LBS中频繁查询时用户隐私保护方法
2013-08-20吕志阳赵炯AhmedAlsayadi
吕志阳 赵炯 Ahmed M.A.Alsayadi
清华信息科学与技术国家实验室(筹) 北京 100086
0 引言
本文提出的方法甚至可以在连续的精确查询情况下对时间相关性很强的LBS的用户提供实时位置隐私。该方法在匿名策略基础上,通过对用户的行进方向上的位置点的信息的提前查询并缓存,来使得追踪者失去对用户即时位置的了解,让用户总是处于一个不确定区域内,这样即使用户在某一标示点上已经被识别出来,也能够保护用户隐私不继续被泄露,防止用户继续被追踪。同时通过对预先查询的时机把握,来使得用户的行进速度也得到保护,防止追踪者从这个信息上对用户进行追踪。用户的不确定区域也可扩大在交叉路口时的产生共同区域的机会。共同区域(Mix Zones),是指当采用了匿名策略后,当两个用户相遇后,对于追踪者来说他们就会变得不可识别,这时相遇点就称为共同区域,当这两个用户分开后,追踪者就不能区分哪一个方向的用户是自己先前追踪的。达到隐私保护的目的。
1 熵模型
LBS由于拥有用户所有的查询记录,可能会滥用这些记录,因而需要针对恶意的LBS建立隐私保护策略。在本文中,恶意LBS被看作追踪者,试图从用户匿名的一系列查询请求中追踪到用户的所在。
我们因此提出了一种熵模型来衡量追踪者的追踪结果,也是对隐私保护算法的一个评价模型。熵值表示追踪者了解到的用户位置的不确定性。对追踪结果的熵值作了分析,分析出了两种熵值:
(1) 对被追踪对象与其他对象的混淆导致的熵值,此处称为个体熵。
(2) 追踪者所能确定被追踪对象实际所处匿名区域的大小,称为位置熵。
个体熵指的是追踪过程中由于被追踪用户与其它用户不可区分而生成的匿名集导致的熵值。Mix Zones策略增加的就是这种熵值。
位置熵指的是被追踪的每个用户实时位置的不确定程度。位置匿名策略通过产生这种熵值来保护用户位置隐私。
图 1中每个阴影区域指的是每个单独被追踪用户的不确定区域,面积越大,说明该用户当前位置熵越大。圆点则是代表实际用户所在,红点是原始追踪目标。三块阴影区域表示当前追踪者已经不能从这三个匿名区域分辨出用户所在。需要注意的是 B区域虽然包含两个用户,但是它们此时处于同一个匿名区域,所以匿名集中用户数量为3,而不是4。
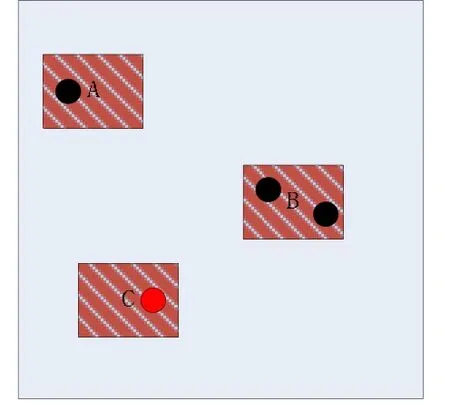
图1 熵模型
这两种熵值可以综合在一起得到一个总的熵值:

S指的是每个匿名区域的用户可能所处位置的数量,我们给单个用户规定了一个区域面积阈值MIN_AREA,当一个用户的不确定区域面积小于MIN_AREA,那么我们认为该用户已经被精确定位了,而 S指的是匿名区域中 MIN_AREA的个数,由匿名区域面积除以MIN_AREA得到。
P指的是当前匿名区域内包含追踪对象的概率。
H则是最终的熵值,表明了追踪者的追踪结果的好坏。
在追踪模型中,每个匿名区域都有个概率值来表示其中包含最初追踪的用户的概率。最初被追踪用户的匿名区域概率值为1,然后在交叉路口遇到另外一个用户的话,形成Mix Zone,之后这两个用户各自的匿名区域的概率为 0.5,但如果是在直道上相向相遇的情况,那么与原运动方向一致的用户的匿名区域概率为p,反向运动的匿名区域概率为1-p,一般情况下,p远远大于0.5,具体数值需要从交通数据中统计得到。所以直道上相遇造成的个体熵不及岔道口。
本文在cachecloak方法基础上做了以下改进:
修改了预测算法,原本的预测算法把整个LBS服务区域分成小块,按照以往用户路径数据分析出每个小块中用户的下一个行进方向。该方法实施起来太过复杂,需要收集以往该区域的用户移动路径数据,并且由于是细粒度预测,预测路径计算起来会非常复杂。对于单个用户来说,他的实际移动路径和统计方法得出的移动路径不一定相符,复杂的计算并不能保证预测结果的准确性。
所以本文使用了电子地图,预测路径是直接沿着用户所在道路向用户前进方向延伸直到交叉路口停止。这种预测方法计算复杂度低,对于移动用户路径的预测准确率高。并且一个地区的地点地图的获取要比用户移动数据的获取容易得多。
对预测路径上预查询算法进行了修改,cachecloak是路径预测完毕后,按照用户请求的频繁程度直接获取路径上所有的查询点,然后一起交给LBS进行查询。该算法并没有考虑到查询路径上不同查询的过期时间点的不同,而且密集查询很容易被追踪者发现。本文提出了一种预查询模型,基于它可以更加有效的调整查询时机,来摆脱追踪,该模型同时也支持解决用户相交的情况。
由此本文提出了一个新的算法,并且使用之前的熵模型进行评价。
2 算法模型
预测算法采用了电子地图来预测用户未来路径,需要考虑到用户行进方向,并且按照用户实际速度,沿着道路行进直到交叉路口。当然该预测算法决定了本方法只适用于公路交通,而不适用于乡村道路。
2.1 预查询算法
预查询即是指当预测了用户未来的行进路径之后,提前获取行进路径上的查询结果。预查询有以下四点目标:
让实际查询 LBS时间与用户请求时间分开,这样 LBS就不能获得用户实时位置,可以产生一个不确定区域,形成位置熵。这里预先查询需要预测算法的支持。
通过控制预测路径上各点的查询时间,来使得用户移动速度不被追踪者识别,防止追踪者通过用户速度来追踪。
由于每个用户都因为预查询产生了匿名区域,只要该匿名区域相交,就可以认为产生了Mix Zone,同样会产生个体熵。如图 2,两个用户虽然没有在交叉路口相遇,但是他们的匿名区域相交,导致产生了个体熵。

图2 十字路口个体熵示意
需要在产生尽可能多熵的情况下保证LBS的可用性,也就是保证预查询结果最终可被用户使用而不是过期。
预查询模型有如下一些假设:
LBS查询过期时间为T,并且在没过期之前,查询结果也会随着时间逐渐失去精确性。
用户速度在一段时间内是恒定的,设为v。
在遇到岔道前,忽略掉道路的宽度与形状,以用户某一时刻的位置为原点的话,前进方向设定为正方向,那么就可以用预测路径上预测点与原点之间的路程距离来表示预测点的位置,这样每个查询都可以表示为(s,t)的二元组,s为查询点位置,t为查询时间。岔道口的处理会在dummu user部分说明。
由以上假设可以得到下面的结论:
(1) 在t>s/v时,查询的时候查询点位置早已经被用户经过,该查询结果已经无用。
(2) 当s/v-t>T时,查询点时间太早,用户到达前查询结果已经过期。
所以(s,t)必须满足 s/v-T<t<s/v,这样的查询点才是可用的查询点,也就是一个位置点必须在用户经过它之前的T时间内进行预查询。
我们使用图3来表示查询点,查询点组成了查询路径。
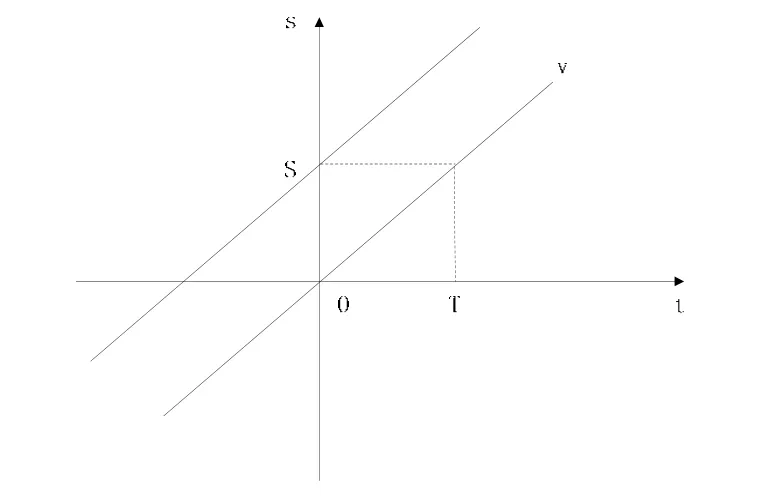
图3 不确定性时空
以用户的当前所在位置与当前时间作为原点,横轴表示预查询的时间点,纵轴表示预查询的位置,过原点的斜线表示用户的 s-t线,由之前讨论可知有效查询点必须位于两条平行的斜线之间。
在这个模型下,我们讨论一下可能的各种预查询方法所采用的预查询路径。
如图4,红线表示预查询路径,这是在cachecloak中采用的预查询方法,每当用户查询时,缓存中没有的话,就会对用户路线进行预测,并且一次取回路线上所有查询结果。这种方法虽然简单,产生的位置熵最大,但是在每次触发对LBS查询的时候,用户的具体位置暴露无疑,位置熵为0,并且这种密集的查询也很容易泄露查询之间的相关性以及用户的前进速度。同时由于每次查询时最远处的查询结果总是在快过期时被用户使用,导致精确性不好。

图4 cachecloak预查询时空模型
图 5表示的是另外一个极端,预查询路径与用户的 s-t线重合。此时查询并没有任何提前,用户是被完全追踪的,用户的位置,速度等信息都泄露,位置熵完全消失。

图5 即时查询时空模型
一般的预查询路径如图 6,预查询路径的斜率是追踪者看到的用户的速度,所以需要随机改变曲线斜率,而且事实上虽然图中查询路径是到了边界然后改变方向,实际却可以超出边界查询(作为假查询),也可以随时转向,这些都是可以随机设置的。这样位置熵就会产生,同时用户真实速度也得到了保护。
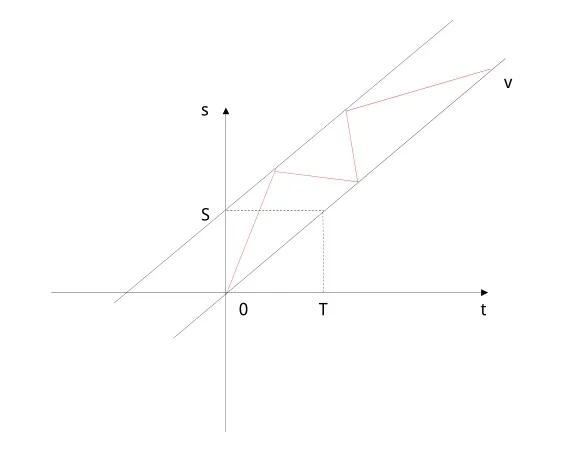
图6 扰乱的预查询时空模型
这里预查询路径的产生是随机的,算法主要决定斜率和转折点。
用户相交时情况如图7表示同向用户相遇,图8表示不同向用户相遇。图中,阴影区域的查询可以被两个用户共用,红线表示最长的公用查询路线。用户相遇可以产生个体熵。但是相对于叉路口,两用户在直道上反向相遇并不能产生1bit的熵值,根据统计规律,两个用户相遇然后同时反向的概率很小,所以此处产生的个体熵远远小于在叉路口产生的个体熵,这点前面熵模型时已经分析过。但是通过假查询,以及设计好各个用户的预查询路径,是可以一定程度提高个体熵的产生值的。
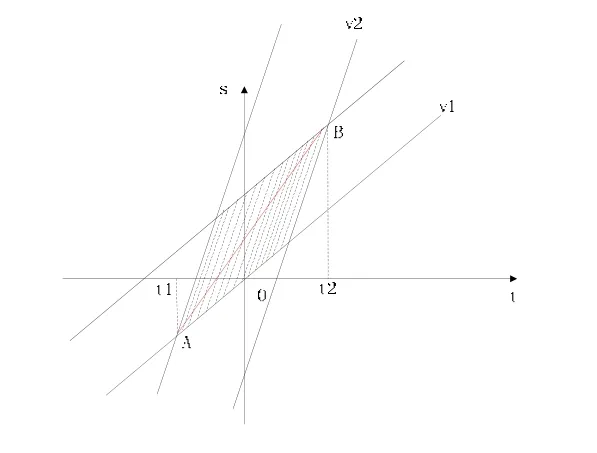
图7 同向相遇不确定时空模型
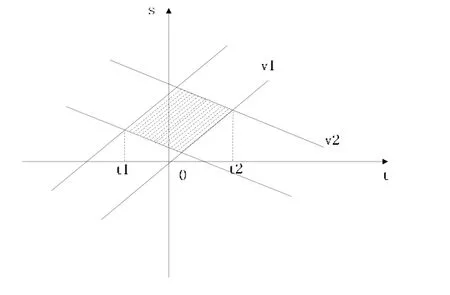
图8 不同向相遇不确定时空模型
设计预查询路径的目的在于:
(1) 使得用户和其他用户相遇时造成有效数量的个体熵;
(2) 保护用户的速度信息。
预查询路径确定之后,然后需要按照用户查询频繁程度来确定具体查询点,用户实际使用查询数据时需要在距当前距离 MIN_AREA范围内搜索最接近的查询点,如果在MIN_AREA内找不到查询点的话,那就需要触发预查询了。但是由于本模型的每个预查询点都是包含触发时间的,不需要额外的触发条件。
2.2 Dummy方法
之前的预测路径只考虑了直道,在岔道口需要采用假用户的方法来产生个体熵。在岔路口相遇的用户会形成 Mix Zone,随之产生个体熵,但是在稀疏环境下这种相遇的机会很少,所以我们需要产生假用户来迷惑追踪者,这里实现方式如下:
(1) 在直道预测路径遇到叉路口时,继续沿所有可能的方向进行预查询;
(2) 在用户到达岔路口时,在没有与其他用户的匿名区域相交的方向上都产生一个dummy user,沿着各条路径继续运动下去。
Dummy user的预查询路径也是完全随机产生,它的消亡条件如下:
(1) 遇到其他用户;
(2) 查询数超过阈值;
(3) 到了下一个岔路口。
这样就可以最大限度的利用岔路口的优势来增加熵值。
对于稀疏应用来说,假请求也不会给服务器带来很大负担,并且在用户逐渐多起来之后,假请求也会越来越少,这是一个良性发展的解决办法。Dummy方法需要一个衡量标准,也就是假查询的数量与熵值增加的比。
3 结论
本文针对城市交通中用户频繁查询不可信的时间相关性很强的LBS时的隐私保护问题,在cachecloak方法的基础上进行了改进,使得用户得到的查询结果更加准确,同时也增加了追踪者的追踪难度。
先对追踪者进行了分析,提出了两种熵的概念以及计算公式,分析了以往隐私保护算法中对两种熵值的影响。然后提出了预查询模型,很好的表现了用户查询之间的时空相关性,同时也通过分析预查询模型来产生预查询路径,用来提高熵值。dummy user的使用让稀疏的应用也可以在岔路口增加熵值。
在实际中我们可以根据应用本身的特点如即时性需求和位置精确度要求,来根据熵模型选择合适的预查询策略,来达到隐私保护的目的。
[1]MOKBEL, C.C.F.Casper*: Query processing for location services without compromising privacy[J].ACM Trans Database Syst 34,2009.
[2]Meyerowitz, J.& Roy Choudhury, R.Hiding stars with fireworks: location privacy through camouflage.Proceedings of the 15th annual international conference on Mobile computing and networking 345-356 (2009).
[3]Meyerowitz, J.& Choudhury, R.Realtime location privacy via mobility prediction: creating confusion at crossroads.HotMobile 1-6 (2009).
[4]L.Sweeney.k-anonymity: a model for protecting privacy.International Journal on Uncertainty,Fuzziness and Knowledgebased Systems.2002.
[5]Pan Xiao, Hao Xing, Meng Xiaofeng.Privacy Preserving towards Continuous Query in Location-based Services.JOURNAL OF COMPUTER RESEARCH AND DEVELOPMENT
