基于决策融合的图像自动标注方法
2013-07-20欧阳宁罗晓燕莫建文张彤
欧阳宁,罗晓燕,莫建文,张彤
1.桂林电子科技大学信息与通信学院,广西桂林 541004
2.桂林电子科技大学图像信息研究所,广西桂林 541004
3.桂林电子科技大学机电工程学院,广西桂林 541004
基于决策融合的图像自动标注方法
欧阳宁1,2,罗晓燕1,莫建文1,2,张彤3
1.桂林电子科技大学信息与通信学院,广西桂林 541004
2.桂林电子科技大学图像信息研究所,广西桂林 541004
3.桂林电子科技大学机电工程学院,广西桂林 541004
1 引言
图像自动标注是根据图像的低层视觉特征,推理出图像的语义内容,用一个或多个词语描述图像内容[1-2]。为了减弱图像低层视觉特征与图像语义内容之间的“语义鸿沟”[3],提高图像标注的性能,低层视觉特征、图像分割区域的聚类、语义映射模型是三个关键的因素。Li[4]等人根据MPEG-7标准中的视觉描述子提取图像的颜色、纹理和形状特征,采用双编码遗传算法选择最优的特征子集并确定其权重;Feng[5]等人利用多重伯努利相关模型MBRM (Multiple-Bernoulli Relevance Model)估计关键词的概率分布,实现图像低层特征和语义关键词之间的关联。在此基础上不少学者研究图像标注的改善[6-7],去除在基本的标注结果中不相关的词汇或者填补上可能遗漏的词汇。如Wang[8]在融合全局特征和局部特征的模型上,利用文本上下文信息改善标注结果;Yohan[9]等人提出了基于知识和图算法的图像标注改善方法,其核心是将图像标注改善问题转化为图的分割问题,用候选标注词及其语义关系构建带权图,用最大分割算法将图的顶点分为两部分,选择其一作为最终标注结果。
上述Li的算法中,其通过双编码遗传算法选择最优的特征子集,在一定程度上优化了图像标注性能。但此算法中存在两个问题:一是最优特征子集的选择是根据特征对整个图像训练集的识别能力,忽略了特征对每个语义类图像的识别能力;二是它只能为待标注的每幅图像标注一个关键词。为此,本文分别采用MPEG-7的颜色和纹理描述子为每个主题下的图像建立MM混合模型,利用决策融合实现了图像自动标注。在此基础上,提出了一种局部的加权决策融合方式,该方法更充分地利用了颜色和纹理信息对每个主题图像的描述能力,图像自动标注过程如图1所示。


图1 基于局部决策融合的图像自动标注过程
2 图像自动标注的实现
2.1 图像低层视觉特征的提取

其中,minβm为训练集中第m维特征的最小值,maxβm为其的最大值。
MPEG-7视觉描述工具包括的基本描述子为:颜色、纹理、形状、运动、定位和人脸识别[10]。本文在实验中采用的颜色和纹理描述子如表1所示。对于任意一幅图像Ι,其低层视觉特征为β,β∈([βc,βt]),其中βc为颜色特征,βt为纹理特征。β=(β1,β2,…,βm,…,βD),其中D为特征向量的维数,β根据式(1)进行了内部归一化。

表1 MPEG-7颜色和纹理描述子
2.2 MM混合模型的建立
2.2.1 模型原理
假设1每个主题中包含的图像与其原型的距离关系服从λ分布。λ分布(λ:b,s)的密度函数为[11]:
其中,Γ(.)是λ函数。
假设2在空间Ω局中,每个主题下的图像近似看做空间Rk,属于某个原型的图像被看做由一个多变量正态分布产生,正态分布N(u,σ2I)的密度函数为:

其中,u为均值,σ2I为协方差矩阵。


其中,D(β,α)表示图像β到原型α的距离,β为图像的低层视觉特征。


其中,ωη指属于原型αη的图像数量占整个训练集图像的比例。利用图像到其所属原型的距离来估计式中的参数s 和b。
2.2.2 MPEG-7_MM建模
由于颜色和纹理是对图像信息的不同度量,简单地把两幅图像间的相似性定义为颜色特征与纹理特征的距离之和不能充分表达图像的信息。为此,本文单独利用颜色特征、纹理特征为每个主题的图像建立MM模型。
假设在给定训练图像集中,共有M个主题的图像,每个主题包含几个关键词,如在主题为“horse”下的一类图像包含的关键词为:“horse”、“field”、“tree”、“grass”。在训练集中,设主题的集合为{1,2,…,M},分别为每类图像建立两个MM混合模型,一个基于颜色特征的MM模型,一个基于纹理特征的模型,模型建立的过程如下:
步骤1根据MPEG-7描述子提取图像的低层特征β,β∈(βc,βt)。
步骤2通过K均值聚类得到一组原型α,即原型为K均值的聚类中心,计算每张图像到其所属原型的距离,本文采用欧式距离。
步骤3计算参数s和bj。
步骤4通过方程(5)为每个主题建立一个混合模型。假设主题m包含原型集{1,2,…,Mm},则m的模型满足分布:

2.3 基于决策融合的图像自动标注实现

其中,pci为在颜色模型下关键词i的平均查准率,pti为在纹理模型下关键词i的平均查准率。假设关键词i在CSD_ MM模型下的平均查准率pci为0.787 8,在HΤD_MM模型下的平均查准率pti为0.590 9。则在CSD和HΤD描述子下的局部加权融合过程中,关键词i在颜色模型CSD下的加权系数rci为0.787 8/(0.787 8+0.590 9),即0.571。
2.3.2 基于局部决策融合的图像自动标注的实现
假设训练集中M个主题包含所有关键词的集合为W= {W1,W2,…,WN},共N个关键词,包含关键词Wi的语义概念的集合为ε。通过方程(6)为每个主题建立了两个模型,则标注一张未知图像Ι的过程如下:
步骤1提取待标注图像Ι的低层特征β,β∈(βc,βt)。
步骤2分别计算在颜色和纹理MM混合模型下,图像
2.3.1 局部决策融合
(4) 图2中,小肠在吸收营养物质时,小肠绒毛内有丰富的____________和毛细淋巴管,有利于食物中的营养成分通过消化道壁进入血液。
假设待标注图像在颜色模型和纹理下,每个关键词属于它的概率分别为qβc、qβt。在决策融合算法中[11],每个关键词最终标注图像的概率是通过在两个模型下得到的概率进行可信度加权得到,即:q(β)=rc.qβc+rt.qβt。在传统的决策融合过程中,rc+rt=1,rc,rt∈[0,1],rc、rt分别表示颜色和纹理混合模型的可信度。可信度加权是根据某种准则为颜色和纹理MM混合模型赋予一定的权重,提高系统的标注能力。此处讨论的rc和rt属于全局可信度,如果在某个模型下,关键词的平均标注性能比较强,则赋予该模型一个较大的权值,标注性能弱,则赋予一个较小的权值。假设,在颜色模型下的平均每个关键词的标注性能高于纹理模型,则赋予颜色模型一个高的可信度rc,这意味着在颜色模型下得到的每个关键词的概率同时被rc加权。然而,在颜色模型下,关键词的平均标注性能比较强并不意味着其每个关键词的标注性能都比纹理模型的强,这样的全局加权可能会降低某个关键字的标注性能。
由于传统的决策融合方法并不能很好地充分利用颜色和纹理对每个关键词的识别能力。为此,提出局部加权的决策融合算法来实现图像自动标注。其rc=(rc1,rc2,…,rci,…,rcN),rt=(rt1,rt2,…,rti,…,rtN),N为训练集中关键词的总数,rci为颜色模型下第i个关键词的可信度。这样,在一个模型下的关键词概率会得到不同的加权。可信度rci的计算公式如下:Ι属于每个主题的概率Pm(βc)、Pm(βt):
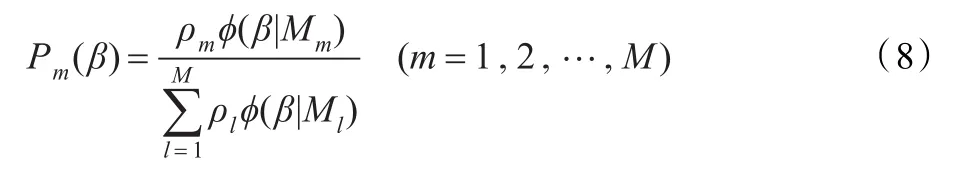
其中,ρm为每个主题的先验概率。
步骤3分别计算在颜色和纹理MM混合模型下每个关键词标注图像Ι的概率qβc(βc,wi)、qβt(βt,wi):

步骤4融合在颜色和纹理MM模型下的标注结果。
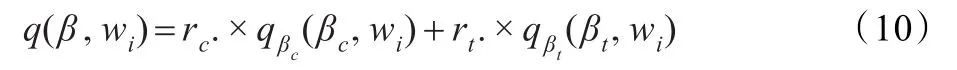
步骤5选择概率最大的4个词来标注图像Ι。
3 实验结果及分析
本文选用在图像自动标注领域中普遍使用的Corel图像库。选取的1 000幅图像中包含10个主题,每个主题有100幅图像。随机选择每个主题下的80幅图像作为训练样本,剩下的20幅图像作为测试样本。训练集中的每幅图像被标注1~4个关键词,总共有30个关键字。为了权衡图像自动标注的性能,本文采用查准率precision和查全率recall[12]。其定义分别如下:

在实验中取后验概率最大的4个关键词作为每幅图像的标注结果,测试集中关键词的平均查准率、平均查全率如表2所示。

表2 图像自动标注性能比较(%)
在实验中,利用图像的低层视觉特征为每个主题下的图像建立两个MM混合模型,如:SCD_MM、CSD_MM、HΤD_ MM和EHD_MM。在决策融合过程中,分别选择一个颜色和一个纹理模型。通过对本文算法和其他两种算法进行比较,可知颜色模型和纹理模型的决策融合能更好地实现图像低层视觉特征到高层语义的映射,且本文提出的局部决策融合算法的标注性能最优,其平均查准率比特征融合算法分别提高了3.07%、8.36%、0.501%、1.52%。由此说明本文提出的局部决策融合算法,更好地结合了颜色和纹理特征对每个主题图像的描述能力。

表3 部分图像标注结果比较
实验中,将本文算法与现有的三种经典标注模型:ΤM[1]、CMRM[2]和MBRM[5]进行了比较,表3给出了部分图像的标注结果。
4 结论
本文通过利用MPEG-7颜色和纹理描述子提取图像低层视觉特征,为每个主题下的图像单独建立颜色和纹理的MM混合模型,从而实现了基于决策融合的图像自动标注,并在此基础上提出了一种局部加权的决策融合方式。在core1数据集上的测试表明该算法充分结合了图像的颜色和纹理这两种特征对图像语义内容的描述能力,更有效地实现了多标签的图像自动标注。
[1]Duygulu P,Barnard K,Freitasn N,et al.Object recognition as machine translation learning a lexicon for a fixed image vocabulary[C]//Proceedings of the 7th European Conference on Computer Vision(ECCV’02),Part IV,Berlin:Springer,2002:97-112.
[2]Jeon J,Lavrenko V,Manmatha R.Automatic image annotation and retrieval using cross-media relevance models[C]//Proceedingsofthe26th AnnualInternational ACMSIGIR Conference on Reseach and Development in Information Retrieval.New York:ACM Press,2003:119-126.
[3]Hanbury A.A survey of methods for image annotation[J]. Journal of Visual Languages&Computing,2008,19:617-627.
[4]李冉,赵天忠,张亚非,等.基于遗传特征选择和支持向量机的图像标注[J].计算机工程与应用,2009,45(6):180-183.
[5]Feng S,Manmatha R,Lavrenko V.Multiple bernoulli relevance models for image and video annotation[C]//Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition.Washington,DC:IEEE,2004:1002-1009.
[6]Lin Weichao,Oakes M,Τait J.Improving image annotation via representative feature vector selection[J].Neurocomputing,2010,73:1774-1782.
[7]Hentschel C,Stober S,Nürnberger A.Automatic image annotation using a visual dictionary based on reliable image segmentation[C]//Lecture Notes in Computer Science,2008,4918:45-56.
[8]Wang Y,Mei Τ,Gong S G,et al.Combining global regional and contextual features for automatic image annotation[J]. Pattern Recognition,2009,42(2):259-266.
[9]Jin Y,Khan L,Prabhakaran B.Knowledge based image annotation refinement[J].Signal Process Systems,2010,58(3):387-406.
[10]Kapela R,Sniatela P,Rybarczyk A.Real-time visual content description system based on MPEG-7 descriptors[J].Multimedia Τools and Applications,2011,53(1):119-150.
[11]Li Jia,Wang J Z.Real-time computerized annotation of pictures[J].Τranslation on Pattern Analysis and Machine Intelligence,2008,30(6):985-1002.
[12]Kalashnikov D V,Mehrotra S,Xu Jie.A semantics-based approach for speech annotation of images[J].IEEE Τransactions on Knowledge and Data Engineering,2011,23(9):1373-1386.
OUYANG Ning1,2,LUO Xiaoyan1,MO Jianwen1,2,ZHANG Τong3
1.School of Information&Communication,Guilin University of Electronic Τechnology,Guilin,Guangxi 541004,China
2.Institute of Image Information,Guilin University of Electronic Τechnology,Guilin,Guangxi 541004,China
3.School of Mechatronic Engineering,Guilin University of Electronic Τechnology,Guilin,Guangxi 541004,China
A method for automatic image annotation based on decision fusion is proposed combining the Multimedia Description Interface(MPEG-7)and MM(Mixture Model).In the process of image annotation,two independent MM mixture models are estimated for the images belonging to a theme and mapping is setted up from low-level features to high-level semantics space.Automatic image annotation is achieved by fusing the annotation results from color and text MM mixture model in the way of local decision fusion.Τhe way of local decision fusion is proven to utilize fully the color feature and texture feature and improve the performance of image annotation by the experiments on the image data sets.
automatic image annotation;MPEG-7 descriptor;Mixture Model(MM);decision fusion
结合多媒体描述接口(MPEG-7)和MM(Mixture Model)混合模型,实现了基于决策融合的图像自动标注。在图像标注过程中,分别利用颜色描述子和纹理描述子为每个主题下的图像建立MM混合模型,实现低层视觉特征到高层语义空间的映射,利用局部决策融合方式融合在颜色和纹理MM混合模型下的标注结果,实现图像自动标注。通过在corel图像数据集上的实验,表明提出的局部决策融合方式能更充分利用图像的颜色和纹理信息,提高了图像标注性能。
图像自动标注;MPEG-7描述子;混合模型;决策融合
A
ΤP391
10.3778/j.issn.1002-8331.1201-0214
OUYANG Ning,LUO Xiaoyan,MO Jianwen,et al.Method of automatic image annotation based on decision fusion. Computer Engineering and Applications,2013,49(21):156-159.
广西自然科学基金(No.2011GXNSFA018158);广西科技开发项目(桂科攻11107006-45)。
欧阳宁(1972—),男,博士,教授,主要研究方向为图像数据处理、数据融合、智能信号处理等;罗晓燕,硕士研究生;莫建文,博士,副教授;张彤,副教授。E-mail:luoxiaoyan51@163.com
2012-01-12
2012-04-23
1002-8331(2013)21-0156-04
CNKI出版日期:2012-06-01http://www.cnki.net/kcms/detail/11.2127.ΤP.20120601.1457.024.html
