斯坦福大学关联数据报告概述
2013-07-23欧亮
欧 亮
(重庆第二师范学院 图书馆,重庆 400065)
斯坦福关联数据研讨会[1]于2011.6.27-7.1召开,其主办者图书馆信息资源委员会(Council on Library and Information Resources,CLIR)与斯坦福大学图书馆与学术信息资源中心(Stanford University Libraries and Academic Information Resources,SULAIR)通过组织相关图书馆员和技术专家来描述图书馆应用关联数据的问题和挑战等等,并最终形成了斯坦福大学关联数据报告。报告在开头引用了《图书馆关联数据孵化小组最终报告》[2],其中文版[3]已由娄秀明翻译,作者在这就不进行介绍了。斯坦福大学关联数据研讨会报告的内容主要包括以下几个方面:
1 有价值的声明:为什么关联数据方法是有价值的原型和模型
研讨论会通过讨论认为关联数据方法在图书馆系统环境中的作用主要有:(1)关联的开放数据(Linked open data ,LOD)把信息放在大众都在利用的万维网上;(2)LOD 能扩展图书馆资源被发现的范围;(3)LOD 提供了在数字环境下的学术交流活动的改革创新的机会;(4)LOD 提供了一个开放持续完善数据的环境;(5)LOD 创建了能改善服务所需要的计算机可操作数据库;(6)图书馆链接的开放数据可能促进打破本领域孤立地位;(7)LOD 能提供现在无法直接访问数据的方式,同时当LOD 数据库成指数增长后其所带的优势是不可想象的。
2 关联图书馆(博物馆、档案馆等)宣言
研讨会通过总结以前的经验,同时从文化和知识管理机构自己或帮助其他机构通过关联数据途径以发现更好的方法来发布、分享和使用信息的角度出发,颁布其宣言如下:(1)发布数据到万维网上是为了让更多人使用和发现,而不是让其商业化和私有化。(2)不断提高数据和关联数据的质量,而不是等着发布完善的数据。(3)构建具有语义的数据,而不是非结构的数据。(4)要团结协作,而不是单打独斗。(5)积极采纳万维网标准,不仅限于图书馆等领域的标准。(6)使用开放宜懂的许可协议,而非封闭或专业难懂的许可协议。
3 培育图书馆关联数据的环境
图书馆传统的MARC 数据转码到RDF 三元组的图表流程如下:
(1)第一阶段的工作是转换MARC 或其他数据为RDF 三元组。同时在此阶段,统一资源标识符(URIs)也将会产生,并且在此过程还需要随时检测URIs 是否与外部的资源重复。
(2)分类法(如LOC)将被用于分类,同时“正式的”URIs 能稳定的被查找和使用,如http://id.loc.gov/提供的。到此,RDF 库所拥有的数据可以提供给合适的伙伴使用,从而能较早的得到问题的反馈,以为开发早期的可视化服务和描述未来的问题和机遇打下基础。
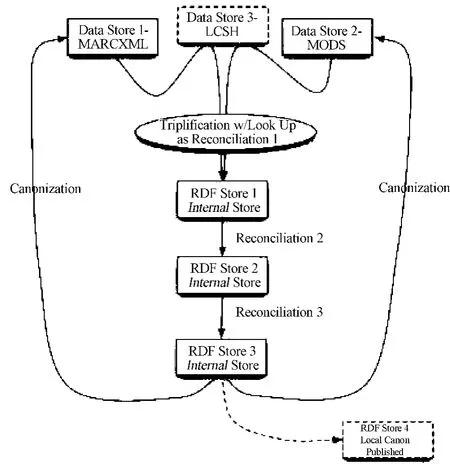
图1 MARC 数据转码到RDF 三元组流程图
(3)接下来的阶段数据(或叫更精确的知识)将不断增加,这时需要重点关注提高同指或同一性(Reconciliation)的信息。在这过程在RDF 库上进行的基于机器的算法将应用于识别同指信息(如asserting skos:exactMatch or owl:sameAs or equivalents)以节约人力。但是伴随当人们大量的参与其中时,进一步的同一性控制将最终全面发生。这是因为除开成本,当更广的领域参与其中时,人的力量很多时候是不可靠的,所以那些用于寻求人去做选择,而不是从头作到尾的系统是更有应用价值。同时在这个过程中记录那些被认为是相同的成对的URIs,又是被确定的是很有价值的。
(4)同一性阶段可能包括:查询,标准化,简单匹配,语义匹配和手工操作。
(5)随着同一性过程的进行,大量的URIs 将能找到其复本,同时这样就能通过有用性来减少他们,这个过程就叫着封存(canonization)。
(6)通过反馈过程将同指信息反馈到开始,然后将其只做为查询用,到后面的阶段就把它们删除掉。
(7)在这些阶段中,当外部系统开始使用URIs,而且其还希望他们被维护时,这就是发布的时候。
(8)已经是同一性过程的主题的URIs 将不会被删除了,但是他们能够在第一个阶段用于查询。
通过上面的流程图可以知道创造一个可用和有用的关联数据环境需要通过迭代的途径来产生、使用和提高关联数据数据库和服务。这些能够被描述为关联数据周期的各个阶段。这些阶段从提出有价值的关联数据方法的提议到实际操作中使用关联数据服务的实例。接下来的一些阶段为:
(1)构建用例
(2)摄入数据(从开放数据库中使用结构化的数据,构建或转码关联数据或进行质量控制)
(3)发布数据,其他机构或个人能够使用
(4)提供基于通过用例得到信任的结构化数据的服务
(5)重复1-5 的步骤去添加或更新用例,以得到新的相关的数据,提高数据和推进服务。
(6)培训元数据的生产者(如出版者、图书馆馆员和学术项目的带头人)和对最终服务进行营销以提供给终端用户。
关联数据的一个必要条件就是要有高信度的结构化的数据控制,一些与会参与者认为如果数据的精确度达不到97%就会导致用户的不满,但这种推断还有待于进一步的测试和还需要在很多的服务所提供的不断迭代和提高URI 的精确度以及关联数据被广泛使用的条件来进行判断。
4 已知问题的优先列表
研讨会的专家们列出了图书馆和文化机构在使用关联数据时应该解决的特殊需求和挑战,通过调查分类,其问题主要涉及来源、可用性、保存和标准这个四个方面。
4.1 跨格式参照,同指与一致(标准问题)
由于在实践的过程,通过建立和提升标准化的方法来与其他数据文档保持联系造成的。这主要涉及两个层面,第一个层面的问题涉及两个事实的陈述和做出这两种说法是否是相同的决定;在第二个层面是指它的复杂性,这是当规划,创建,发布和管理关联数据,必须处理结构化数据词表的范围,
4.2 图书馆规范文档的使用如名称和主题等(标准和可用问题)
图书馆元数据是关联数据重要的来源,这主要是因为图书馆元数据规范文档能够帮助关联数据进行术语控制。当一个规范文档与别一个规范文档建立关系时,主要是通过程序进行处理,而这些术语在计算机环境中只是一串的字符,所规范文档的使用就能在计算机程序条件准确无误的进行标识了。这里要涉及的问题就是大量的规范文档的建立和维护。
4.3 杀手级应用(可用问题)
这主要是涉及关联数据的如何应用问题研究。
4.4 归属,来源及规范(来源问题)
这是要经常面对的问题,其看上去是图书馆等文化机构在面对关联数据世界最大的挑战,其要求我们能掌握好开放性和准确性的关系。因为不是所有人知道URI 所拥有的属性,只有其发布者才能理解,所以其要为大家所共知还需要进行良好的处理,现在对此的研究比较热。
4.5 培训创建、衍生和发布URI,但是在做链接和使用链接时却处于不断变化的环境(可用问题)
创建和发布URIs 不是困难的技术问题,困难的技术问题是围绕在对元数据的表达。
4.6 数据的可用性(可用问题)
数据必须是具体化的。有能力去指定属性,如可靠和来源RDF 数据需要有系统能够使元数据说明(metadata statements)指向元数据,也就是能把一个数据当成一个事件来指向。现在对此研究比较热。然而,在实践中大部的RDF 系统提供多种技术如通过使用RDF 库和SPARQL 的组合来保证可信任属性能被确定和获取,如Named Graphs。
4.7 质量控制(可用问题)
质量控制必须包括URIs 的创建和长期的维护,其中还包括不熟悉的语言,这个挑战是相当大的。
4.8 URIs 标准问题(标准问题)
关联数据的一个宗旨就是URIs 必须是可读的,同时,更重要的是当他们确定后,他们应该是指向有用的信息。Kyle Neath 和Jeni Tennison 对URL 设计进行了比较详细的调查,他们认为URL 结构的设计是应该好好考虑的,这关系以后的使用。
4.9 数据保存(保存问题)
关联数据使用的是URIs,关联数据能够被搜集后进行以文档方式保存。这其中就涉及由谁来保存,如何进行保存的问题,利用什么技术等。
4.10 责任分配问题(可用问题)
关联数据所涉及的主体是很多的,这其中责任的分配问题直接关系到其成功。
4.11 营销和宣传(可用问题)
这里的关键是吸引用户的使用、培训工作人员及用户。这样才能有更多的人关注关联数据,从而促进其发展。
4.12 工作流程(可用问题)
工作流程应该重点考虑的是什么应该包括到这个工作流程中,他们认为http://sameas.org/ 的工作流程就比较相似。
4.13 可伸缩性问题
与会人员认为Web Scale 系统已经完成,接下来开发URIs 是理所当然的。因为面临的挑战是转换和制造的URI,然后将其放在开放库中以便最终能提供使用。
4.14 索引问题
索引还不够准确和可靠,如何改进才能更好的帮助其发展。
4.15 本体的使用(标准问题)
如果本体用于关联数据,其能很好的解决不同领域的交互问题,但其存在的问题就是不同国家,文化和不同时语言的处理。
4.16 许可问题(标准问题)
元数据的许可是相当多的,他们的开放对于关联数据的应用是具有相当大的帮助的。现在已经有些国家开放了他们的元数据。
4.17 注释(来源问题)
对于注释的处理这里有两种办法,一种就是把注释当做是对现存内容所添加的评论。另外一种就是把注释当做是扩展和重新定义元数据或其他导航的以帮助发现和探索文化遗产资源。
4.18 同一性管理
在上面的流程图中广泛使用了同一性管理子系统,另外,当要从多个机构所发布的关联数据中获得有价值的数据时需要同一性管理系统以在多个机构中交互。
4.19 与e-学术(尤其是e-科学)和e-学习的关系
可分离的元素的扩散附加到或嵌入在学术交流,特别是文章,自从网络出版在上世纪90 年代中期出现,以及类似的基于网络的课程管理系统支持表明有必要更多的元数据和索引产生。通过关联数据途径,优化生成算法的论文由出版商和互联网服务提供商处理能够使分离的元素得到发现,从而节约研究人员和老师的时间和精力。结合与出版商的数据链接库链接的数据和从各种其他来源,包括学术项目,关联数据可能会导致大大提高了速度,相关性,发现和细化搜索的手段
4.20 文化多样性(可用问题)
关联数据的主要承诺之一,是其固有的兼容性多种语言。通过URIs 的形式表达实体和概念而不是字符串,研究者和文化机构可能会越过这个绊脚石,这就涉及到关联数据环境的设计问题,通过URIs 能够可以输入和输出适当的国际化字符串,并显示它也可能包括支持架构可以反映和与不同文化的理解和上下文常见的实体
4.21 搜索引擎的优化(标准问题)
当前迭代的结构化数据知名如微数据志在于提供更好的检索结果,如schema.org,其他的迭代方法有Google’s“rich snippets”和关联数据领域提供的RDFs
4.22 社会化媒体:FaceBook 应用程序等
Facebook 的开放图形协议(Open Graph protocol)志在通过社会图形提供足够的信息去表达任何的网页,OGP 提供网页开发者一个用于为网页四个属性添加元数据的框架。OGP 和其他扩展社交媒体的图形组件为关联数据和语义网支持者和参与者相当大的突破。
上面对图书馆使用关联数据所面对问题和挑战进行了介绍,这里还需要指出的是对于上面所有的问题,资源的分配(如人员、外包和经费等)可以导致其他并发问题的产生,同时要解决上面的问题的最有力的方法就是通过在关联数据环境下的商业案例来提供的服务以提高终端用户发现和导航的能力。
5 部署关联数据
5.1 早发布,常发布
这主要是因为关联数据技术现在还没有广泛的传播使用,所以很有必要通过现阶段的实践来预见下阶段的问题,使失误减少到最少。另外,关联数据技术才出现,图书馆的专家和用户需要通过前期的使用后才能为图书馆关联数据发展提供新的反馈。
5.2 创建URIs
选择去制造一个新的URI 作为标识通过是简单和快速的决定。允许继续转化三元组的过程和尝试重新使用存在的URIs 使转化三要素的过程变得复杂化,从而导致了发布的推迟。确定合适的URIs来重新使用非常容易出错,从而能降低三元组转化的质量。
5.3 把链接放到后面
链接是一项艰巨的工作,不要在开始就做它。这是因为它需要大量的知识,同时有可能在随着项目的推进得到解决以促进链接的错误率,而且还有可能在后面别人都为你做好了。
6 寻找关联数据的关键应用
现在有必要通过各种调用为杀手级的应用来证明利用关联数据来发现和导航包括信息实体,描述他们的元数据和在图书馆、博物馆等实物的有效性,现在已经有曙光,但没有走出清楚的新一个级别的搜索或导航功能,现在有一些小的实例,可能比较诱人。如下:
(1)David Huynh (MIT)的freebase parallax
(2)BBC 的野生动物子网站由关联数据做的后台。
(3)LinkSailor,a Talis experiment
(4)Civil Ware 150
(5)Metaweb/Freebase
7 下一步和将来做的计划
7.1 下一步的工作
斯坦福团队将与其他团队一起合作创建一个基于开放的链接数据的多国和多机构的发现模型,以向终端用户和我们领域相关的研究者证明关联数据方法是很有价值的。这个模型功能包括生成、获取、迭代调整URIs,同时其还要采用或生成一个或多个杀手级应用和组装或呼吁相关工具来支持流程中必要的步骤,其后再开拓针对学术信息资源的环境。
7.2 明确的计划
(1)创建URI
由学术期刊文章元数据创建结构化数据URI,斯坦福HighWire 出版社与大英图书馆(BL)潜在联合计划。目标元数据来自:HighWire 服务器的文章(6.7M)、Medline/PubMed 的元数据(>21M 引文)、大英图书馆得到许可使用的2 万种期刊的文章。
(2)MARC 记录
斯坦福团队将与参加这次会议的国家图书馆(国会图书馆、大英图书馆、法国国家图书馆和德国国家图书馆)等一同工作。受2011 年9 月欧洲国家图书馆会议(CENL)投票支持将其元数据开放为关联开放数据的鼓舞,我们将追随BL 协同Talis 设计一个丰富的、理解网络的图书馆关联数据的数据模型,通过由MARC 记录出取适当事实构建其关联数据,将数据发布为开放数据而不限制其使用。同时我们还将关注支撑当今图书馆元数据的不同类型的规范记录。
(3)开放虚拟国际规范文档(VIAF)
高度期望创建一个开放的VIAF,或者请求OCLC 以开放关联数据服务提供VIAF。
(4)手稿互操作
斯坦福将以URIs 收集手稿描述(著录),然后由斯坦福或其他机构来连接展示不同中世界手稿集的个别应用。
(5)关联开放数据工具套件
已知工具太一般不适合图书馆需要,出版者则需要另外的工具。目标不是罗列所有已有工具,而是引进经试用与测试的工具与方法,向没有关联数据经验的机构提供。
(6)MARC 交换所
应当由URI 建立MARC 交换所(数据存储),应当包括资源的FRBR 第一组实体关系即WEMI。
7.3 其他潜在计划
(1)特定领域计划
通过关注或参与关联数据相关的项目(如英国呼吸系统团队、NLM),引入某些特殊的本体成为LOD 以提供使用,寻找用例(如Nines)或可能成为用例的项目(如Civil War 150),为某些对跨专业领域有期望的专家提供帮助和争取其他项目的支持(MyExperiment.org、Getty 叙词表等)以进一步扩大关联数据的影响力和研究范围等等。
(2)关联数据能力构造
通过扩展图书馆团体发布、加强和利用关联数据的能力,发动来自不同领域的具有不同能力的机构参与,认识到创建研讨会、工具、学习机会和简单捐赠数据去创建URIs。
8 结束语
关联数据(L inked Data)概念由Tmi Berners-Lee 于2006 年首次提出,其通过网络把以前没有关联的相关数据连接起来,成为推动语义Web 发展的重要力量之一,近年来逐渐得到学术界、工业界及政府部门的广泛关注,包括BBC、纽约时报、MIT、IEEE、HCLS、美国国会图书馆等在内的机构纷纷加入到关联数据的出版发布队伍中。斯坦福关联数据研讨会通过对关联数据方法的价值研究、发表关联数据宣言、培育图书馆关联数据环境和列出图书馆使用关联数据先后顺序的问题等等,对图书馆关联数据研究进行了较为完整的研究和展望。而在国内对图书馆关联数据的研究还处于探索阶段,希望能通过对此报告的概述能对我国图书馆关联数据研究提供帮助。
[1]Linked Data for Libraries,Museums,and Archives:Survey and Workshop Report [EB/OL].(2011-10)[2012-3-4]http://www.clir.org/pubs/abstract/reports/pub152
[2]Library Linked Data Incubator Group Final Report [EB/OL].(2011-10-25)[2012-3-4]http://www.w3.org/2005/Incubator/lld/XGR-lld-20111025/
[3]图书馆关联数据孵化小组最终报告[EB/OL].(2011-11-14)[2012-3-4]http://libspace.org/2011/11/14/tu-shuguan-guan-lian-shu-ju-fu-hua-xiao-zu-zui-zhong-bao-gao/
