基于马氏距离判别法的企业资信评估
2013-08-16高洪波马素萍
高洪波,马素萍
(南通广播电视大学科研处,江苏 南通 226006)
随着我国经济的高速发展,作为市场经济的金融市场发展速度不断加快,逐渐与世界经济接轨,我国经济形态也更趋向于信用经济。资信评估作为市场经济中的监督力量,在很大程度上可降低信息不对称性,能够为评价企业的资信水平提供重要参考依据。科学准确的资信评估可以辅助决策,降低投资风险。因此,如何提高企业资信评估的准确性和科学性极其重要[1]。企业资信评估是以独立经营的企业或经济主体为对象,根据企业及经济主体的生产、经营、管理前景及当前的企业经济效益状况,给出企业的资信评级,本质上是属于综合评价中的分类问题。经济社会活动中判断一个企业是否守信用,可牵涉到多个数据指标,如资产负债率、现金流量、流动资产、销售利润率、存贷比、利息偿还率等,如何从这些数据中判定企业的信用、财务状况,从而准确地标记出企业的资信等级是一个较为复杂的问题[2]。资信评估通常采用基于统计学的分析方法,包括线性回归分析法、多元判别分析法等。然而传统的统计学评估方法有较大的局限性,存在着诸如权重确定缺乏理论依据、带有明显主观臆断且运算量大等缺点,已经无法满足实际应用的需要。近年来随着科学技术的飞速发展,尤其是计算机技术的突飞猛进,基于计算机处理的距离判别法、贝叶斯判别、FISHER判别等方法在综合评价中的分类问题有了较大的突破和广泛应用。本文将基于Matlab实现的距离判别法应用于企业资信评估,并给出了实例来验证该方法在企业资信评估中财务状况方面评价的可靠性。
1 距离判别法原理
判别分析方法是一种有效的多元数据分析方法,它能从各训练样本中提取各总体的信息,科学地判断得到的样品属于什么类型,现已在很多领域广泛应用。马氏距离是由印度统计学家马哈拉诺比斯(P.C.Mahalanobis)提出的,表示数据的协方差距离,是一种有效的计算两个未知样本集的相似度的方法。
1.1 马氏距离
设G为n维总体,其分布的均值向量和协方差矩阵分别为:
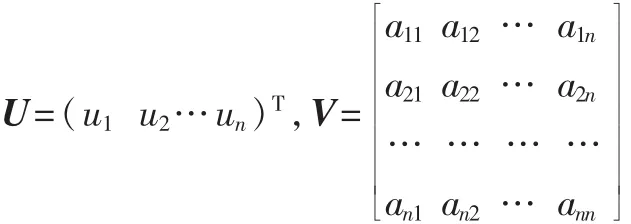
设 x=(x1,x2, … ,xn)T,y=(y1,y2, … yn)T为 取 自 总 体G的两个样品,假定 V>0(V为正定矩阵),定义 x,y间的平方马氏距离为:
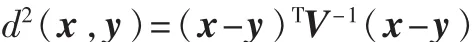
定义x到总体G的平方马氏距离为:
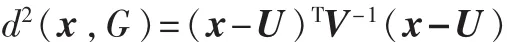
1.2 马氏距离判别法
可分为两个总体与多个总体判别,实际上多个总体判别可归结为两个总体判别,即多个总体判别可视为两个总体判别的推广。以下介绍两个总体距离判别原理。
设有两个n维总体G1和G2,分布的均值向量分别是 U1,U2,协方差矩阵分别是 V1>0,V2>0。从两个总体中分别抽取容量为 n1、n2两个样本, 记为 x11,x12…,x1n1和x21,x22,…,x2n2。 现有一未知类别的样品,记为 x,则可用以下的判别规则进行判断:
(1)若 d2(x,G1)<d2(x,G2),则 x∈G1;
(2)若 d2(x,G1)>d2(x,G2),则 x∈G2;
(3)若 d2(x,G1)=d2(x,G2),则待判。
1.3 基于Matlab的距离判别法的实现[3-5]
Matlab统计工具箱中提供了classify函数,用来对未知类别的样品进行判别,可以进行距离判别和先验分布为正态分布的贝叶斯判别,其调用格式如下:
class=classify(sample,training,group,type)
输入参数sample是待判别的样本数据矩阵,training是用于构造判别函数的训练样本数据矩阵。它们的每一行对应一个观测值,每一列对应一个变量,sample和training具有相同的列数,该函数将sample中的每一个观测值归入training中观测值所在的某个分组。参数group是与training相应的分组变量,参数group是与training具有相同的行数,group中的每一个元素指定了参数group是与training中相应观测值所在的组。group可以是一个分类变量、数值向量、字符串数值或者是字符串元胞数组。输出参数class是一个行向量,用来指定sample中各个观测值所在的组,class和group具有相同的数据类型。参数type的取值决定了classify函数支持的判别类型,其 中 有 五 种 可 选 参 数 , 即 linear、diaglinear、quadratic、diagquadratic及mahalanobis。当type参数取前四种值时,该函数可用来作贝叶斯判别;当取值为mahalanobis时,该函数用作距离判别,并且所计算的先验概率用来计算误判概率。
2 企业资信中财务状况评估模型构建[6]
2.1 企业资信评估指标选取
企业资信评估通过分析独立经营企业资产实力、偿债能力和信用风险程度等,从而确定该企业的信用等级,使管理者掌握企业经营状况,帮助金融机构决策者对企业进行评价和选择。资信评估包括资产评估和信用评估两个方面,本文选择4项评价指标对企业的财务状况进行评价:
X1=现金流量/总债务
X2=净收入/总资产
X3=流动资产/流动债务
X4=流动资产/净销售额
表1是相关企业年度财务数据,其中收集了21个破产的企业在破产前两年的年度财务数据,同时对25个财务状况良好的企业也收集了同一时期的财务数据进行距离判别,找出未判别的四家企业的财务状况的情况,判别是否处于破产状态。
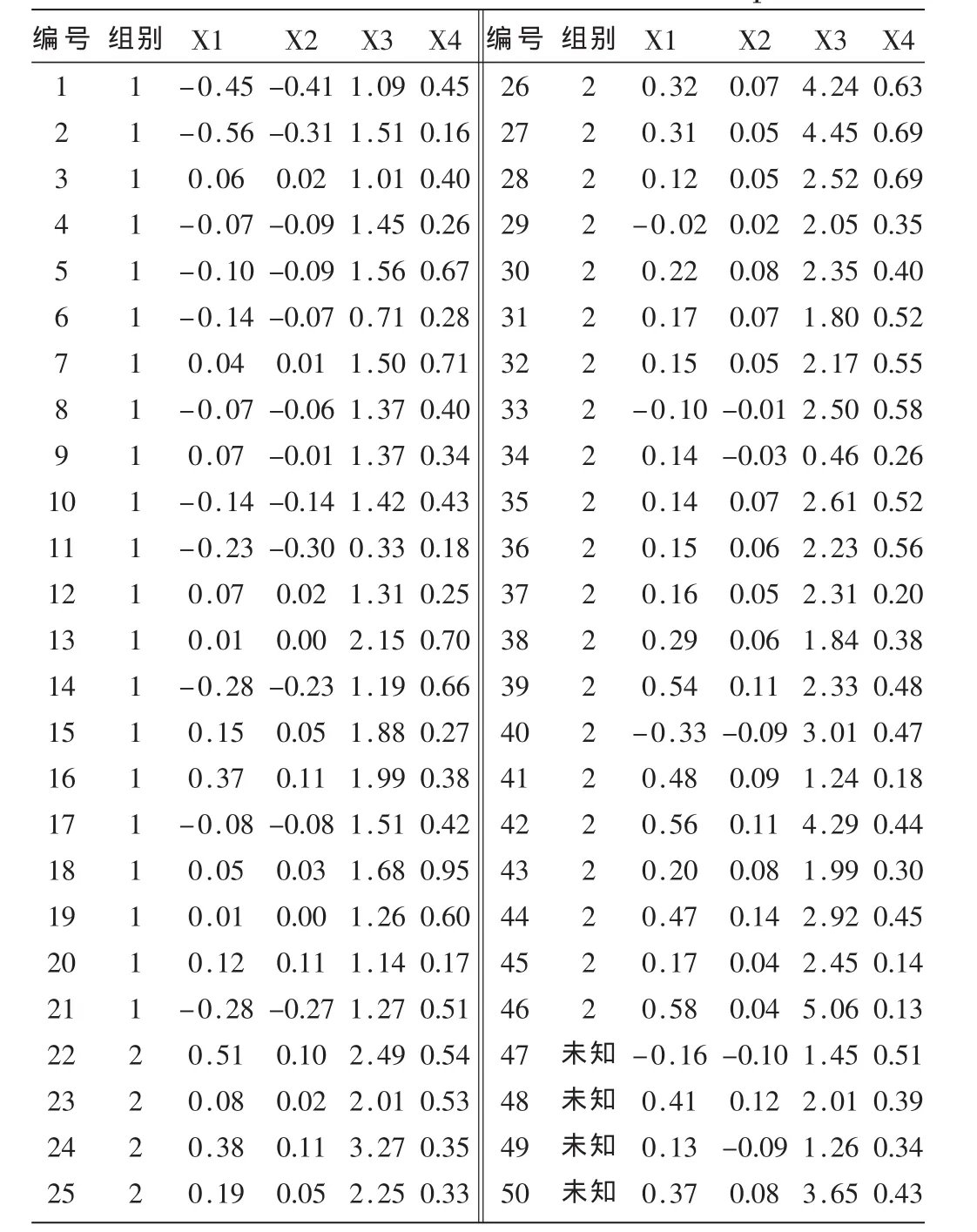
表1 相关企业年度财务数据表example.xls
2.2 基于Matlab的距离判别过程
(1)读取数据
读取文件example.xls的第一个工作表中 C2:F51范围的数据,即全部样本数据,包括了未判企业数据。
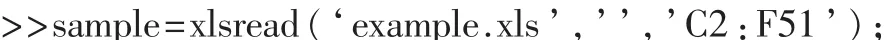
读取文件 example.xls的第一个工作表中 C2:F47范围的数据,即已知组别的样本数据。
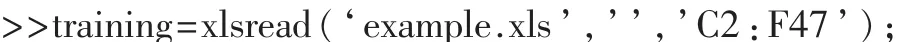
读取文件 example.xls的第一个工作表中 B2:B47范围的数据,即样本的分组信息数据。
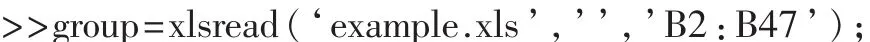
列出企业编号
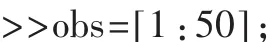
(2)进行马氏距离判别,返回判别结果向量C和误判概率err

得出判别结果如表2所示。

表2 马氏距离判断结果
从表中可以看出,共有3个观测值发生了误判,即是第 15、16和 34号,其中第 15和第 16号由第 1组(财务良好)误判为第2组(破产企业),而第34号观测值原本属于第2组误判为第1组,用 P(j|i)来表示原本属于第I组的样品被误判为第J组的概率,则误判概率的估计值分别是:
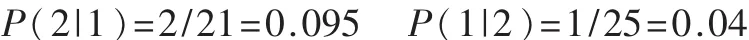
假设两组的先验概率均为0.5,则classify函数的误判概率是:
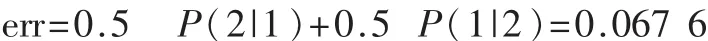
可见该马氏判别的结果是可以令人接受的且基本是合理的。表2中的第47~50号企业是未判企业的观测值,即未知组别的样品。由以上结果可知,第47号和第49号企业的观测值判归第1组,从而判定它们是破产企业,第48号和第50号企业的观测值被判归为第2组,它们为非破产的财务状况良好的企业。
本文提出将基于距离判别算法用于企业资信评估,该方法具有以下优点:(1)与资信评估常用的统计学方法不同,该方法无需事先建立数学模型,只需将从各训练样本中提取各总体的信息,科学地判断得到的样品属于什么类型,评价过程方便、快捷。(2)不需要人为确定权重,从而避免由于评价过程中的主观因素所导致的结果失真。(3)使用基于距离判别算法,即便出现误差,也可通过假设的先验概率计算误判概率,得出较为客观的结论,其评价结果比传统的统计学方法更为客观、有效。
[1]刘重才,周洲,梅强.LVQ神经网络在企业资信评估中的应用[J].集团经济研究,2007(10):50-51.
[2]李翀,夏鹏.后验概率支持向量机在企业信用评级中的应用[J].计算机仿真,2008,25(5):256-258.
[3]苏金明,张莲花,刘波.Matlab工具箱应用[M].北京:电子工业出版社,2004.
[4]董维国.深入浅出 Matlab7.X混合编程[M].北京:机械工业出版社,2006.
[5]张润楚.多元统计分析[M].北京:科学出版社,2006.
[6]郑志勇.金融数量分析[M].北京:航空航天大学出版社,2009.
