基于K-means聚类的网络舆情监控系统
2013-08-13张玉珠
张玉珠
(贵州大学 计算机科学与信息学院,贵州 贵阳 550025)
0 引言
互联网的发展不仅推动了社会经济的飞速发展,改善了人们的生活品质,还进一步改变了人们获取信息的方式。作为继报纸、无线广播和电视三大传统的传播媒体之后出现的新兴“第四媒体”,互联网已成为庞大的公共信息集散地,成为人们日常交流的平台。社会民众通过网络所表达的群体性的情绪、态度、意见、要求等形成了网络舆情[1]。
由于网络本身的虚拟性,隐蔽性,自由性等特点,人们更愿意通过网络来表达他们的真实想法,发泄负面情绪。近年来,由突发事件引起的网络舆情更是直接关系到社会的稳定[2]。由于网络信息量的巨大,传统的依靠人工进行分析处理,难以满足人们对网络信息的需求。因此迫切需要借助现代信息技术,提高网页信息的采集效率,制定相应的预警机制,构建网络舆情监控系统。
1 系统总体功能
网络舆情监控系统主要采用了网络爬虫技术,中文分词技术,信息分析与处理技术,文本挖掘技术等多项技术,实现网页信息的自动采集,并对海量的动态信息进行分析及实时的监管,将处于“未然状态”下的舆情信息进行挖掘分析,把握处理突发事件的最佳时机。网络舆情监控系统主要包括舆情信息采集及预处理模块、舆情信息分析模块以及舆情服务模块,系统构架如图1所示。信息采集及预处理模块主要用于对网络舆情信息的采集,将网页信息经过去噪处理,生成干净的文本信息,并对文本信息进行特征值提取,建立向量空间模型(VSM,Vector Space Model);舆情分析模块是系统的核心部分,主要通过文本聚类发现热点话题发现,并对话题进行情感倾向性分析,方便人们掌握舆情的整体趋势;舆情服务主要向人们提供舆情报告,通过对舆情报告的掌握对网络舆情突发事件进行处理,并通过个性化定制,制定方便,适合需求的舆情信息。
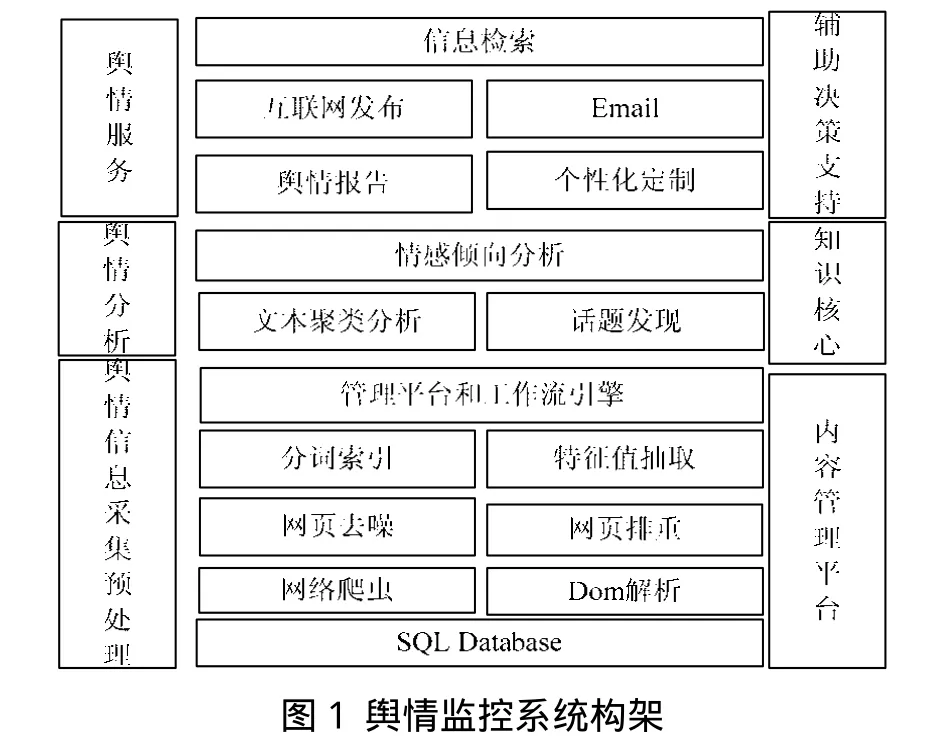
2 系统功能模块设计
2.1 舆情信息采集
舆情信息采集模块主要运用了网络爬虫技术,获取网页信息。网络爬虫是一种按照一定的规则,自动的抓取万维网信息的程序或脚本,是一个自动提取网页的过程。网络爬虫通过网页的链接地址来寻找网页,从网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
2.2 网络舆情信息预处理
舆情信息的预处理模块主要包含网页去噪,网页排重,中文分词和特征词提取等。通过网络爬虫采集到的网页信息通常含有大量的噪声,因此首先需要对其进行去噪处理,即保留网页链接、正文,时间及一级标题、二级标题[3-4]。本文采用文档对象模型(DOM,Document Object Model)来获取网页的正文、一二级标题等,构建DOM树,从DOM树上删除节点的过滤器,最终获得相应的文本信息。
网络舆情中还存在着众多重复和转载信息,为了提高聚类分析的效率,避免网页冗余,还需要对网页进行网页的去重。首先进行页面分析,提取网页的特征码,区分网页是否相同或相似的判定标准主要是特征码,再用提取到的特征码进行索引网页,构建检索系统,将提取到的网页特征码置于构建的检索系统中,聚为以该网页特征码标注的一类。将句号作为其中一个特取位置,在句号两边提取长度为L/2的词串,构成固定长为L的词串作为网页的特征码,排除了版权信息和导航的干扰。
经上述处理得到的结构化的舆情信息存入数据库,并对其进行进一步的分词处理。采用了中科院得汉语词法分析系统(ICTCLAS,Institute of Computing Technology, Chinese Lexical Analysis System)[5],利用词类信息对分词决策提供帮助,并且在标注过程中又反过来对分词结果进行检验。分词完毕后,需去除停用词,如标点符号,助词等,减少提取特征词和建立VSM时产生的冗余。
本系统采用VSM向量空间模型表示文本内容,在有n个不同特征项的一组d1,d2,…,dn的文本系统中,给定文本的传统特征向量表示:di=(ω1(di),ω2(di),…,ωn(di)),由于d1,d2,…,dn互不相同,可以把它们看作是n 维欧氏空间n 个坐标,把di看作是n 维欧氏空间的向量。其中ωj(di)表示第j个特征词在文档di中的权重。用词频率指数-逆文本频率指数(TF-IDF,Term Frequency-Inverse Document Frequency)方法给出特征词一个权重[6]。计算公式如下:
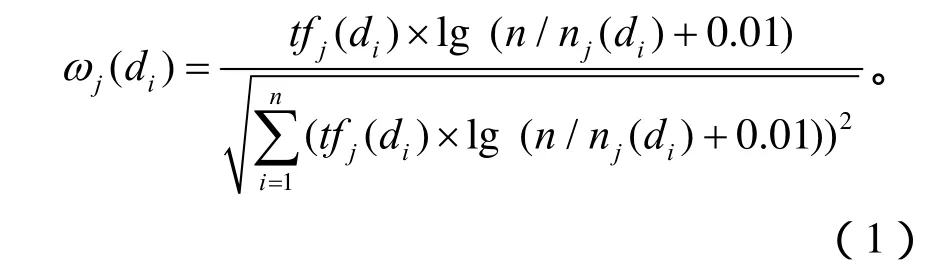
ωj(di)表示第 j 个特征词在文本中di的权重;fj(dj)表示第 j个特征词在文本di中出现的频率,nj( di)表示包含第j个特征词的文本个数,n表示所有文本个数。
2.3 舆情信息分析
舆情信息分析模块包括舆情信息相似度的计算,聚类分析及情感倾向分析。其流程图如图2所示。
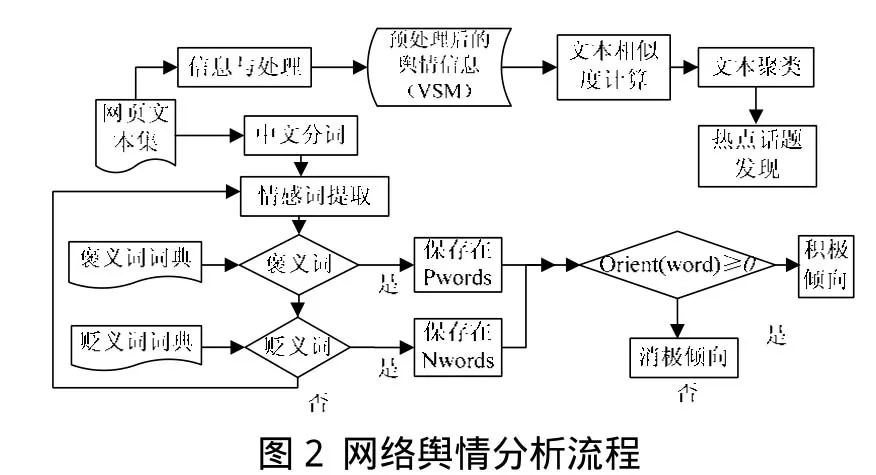
本文采用余弦距离度量[7]表示文本之间的相似性,它定义两篇文档di,dj的相似度如下:

文档聚类是一种无监督的过程,即不依赖任何关于集合划分的先验知识,而仅仅根据集合内部的文档对象彼此之间的相似度按照某种准则对文档集合进行划分。k-means聚类算法具有良好的可伸缩性和很高的效率,适合处理大量文本集,该算法是划分算法的代表,对文本进行分析聚类有较好的结果。该算法的主要思想有[8]:对于一个大小为 n的文本集,首先随机选择k个文本作为初始聚类中心,对于剩下的每一个文本对象,计算该文本与各个初始聚类中心的相似度,然后根据簇内文本之间相似度大而不同簇间文本相似度小的原则,把文档指派到相应的类簇。重新计算每一个聚类簇的平均值,得到新的聚类中心,不断重复上述过程,直到准则函数收敛。利用 k-means聚类算法能够快速为文本进行分类,发现事件的热点[9],对网络突发事件进行监控,及时有效的实现舆情监控。
在对舆情信息进行分析时,还可以通过情感倾向分析判断舆情信息的正负面情绪。本系统利用知网(HowNet)的词汇语义相似度进行计算,识别词汇的语义倾向性[10-12]。令Pwords表示带有积极语义倾向的基准词集合,Nwords表示带有消极语义倾向的基准词集合。词汇的语义倾向值表示为:
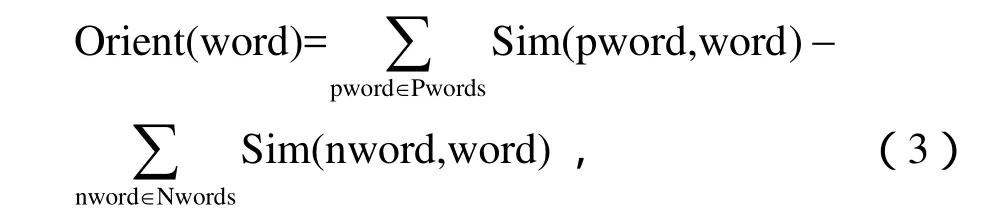
其中,Sim(word1,word2)表示词汇 word1和 word2的语义相似度。当Orient(word)≥θ时认为词汇word为积极语义倾向;反之为消极语义倾向。
2.4 舆情服务
舆情服务作为系统的输出层,主要提供用户需求层的信息,具体包括舆情报告,舆情信息的互联网发布及邮件 Email服务和用户个性化定制。为用户提供清晰、准确、快捷的舆情信息服务,满足用户对信息的各种需求。
3 结语
网络舆情是一个比较新的研究领域,在信息高速传播的互联网时代,实施舆情信息是非常有必要的。但是由于网络结构的复杂,舆情信息的隐蔽性、爆发性等特点,很难全面有效的掌控舆情信息。本系统主要通过遍历互联网上的信息,通过预处理得到干净的文本,再由聚类发现舆情的热点,并发布舆情报告,形成一套相对完整的网络舆情监控系统。本系统的不足之处在于只是通过文本挖掘追踪热点话题,但是没有建立网络舆情的预警机制,在这方面还有待研究改进。
[1] 曾润喜.我国网络舆情研究与发展现状分析[J].图书馆学研究,2009(08):2-6.
[2] 中国互联网网络信息中心.第28次中国互联网发展状况统计报告[R].北京:CNNIC,2011.
[3] 张继超,和应民,周春楠,等.综合资源管理系统中数据采集的实现[J].通信技术,2011,44(03):116-119.
[4] 王平根.基于 DOM的动态网页信息抽取方法[J].科技信息,2010(31):470-470,475.
[5] 中国科学院计算技术研究所.ICTCLAS简介[EB/OL].[2008-12-01](2012-08-05).http://ictclas .org/sub_1_1.html.
[6] 李文超,周勇,夏士雄,等.一种新的基于层次和 K-means方法的聚类算法[C].中国:中国自动化学会,2007:605-609.
[7] FAHIM A M,SALEM A M,TORKEY F A,et al.An Efficient Enhanced K-means Clustering Algorithm[J].浙江大学学报A:英文版,2006,7(10):1626-1633.
[8] STEINBACH M, KARYPIS G, KUMAR V. A Comparison of Documentclustering Techniques Proceedingof the 6th ACM-SIGKDDInternational Conference on Text Mining[M].USA:ACM Press, 2000:103-122.
[9] 焦超,刘功申.网络突发热点事件的热度分布[J].信息安全与通信保密,2012(04):58-60.
[10] 熊德兰,程菊明,田胜利,等.基于HowNet的句子褒贬倾向性研究[J].计算机工程与应用,2008,44(22):143-145.
[11] 薛丽敏,李殿伟,肖斌,等.中文文本情感倾向性五元模型研究[J].通信技术,2011,44(07):130-132.
[12] 黄萱菁,张奇,吴苑斌,等.文本情感倾向分析[J].中文信息学报,2011,25(06):118-126.
