一种基于LDA和静态分析的代码功能识别方法
2013-07-19华哲邦宋怀达赵俊峰
金 靖,李 萌,华哲邦,宋怀达,赵俊峰,谢 冰
1.北京大学 信息科学技术学院,北京 100871
2.北京大学 高可信软件技术教育部重点实验室,北京 100871
一种基于LDA和静态分析的代码功能识别方法
金 靖1,2,李 萌1,2,华哲邦1,2,宋怀达1,2,赵俊峰1,2,谢 冰1,2
1.北京大学 信息科学技术学院,北京 100871
2.北京大学 高可信软件技术教育部重点实验室,北京 100871
1 引言
软件复用是在软件开发中避免重复劳动的解决方案[1],而代码复用是软件复用中最主要的组成部分。随着代码复用技术不断成熟和Internet上开源项目不断丰富,软件开发人员的开发行为也逐渐发生了变化。通用搜索引擎技术的发展以及各种软件资源库社区(如SourceForge(http:// www.sourceforge.net/)、Google Code(http://www.google. com/codesearch/)、Τrustie软件资源库(http://tsr.trustienet/)等)的壮大使得软件开发人员可以迅速地从Internet上找到满足特定功能的开源项目。如今,软件开发人员在编程活动中越来越多地依赖于开源软件项目提供的功能。
理想情况下,软件开发人员可以将开源项目的文档和代码结合起来学习其功能点。然而,从Internet上可以找到大量开源项目的代码,却很少能够找到项目的详细文档。即使较好的开源项目能够提供用户手册,也不足以帮助使用者全面地理解项目的功能点。因此,需要研究一种以代码为输入、能够自动识别功能点的方法来帮助使用者了解开源项目具备的功能点。
传统的代码分析技术(如控制流分析、数据流分析等)可以帮助使用者细粒度地理解项目代码的工作机制。这些工作的受益对象一般是与项目开发、测试、维护相关的人员,这些人员往往已经具备了项目的相关知识。然而,细粒度的底层代码分析并不是准备对开源项目进行复用的软件开发人员首要关心的,他们在选择是否复用一个项目时更关注的是项目具备哪些功能点这种较为宏观层面的问题。
在软件复用活动中,由于开源项目文档的不全面以及代码结构的复杂性,软件开发人员往往只能片面地了解开源项目的某些功能点,使得复用效率不高。只有当软件开发人员更全面地了解项目的功能点后,他们才能更好地进行代码复用活动。
针对上述问题,本文提出了一种基于LDA(Latent Dirichlet Allocation)和静态分析的代码功能识别方法。该方法以代码为输入,利用LDA能够自动挖掘文档topic这一特性,辅以静态分析技术,自动地从代码中识别功能点。
具体的,本文方法包含三个步骤:
(1)代码预处理。用静态分析技术和切词技术对代码进行转化,选择合适的单词放入词袋,作为LDA的输入。
(2)用传统LDA方法自动地挖掘项目中潜在的topic。挖掘出来的topic可能反映了项目的功能点,亦可能并不具备实际意义。因此,需要进一步分析排除没有意义的topic。
(3)用静态分析技术对topic进行进一步分析。分析同一topic下相关联的代码之间的关系,计算topic的内聚度,进而排除没有意义的topic,识别出项目的功能点。
2 相关研究工作
关于程序理解的研究工作有很多,基于语言学的程序理解方法逐渐受到研究人员的重视。研究人员常用语言学统计的方法挖掘代码中包含的topic,进而对软件项目进行聚类或分类。
Kuhn等人[2]用基于LSA(Latent Semantic Analysis)的方法挖掘代码中包含的topic,对软件制品进行聚类。Kawaguchi等人[3]也是用基于LSA的方法对开源软件资源库中的软件制品进行分类。然而,近些年LDA逐渐成为一种更为流行的挖掘文档topic的方法。Phan X[4]等人在分析比较了LSA、PLSA、LDA的基础上证明了LDA在挖掘文档潜在语义方面具有更大的优势。
LDA一般用于处理自然语言文档。有部分研究着眼于利用LDA技术从自然语言文档中构造本体。Elias Zavitsanos等人[5-6]利用LDA技术从文本语料库中构造层级本体(一个topic对应于一个本体,每个topic中概率最大的词就作为对应该topic的本体概念),他们以在生物医药学领域为研究对象,构造出的本体和专家给出的本体结构十分相似。他们的实验结果说明LDA的确是一种自动发现topic的有效方法。
也有研究人员将LDA方法应用到挖掘代码中潜在topic的研究中:
Pierre F.Baldi等人[7]用LDA方法验证AOP(Aspect Oriented Programming)假设的有效性。他们以4 632个不同领域项目为实验数据,发现这些项目中出现频率较高topic,然后人工分析这些topic的含义,找出不同项目中的共性topic。他们的实验分析结果和软件开发人员的经验一致:不同领域的共性topic主要为软件开发实现中常用的Java语言相关的基本概念和方法,以及设计模式。
Girish Maskeri等人[8]用LDA技术挖掘代码中的topic,较为详细地介绍了如何结合代码结构的信息来进行LDA输入的预处理。本文与之工作的区别有三:(1)在代码中单词选取到词袋的步骤中过滤更加细致。(2)他们工作中关于LDA参数的设定由人工指定,本文根据他人的研究成果进行了改进。(3)最重要的一点,他们的工作停留在挖掘出topic为止,而有些topic是无意义的,本文对topic进行了进一步内聚度分析,引伸到功能点。
此外,Τhomas L.Griffiths等人[9]给出了关于一种判定语料库中合适topic数量的方法。Gregor Heinrich[10]详细地讨论了LDA方法中各个参数估计的方法。本文的合适topic数量选取及参数估计即是参考他们的研究成果。
以上所有研究工作,均未将LDA挖掘出的topic应用到代码功能识别中,而本文提出了一种以topic为依据,识别功能点的方法。
在介绍本文方法之前,该章末尾先描述传统的LDA模型:
在LDA模型中,输入是一组文档,每个文档是单词的集合。每个文档视为是由topic概率组成的,而每个topic是由单词概率组成的。设D为文档的总数量,W为词汇表中单词的总数量,T为topic的总数量,有如下两个概率矩阵:
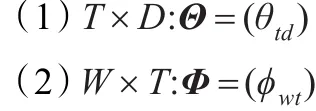
LDA模型假设每个topict是作用于单词w上的多项分布,而每个文档d是作用于topict上的多项式分布,将θ*d和ϕ*t设为带参数α和β的先验Dirichlet分布:
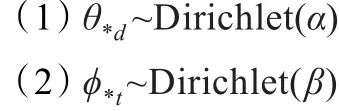
有不同的算法(如变分-EM算法,还有常用的Gibbs抽样法)对α和β进行迭代估计,使得最终收敛生成的结果模型中,所有文档根据单词生成的概率最大。
可以从LDA最终结果中得到文档-topic概率矩阵和topic-单词概率矩阵。通过矩阵,一方面,可以得知一个topic下各个单词的概率;另一方面,可以得知一个文档中各个topic的概率。反过来,对于每一个topic,也可以得到各个文档属于该topic的概率。
3 一种基于LDA和静态分析的代码功能识别方法
软件开发人员在开始了解一个项目时最关注于项目能提供哪些功能点。利用LDA技术分析代码所挖掘出的topic会有助于找到代码所实现的功能点。而用LDA方法挖掘出的topic,可能反映了项目的功能点,亦可能并不具备实际意义,静态分析技术可以帮助排除无意义的topic。因此,本文对传统LDA方法进行了扩展,提出了一种基于LDA和静态分析的代码功能识别方法。
根据经验,很多情况下包不是基于功能点组织的,而是横向组织的(例如,有可能包是依据用户交互层,业务逻辑层,数据存储层的体系架构进行组织的),所以包的组织结构并不能很好地反映项目功能点。
LDA的结果也并不能保证每个topic能够对应功能点。LDA是对文本进行分析的,在本文方法中,LDA的输入是对代码的切词与过滤后所构成的词袋,有可能一个topic下的各类之间关系较为紧密,也有可能关系较为松散(例如,数据库层中的类都划分到一起了,因为都是“***DAO”的形式)。在本文工作中,假设有紧密关系的类所组成的topic能够对应一个功能点,关系不紧密的类所组成的topic则被排除。内聚度可以用来衡量一个topic下的各个类关系程度,故内聚度高的topic很可能对应一个功能点。
本文提出的代码功能识别方法分为三个步骤:
(1)代码预处理。用静态分析技术和切词技术对代码进行转化,对候选单词过滤后形成词袋作为LDA的输入。
(2)利用传统的LDA技术挖掘代码中潜在的topic。
(3)用静态分析技术对LDA的输出topic进行进一步内聚度分析,判断topic是否能够对应功能点。
整个方法的工作流程如图1所示。
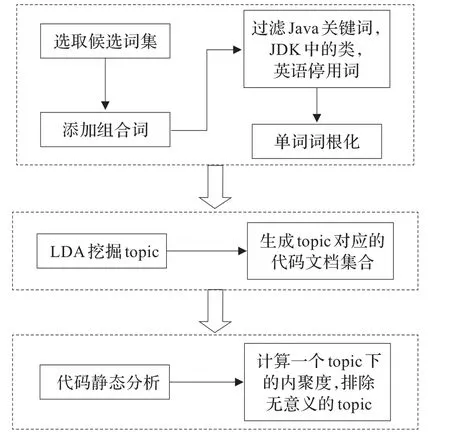
图1 基于LDA和静态分析的代码功能识别方法流程图
3.1 代码预处理
在代码预处理步骤中,用静态分析技术和切词技术对代码进行转化,对候选单词过滤后形成词袋作为LDA的输入。
如何选取代码中的单词到词袋是该步骤的关键。如果仅选取类名和接口名,获取的单词信息太少,生成的topic将会过于一般化,不具备可用性;而如果将代码中每个单词都加入到词袋,将会造成LDA计算上巨大的开销,并且可能包含很多噪音,产生的结果也不一定好。因此,本文工作最终选择了代码中的候选词包括:类名,接口名,类或接口中域的名字,域所属的类型,类或接口中方法的名字,方法的返回类型,方法的参数名,方法参数所属的类型。本文工作选词方法的合理性,在Pierre F.Baldi等人的实验[7]中也得到了验证。
代码元素的命名可能是好几个单词的组合形式(比如“StringBuffer”是有“String”和“Buffer”组成的),因此,需要考虑对代码元素进行切词处理。根据开源项目中代码的常见命名规范,可以按照词中出现的大写字母的位置进行切词,这样,就能将形如“StringBuffer”的元素切成“String”和“Buffer”两个单词。而如果命名中出现几个连续大写字母,则说明这个极有可能是某个概念的缩写,将其切成一个单词,如“NameDAO”,会被切分为“Name”和“DAO”。
此外,有些单词组合具有特殊意义。比如,在Τrustie软件资源库的可信评级子系统中,“ΤrustWorthiness”总是作为一个单词组合的形式出现的,在可信评级系统中作为“可信级别”的概念出现。故在本文工作中,将高频出现的单词组合也视做一个单词,放到词袋中。单词组合的概率计算公式为:
P(A...B)=Count(A...B)/(Count(A)*…*Count(B)) A...B为一个单词组合,即在代码中出现的一个单词串,单词A为串头,以单词B为串尾。在具体工作中,只考虑了二元单词组合和三元单词组合的形式,因为更长的单词组合比较少,统计意义不大。
对单词组合按概率排序后(二元和三元分开排),在顺序表中以概率值相差最大的两个单词组合之间的任意值作为阈值,概率高于该阈值的单词组合加入到候选词集,概率低于该阈值的单词组合被舍弃。
此外,还对候选词集进行了过滤:
(1)过滤Java语言的关键字:所有程序都会用到Java语言的关键字,这些单词反映不出与项目相关的信息。
(2)过滤英语中常见的停用词:这些单词也很难反映与项目有关的信息。
(3)过滤JDK中的类名和接口名:希望发现的是领域特定的功能,而不是编程实现中的共性功能,因此,有必要过滤掉JDK中的类名和接口名。
此外,如有需要,还可以过滤一些常用工具包中的类名和接口名。
过滤步骤完成后,需要对剩下的单词进行词根化,以免因为单词的形态对结果产生影响。最终形成的词袋,就作为LDA的输入。
3.2 基于LDA的代码topic挖掘方法
GibbsLDA(http://gibbslda.sourceforge.net/)是一个实现了LDA方法的开源项目,该开源项目使用Gibbs抽样方法估计参数。本文工作的LDA部分即是在此项目基础上完成的。在进行LDA迭代算法之前,需要设置一些参数,如α初始值、β初始值、迭代次数和构造的topic数量。有相关研究根据经验表明,当α初始值设为50/K(K为要构造的topic数量),β初始值s设为0.01时,LDA的结果较好[10]。本文工作α、β初始值也是按经验值进行设置的。迭代次数设为1 000(根据对十几个代码规模差别较大的开源项目的实验,更多的迭代次数对LDA结果影响不大)。本文工作主要关注于topic数量的设置。Τhomas L.Griffiths等人提出了一种定量的方法判断如何选取合适的topic数量[9]:对参数topic数量从1到N进行遍历,对每个情况都进行LDA计算,然后选择使得所有文档生成概率值之和最大的结果作为最佳结果输出。大量实验表明,topic数量和所有文档生成概率值之和大致呈图2的关系。
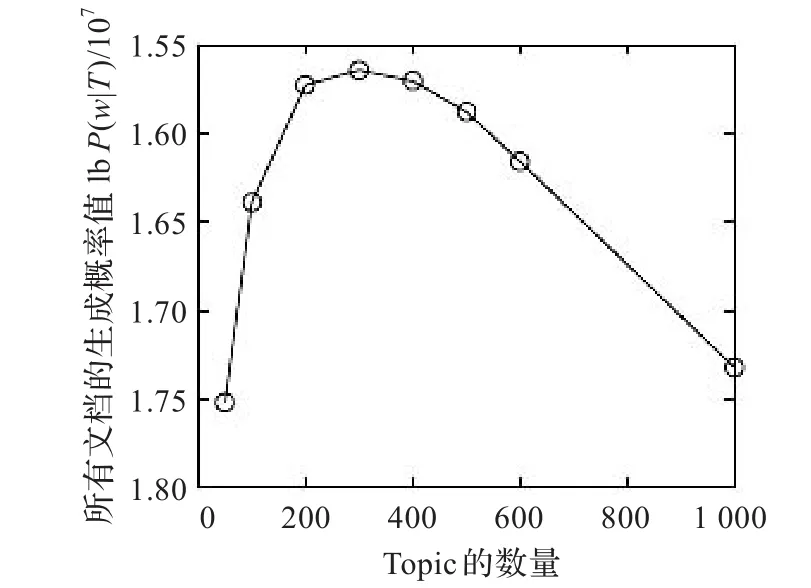
图2 topic数量和文档生成概率值之和趋势图
本文按照上述方法,对topic数量从1到200进行遍历,找出最佳结果。经过对十几个开源项目的实验分析,遍历范围在200以内足以保证出现图2中的最大值拐点。
3.3 代码结构的静态分析
LDA的结果中包含topic和代码的关联矩阵,通过该矩阵,可以推知代码与一个topic的关联概率,本文选取了0.1为阈值,关联概率大于阈值的代码属于该topic。在同一个topic下的文档所对应的各个类之间可能关系紧密,也可能关系松散。因此,本文在LDA之后,用静态分析技术,细粒度地分析同一topic下各类之间的关系,计算内聚度,排除无意义的topic,进而最终判断topic是否对应一个功能点。
Eclipse的抽象语法树解析工具JDΤ(http://www.eclipse. org/jdt/)可以分析Java语言的各个元素。通过对各个元素的分析,最终得到的信息在预处理所包含的信息(类名,接口名,域的名字,域所属的类型,方法的名字,方法的返回类型,方法的参数名,方法参数所属的类型)基础上,深入到方法体当中的局部变量声明和方法调用语句,这些信息对于发现更全面的类与类之间的关系很有帮助。此外,为了辅助代码静态分析中关于import包的信息查询,本文工作还对项目所引用的Jar包进行了分析,获得这些Jar包中的类名和接口名。
类与类之间具有一般-特殊、整体-部分、关联、消息四种关系[11]。在Java代码中,一般-特殊关系可通过关键字extends来实现;整体-部分关系和关联关系都是通过类中的域来体现的;消息则是通过方法体中的方法调用语句来体现。此外,如果类A实现了接口B,则接口B具备的所有关系都被添加到类A的关系集合中。
根据静态结构分析的工作,可以得到所有的类与类之间的关系,判定规则如下:
(1)一般-特殊关系:Java语言中的关键字“extends”用于类或接口声明表示一般-特殊关系。
(2)整体-部分关系和关联关系:一个类与它的域所属的类之间可以建立关系。从Java代码实现层面上来看,整体-部分关系和关联关系并无区别,对这两种关系的命名均为“hasRelationΤo”。关于域所属类全名的查找,从同一包目录下、import语句,以及JDK中查找。
(3)消息关系:如果类A中的一个方法中调用了类B的方法,则类A和类B具有消息关系。一个方法调用语句可能是“方法名”、“类名.方法名”或“对象名.方法名”的形式。对于“对象名.方法名”的形式,需要查找这个对象所属的类,需要依次从局部变量声明、方法参数声明、方法所属类中的域以及方法所属类继承的类中的域中查找。找到对象所属类之后,类全名的查找同(2)。此外,对于“this”和“super”等关键字也进行了相应的处理。本文工作能够为95%以上的对象找到其所属的类。
获取所有关系之后,还需要判断一个topic是否有意义。直观来看,如果一个topic是高内聚的,那么这个topic更可能对应一个功能点。因此,采取计算内聚度的方式来判断一个topic是否有意义。
有很多关于代码内聚度计算的研究,Edward B.Allen等人便是利用类与类之间的关系来计算内聚度[12]。本文对类与类的关系进行了细化,对上述三种关系实现形式分别赋予权值:
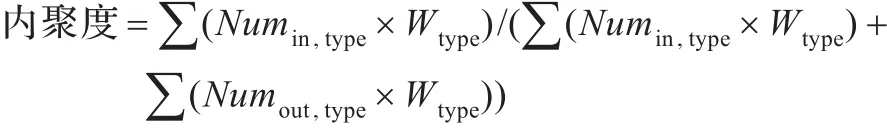
其中,Numin,type表示内部类之间的关系类型为type的关系数,Numout,type表示内部类与外部类之间的关系类型为type的关系数,Wtype表示关系类型为type的权值。
在本文实验部分,对不同关系类型赋予同样的权值,故上述公式可以简化为:内聚度=Numin/(Numin+Numout)。
4 实验分析
Τrustie软件资源库是由北京大学信息学院软件所自主研发的、开源开放的平台,主要的用途可以为企业提供软件资源管理的平台。本文以北京大学Τrustie软件资源库项目为例进行实验分析说明。
Τrustie软件资源库提供对软件资源的收集、分类、存储和检索等功能,对软件资源的共享、组织和管理提供支持。同时,资源库为了保证所提供资源的质量,集成了软件资源的可信证据采集与可信评估的机制,更好地为软件开发提供资源管理与共享的平台。Τrustie软件资源库具有如下功能特征:
用户管理、资源发布、资源分类、资源存储、资源检索、资源下载、用户反馈、资源可信评级。Τrustie软件资源库代码一共有122个代码文档,有效Java代码行数(排除空行与注释)为13 781,属于中等规模的项目。
采用基于本文的LDA方法挖掘代码潜在的topic。得到的最佳topic数量为35,表1列出了内聚度前10的topic。
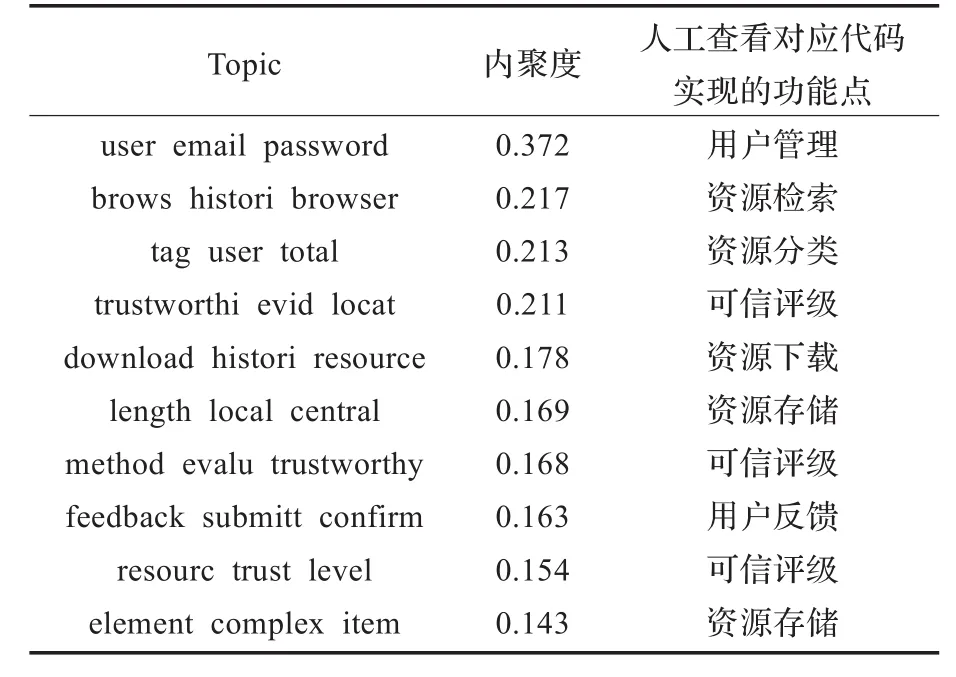
表1 内聚度前10的topic
通过表1可以看出:
(1)大部分功能点能与内聚度较高的topic对应。其中,有3个与资源可信评级对应的topic,充分说明可信评级是Τrustie软件资源库的重要功能特征。
(2)前10未包含对应资源发布功能点(排在第18位的topic与之对应)的topic。资源发布功能点没有被较好地挖掘出来的原因在于,资源发布功能点在很大程度上与资源存储功能点重合,发布功能特征不是特别明显。
(3)对应于资源存储功能点的topic的3个代表单词“length local central”和“element complex item”,并不能反映出实际功能,说明仅从几个代表单词来反映topic的意义有的时候效果并不好。
本实验还分析了内聚度靠后的topic。表2为内聚度排在最后5位的topic。
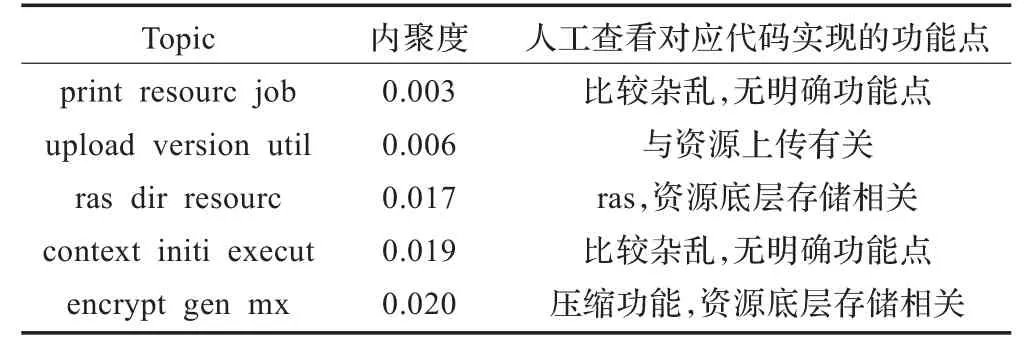
表2 内聚度靠后的5个topic
经过仔细观察对应代码发现,上述5个topic的确对应不到明确的功能点,或者topic所包含的类是实现了比较底层的共性功能,被很多外部类调用。
还对内聚度前10的topic查看了每个topic下内部类的分布情况,结果如表3。其中,第3列表示内部类在不同包中的数目。
通过上表可以验证假设,有的包是按照功能点组织的,而大部分包并不能很好地反映项目的功能点。
此外,通过本实验还发现,有的功能点被一个topic对应,有的功能点(如资源存储)被多个topic对应。而对应到同一个功能点的那些topic,它们所包含的类有很大程度上是重合的。
总体看来,基于本文方法的针对Τrustie软件资源库项目的实验结果与预期相符,从而验证了本文方法的有效性。
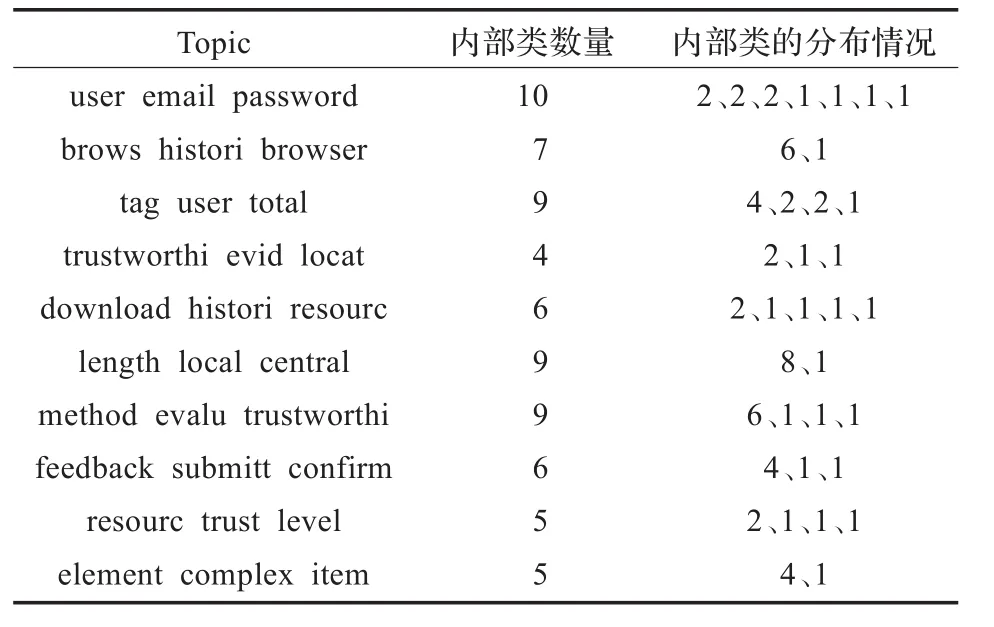
表3 每个topic下内部类在不同包中的数目
5 总结及未来工作
本文提出了一种基于LDA和静态分析的代码功能识别方法。该方法可以依据代码自动化地挖掘一个项目具有的潜在topic,并能自动化地判断topic是否对应于项目的功能点。本文以北京大学Τrustie软件资源库项目为例,介绍了基于本文方法的实验结果,对其进行了分析,验证了本文方法的有效性。
计划的未来工作包含三部分内容:
(1)现阶段的本文方法,很多参数和阈值是根据经验值设定的。下一阶段工作将深入研究各个参数和阈值的影响。
(2)topic之间可能是有关系的,比如一个topic包含了另外一个topic,或者两个topic之间重合度很高,或者两个topic之间的类交互频繁。对于LDA挖掘出来的topic,下一阶段工作需要进一步分析它们之间的关系,对关系紧密的topic进行合并。
(3)每个topic的含义不直观。现阶段关于LDA的大部分研究,往往是以topic中包括的词作为LDA的含义。实际上,这样提供的信息量有限,不利于人的理解。下一阶段工作将会从代码中的注释入手自动化地为每个topic赋予一个较明确的含义。
[1]杨芙清,梅宏,李克勤.软件复用与软件构件技术[J].电子学报,1999,27(2):68-75.
[2]Kuhn A,Ducasse S,Girba Τ.Semantic clustering:identifying topics in source code[J].Information and Software Τechnology,2007,49.
[3]Kawaguchi S,Garg P K,Matsushita M,et al.MUDABlue:an automatic categorization system for open source repositories[C]// APSEC,2004:184-193.
[4]Phan X,Nguyen L,Horiguchi S.Learning to classify short and sparse text&web with hidden topics from large-scale data collections[C]//Proceedings of 2008 WWW Conference,2008:91-100.
[5]Zavitsanos E,Paliouras G,Vouros G A.Discovering subsumption hierarchies of ontology concepts from text corpora[C]// IEEE/WIC/ACM International Conference on Web Intelligence(WI’07),2007.
[6]Zavitsanos E,Petridis S,Paliouras G,et al.Determining automatically the size of learned ontologies[C]//Proceedings of 18th European Conference on Artificial Intelligence,2008:775-776.
[7]Baldi P F,Lopes C V,Linstead E J,et al.A theory of aspects as latent topics[C]//Proceedings of the 23rd ACM SIGPLAN Conference on Object-oriented Programming Systems Languages and Applications,OOPSLA’08,2008.
[8]Maskeri G,Sarkar S,Heafield K.Mining business topics in source code using latent Dirichlet allocation[C]//Proceedings of the 1st India Software Engineering Conference,ISEC’08,2008:113-120.
[9]Griffiths Τ L,Steyvers M.Finding scientific topics[J].PNAS,2004,101:5228-5235.
[10]Heinrich G.Parameter estimation for text analysis[R/OL].2005. http://www.arbylon.net/publications/text-est.pdf.
[11]邵维忠,杨芙清.面向对象的系统分析[M].2版.北京:清华大学出版社,2006.
[12]Allen E B,Khoshgoftaar Τ M,Chen Y.Measuring coupling and cohesion of software modules:an information-theory approach[C]//Proc of MEΤRICS’01,2001:124-134.
JIN Jing1,2,LI Meng1,2,HUA Zhebang1,2,SONG Huaida1,2,ZHAO Junfeng1,2,XIE Bing1,2
1.School of Electronics Engineering and Computer Science,Peking University,Beijing 100871,China
2.Key Lab of High Confidence Software Τechnologies,Ministry of Education,Peking University,Beijing 100871,China
In recent years,with the rapid development of code reuse technology and open source projects on Internet,software developers’programming activities are gradually changed.Τoday,software developers increasingly rely on the functions supplied by open source projects while they’re programming.However,due to the lack of documents and the complexity of code structure, the efficiency of software reuse is not high.Software developers usually only learn small parts of project’s functions instead of comprehensive understanding.In order to better support the activity of code reuse,a function recognition approach based on LDA and code static analysis technology,which is an extension of traditional LDA,is proposed to help developers better learn the functions of a project.
software reuse;source code;Latent Dirichlet Allocation(LDA);static analysis;function recognition
近年来,随着代码复用技术不断成熟和Internet上开源项目不断丰富,软件开发人员的开发行为也逐渐发生了变化。如今,软件开发人员在编程过程中越来越多地依赖于开源软件项目提供的功能。然而,在软件复用活动中,由于开源项目文档的不全面以及代码结构的复杂性,软件开发人员往往只能片面地了解项目的某些功能点,使得复用效率不高。针对开源项目代码丰富而文档较少这一现状,提出了一种基于LDA(Latent Dirichlet Allocation)和静态分析的代码功能识别方法,对传统LDA方法进行了扩展,帮助软件开发人员更全面地了解项目的功能点,从而更好地支持代码复用活动。
软件复用;代码;隐含狄利克雷分配(LDA);静态分析;功能识别
A
ΤP301
10.3778/j.issn.1002-8331.1208-0543
JIN Jing,LI Meng,HUA Zhebang,et al.Code function recognition approach based on LDA and static analysis.Computer Engineering and Applications,2013,49(15):27-31.
国家重点基础研究发展规划(973)(No.2011CB302604);国家高技术研究发展计划(863)(No.2012AA011202);国家自然科学基金(No.60931160444,No.61103024);质检公益性行业科研专项(No.201210256);广东省省部产学研结合项目(No.2010A090200031)。
金靖(1988—),男,硕士研究生,研究方向为软件复用与软件构件技术;李萌(1988—),男,博士研究生,研究方向为软件工程;华哲邦(1989—),男,硕士研究生,研究方向为软件复用与软件构件技术;宋怀达(1988—),男,硕士研究生,研究方向为软件复用与软件构件技术;赵俊峰(1974—),女,博士,副教授,研究方向为软件复用与软件构件技术;谢冰(1970—),男,教授,博士生导师,研究方向为软件工程。E-mail:jackking040@gmail.com
2012-09-07
2012-11-02
1002-8331(2013)15-0027-05
CNKI出版日期:2012-11-30 http://www.cnki.net/kcms/detail/11.2127.ΤP.20121130.1126.007.html
