恶劣天气下高速公路实时事故风险预测模型
2013-08-16徐铖铖李志斌
徐铖铖,刘 攀,王 炜,李志斌
(东南大学 交通学院,南京 210096)
文献[1-3]研究表明:雨天发生的交通事故是正常天气条件下的1.5倍以上。文献[4-5]研究发现:冰雪天气不仅增加了交通事故总量,也增加了伤亡事故的数量。
随着高速公路智能交通系统的不断运用,海量高精度交通流数据的获取越来越容易。许多学者开始研究基于实时交通流数据的高速公路实时事故风险预测模型(Real time crash risk prediction model)[6-11]。与用来预测交通事故的频率的传统事故预测模型不同,实时事故风险预测模型用来预测交通事故发生的概率。
目前高速公路实时事故风险预测模型只考虑了实时交通流参数(如速度差、交通流密度和上下游断面速度差等)对交通事故风险的影响,忽略了恶劣天气对交通事故风险的影响[6-12]。因而,本文研究了基于实时交通流数据和天气数据的交通事故风险预测模型。该模型是对已有交通事故风险预测模型的改进,它不仅能够量化恶劣天气条件对实时事故风险的影响,而且可以提高实时事故风险预测模型的预测精度。
1 研究路段与数据特征
由于国内高速公路交通流检测设备的布设密度相对较低、交通流数据的采集精度相对较低以及历史交通流数据保存不完整等原因,论文提取了美国加州I-880N高速公路从桩号22.78(英里)到桩号37.07(英里)约23公里路段的数据,用来建立实时事故风险预测模型。提取的数据包括30s精度的交通流数据、事故数据和气象数据。在该研究路段中,单向共有29组交通流线圈检测器和2个环境气象监测站。各组线圈和气象监测站的位置如图1所示,线圈之间距离的平均值约为0.8km,2个环境气象监测站之间的距离约为10km。
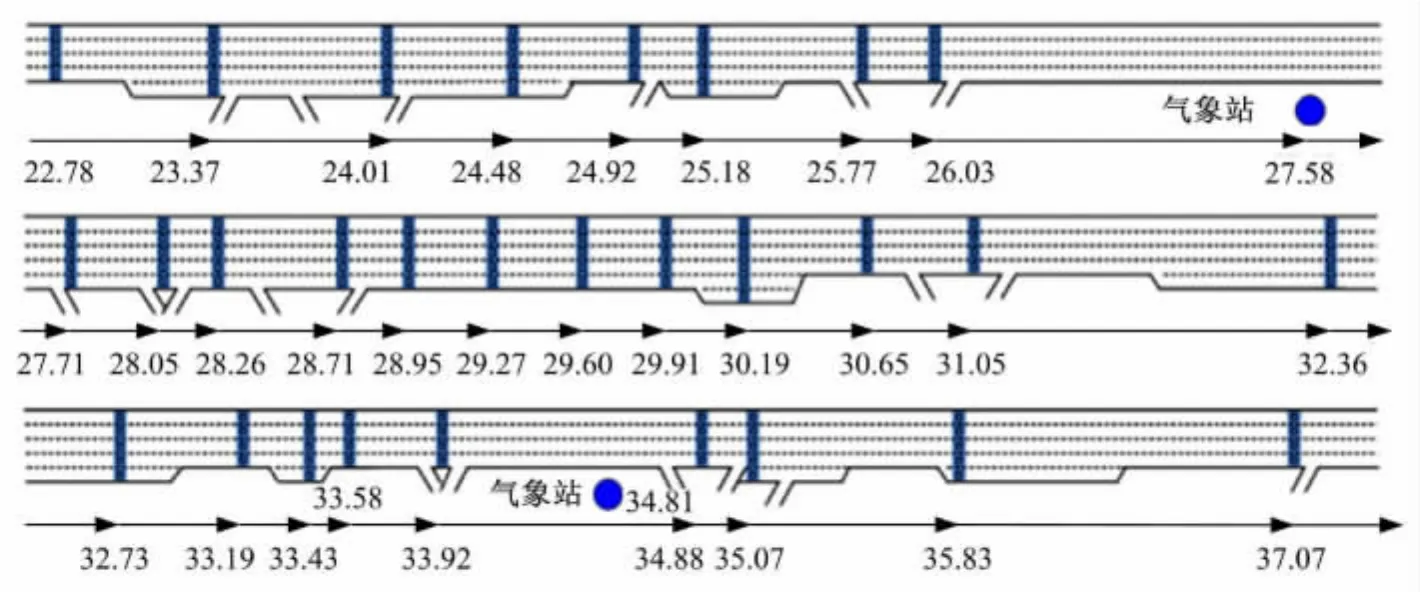
图1 I-880N高速公路线圈和气象站分布点位Fig.1 Locations of loop detector stations and weather stations on selected segment of I-880Nfreeway
论文提取了研究路段从2010年1月到2010年12月的交通事故数据和对应的实时交通流数据,总共包含有效事故样本477起。图2给出了I-880N整条高速公路从2010年1月到2010年12月交通流数据的有效率,本文选取图2中桩号为22.78到37.07路段的交通流数据有效率基本都在80%以上。说明所选取的交通流数据具有较好的质量。
研究路段上交通流线圈检测器采集的间隔较短,为30s。采集的交通数据包括速度、流量和占有率3个参数。由于交通流数据采集间隔较短,容易导致较多的数据噪声,从而使得分析结果受到影响。因此,论文将原始交通流数据汇集到5 min,计算各个交通流参数的平均值和标准差[6-8]。由于交警部门记录的交通事故发生时间往往晚于实际的交通事故发生时间,因而这里需要对交通事故的实际发生时间进行校准[6-8]。交通事故的发生会对交通流运行状态造成扰动,并且这种扰动会以冲击波的形式往上游传播。如图3所示,在L1与L2线圈中间发生了一起事故,在事故发生地点的车辆速度会迅速降低,并且以冲击波的形式往上游传播,因而上游线圈的速度也会出现突变。由于交通事故发生时间T1和下游线圈出现突变的时间T2非常接近[10],因而可以利用上游线圈速度出现突变的时间T2代替交通事故的实际发生时间T1。
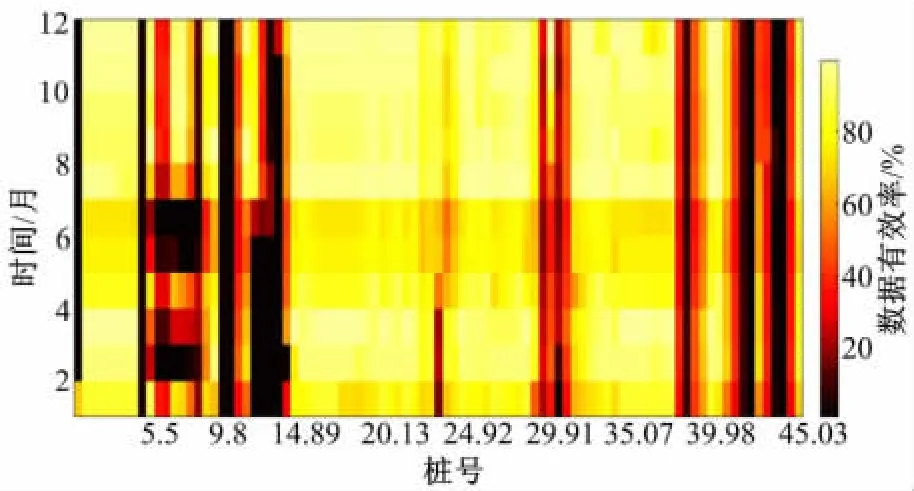
图2 I-880N高速公路线圈交通数据有效率Fig.2 Data quality map for I-880NFreeway

图3 事故发生时间校准示意图Fig.3 Illustration of estimation of crash occurrence time based on speed and occupancy data
采用“案例-对照”方法提取研究数据,其中“案例”为交通事故发生前的交通流和天气条件,“对照”为没有发生事故条件下的交通流和天气条件。“对照”和“案例”的比例采用了最常用的4∶1比例。对照组数据的选取考虑了如下4个条件:①对照组所在日期与对应事故所在的日期不同;②与事故发生时间相同;③与事故发生地点相同;④对照组所在当日在该处没有事故发生。论文提取了2组相邻线圈的交通流数据,1组线圈在事故发生地点的上游,1组线圈在事故发生地点的下游。如图4所示,这2组线圈分别命名为线圈1和线圈2。
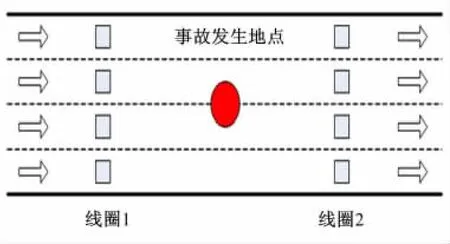
图4 研究所需线圈示意图Fig.4 Layouts of 2loop detector stations for each crash
为了对交通事故进行提前预测,论文提取了事故发生前15~10min这段时间内的交通流数据,同时对应于每起事故,利用上述方法提取了4组没有发生事故条件下的交通流数据。例如编号为802的事故发生在桩号27.4处,发生时间为2010年1月2日13∶23pm。提取2010年1月2日13∶08pm到13∶13pm(如图4所示2组线圈)的交通流数据作为一个“案例”;并在该处随机选取4天从13∶08pm到13∶13pm的交通流数据作为对应的4个对照,并且这4天在该处都没有交通事故发生。事故组(案例组)共包含477个样本,而非事故组(对照组)共包含1908个样本。
事故组和非事故组中各个样本对应的天气特征参数通过桩号和时间进行匹配。对于事故组和非事故组中每个样本,选取与其距离最近的气象站数据。由于气象站数据的精度为1h,因而选取与事故发生时间最近的气象数据作为该条样本的天气特征参数。表1给出了事故组和非事故组的样本在不同天气条件下的分布情况。

表1 事故组和非事故组在不同天气条件下的分布Table 1 Distributions of crash and non-crash cases under different weather conditions
2 数学模型
2.1 Logistic回归模型
利用二项Logistic回归模型建立基于实时交通流和气象数据的高速公路交通事故风险预测模型。二项Logistic回归模型常用来定量分析解释变量对二分类因变量的影响,同时可用来估计因变量某分类出现的概率。研究样本中某条数据对应的事故发生概率如下:
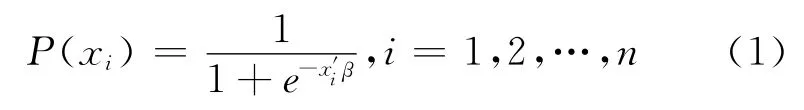
经过logit变换以后的线性表达为

式中:P(xi)代表发生交通事故的概率;x′iβ 代表解释变量的线性组合,即:
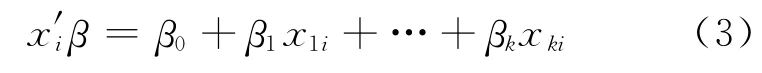
式中:xki代表样本i中变量k的值;β0为回归截距;β1,β2,…,βk为解释变量xki对应的回归系数;β0,β1,β2,…,βk可以通过最大似然估计方法进行计算,似然函数的表达式如下:

2.2 Logistic模型检验
在Logistic回归中,似然比检验和分类预测精度通常用来反映模型的拟合优度和模型的预测精度。模型的全局似然比可以用来反映最终模型的拟合效果是否显著优于只含有常数项的无效模型的拟合效果,其表达式为
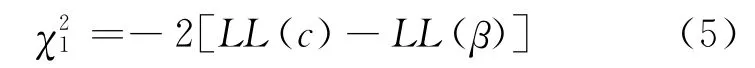
式中:LL(β)代表最终模型的对数似然函数值;LL(c)代表只含有常数项无效模型的对数似然函数值。
同样,似然比检验还可以用来检验加入某个(些)参数后,模型的拟合效果是否被显著提高。论文利用似然比检验来分析含有天气参数模型的拟合效果是否显著优与不含天气参数模型的拟合效果,其表达式为

式中:LL(β1)代表不含天气参数模型的对数似然函数值;LL(β2)代表含有天气参数模型的对数似然函数值。
利用Logistic模型对分类进行预测时,需要指定概率阈值,即,当由Logistic模型计算得到的概率值大于指定阈值时,判别为交通事故;而当概率值小于指定阈值时,判别为非事故,即安全状态。阈值的大小直接决定各个分类的预测精度和总样本的预测精度,已有研究常用某个分类在整体样本中的比例作为预测该分类的阈值[13]。论文研究高速公路交通事故的实时预测方法,因而取事故样本在整体样本中的比例0.2作为阈值。
3 研究结果与讨论
3.1 模型参数选择
论文利用高速公路上线圈检测器采集的交通流数据和环境气象站采集的气象数据建立高速公路事故风险预测模型。在交通流数据中选取了如下4组参数作为模型的待选参数:①5min内线圈检测参数的平均值;②5min内线圈检测的标准差;③5min内上游线圈与下游线圈差值的平均值;④5min内上游线圈与下游线圈差值的标准差。通常线圈检测器采集的交通流参数包含流量、占有率和速度3个变量,因而总共有18个交通流参数作为模型的待选变量。
通常环境气象站检测的数据包含温度、相对湿度、能见度、云量、降雨量、风速风向和天气状况。论文选用这7个参数作为天气条件的备选参数。表2给出了各个交通流参数和天气参数的描述性统计分析结果。论文利用统计分析软件SPSS的Binary Logistic regression模块建立高速公路实时事故风险预测模型[14]。由于待选变量较多,论文采用如下步骤建立模型:
(1)对每一个参数执行一次二项Logistic回归(单变量Logistic回归),选取与事故发生相关的参数作为后续步骤的待选变量。
(2)利用Pearson相关系数或者卡方检验来检查各个变量之间的相关性,使待选变量中不含高度相关的变量。
(3)利用Logistic回归中的正向逐步回归方向选择模型的合理解释变量;模型保留变量的显著性水平设定为:选入变量为P≤0.05,剔除变量为P>0.10。
3.2 模型标定结果
采用上述建模步骤,利用交通流参数和气象参数作为待选参数,最终得到的模型如表3所示。表3中的Wald卡方值表明上游线圈占有率、上游线圈速度标准差、下游线圈占有率和天气状况对高速公路交通事故风险有显著影响。其中天气状态的比值比(Odds ratios)可以用来量化恶劣天气条件对事故风险的影响。以天气状况1(雨天)的比值比作为例子进行说明,雨天的比值比可以通过如下步骤进行计算:

x1、x2、x3为交通流参数,β1、β2、β3为交通流参数的系数,雨天的比值比eβ4=6.443,因而雨天交通事故风险是晴天交通事故风险的6.443倍。如表3所示,雾天的比值比为4.432,因而雾天交通事故风险是晴天交通事故风险的4.432倍。由于在雾天驾驶员会更加谨慎驾驶,因而雾天的比值比要略小于雨天的比值比。
为了检验天气参数的加入能否显著提高模型的拟合精度,论文还建立了不含天气参数的交通事故风险预测模型,仍然采用3.1节中参数选择步骤,最终模型拟合结果见表4。
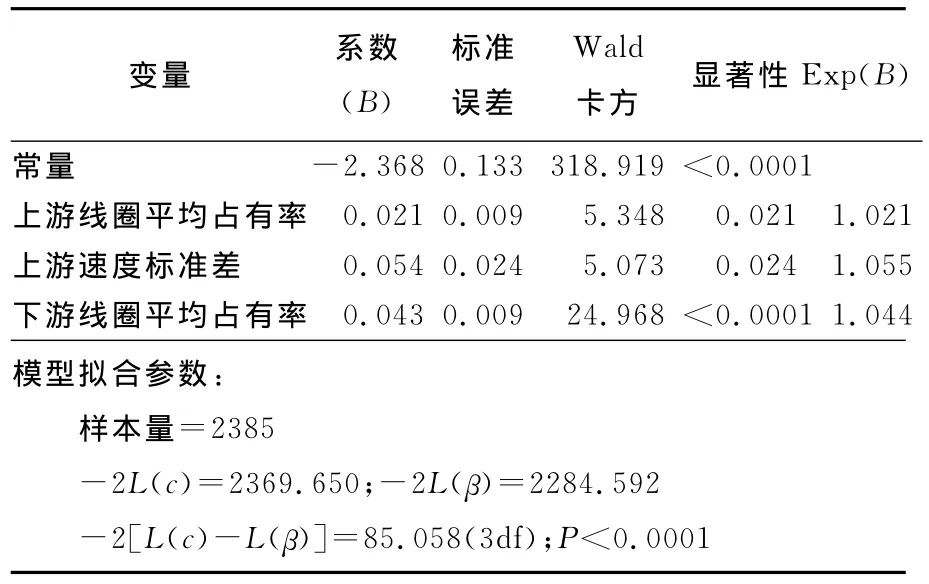
表4 不含天气条件参数的模型估计结果Table 4 Estimation results of logistic regression model without weather conditions variables
利用式(6)计算两个模型最终-2log likelihood值之间差值即χ2=2284.592-2137.898=146.694;式(6)的自由度为2个模型自由度之差,即df=5-3=2,P<0.0001,因而天气条件参数的加入,在统计学意义上能够显著提高模型的拟合精度。
3.3 模型预测精度对比
在指定合理的阈值后,标定后的模型可以对高速公路交通事故进行实时预测。由于在总样本中,事故样本所占的比例为20%,因而这里将阈值设定为0.2,即当模型输出的概率值大于0.2时,判别为交通事故;而当模型输出的概率值小于0.2时,判别为安全状态,不会发生交通事故。如表5所示,模型1(含天气参数)能够预测样本中57.2%的事故和75.3%的非事故,总预测精度达到71.7%。因而,本文建立的事故风险预测模型能够利用实时交通流数据和天气数据,对高速公路交通事故进行较好的实时预测。
表5中,模型2(不含天气参数)对事故组的预测精度为51.6%,非事故组的预测精度为70.3%,总预测精度为66.5%。本文采用McNemar-test来检验模型1的预测精度是否显著优于模型2的预测精度。McNemar-test是一种非参数检验方法,可以用来检验2个相互有关联的离散变量的均值是否相同,常用来比较2种分类方法对同一样本的预测精度[15]。检验结果表明,模型1的预测精度显著优于模型2的预测精度(χ2=11.766,P<0.001)。

表5 模型1与模型2预测结果对比Table 5 Prediction accuracy of model 1and model 2
4 结束语
研究了基于实时交通流参数和天气参数的高速公路实时事故风险预测方法。提取了美国加州I-880N高速公路的交通流数据和气象数据,采用Logistic回归模型建立高速公路交通事故的实时预测方法。研究结果表明天气参数显著影响交通事故发生概率,雨天和雾天的比值比分别为6.443和4.432,代表雨天和雾天发生交通事故的概率是晴天的6.443和4.432倍。天气参数的加入能够显著提高事故风险预测模型的预测精度,含有天气参数的模型能够预测57.2%的交通事故,因而该模型能够对高速公路交通事故进行较好的实时预测。由于交通事故风险受到驾驶人特征、车辆特性和道路条件的影响,因而本方法在实际运用之前,还需要利用将来国内高速公路的高精度交通流数据和气象数据进一步验证本文的研究结果。
[1]Qiu L,Nixon W A.Effects of adverse weather on traffic crashes systematic review and meta-analysis[J].Transportation Research Record,2008,2055:139-146.
[2]Brodsky H,Hakkert A S.Risk of a road accident in rainy weather[J].Accident Anal Prevention,1988,20(2):161-176.
[3]Andrey J,Yagar S.A temporal analysis of rainrelated crash risk[J].Accident Anal Prevention,1993,25(4):465-472.
[4]Khattak A J,Knapp K K.Interstate highway crash injuries during winter snow and nonsnow events[J].Transportation Research Record,2001,1746:30-36.
[5]Eisenberg D,Warner K E.Effects of snowfalls on motor vehicle collisions,injuries,and fatalities[J].American Journal of Public Health,2005,95(2):120-124.
[6]Abdelaty M,Uddin N,Abdalla F,et al.Predicting freeway crashes based on loop detector data using matched case-control logistic regression[J].Transportation Research Record,2004,1897:88-95.
[7]Abdel-aty M,Uddin N,Pande A.Split models for predicting multi-vehicle crashes during high-speed and low-speed operating conditions on freeways[J].Transportation Research Record,2005,1908:51-58.
[8]Abdelaty M,Pande A.Identifying crash propensity using specific traffic speed conditions[J].Journal of Safety Research,2005,36(1):97-108.
[9]Lee C,Saccomanno F,Hellinga B.Analysis of crash precursors on instrumented freeways[J].Transportation Research Record,2002,1784:1-8.
[10]Lee C,Hellinga B,Saccomanno F.Real-time crash prediction model for application to crash prevention in freeway traffic[J].Transportation Research Record,2003,2749:67-77.
[11]Hossain M,Muromachi Y.Evaluating location of placement and spacing of detectors for real-time crash prediction on urban expressways[C]∥The 89th Annual Meeting of the Transportation Research Board,Washington,D.C.,2010:1-15.
[12]Zheng Z,Ahna S,Monsere C.Impact of traffic oscillations on freeway crash occurrences[J].Accident Analysis and Prevention,2010,42(2):626-636.
[13]Jung S,Qin X,Noyce D A.Rainfall effect on single-vehicle crash severities using polychotomous response models[J].Accident Analysis and Prevention,2010,42(1):213-214.
[14]张文彤.SPSS11统计分析教程[M].北京:北京希望电子出版社,2002:91-99.
[15]Lensberg T,Eilifsen A,McKee T E.Bankruptcy theory development and classification via genetic programming[J].European Journal of Operational Research,2006,169(2):677-697.
