基于云平台的互信息最大化特征提取方法研究*
2013-08-10魏莎莎陆慧娟
魏莎莎 ,陆慧娟 ,金 伟 ,李 超
(1.中国计量学院信息工程学院 杭州 310018;2.中国计量学院机电工程学院 杭州 310018)
1 引言
基因芯片技术是随着人类基因组计划发展起来的一项新技术,大规模基因芯片(DNA微阵列)技术的应用是现在功能基因组以及肿瘤诊断等研究中的重要监测手段[1],可广泛用于基因序列分析、基因突变检测、疾病诊断等诸多领域。基于基因表达数据维数高、样本小的特点,直接对其进行学习的生物学分析成本较高,并且有些基因只在特定实验条件下表达,为了降低机器学习的时间及空间复杂度,需要对其进行特征选择,选取与分类紧密关联的基因,同时提高分类精度[2]。特征选择是根据各个特征的重要程度,剔除特征中不相关的冗余特征后,挑选出对分类有意义的某些特征,以降低特征空间维数。在模式识别、数据挖掘以及机器学习中,特征选择都非常关键[3]。特征选择方法从研究之初到现在,已经有了很多成熟的方法,2005年,Peng[4]和Ding[5]在处理连续特征时,分别使用 F-Statistic和Pearson相关系数度量相关性程度进行特征选择。这为本文利用两个特征之间互信息最大化的方法进行特征过滤提供了思路与基础。
互信息是信息论中的一个重要概念,通常用于描述两个随机变量间的统计相关性,用一个变量中包含另一个变量的信息多少表示两个随机变量之间的依赖程度,一般用熵表示[6]。在统计学上,同一分类系统的基因并非独立而是相关的,确定基因之间的互信息就是要定义相似性测度寻找变换关系,使得基因间的相似性达到最大,从而确定该基因在分类系统中的重要程度。其中,当信息量达到最佳配准时,即实现互信息最大化。在医学领域中,利用互信息最大化法进行多模医学图像配准包括CT扫描以及核磁共振等成为医学图像处理方面的热点[7],它能够很快地排除很大数量的非关键性的噪声和无关基因,是特征选择中一种基于相关性的过滤方法。但在数据量较大的情况下,对服务器性能要求高,计算效率低,而云计算的出现为解决这个问题提供了新的契机[8]。
云计算是传统计算机技术发展融合的产物,是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需提供给计算机和其他设备[9]。云是网络、互联网的一种比喻说法,一般来说包括IaaS、PaaS和SaaS3个层次。
目前,将云计算与分类问题结合,参考文献[8]等提出了基于云计算平台的代价敏感集成学习算法,参考文献[10]提出了云计算在贝叶斯分类中的应用,但还没有相关文献讨论如何在云计算平台环境下对数据特征进行过滤。为了能够快速、准确、高效地处理基因数据特征提取问题,本文提出了一种基于云计算平台的Filter型基因选择算法——CMI-Selection。
本文对算法的实现进行了仿真模拟,在CMI-Selection中,实验室用5台PC搭建了Hadoop云计算平台,首先利用随机函数将数据集随机分为5个部分,每个部分遵循互信息算法进行筛选计算,然后将结果返回到客户机端用于测试及分类。为了评估算法在云平台下的性能,实验用ELM(极限学习机)对提取后的特征进行训练和学习,结果表明,在分类精度与普通PC端相近的情况下,CMI-Selection速度更快。
2 互信息与基因筛选
在进行基因选择和基因降维之前,首先要进行基因筛选。在基因表达数据特征提取的前期过程中,基因筛选能够提高计算效率,是选出具有代表性的精简的基因子集的有效方法[11]。
熵用来表示任何一种能量在空间中分布的均匀程度,其大小跟能量分布均匀程度有关,能量越不确定且分布越均匀,熵就越大[12]。信息论中的“信息熵”是香农[13]在进行信息处理时提出的概念。在互信息最大化方法中,信息熵主要用来衡量一个随机变量取值的重要性程度,以特征能够为分类带来多少信息为衡量标准,带来的信息越多,该特征越重要。
假设X来自于一个集合S,且X是一个离散随机变量。X的概率密度分布函数表示为p(x),则X的信息熵定义如下:
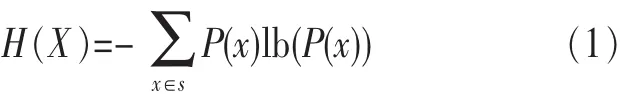
已知一个来自于集合T的变量Y,P(x|y)表示Y取值为y、X取值为x的概率,X的不确定性用 H(X|Y)衡量,如式(2)所示:
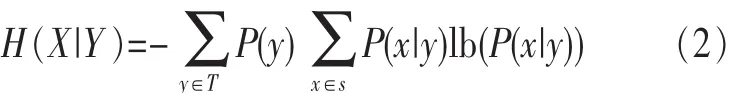
P(x,y)用来表示X、Y的联合概率密度,则它们的互信息量I(X;Y)定义为:

在基因筛选过程中,互信息通常用来表示计算特征与特征之间的关系。在上述式子中,假设考虑特征t与类c的分布,N为基因总数,A为类c中出现特征t的基因数,B为非类c中出现特征t的基因数,C为类c中不出现特征t的基因数,特征t与类c之间的互信息定义为:

如果I(t;c)=0,那么特征t与类c相互独立。
在式(5)中提供关于类别信息的加权平均值来衡量一个特征在全局特征选择中的重要性:
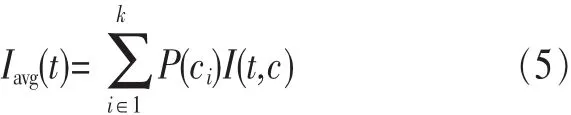
特征选择后,尽可能多地保留关于类别的信息,即达到互信息最大化:
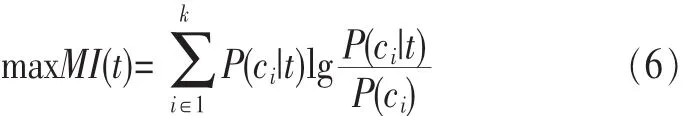
则最大互信息量为:

用互信息最大化方法进行特征选择后,选出来的特征集合应该尽可能多地提供关于某个类别的信息。两个随机变量之间共有的信息量越大,则两个变量之间的相关程度越高,互信息量越大;如果两个随机变量完全不相关,则两个变量之间不相关,互信息量为0。互信息最大化是选择相关程度最高的两个变量进行循环迭代,得出每次信息量中相关程度最高的变量。
3 基于云计算平台的特征选择系统
云计算[14]描述了一种基于互联网的新的IT服务增加、使用和交付模式,通常涉及互联网提供动态易扩展而且经常是虚拟化的资源,意味着计算能力也可以作为一种商品进行流通。云是网络、互联网的一种比喻说法。典型的云计算提供商往往提供通用的网络业务应用,软件和数据都存储在服务器上(即云端),用户可以通过浏览器或者其他Web服务访问。
3.1 Hadoop云计算平台的体系结构
Hadoop是Lucene子项目Nutch的一部分,是由Apache SoftwareFoundation开源组织提出的一个分布式计算开源框架,它不是一个缩写字,而是一个虚构的名字。Hadoop的核心是MapReduce和分布式文件系统 (Hadoopdistributedfile system,HDFS)及后来加入的 HBase。MapReduce就是任务的分解与汇总(规约),如图1所示,它是一种简化的并行计算编程模型,其中map主要是把任务分解成多个任务,而reduce则把分解后的多任务处理汇总起来。
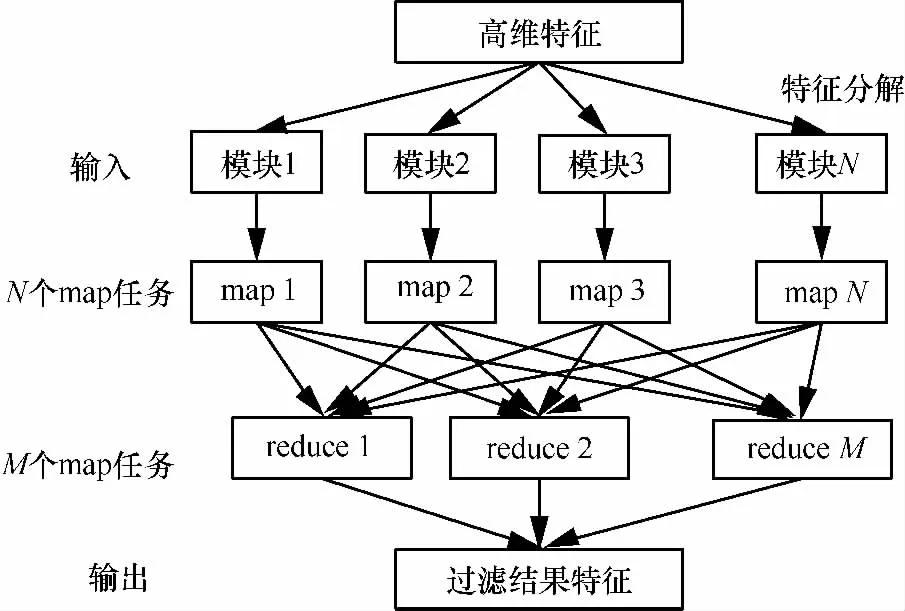
图1 MapReduce工作过程
HDFS用来存储分布式计算的数据,采用mater/slave架构,由若干个数据节点和一个名称节点组成。服务器间相互通信的过程如图2所示。
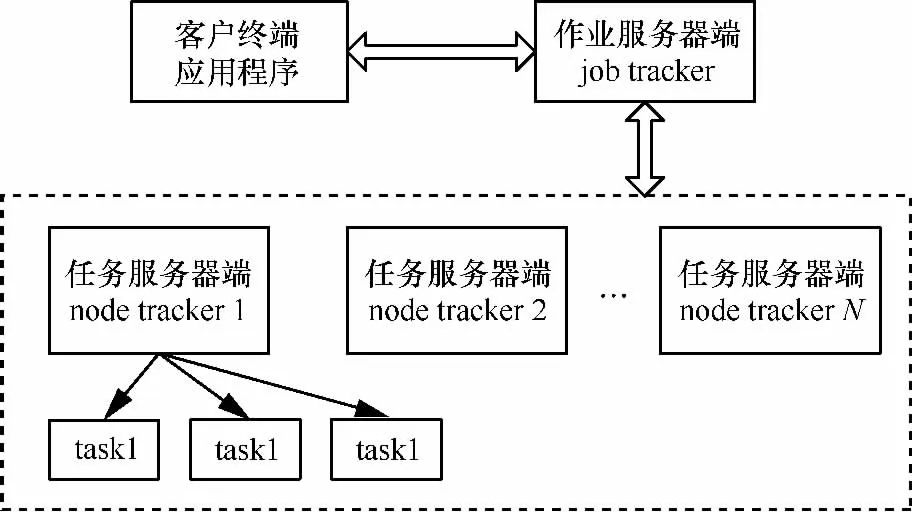
图2 服务器之间相互通信的过程
HBase则对应于Google的BigTable。
Hadoop的特点介绍如下。
·构建成本低:Hadoop框架对硬件环境没有任何限制,无需昂贵的服务器,普通的PC即可实现。在软件使用方面,由于部署目标平台 Linux是开源的,不存在软件授权费等方面的问题。
·可靠性:在实现时,由于Hadoop认为所有节点都有可能会发生计算或者存储失败,故其在节点群中维护了很多工作副本,一定程度上保证了系统的备份恢复机制和分布式处理的可靠性。
·扩容能力:能非常容易地增添计算存储资源。
·效率高。
3.2 基于MapReduce的特征过滤
MapReduce由两个动词组成,分别控制任务的分解和汇总,从技术创新角度来讲,MapReduce也并不是创新技术,分布式并行计算程序的编写也十分简单,Hadoop中Streaming工具使用起来方便快捷,一般编程技术就可以开发出一个分布式并行程序,用于海量数据的并行计算。
在对基因表达数据进行特征过滤中,步骤如下。
(1)随机函数对基因数据集进行随机分块。为了仿真模拟,实验用5台PC组成一个Hadoop云计算平台。
(2)map函数对分块的特征集进行信息熵的计算。这里的map函数被定义为互信息最大化算法。通过设置map任务的特征数量的大小,让云平台自动对t时刻到达的特征集进行划分,每块数据对应一个map任务,每个map任务计算各自特征集的信息熵,同一时刻不同map之间进行并行计算,得到t时刻所有特征的信息熵。
(3)执行reduce任务,包括特征提取和特征集成两个阶段。其中特征提取按照互信息最大化算法的标准进行。
4 实验结果
在理论分析的基础上,本节选取4组基因表达数据集对 CMI-Selection进行性能测试,其中 Breast、Colon、Heart为两类数据,Leukemia为多类数据。数据集信息见表1。
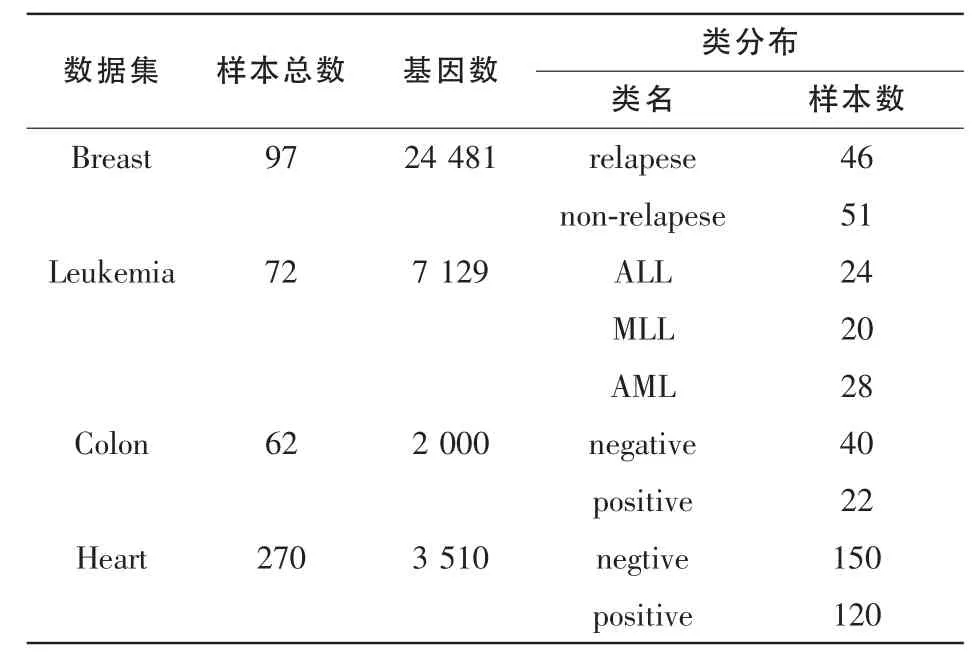
表1 数据集信息
在特征提取之前,先将基因表达矩阵中的元素进行对数转换,实现标准化:
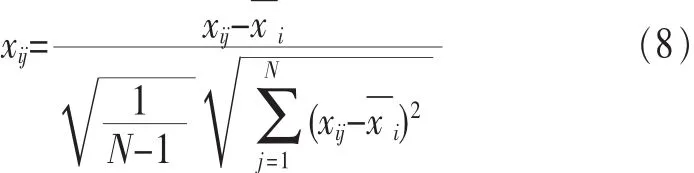
本文用Breast数据集作为实验例子进行分析与研究,首先用随机函数对数据集进行分块,在云平台上有4台PC部署数据节点和任务服务器端,即每部分得到6120个特征。每块特征数据对应一个map任务,每个map任务计算各自特征集的信息熵,利用互信息最大化方法得出特征集额互信息,随后开始执行reduce步骤。在reduce步骤中,对上一步得到的互信息进行排序,筛选特征,得到排名前1224个特征。最后进行汇总,运送到客户机,在客户机端用ELM对获得的基因特征进行训练和测试。实验结果如图3、图4所示。
从图3可以看出,在云平台环境下,通过互信息对特征进行筛选后,将特征和标签分别作为ELM的输入和输出进行训练与测试,采用5折交叉验证,获得的精度最高可以达到93%,与在普通PC环境中相同特征数量的前提下进行比较可以发现其分类精度大致相同,说明CMI-Selection算法在分类精度方面具有可行性与有效性,它能够保证提取的特征是有效的,具有较高的分类精度。
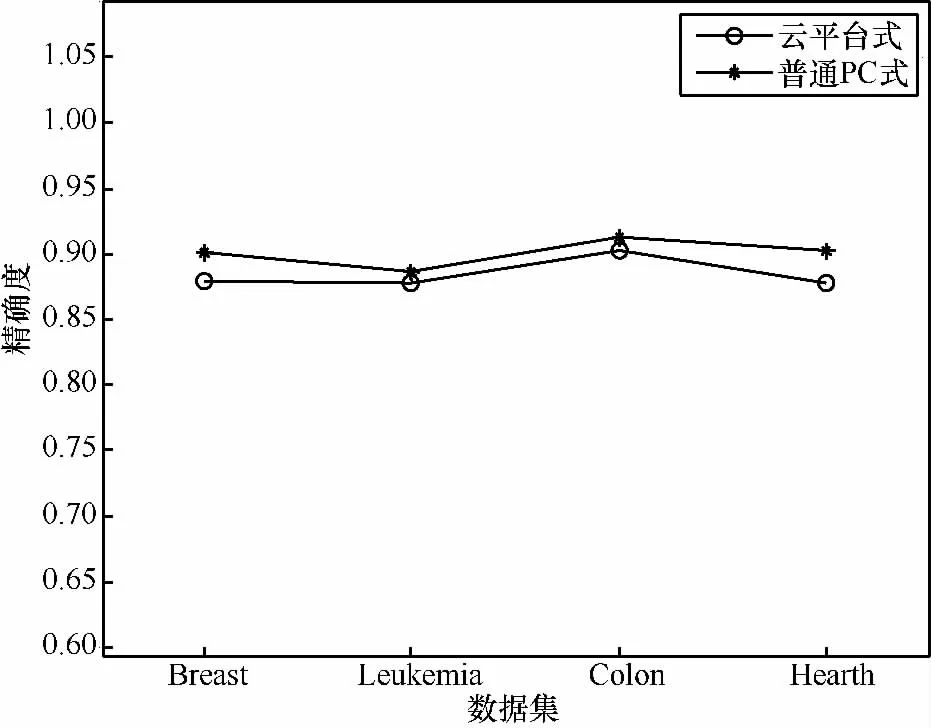
图3 ELM在不同环境下的不同数据集上的分类精度
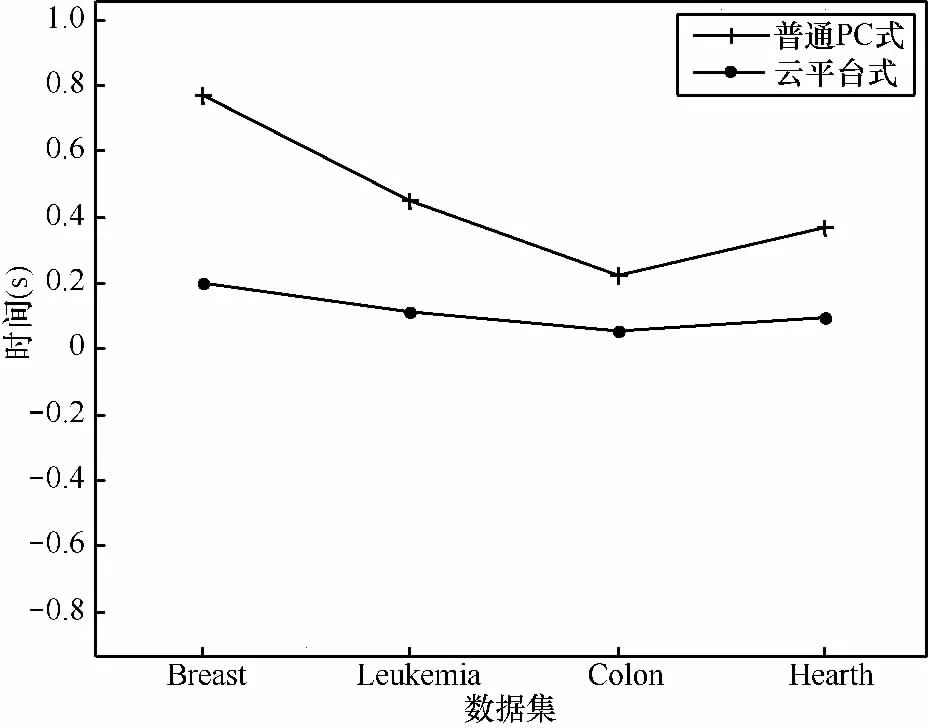
图4 不同环境下的特征基因提取时间
从图4中可以看出,由于云平台的并行计算性能,其在保证较高分类精度的同时,相比于普通PC速度提高了4倍左右,并且这种提速会随着服务器数量的增加变得更加明显,从而为大数据学习节省了时间资源,说明了云平台的高度并行化。
5 结束语
本文将传统的特征提取方法同云计算平台相结合,提出了一种基于云平台的互信息最大化的特征提取方法,构建了一个基于云平台的特征过滤模型。该模型通过设置平台中map任务的个数、划分特征集的大小让云平台自动对基因数据集进行特征的筛选提取,提取后的特征用于训练与测试。与普通单个PC相比,该模型在保证较高的分类精度的情况下,速度快,易于实现。实验结果表明,基于云平台的互信息最大化特征提取方法是正确、可行的,能够快速提取特征,节省大量时间资源,是一种高效的基因特征提取系统。
1 Kang H N,Chen I M,Wilson C S.Gene expression classifiers for relapse-free survival and minimal residual disease improve risk classification and outcome prediction in pediatric B-precursor acute lymphoblastic leukemia.Blood,2010(115):1394~1405
2 任江涛,黄焕宇,孙婧昊.基于相关性分析及遗传算法的高维数据特征选择.计算机应用,2006,26(6):1403~1405
3 裘国永,王娜,汪万紫.基于互信息和遗传算法的两阶段特征选择方法.计算机应用研究,2012,29(8):2903~2905
4 Peng H H,Long F H,Ding C.Feature selection based on mutual information:criteria of max-dependency,max-relevance,and min-redundancy.IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(8):1226~1238
5 Ding C,Peng H.Minimum redundancy feature selection from microarray gene expression data.Journals of Bioinformatics and Computational Biology,2005,3(2):185~205
6 王凌,陈震,危水根等.基于改进最大互信息法的MR切片图像配准.生物医学工程学杂志,2012,29(2):201~205
7 杨虎,马斌荣,任海萍等.基于最大互信息的人脑MR-PET图像配准方法.北京生物医学工程,2001,20(4):246~251
8 张彾卫,万文强.基于云计算平台的代价敏感集成学习算法研究.山东大学学报(工学版),2012,42(4):19~23
9 Vouk M A.Cloud computing-issues,research and implem entations.Proceedings of ITI 2008,Dubrovnik,2008:79~120
10朱杰.云计算在基于贝叶斯分类的垃圾短信过滤中的研究与应用.电子科技大学硕士学位论文,2010
11王明怡.微阵列数据挖掘技术的研究.浙江大学博士学位论文,2004
12刘庆和,梁正友.一种基于信息增益的特征优化选择方法.计算机工程与应用,2011,47(12)
13 Hu Y, Loizou P C.Speech enhancement based on wavelet thresholding the multitaper spectrum.IEEE Transactions on Speech and Audio Processing,2004,12(1):59~67
14戴元顺.云计算技术简述.信息通信技术,2010(2)
