基于关联图划分的Kmeans算法
2013-07-20李正兵罗斌翟素兰涂铮铮
李正兵,罗斌,翟素兰,涂铮铮
1.安徽大学计算机科学与技术学院,合肥 230039
2.安徽省工业图像处理与分析重点实验室,合肥 230039
3.安徽大学数学科学学院,合肥 230039
4.安徽大学计算智能与信号处理教育部重点实验室,合肥 230039
基于关联图划分的Kmeans算法
李正兵1,2,罗斌1,2,翟素兰1,3,4,涂铮铮1,4
1.安徽大学计算机科学与技术学院,合肥 230039
2.安徽省工业图像处理与分析重点实验室,合肥 230039
3.安徽大学数学科学学院,合肥 230039
4.安徽大学计算智能与信号处理教育部重点实验室,合肥 230039
1 引言
传统的Kmeans是基于中心的聚类算法[1],因其简洁、运算速度快,并能有效地处理大数据集而得到广泛应用。Kmeans有很多固有的缺陷[2-3]:对初始聚类中心的选择过于敏感且容易陷入局部极值;聚类参数k很难确定。实际的应用中,用户往往不充分了解数据的分布特性,很难确定聚类参数k,增加了用户的负担。这两个缺点极大地制约了Kmeans的应用。
针对传统Kmeans的缺陷,学者们做过一系列的研究。文献[4-5]采用基于密度的最大最小距离法替代了传统Kmeans随机初始化聚类中心的方法,在收敛速度、准确率方面都有了较大的提高;文献[6]运用距离代价函数作为聚类有效性检验函数,即当距离代价函数达到最小值时,空间聚类结果为最优,并在理论上做了严格证明;文献[7]用直方图方法将数据样本空间进行最优划分,依据样本自身分布特点确定k值;文献[8]提出了一种新的基于数据样本分布特性选取初始聚类中心的Kmeans算法。
本文通过分析原始数据集的分布特性,提出了基于关联图的Kmeans算法(以下简称:KCG),能够在用户指定的密集程度η下,自动确定聚类的数目,减轻了用户的负担,同时选取每个类别中关联度最高的对象作为初始聚类中心。这种做法的优点是能够从全局的角度将初始聚类中心均衡地分布在整个数据空间中,避免了因对初始聚类中心的选择而陷入局部极值。该方法可以得到较为合理的初始聚类中心和聚类数目,将它们作为参数调用Kmeans算法。通过有效性分析和实验表明,KCG具有以下优点:
(1)聚类的准确率能够达到多次运行传统的Kmeans算法的最高准确率。
(2)算法在用户指定的密集程度η下自适应地确定数据集的聚类数目。
(3)多种数据集,多次运行KCG算法,聚类结果稳定性很好。
2 Kmeans算法思想
Kmeans算法是基于划分的聚类方法,是十大经典数据挖掘算法之一。Kmeans算法的基本思想是[1]:通过用户事先指定聚类数目k,随机选择k个对象作为初始聚类中心,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至标准测度函数开始收敛为止。

所获得的聚类应满足[1]:同一类中的数据对象相似度较高;不同类中的数据对象相似度较小。
假设要把数据集D分为k个类别,传统Kmeans算法描述如下:
步骤1随机选择k个类的初始聚类中心;
步骤2对任意一个对象,计算到k个中心的距离,并将该对象归到相似性最大的中心所在的类;
步骤3利用均值法更新k个类的中心值;
步骤4对于所有的k个聚类中心,如果利用步骤2、步骤3的迭代法更新后,标准测度函数收敛或达到最大迭代次数,则迭代结束,否则继续迭代。
3 图划分问题的数学描述
图划分的优化理论可以描述为:
对于一个图G=(V,E,ω),其中顶点集为V=(ν1,ν2,…,νn),边集为E⊆V×V,用w:E→R表示边上的权值,现将图G划分成k个子图G1,G2,…,Gk,且G1∩G2∩…∩Gk=Φ,满足以下目标函数:上式是求子图间权重之和的最小值,实质上等价于求子图内权重之后的最大值,即公式(2)与公式(3)等价:

4 KCG算法的设计
本文充分研究数据分布特性的度量方法和关联图的划分方法,提出了KCG。该算法首先构建对象集的关联图SG=(V,E,ω),根据下文中公式(4)~(6)计算各对象的关联度,再遍历关联图SG,得到图SG的一个合理划分,选取每个子划分中关联度最高的对象作为该类的初始聚类中心,将子图的数目作为聚类数目k。根据所得的初始聚类中心集和聚类数目k调用Kmeans算法,得到最终的聚类结果。
4.1 关联图的构造
首先将每个数据对象di看做关联图SG的一个顶点νi,任意的两个顶点νi、νj有一条边eij,边上的权重按照公式(4)进行定义。所得的是一个完全图,为了降低计算的复杂度,对完全图作如下处理:对于每个顶点νi,将与其相连的所有边权重的均值作为阈值,即公式(5),删除权重小于阈值的所有边,保留权重大于或等于阈值的边,即公式(6)得到较为稀疏的关联图SG=(V,E)。
定义1设di为n维数据di=(di1,di2,…,din),将边eij的权重weight(eij)定义为:

4.2 关联度的定义和计算
对于4.1节中得到的关联图SG=(V,E),依次定义各顶点对应的对象di的度df(di),关联权重之和sw(di),关联度attachment(di)为公式(7)~(9),这三个指标能够很好地反应对象集的分布特性:关联度越大,表示数据的平均密集程度越高。
定义4第i个对象di的度df(di)为:

定义5第i个对象di的关联权重之和sw(di)为:

4.3 KCG具体描述
输入:数据对象集D
输出:合理的聚类结果
步骤1申请一个空队列Q(用于关联图的遍历),一个空栈S(存储候选聚类中心),初始化聚类数目clusternum=1。
步骤2按照4.1节所述构建关联图SG=(V,E,w),根据公式(7)~(9)计算各对象关联度attachment(di),根据关联度降序排列对象集D,初始时所有对象均未被标记。
步骤3若D中存在数据对象未被标记,则将具有最高关联度的对象d加入队列Q,作上访问标记,同时作为类别clusternum的初始聚类中心加入S中,否则程序执行完毕(即:将当前未被标记的具有最高关联度的数据对象选做类别clusternum的候选聚类中心)。

步骤5利用上述四步得到的初始聚类中心集S和聚类数目clusternum,调用Kmeans算法,便得到合理的聚类结果。
4.4 KCG的几点说明
4.4.1 参数η的选取
η通常取1,得到的聚类数目非常接近数据集的自然数目。很多实际的应用中为了得到不同粒度上的聚类,可以对η进行放缩,如15%、25%等等。
4.4.2 初始聚类中心的选择
KCG中选择新的初始聚类中心至关重要。较高的关联度具有较高的权重之和,因此反映了该对象与相邻对象的密集程度。所以选择一个没有被访问的具有最高关联度的对象作为一个新类的候选聚类中心非常合理。
4.4.3 类的扩充
初始化时每个类仅有一个初始聚类中心。考虑关联图中所有相邻的对象,一个相邻的对象被加入此类当且仅当它和初始聚类中心是最相似的。新加入的对象再执行初始聚类中心相似的操作扩充该类。
4.4.4 有效性分析
良好的初始聚类中心的选择算法保证了子图内权重之和达到最大值,即子图内相似度最大的原则,所得的聚类结果趋于全局最优解。
本文对初始对象集没有作任何假设,第5章中的实验表明在真实的和人工数据集上KCG都能够得到非常好的聚类结果,同时说明算法的有效性。
5 实验设计及结果分析
聚类结果的好坏可以用聚类精度、迭代次数、运行时间和聚类精度的方差四个指标来衡量。本章将传统Kmeans 和KCG在上述四个指标下作了对比实验。
5.1 聚类性能测试
UCI数据库是国际通用的测试数据挖掘算法的标准数据库,每个数据含有一个确定的属性分类,因此方便计算每次聚类的精确度。采用的测试数据是UCI数据库的Iris、Wine、Glass三组数据。
由于传统Kmeans算法对初始聚类中心依赖性较强,因此需要多次运行了解其平均性能。在表1至表3中,Kmeans 与KCG分别取50次运行的结果。图1中,Kmeans与KCG在三种数据集上分别运行50、100、150、200、250、300、350 和400次,取聚类精度的方差。为了增加实验的可比性,本文设定传统Kmeans的聚类参数k与KCG算法中的一致。

表1 Kmeans算法与KCG聚类精度比较
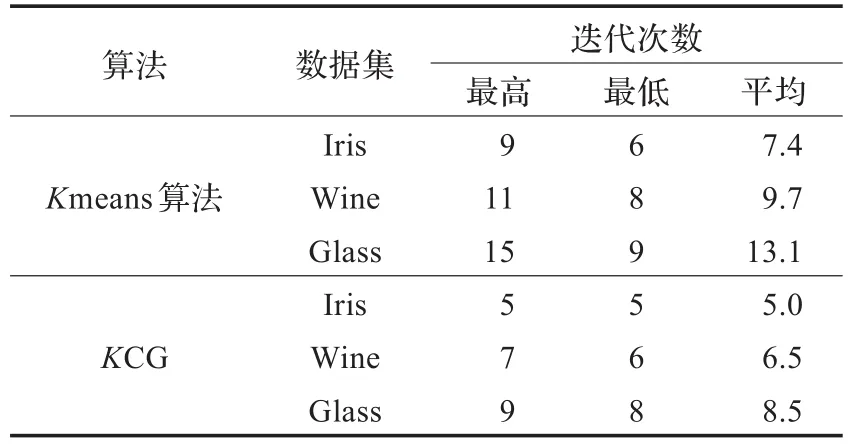
表2 Kmeans算法与本文算法迭代次数比较

表3 Kmeans算法与KCG平均时间比较
聚类精度的计算公式:r=1-er/N,其中N为样本总数,er为错分样本个数。

图1 三种数据集上聚类准确率的方差
由表1可知,在数据集Iris、Wine、Glass上KCG聚类精度超出了传统Kmeans的平均精度的3.54%、2.78%、2.94%,达到了多次运行传统Kmeans算法的最高精度,由此可见KCG在聚类精度上有了较大的提高。由表2可知,与传统Kmeans算法的平均迭代次数相比,KCG分别减少了2.4、3.2、4.6次,优化之后的迭代次数有了较大减少,收敛速度有了较大提高。因此KCG有较高的聚类精度。
由表3可知,KCG的执行时间有了一定的延长。这里主要时间消耗为构建关联图,时间复杂度为O(N2),略大于传统聚类算法的时间复杂度O(Nkt),其中N为数据对象的个数,k是聚类数目,t是迭代次数。而传统的Kmeans算法需要多次运行找到较好的结果,从这个角度来说时间消耗换得性能的提高是很有意义的。

图2 四种人工数据集上的聚类效果图
由图1可知,在不同的数据集上,KCG准确率的方差均较原Kmeans算法小很多,说明KCG算法有较高的稳定性。
5.2 聚类参数k的自动估计
为了验证KCG算法能够在指定的η下自适应确定聚类的数目,本文选取了UCI数据集上的八种数据集分别在η为1、0.8、1.2的实验结果,如表4所示。

表4 KCG算法对聚类参数k的估计
为了能够更直观地考察KCG的性能,选取了四组人工数据集,分别代表四种不同的流行结构,所获得聚类结果如图2所示。
从表4、图2中可以看出,KCG能够自动确定聚类的数目,并且非常符合聚类数据的实际类别。在聚类准确率上图2(a)有所偏离,这说明本文的算法在环绕的流行数据集上的处理效果还不是很好。自适应地确定聚类数目能够给用户带来极大的方便。
6 结束语
Kmeans算法是一种应用非常广泛的聚类算法,但它对初始聚类中心的依赖性较强,容易陷入局部最优解。本文提出的KCG能够从全局角度均衡地选取初始聚类中心,确定聚类数目,增加找到全局最优解的可能。
有效性分析和实验表明,KCG较大地提高了聚类性能。但该算法仍然没有解决Kmeans算法处理非球形数据、流行数据集的聚类效果,如何拓展Kmeans算法的适用范围是下一步要做的工作。
[1]Jain A K.Data clustering:50 years beyond Kmeans[C]//Daelemans W,Goethals B,Morik K.Lecture Notes in Computer Science 5211:ECML/PKDD(1),2008:3-4.
[2]Pollard D.Strong consistency of Kmeans clustering[J].Ailnals of Statistics,1981,9:135-140.
[3]Huang Z.Extensions to the Kmeans algorithm for clustering large data sets with categorical values[J].Data Mining and Knowledge Discover,1998,2.
[4]张文明,吴江,袁小蛟.基于密度和最近邻的K-means文本聚类算法[J].计算机应用,2010,30(7):1933-1934.
[5]Gan Wenyan,Li Deyi.Hierarchical clustering based on kernel density estimation[J].Journal of System Simulation,2004,16 (2):302-309.
[6]杨善林,李永森,胡笑旋,等.K-means算法中的k值优化问题研究[J].系统工程理论与实践,2006(2):97-101.
[7]张健沛,杨悦,杨静,等.基于最优划分的K-Means初始聚类中心选取算法[J].系统仿真学报,2009,21(9):2586-2590.
[8]曹志宇,张忠林,李元韬.快速查找初始聚类中心的Kmeans算法[J].兰州交通大学学报,2009,28(6):15-18.
[9]Mimaroglu S,Erdil E.Combining multiple clusterings using similarity graph[J].Pattern Recognition,2011,44.
LI Zhengbing1,2,LUO Bin1,2,ZHAI Sulan1,3,4,ΤU Zhengzheng1,4
1.School of Computer Science&Τechnology,Anhui University,Hefei 230039,China
2.Anhui Provincial Key Lab for Industrial Image Processing and Analysis,Hefei 230039,China
3.School of Mathematical Sciences,Anhui University,Hefei 230039,China
4.Key Lab of Intelligent Computing and Signal Processing of Ministry of Education,Anhui University,Hefei 230039,China
Kmeans is the most typical clustering algorithm,which is widely used because it is concise,fast.As the traditional Kmeans is sensitive to initial clustering centers and the value of clustering parameter k is difficult to establish,this paper proposes an algorithm based on the partition of correlational graph.Τhe algorithm can select initial clustering centers globally according to the distribution characteristics of the given data;the algorithm can determine the number of cluster automatically according to intensive degree of the given data.Effective experiments show that the algorithm has great accuracy and stability.
Kmeans;relation graph;initial clustering center;similarity matrix
Kmeans是最典型的聚类算法,因其简洁、快速而被广泛使用。针对传统Kmeans算法对初始聚类中心敏感和聚类参数k难以确定的问题,提出了一种基于关联图划分的Kmeans算法。该算法能够有效地根据数据的分布特性选取初始聚类中心,能够在指定的数据密集程度下自适应确定聚类数目。有效性实验表明上述改进的Kmeans算法具有较高的准确率和稳定性。
K均值;关联图;初始聚类中心;相似度矩阵
A
ΤP391
10.3778/j.issn.1002-8331.1202-0314
LI Zhengbing,LUO Bin,ZHAI Sulan,et al.Kmeans algorithm based on partition of correlational graph.Computer Engineering and Applications,2013,49(21):141-144.
国家自然科学基金(No.61073116);安徽省教育厅自然科学研究基金资助重大项目(No.KJ2011ZD10);博硕士队伍建设计划(No.02203105);安徽省高校优秀青年人才基金项目(No.2009SQRZ19ZD)。
李正兵(1988—),男,硕士研究生,主要研究方向:图像处理和模式识别;罗斌,教授,博导,主要研究方向:图像处理与模式识别;翟素兰,副教授,硕导。E-mail:lizhengbing870427@163.com
2012-02-20
2012-04-09
1002-8331(2013)21-0141-04
CNKI出版日期:2012-06-15http://www.cnki.net/kcms/detail/11.2127.ΤP.20120615.1726.025.html
