基于BWDSP指令Cache的PLRU替换算法研究
2013-08-13洪兴勇
洪兴勇 ,洪 一 ,2
(1.合肥工业大学 计算机与信息学院,安徽 合肥 230009;2.中国电子科技集团第38研究所,安徽 合肥 230031)
自1978年以来,我国的集成电路用量和产量几乎以平均每年20%的速度同步增长,集成电路生产中心也在向中国大陆转移,使我国IC产业迅速发展。目前IC制造工艺水平已达到28 nm,为设计高性能DSP系统打下了牢固的基础。DSP处理器速度与存储器速度之间的差异是DSP体系结构设计的一个瓶颈问题,在DSP处理器的存储层次中,Cache是离处理器内核最近的一层存储器,而Cache技术是有效解决DSP处理器的存储层问题的重要技术[1]。可以依据Cache的速度和命中率来配置Cache的参数,使Cache的性能达到最佳[2]。
1 BWDSP处理器总体结构
BWDSP处理器是中国电子集团第38研究所自主研制的一款32 bit静态超标量处理器,采用8发射、11级流水线、SIMD架构。处理器指令总线宽度为512 bit,数据总线位宽为256 bit;指令存储空间和数据存储空间在物理上是分开的,指令存储空间大小为2 MB,指令Cache空间为512 KB,数据存储空间为8 MB;取指程序计数器每变化一次,从指令Cache中取出8条指令为一个256 bit指令包进入指令流水线。BWDSP处理器的执行部件包含在4 个执行宏中,分别为 macro x、macro y、macro z、macro t。指令译码单元解析从指令包中得到的并行指令,并决定指令在那些执行宏中运行,进而为指令分配对应执行宏中的执行资源,并且把指令翻译为微操作,发射到4个执行宏。高性能DSP处理器总体结构如图1所示。

在高性能DSP处理器上对指令进行重复访问时,指令Cache的失效次数与指令空间大小的关系:首先计算第一次重复访问时的失效次数。设程序指令大小为M,即M0=M/512个Cache行。当M≤512 KB时,程序被访问后,指令Cache每一组内至多包含一个Cache行的有效指令数据,不会因为冲突失效而发生替换,所以再次执行程序时,不会使指令Cache发生失效;当M在512 KB~1 024 KB时,访问完一遍之后,前 512个 Cache行的数据会填充每组内的一个Cache行,而超过512个Cache行的部分,每个Cache行的指令数据有1/4的概率替换掉有效数据,因此,被替换出去的Cache行数约为(M0-512)/4,即重复访问的失效概率约为(M0-512)/4 M;对于M在 1 024 KB~1 536 KB、1 536 KB~2 048 KB、2 048 KB~∞的情况时,可用同样的方法分析得到访问一遍之后被替换出去的Cache行数目。
由上述可知,当执行程序指令空间小于512 KB(即M0<512 KB)时,所有 Cache行都不会被替换掉;而当执行程序指令空间大于512 KB时,被替换出去Cache行数呈线性增长,并且不同区间内增长的斜率依次变大。因此,当执行程序指令空间大于指令Cache大小时,指令Cache行被替换出去的概率与指令Cache的替换算法有关。
指令 Cache参数包括:Cache容量大小、Cache块大小、组相联度和替换策略。在某种程度上,可通过优化Cache参数提高Cache的性能,但当Cache容量增加到某一程度时,Cache命中率将迅速降低[3]。指令Cache替换算法是影响指令Cache性能的主要因素,目前常见的指令Cache替换算法有Random、FIFO、LRU、LFU、MRU、SCK-4[4],此外还有比较新颖的LNC算法。FIFIO和Random算法硬件实现简单,但其性能不佳;而常用的LRU算法性能最佳,但是硬件实现过于复杂,同时该算法占用时间较多。因此,LRU替换算法不是指令Cache最佳的替换算法[5]。预取技术是利用空间局部性,若利用预取技术来克服LRU算法,其缺点将导致缺失不断增加[6]。而采用PLRU算法对LRU算法进行改进,几乎不会影响Cache的缺失率,并且简化了硬件实现代价及复杂度[7]。
2 PLRU替换算法
LRU(Least Recently Used)替换算法是基于程序时间局部性原理(即现在使用指令代码在不久时间里将再次访问该条指令代码),每次替换最近最少被使用的Cache块。LRU替换算法是组相联Cache中最常用的替换算法之一(即比较Cache组内指令行中哪个指令行时间最长没有被访问过则被替换出去),而且每次都要记录每个指令块的使用情况。Cache是N组相联映射,需要log2N位来描述LRU替换算法中组内每块的使用状态[8]。严格意义上的LRU算法实现代价很大,因此考虑到硬件开销,通常使用伪LRU替换算法,即PLRU(Pseudo-LRU)算法。PLRU算法与LRU算法相近,但简化了数据预测的过程[9]。 PLRU 通过使用 MRU(Most Recently Used)位,使组中每个Cache块都有自己的MRU位。4-way组相联指令Cache的PLRU替换算法示意图如图2所示。

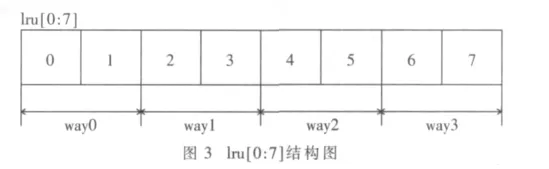
4-way组相联Cache 由 Data Array、Tag Array、LRU Array三部分组成,其中,LRU Array的入口数目与Tag Array的入口数目一致,每个LRU Array入口包含一个8 bit的 LRU矢量“lru[0:7]。 “lru[0:1]表示 way0的状态(b00表示way0是最近最少使用,b01表示way0是最近第2少使用,b10表示way0是最近第3少使用,b11表示way0是最近经常使用);lru[2:3]表示way1的状态;lru[4:5]表示way2的状态;lru[6:7]表示way3的状态。其lru[0:7]结构图如图3所示。
PLRU替换算法的步骤如下:
(1)上电复位时,将LRU Array所有入口值设置为8’b11100100,即 lru[0:7]=11100100。4路中最近经常使用情况为 way0>way1>way2>way3。
(2)如果命中Cache,则按照下述算法更新8 bit的矢量(lru[0:7])值。
在BWDSP指令Cache采用4-way组相联的Cache中,Cache命中可能在4路中的某一路命中,当某一路命中时则要更新lru[0:7]的值。有如下4种情况:
①若命中 Cache的 way0,则根据 lru[0:1]值为 b00、b01、b10、b11 4 种情况更新 lru[0:7]的值:


②若命中 Cache的 way1,则根据 lru[2:3]值为 b00、b01、b10、b11 4 种情况更新 lru[0:7]的值:

③若命中Cache的way2,则根据 lru[4:5]值为b00、b01、b10、b11 4 种情况更新 lru[0:7]的值:


④若命中 Cache的 way3,则根据 lru[6:7]值为 b00、b01、b10、b11 4 种情况更新 lru[0:7]的值:

(3)如果Cache缺失,则按照下述替换算法替换 Cache的数据块,并更新对应的lru[0:7]的值。


3 仿真与实验结果
BWDSP模拟器包含了编译器、BWDSP指令集、汇编器,能够编译用高级语言(C语言)编写的雷达信号处理的程序代码和产生基于BWDSP体系结构的目标代码。BWDSP模拟器的主频为 1 MHz、11级流水线,其内核发射的宽度为8条指令,指令存储器为 1 Mb,指令 Cache大小为256 Kb,4路组相联映射,数据存储器为2 Mb。用4个典型雷达信号处理程序xd_lib_test2_1_Cache.out、xd_lib_test2_1_part_cache.out、xd_lib_test2_1_Cache.out、dsp.out在BWDSP模拟器验证平台上对本文提出的PLRU替换算法进行仿真实验,并与直接映射、FIFO、RLU、Random替换算法进行对比,从指令Cache的访问次数、命中次数、缺失次数和命中率来统计指令Cache的性能,其仿真结果如表1所示。
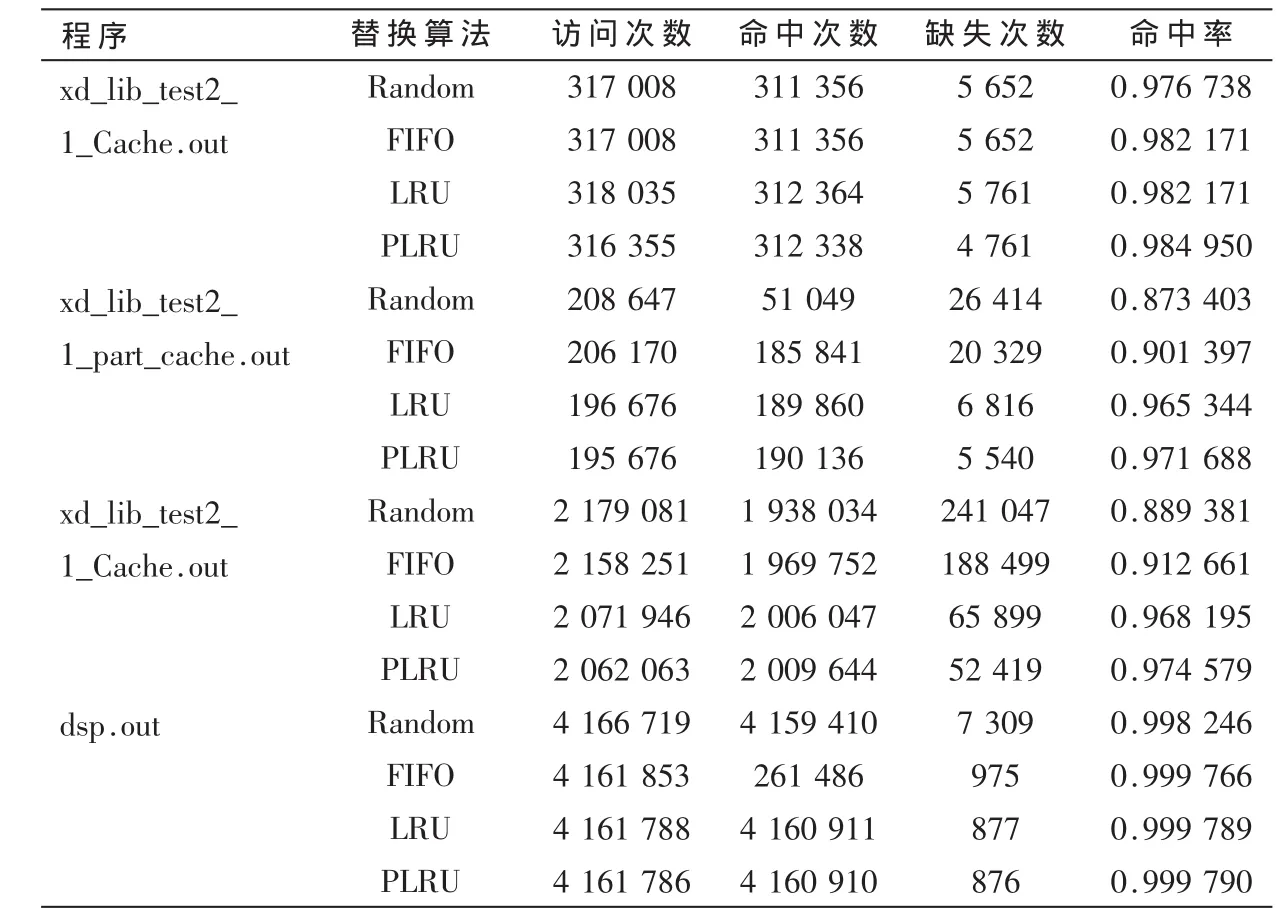
表1 指令Cache的仿真结果
表1的仿真结果表明,本文提出的PLRU替换算法其命中率高于其他三种替换算法,且实现PLRU替换算法的硬件代价相对于LRU替换算法要低。通过验证,高性能BWDSP处理器其整体性能都高于其他三种方法的1.12倍。
高性能DSP处理器是未来DSP发展趋势,高速缓存器的多层次存储器体系结构是提高数字信号处理器系统性能的重要方法。本文在32 bit BWDSP基础上提出了基于PLRU替换算法的512 bit指令包的指令Cache研究,通过实验仿真,指令Cache的PLRU替换算法在指令Cache的命中率比 FIFO、RLU、Random替换算法都要高出约5.0%。
[1]PEREZ W J H,SANCHEZ E,REORDA M S.Functional test generation for the PLRU replacement mechanism of embedded Cache memories[C].Test Workshop(LATW),2011 12thLatin American,27-30 March 2011.
[2]TAWADA M,YANAGISAWA M,OHTSUKI T,et al.Exact and fast L1 Cache configuration simulation for embedded systems with FIFO/PLRU Cache replacement policies[C].VLSI Desgin,Automation and Test(VLSI-DAT),International Symposium,2011:1-4.
[3]KLEEN A,STIENBERG E,ANSCHEL M,et al.An improved instruction Cache replacement algorithm[C].Signal Processing Systems Design and Implementation,2-4 Nov.2005:573-578.
[4]田小波,陈蜀宇.基于最小效用的流媒体缓存替换算法[J].计算机应用,2007,27(3):733-736.
[5]KLEEN A,STIENBERG E,ANSCHEL M,et al.An improved instruction Cache replacement algorithm[C].Signal Processing Systems Design and Implementation,2-4 Nov.2005:573-578.
[6]ZUCKER D F,LEE R B,FLYNN M J.Hardware and software Cache prefetching techniques for MPEG benchmarks[J].IEEE Transactions on Circuitsand Systems for Video Technology,2000,10(5):782-796.
[7]江喜平,高德远.CISC中混合Cache的优化设计[J].计算机工程与应用,2006(10):109-111.
[8]Zhang Xi,Li Chongmin,Wang Haixia.A Cache replacement policy using adaptive insertion and re-reference prediction[C].Computer Architecture and High Performance Computing.oct.2010:95-102.
[9]MOLMEN S,MOHSEN S,HOSSEIN R M.Performance evaluation of Cache memory organizations in embedded systems[C].Information Technology,2007:1045-1050.
