基于聚类算法的数据库访问日记入侵检测
2013-08-06陈志德
邵 磊 陈志德
(福建师范大学福建省网络安全与密码技术重点实验室,福建 福州 350007)
1.引言
当前,信息已成为社会发展的重要战略资源,国际上围绕信息的获取、使用和控制的斗争愈演愈烈,信息安全成为保障经济健康发展、维护国家安全和社会稳定的一个焦点。计算机安全主要包括操作系统安全、数据库安全和网络安全3部分[1]。目前人们把信息安全的重点放在网络安全上,对操作系统和数据库安全的研究远不如对网络安全的研究。而实际上在信息系统的整体安全中,数据库往往成为攻击者最感兴趣的目标。在数据库受到攻击的可能性、空间和时间都大大增加的情况下,传统的以身份认证和存取控制为重点的数据库安全机制越来越无法满足安全需要。对数据本身的完整性和可利用性较少涉及。而对于数据库安全来说,数据的完整性、可利用性和保密性都具有同等重要地位。
入侵检测技术是为保证计算机系统的安全而设计与配置的一种能够及时发现并报告系统中未授权或异常现象的技术,是一种用于检测计算机网络中违反安全策略行为的技术。进行入侵检测的软件与硬件的组合便是入侵检测系统(Intrusion Detection System,简称IDS)。它是检验数据库安全的一种很常见很有效的技术。入侵检测系统是实现入侵检测功能的一系列的软件、硬件的结合。作为一种安全工作,它用来分析反应异常行为模式的信息,对检测的行为作出自动的反应,并报告检测过程的结果。作为现代安全防御体系的一个重要组成部分。它的作用在很大程度上影响整个安全策略的成败。入侵检测系统最早出现在1980年4月,在1998年末,1999年初麻省理工学院的林肯实验室在DARPA的资助下进行了对比评价开发的入侵检测系统[5]。将入侵检测系统应用在数据库中,已经有一些科学家投入到这方面的研究中。2002年,Sin Yeung Lee等提出了一种建筑学的框架DIDAFIT,即通过指纹识别处理的数据库入侵检测模型[6]。
已经有一些研究人员提出了一些数据库中的入侵检测系统模型,它可以按照自己所设定的规则,检测数据的行为,来判断数据是正常数据还是异常数据[2,3]。但是,这种技术目前也存在一些缺陷,由于数据库的大数据特性,往往数据量都是很大,所以如果只是将数据一项一项地按照入侵检测系统模型来检测的话,无疑这需要很多的时间。针对这点,本文提出了一种入侵检测系统模型,可以更加高效地来检测数据库的安全性。
在这篇文章里,我们将分簇算法与入侵检测技术相结合应用在数据库访问日记的安全检测上。首先,我们将数据库访问日记中的数据标准化。这样我们可以得到一些关于数据的数据集。然后,通过我们的分簇算法将数据进行分类。通过聚类分析可以识别密集和稀疏的区域,发现全局的分布模式,以及数据属性之间的相互关系等。我们通过聚类的思想数据库中的数据分成K个聚簇。首先我们要对系统进行一些假设。假设一,正常数据的数目要远远大于异常数据的数目。假设二,异常数据和正常数据的特征差异很大。在这两个假设的基础上,我们将聚类应用在入侵检测系统的基本思想就是,异常是和正常数据不同的并且数目相对很少,因此他们在能够检测到的数据中表现出比较特殊的特性。这样,我们就可以通过分簇的方法分别找出正常数据和异常数据的簇群。
2.数据库入侵检测系统模型
我们所提出的系统主要由三部分构成,第一部分是提取数据阶段。这阶段我们将数据库访问日记中的数据标准化,并将这些数据提取到一个虚拟的区域中进行下一阶段的工作。第二部分是数据分类阶段,也就是前面所提到的数据分簇。这一部分是我们这篇文章的主要工作。这里,我们提出了一种基于属性与关系的分簇方法,可以将数据库访问日记中的所有数据分成K个簇群,每个簇群内的数据都是属性相接近的。这样,我们就可以分别得到正常数据和异常数据的簇群。第三部分是入侵检测部分。在第二部分我们可以得到K个簇群,由于每个簇群之间数据类别的统一性,我们只需要鉴定其中的任一数据,看其是否符合检测模型,我们就可以判断这个簇群内的数据是正常数据还是异常数据。针对个别由于误差导致的错误和一些伪装性很高的异常数据,我们需要多检测每个簇内的数据。这样可以弥补一些数据检测的遗漏。为了更好地去理解我们的系统,图1可以形象地说明我们系统的整个流程。

图1 数据库访问日记入侵检测系统体系结构图
3.访问日记入侵检测聚类算法
输入:经过数据标准化的数据集Dataset,关系矩阵Wij。
输入参数:可调参数α。
输出:k个聚类。包括异常数据簇和正常数据簇。
(1)Di{i=1,2……n}表示数据库里的n个数据,计算所有数据的空间密度di,di越小,说明该点位于高密度区域。
(2)选取M个高密度区域的节点,表示为Ai{i=1,2……M}。
(3)选取A1作为第一个聚类中心,分别计算Ai与A1的欧氏距离dist(Ai,A1),选取距离最远的作为A2。
(4)重复步骤(3)计算 dist(Ai,A2),选取距离最远的作为A3。
(5)反复重复步骤(3),确定K个聚类中心,记为Ai{i=1,2……K}。
本文关于共享领域的安全头盔的CMF的研究分析主要体现在材料、工艺和颜色带来的美观性、安全性、可用性上。
(6)使Ci与Ai一一对应,作为K个聚类的中心点,i代表聚类的编号。通过公式(3.2)计算每个聚类的密度d(Ci)。
(7)添加一个节点v到Ci,通过公式(3.3)计算它的贡献值 c(v,Ci),如果 c(v,C)>α*d(c),则把这个节点归类到集合Ci中。否则,将数据归入到一个新的集合B。
(8)返回(6),直到B中的节点数目小于节点总数目D的5%,算法结束。
在我们的算法中,我们的方法存在一个难题,那就是如何去量化数据间的联系,数据中有着大量的标量,我们认为可以通过很多方法去定义数据间的联系,比如数据的大小、类型等等[6]。如果能够找到一个好的数据标准化的方法,那会让我们的方法更加有效率,也更加有说服力。这里,我们提出一种数据标准化的方法。
我们假设在数据库的访问日记中,数据之间存在着一种关系,我们把这种关系以数据之间的边来定义。这样,我们引入一个概念权重w(e),权重表示的是数据之间关系的一个紧密度。打个比方,如果两个数据间通过一条边连接,权重w即为1,如果两个数据间通过两条边连接,权重即为2。那么,如何去判定数据之间是否存在边呢?我们假设每个数据在库中都有一个明确的位置,用坐标轴(x,y)表示。我们计算数据与数据间的欧氏距离,然后我们给定一个关系阈值h,假如数据A1和数据A2的欧氏距离dist(A1,A2)<h,则判定两数据间存在着关系,即存在一条边E。这样的话,所有的初始数据处理完之后,我们可以得到一个数据集Dataset,它包含着数据以及数据的位置关系,还可以得到一个关系矩阵Wij。
得到了标准化的数据以后,我们考虑将数据进行分类。在数据挖掘技术中,最常用的算法有K-means等等。但是它也存在着一些不足之处。(1)K-means算法中需要先将聚类个数k确定下来。对于一组未知的数据,如果要事先确定分为几组,的确是一件比较困难的事,而我们往往是根据大量的实验来给定k的值,而这样会导致检测的结果不太准确。(2)K-means算法里,初始聚类中心的选择是很重要的。如果选择不同的初始聚类中心,可能会导致聚类的结果有很大的不同,传统的算法中,初始聚类中心是随机选择的,可能会导致检测结果不尽人意[4]。所以我们基于K-means算法做了一些改进。可以通过改进初始聚类中心使得算法更加有效率。
在数据空间里,低密度的空间对象区域分割高密度的空间对象区域,把处于低密度区域的数据点叫做噪声。我们取相互之间的距离最远的k个点作为初始的聚类中心,这k个点都要位于高密度,这样可以防止将噪声点取到。
首先我们要定义空间密度参数的概念,是用来求得数据Di的空间密度,判断它是在高密度区域还是在低密度区域。将数据Di作为中心,密度参数定义为包含常数M个对象的半径。用di表示,计算出来的di值越大,说明该数据点位于低密度区域中。计算出来的di值越小,说明该数据点位于高密度区域中。为了得到k个初始聚类中心,具体的聚类方法在算法中的前五个步骤已详细描述。
这里,我们还需要定义一些公式,它们会在算法中用到。首先,我们介绍一下欧氏距离的计算方法,如公式(3.1)。

公式里,A1和A2代表着两个数据,x和y分别代表它们位置的横坐标和纵坐标。
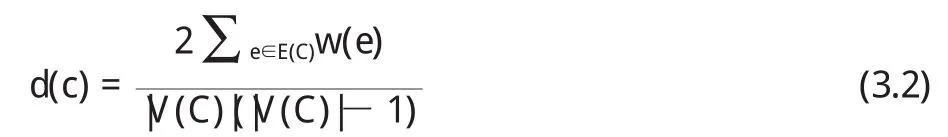
通过公式3.2可以计算出这个簇群的密度d(c),其中|V(C)|是这个簇群的尺寸,这里我们可以通过计算发现,如果w(e)为1的话,那么这个簇群的密度d(c)就为1。接下来我们对k-means算法进行改进来确定一个节点是否属于这个聚类中心的簇群中。这里我们是通过计算这个数据对整个簇群的贡献值c(v,C)来确定的,计算公式通过公式3.3计算。

如果c(v,C)>α*d(c),那么我们就说这个节点是属于这个簇群的。这里的α是一个可调参数。
我们的算法共有8个步骤,数据的输入部分Dataset和Wij是通过前面所提到的数据标准化过程得到的。首先通过对数据空间密度的计算,得到我们所需要的K个初始聚类中心。然后我们分别来确认每个节点是否属于这个聚类,直到算法结束。通过上面的算法,我们可以将数据分成K个聚类,由于同一聚类中数据特征的相似性。不管是正常数据还是异常数据,他们都应该在同一聚类中。
最后是我们模型的第三部分,也就是入侵检测部分。入侵检测引擎将收集到的信息加以分析,判断网络中是否有违反安全策略的行为和遭到攻击的迹象,若找到入侵痕迹,认为与正常行为相符合的行为是正常行为,与攻击行为相符合的是入侵行为,二者都不符合的,则认为是异常数据,将其加入到数据仓库中作进一步分析。经过我们前面所做的分簇聚类工作,我们将数据库访问日记中的数据已经分为几个聚类。如图2,是我们的入侵检测系统模块图。在数据经过模型第一部分和第二部分的处理后,我们就可以用检测引擎通过交换机从访问日记服务器中提取到数据并检测。我们只需检测每个聚类中的少数个体数据,就可以确定整个聚类的属性。鉴于少数被遗漏的数据,我们在系统的第三部分,也就是入侵检测部分。我们针对每一组聚类,提取10个数据进行检验。我们假设如果它们全部都符合检测模型,那么这个簇里的数据全都是正常数据。如果它们全部都不符合检测模型,那么这个簇里的数据全都是异常数据。如果符合于不符合的数据都存在,那么说明这组聚类是不完备的。那么,我们先将这组数据放入空白区域,待所有的分簇都判定完成以后,我们再重新通过算法来分类。

图2 数据库访问日记检测系统模块图
4.结语
数据库系统的安全特性主要是针对数据而言的,包括数据独立性、数据安全性、数据完整性、并发控制、故障恢复等几个方面。入侵检测技术是计算机安全领域的一项重要技术,目前也有很多研究人员将它应用在数据库系统中。但是它存在着一些不足。本文将聚类的思想与入侵检测技术相结合应用在数据库的数据检测上。首先我们要将数据库访问日记中的数据标准化,然后我们通过聚类算法将数据分类。最后再通过入侵检测引擎对数据进行检测。这样,可以高效地将数据库分块并找到数据库中的异常数据。
[1]宋红.计算机安全技术[M].中国铁道工业出版社,2005.
[2]卢硕珽.数据库入侵检测系统的设计与分析[D].中山大学,2010.
[3]张洪斌,李娜.多信息源数据库入侵检测系统[J].电子商务,2011年(11期).
[4]史习云.改进的k-means聚类算法在图像检索中的应用研究[D].江苏大学,2010:37-38.
[5]M cHugh J.Testing intrusion detection systems:a critique of the 1998 and 1999 DARPA intrusion detection system evaluations as performed by Lincoln Laboratory[J].ACM transactionson Information and system Security,2000,3(4):262-294.
[6]Lee S,Low W,Wong P.Learning fingerprints for a database intrusion detection system[J].Computer Security— ESOR ICS 2002,2002:264-279.
