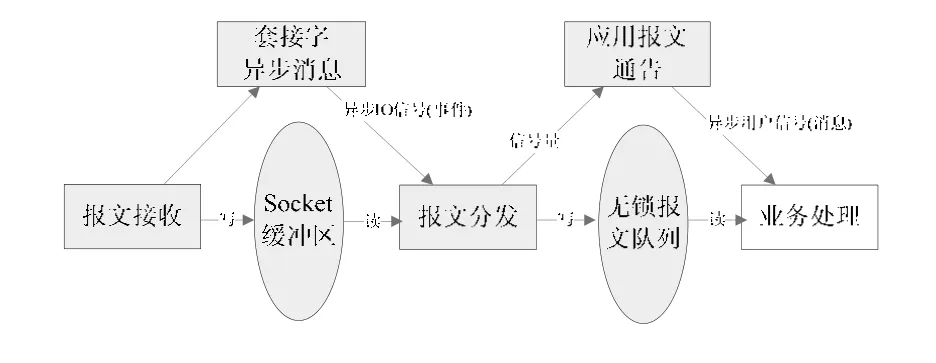
图2 报文分发软件生产/消费信息关系
定义Ω代表整个生产者/消费者系统,Ω由5个元素构成:Ω:{P,C,Q,consume,produce},其中:P为生产者集合,|P|为生产者个数,P={pi|i∈[1,|P|]},集合中的每个元素 pi代表一个独立运行的生产者线程,整个系统中要求至少包含一个生产者线程,即:|P|≥1;C为消费者集合,|C|为消费者个数,C={ci|i∈[1,|C|]},集合中的每个元素 ci代表一个独立运行的消费者线程,整个系统中要求至少包含一个消费者线程,即:|C|≥1;Q 为共享数据队列集合,|Q|为队列个数,Q={qi|i∈[1,|Q|]},集合中每个元素qi表示为一个独立的队列对象;produce为生产操作,生产者线程pi向数据队列对象qj中放置新的数据元素 x 的操作记为:<qj.produce(x),pi>;consume为消费操作,消费者线程ci从数据队列对象qj中获取数据元素y所执行的操作记为:<qj.consume(y),ci>。
对于给定的流水线系统,上述生产者/消费者模型中的P、C、Q 是确定的,需求解的问题为:通过优化设计 produce和consume两个操作算法使其满足在并行执行环境中的评价指标,即正确性(correctness property)、活跃性(liveness property)、效率性(productiveness property)。
2 无锁队列算法
根据图2所示的报文分发软件流水线信息关系模型,整个流水线存在两种共享数据区:一种是Socket缓冲区,是操作系统创建和维护的缓冲区,是Socket套接字自身支持的;另一种是报文分发程序与业务处理软件之间的缓冲区,是本文介绍设计的重点。该缓冲区仅存在一个生产者和一个消费者,因此可以将问题简化为针对单生产者/单消费者(SP/SC)队列的操作算法设计。
2.1 相关算法分析
针对SP/SC队列的并发操作已经有很多经典算法,最直接的算法基于互斥锁的算法,生产者和消费者在操作队列之前获得锁,在操作完成之后释放锁,但是这种锁操作的效率不高,而且算法是阻塞的,操作不当易产生死锁等问题。由于SP/SC系统的特殊性(只有一个生产者和一个消费者),只需要对算法实现进行简单改进即可实现非阻塞操作算法(记为Lamport算法)。Giacomoni 等人在PPoPP08会议上发表了针对Lamport算法的优化算法——Fast Forward算法,通过对Lamport算法的改进,消除了生产操作中对队列HEAD指针的读写和消费操作中对队列TAIL 指针的读写,使得算法在多处理器环境中执行时不会产生处理器缓存频繁同步的问题,执行效率有了进一步的提升。
Lamport算法和FastForward算法是关于SP/SC队列操作的非阻塞的经典算法,可以在并行系统中高效执行。但是,都是采用静态循环数组结构来组织队列元素,对突发流量的时间段很容易产生丢包,因此动态链表的结构形式更适合报文分发流水线模型。
2.2 无锁队列算法
针对SP/SC队列的特点,借鉴Lamport和Fast Forward两个算法的设计思想,提出面向动态链表结构的无锁队列算法,算法实现见图3。无锁队列算法中,借鉴了Fast Forward算法的思想,在报文队列中始终保留一个数据元素,在produce操作中只读写队列的TAIL指针,在consume操作中只读写队列的HEAD指针,从而消除了由于生产者线程和消费者线程访问共享数据变量引起的频繁缓存同步开销,提升算法执行效率。
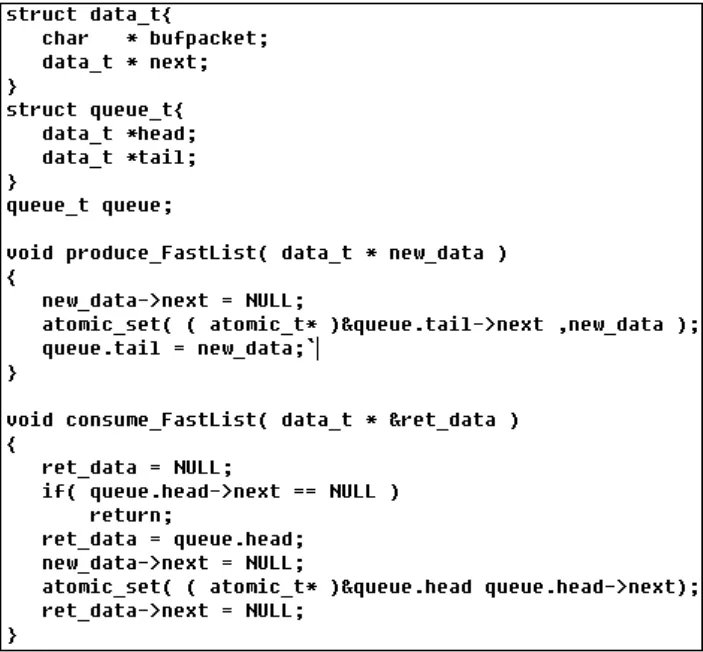
图3 无锁队列算法实现
3 模拟试验
3.1 试验环境
通过模拟试验获得算法的性能衡量指标,试验中选取SPARC64VII2.4GHz处理器作为硬件平台,采用Solaris10构建软件环境。
3.2 试验结果与分析
在测试环境下对Lock-based、Fast Forward和本文介绍的无锁队列算法进行性能测试,测试中生产者和消费者各自连续执行100万次生产操作和消费操作,然后计算平均操作时间。测试结果如图4。
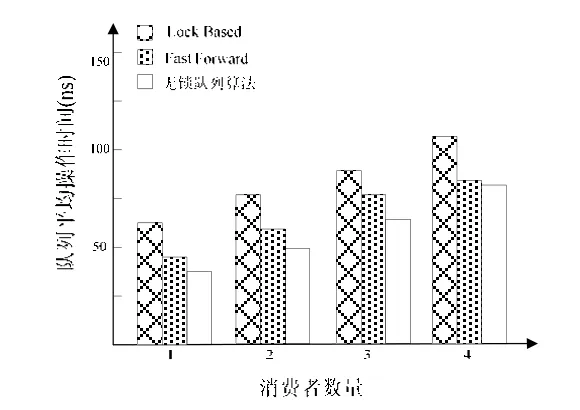
图4 报文分发软件性能测试结果
4 结论
本文针对报文分发软件的流水线处理模型,提出了一种无锁队列算法,该算法采用了动态链表结构,消除了存储空间限制和内存浪费问题;同时该链表通过无锁算法实现更为简洁,效率更高,通过证明试验,在多核多处理器的环境下具有较好的性能指标。
[1] Guo Danhua,Liao Guangdeng,Bhuyan L N,et al.A Scalable Multithreaded L7-filter Design for Multi-Core Servers [C] ∥ANCS’08 , San Jose.California,USA :ACM.2008.
[2]Schuff D L,Choe Y R,Pai V S.Conservative vs.Optimistic Parallelization of Stateful Network Intrusion Detec2tion[C]∥PPoPP’07,San Jose.California,USA:IEEE .2007.
[3]Wu Qiang , Wolf Tilman.On Runtime Management in Multi-Core Packet Processing Systems [C] ∥ANCS’08 ,San Jose.California , USA : ACM .2008.
[4]LamportL.Specifying Concurrent Program Modules[J]ACM Transactions on Programming Languages and Systems.1983.
[5]Giacomoni J,Moseley T,Vachharajani M.Fast Forwardfor Efficient Pipeline Parallelism: A Cache2Optimized Concurrent Lock2Free Queue[C]∥PPoPP’08,Salt LakeCity,USA:ACM.2008.
