MPI程序的性能优化方法研究*
2013-08-10阚亚斌张世燎
刘 鹏 阚亚斌 张世燎
(大连舰艇学院 大连 116018)
1 引言
MPI是目前集群系统最流行的并行编程环境之一。而且随着科学与工程技术的发展,对计算量的需求越来越大。因此基于分布存储的MPI并行编程模型也逐渐被广泛应用。由于MPI是基于消息传递的并行模型,所以进程之间的通信必须通过显示的调用MPI消息传递库中的通信函数来实现。因此,如何在MPI并行程序中充分利用MPI提供的函数库,如何从MPI函数库提供的多种通信函数中有效的选择通信函数,以及如何通过尽量减少通信开销来提高并行程序性能已成为该领域研究热点之一。本文两次改进DNS的MPI程序实现,减少了程序的通信开销,提高了程序性能,并通过两次改进提出一个优化MPI并行程序的一般思路与方法。
2 只用Send和Receive调用来实现通信部分
尽管MPI函数库提供了多种消息传递函数,但点对点通信仍然是所有通信函数的基础[2],所以本文先完全以点对点通信函数来实现DNS算法的通信部分,用以和改进后的程序做比较。由MPI函数库为每种阻塞通信形式都提供了相应的非阻塞通信形式[3],尽管非阻塞通信方式可以实现计算与通信的重叠,从而提高程序的性能,但是由于DNS算法本身计算和通信重叠的可能性不大,即使采用非阻塞的通信方式效率也不可能得以提高,所以本文选用阻塞的点对点通信 MPI_Send/MPI_Recv来实现DNS。
在程序中,由于只采用点对点通信函数 MPI_Send/MPI_Recv,所以起初的分布数据是由根进程root通过p-1(p:进程数)次 MPI_Send函数调用来将数据发送给其它进程的,而非root进程通过一次MPI_Recv函数调用来完成数据接收。各进程运算结束后,由根进程root通过p-1次MPI_Recv函数调用来完成数据收集,非root进程通过一次MPI_Send函数调用来将结果发送给root进程。
3 通过集群通信函数来改进程序
MPI函数库不仅提供了点对点通信函数,还提供了丰富的集群通信函数,这些集群通信函数和点对点通信的一个重要区别就在于集群通信需要一个特定组内的所有进程同时参加通信,而不是像点对点通信那样只涉及到发送方和接收方两个进程。集群通信在各个不同进程的调用形式完全相同,而不像点到点通信那样在形式上就有发送和接收的区别。这就为编程提供了方便性,也提高了程序的可读性和移植性。
MPI提供的集群通信函数基本分为四类[4]:
1)一对多的通信操作,根进程发送相同数据到所有进程或分发不同数据到所有进程。例如广播操作MPI_Bcast和数据分发操作MPI_Scatter。
2)多对一的通信操作,根进程从所有进程接收数据。例如数据聚集操作MPI_Gather。
3)多对多的通信操作,进程组中各进程从每个进程接收数据,或者各进程向每个进程分发数据并从每个进程接收数据。例如多对多的数据聚集操作MPI_Allgather和多对多的数据分发与聚集操作MPI_Alltoall。
4)进程组中所有进程进行全局数据运算,运算结果返回给根进程或所有进程,例如多对一的全局运算操作MPI_Reduce和多对多的全局运算操作MPI_Allreduce。
本文对程序的第一次改进是将通过调用点对点通信实现的数据分布和收集操作分别用 MPI_Scatter和 MPI_Gather操作来代替。本文对改进前后的程序性能做了对比,对比结果如图1。
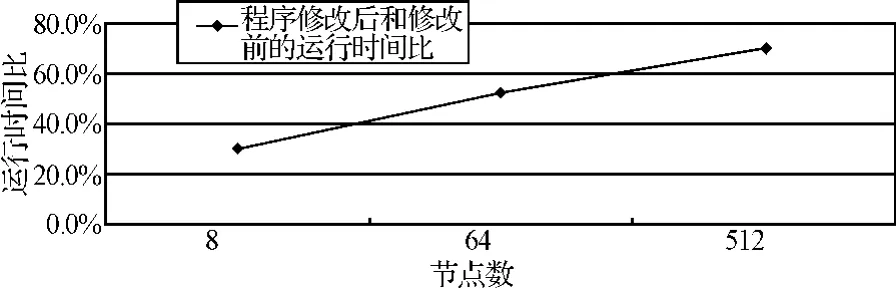
图1 第一次改进后的性能优化
由图1可见,改进后程序的运行时间比改进前有了明显的缩短,这说明在实现集群通信时使用MPI提供的集群通信函数比使用点对点通信函数的性能好。但是随着节点数的增加,两者的差距逐渐缩小,甚至当节点数增加到足够多时,修改后程序的运行时间有可能比修改前更长。这是因为在程序中使用集群通信函数时,通信域的参数直接使用了 MPI_COMM_WORLD,而该算法只要部分进程通信,因而增加了无效数据的传输开销,且该开销随着节点数的增加而增大。
4 利用派生数据类型和建立新通信域来改进程序
4.1 通过派生数据类型减少通信次数
尽管MPI库函数提供的所有通信函数在进行调用的时候,都有一个参数count和datatype。这两个参数允许用户把基本类型相同的多个数据项打包成一个基本的消息项。但是为了使用这项功能,被打包的数据项必须被存储在连续的内存空间。因此,要发送存储在非连续的内存空间中的多个数据项时,以上方法就无能为力了,就必须考虑使用MPI提供的两种处理不连续数据的方法[5]:一是允许用户自定义新的数据类型(又称派生数据类型);二是数据的打包与解包,即在发送方将不连续的数据打包到连续的区域,然后发送出去,在接收方将打包后的连续数据解包到不连续的存储空间。程序中由于两矩阵之间数据的不连续性,导致进程间数据的传输需要两次通信过程才能完成,降低了程序的性能。因此,本文考虑采用以上两种方法之一来解决非连续数据的传输问题,以进一步提高程序效率。鉴于使用数据的打包与解包过程开销相对过大,因此本文选择使用派生数据类型的方法来改进程序。新数据类型的声明,生成与提交如下:

程序中使用数据类型生成器MPI_Type_Contiguous派生出一个由两个连续的整型数据构成的新数据类型。这样,新建立的MPI数据类型可用于 MPI的任何通信函数中。当用它的时候,需要在数据类型参数的位置上写上派生的数据类型。
4.2 通过分割通信域避免无效数据的传输
由于该程序中数据的分布与收集实际上只需要通信域中的部分进程参与,而程序中使用的集群通信函数的通信域的参数是预定义组内通信域 MPI_COMM_WORLD,这就意味着所有的进程都参与了该集群操作,其中n*n*(n-1)进程发送和接收了许多无效数据,增加了通信开销。
为了解决这一问题,避免这种没有必要的开销,本文考虑使用MPI函数库提供的用于建立新通信域与新进程组的相关函数 MPI_Comm_split(comm.,color,key,newcomm)。MPI_Comm_split对于通信域comm中的每一个进程都要执行,每一个进程都要指定一个color值,根据color值的不同,此调用首先将具有相同color值的进程形成一个新的进程组,新产生的通信域与这些进程组一一对应,新通信域中各个进程的顺序编号是由key决定的。程序中通过调用MPI_Comm_split函数建立了一个由n*n个进程组成的新进程组与通信域。这样在很大程度上改善了程序的性能。本文对改进前后的程序性能做了对比,对比结果如图2。
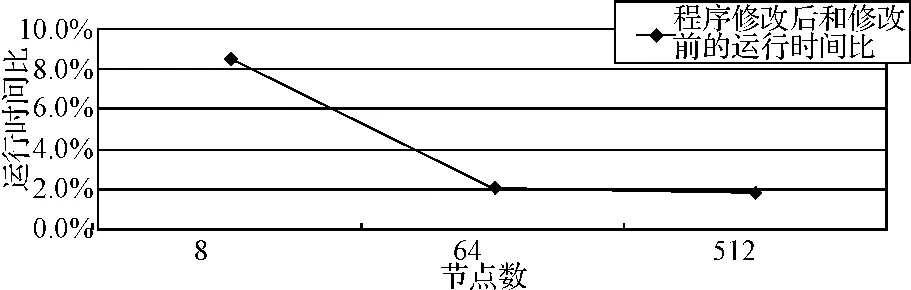
图2 程序修改前后运行时间比
由图2可见,程序经过两次改进获得了性能的提升,而且随着节点数的增加,性能提升的幅度越大。
5 优化MPI并行程序的一般思路与方法
1)尽量使用MPI函数库提供的集群通信函数。尽管有实验表明MPI并没有对集群通信操作的执行性能进行加速[6],但是在MPI并行程序设计当中,由于开发人员通常没有考虑而且也不易设计出更优化的集群通信操作,所以在一般情况下,MPI并行程序选用MPI提供的集群通信函数比单纯使用点对点通信函数能获得更优的性能。而且集群通信函数给用户提供了一个方便地进行集群通信的界面,在一定程度上简化开发难度,也提高了程序的可读性和移植性[7]。
2)通过数据打包以减少通信次数。据测试,发送一次消息的通信开销相当于几千次计算量的开销[8]。然而,在实际编程的过程中,不可避免地要发送多个数据,并且这多个数据的基本类型可能相同,也可能不同。在这种情况下,应该尽可能地将多个单独的数据项打包成一个单独的信息项,从而在保证不减少消息量的 前提下,减少了通信次数。具体应用中可以考虑使用派生数据类型或者 MPI_PACK/MPI_UNPACK等方法将数据打包,从而降低通信过程中的开销。
3)考虑通过建立新的进程组和通信域来避免无效通信。进程组是通信域的组成部分,MPI的通信是在通信域的控制和维护下进行的,因此所有的MPI通信都用到通信域这一参数。由于MPI预定义组内通信域是MPI_COMM_WORLD,它包括所有的进程。而程序中经常会遇到部分进程需要通信的问题,无论选择点对点通信还是简单地使用集群通信都难以得到较好的性能。为了解决这一问题,可以通过对通信域的重组,以非常简单的方式方便地实现通信任务的划分,从而提高通信效率[9]。
4)选取适当的通信方式,充分发掘程序中通信与计算重叠的可能性。MPI中每种阻塞通信函数都有与其对应的非阻塞通信函数。程序中由于通信经常需要较长的时间,在阻塞通信结束之前,处理器只能等待,这样就浪费了处理器的计算资源。对于非阻塞通信,不必等到通信操作完成便可以返回,这样处理器可以同时进行计算操作,实现了计算与通信的重叠,大大地提高了程序执行的效率[10]。然而,要合理地选择通信方式需要开发人员对程序中计算与通信重叠的可能性进行详细的分析,由于DNS算法中计算与通信重叠的可能性不大,因此在对以上程序优化的过程中并未使用该优化方法。
6 结语
本文讨论了MPI并行程序的性能优化问题,尤其是其中的通信优化问题,并通过具体的实验为MPI程序开发人员提出了优化MPI并行程序的一般思路与方法。本文设计的并行程序有很好的加速效果,适合于大规模科学与工程计算。未来的工作:对虚拟进程拓扑进行深入的研究,以简化并行程序设计,提高程序效率;对 MPI通信函数的源码进行分析与研究,设计效率更高的通信函数,尤其是集群通信函数;通过对MPI中的动态进程管理作深入的研究,分析如何通过有效地利用动态进程管理以提高MPI并行程序的效率。
[1]Ghanbari M.The Cross-search Algorithm for Motion Estimation[J].IEEE Trans.Commun.1990.38:950-953.
[2]罗省贤,李录明.基于MPI的并行计算集群通信及应用[J].计算机应用,2003,23(6):51-53.
[3]罗省贤,何大可.基于MPI的网络并行计算环境及应用[M].成都:西南交通大学出版社,2001:35-44.
[4]陈国良.并行计算——结构·算法·编程[M].北京:高等教育出版社,1999:285-290.
[5]陈国良,吴俊敏,章锋等.并行计算机体系结构[M].北京:高等教育出版社,2002:125--146.
[6]任波,王乘.MPI集群通信性能分析[J].计算机工程,2004,30(11):71-73.
[7]蒋英,雷永梅.MPI中的3种数据打包发送方式及其性能分析[J].计算机工程,2002,28(8):261-263.
[8]都志辉.高性能计算并行编程技术[M].北京:清华大学出版社,2001:178-187.
[9]雒战平,刘之行.有限元并行计算的MPI程序设计[J].西安交通大学学报,2004,38(8):873-876.
[10]杨爱民,刘韧.集群系统中基于MPI的并行GMRES(m)计算通信的研究及应用[J].微电子学与计算机,2009,26(9):129-131.
