Web 气象信息树型提取算法与LED 显示设计
2013-07-19彭伟
彭 伟
(武汉城市职业学院 电子信息工程学院,湖北 武汉430064)
0 引 言
互联网Web 页数据信息挖掘是一项非常重要且具有大量现实应用的技术,特别是基于HTML 的Web页已经成为绝大多数程序的人机界面,从Web 页挖掘数据已经成为最重要的信息获取方式之一。对于目前为数众多的互联网地址免费发布的城市气象信息,它们均具有相对稳定的URL 地址,但其Web 页数据信息却表现为无结构或半结构状态[1],对于气象信息的提取可以面向顺序文本通过正则表达式实现,这种方式速度快,但容易产生噪声信息。本文将基于. NET开发平台,研究通过Microsoft mshtml DOM 接口[2-3]递归提取互联网免费发布的气象信息程序算法,并给出通过取模及挂载第三方EXE 的方式将提取的气象信息发布于LED 电子屏显示的相关技术。
1 Microsoft mshtml DOM 接口简介
1.1 W3C DOM 程序设计接口
W3C 制定的文档对象模型(Document Object Module,DOM)是一种独立于平台和具体编程语言的接口,它允许通过程序或脚本动态访问及更新HTML、XHTML、XML 文档对象,包括其内容、结构和样式。DOM 把Web 文档组织成DOM 树结构[4-5],其定义为:DOMTree= (Node,Relation);Node = (Node1,Node2,…,Noden),Nodei = (Name,Attribute,Semantics,Index),Relation 为 Node 之 间 的 关 系(Parent,Child,Sibling)。DOM 树的根结点只有一个,由Document 接口管理,每个加载到浏览器的HTML 文档都会成为Document 对象。DOM 树中的各结点对象均可被寻址和操纵。DOM 规范在Node 接口中定义了12 种不同的结点类型,操作HTML 文档的几个重要结点类型如表1 所示。

表1 DOM 结点类型(部分)
1.2 Microsoft mshtml 提供的DOM 接口
为访问Microsoft mshtml 所提供的接口功能,.NET封 装 了 HtmlDocument、HtmlElementColletcion 及HtmlElement 等类,但这些封装仅提供了DOM 的部分功能且并不完善。本节将通过mshtml 接口实现对Web 页结点的访问,在.NET 平台使用mshtml DOM 接口时需要添加引用Microsoft. mshtml,并添加using mshtml 语句,所引用的文件Microsoft. mshtml. dll 处于.NET 安装目录下。表2 给出了mshtml DOM 开发涉及的相关接口。

表2 Microsoft mshtml DOM 开发涉及的相关接口
2 基于mshtml DOM 接口气象信息提取算法
2.1 气象信息Web 页数据结构分析
为解析以HTML 方式提供的气象信息Web 页,现以URL:http://weather. news. qq. com/inc/07_dc125.htm 为例进行分析研究,它是腾讯公司发布的北京市气象信息地址,可以实时查看北京当天的详细气象信息及近3 天的气象预报信息。在C#.NET 开发平台设计模式及源模式下打开该Web 页面的效果及经过逐层剖析HTML 标记所构造的树型结构如图1 所示,其中树型结构以<html >为根结点(更顶层为Document结点),所有气象信息均驻留在树中由根结点到各叶子结点的各条路径上最末端的<td >标记内及<td >之下的<strong >、<a >等标记内,部分信息内有<br>标记,另外还有部分<td >标记内容为空。考察图1所示Web 页树型标记结构,并参考DOM 树与结点定义可知,提取该Web 页数据信息的过程就是通过DOM 提供的接口提取树中相应结点文本信息的过程[6-9]。
2.2 Web 页Document 文档对象的创建
基于DOM 接口提取Web 页数据信息时,需要从顶级根结点(即文档对象)开始,为了获取mshtml.HtmlDocument 顶级文档对象以便进行编程访问,可通过WebBrowser 实例(本文定义为tmpIE1)加载Web 页然后获取文档对象,其创建及载入URL 的语句如下:
string URL = @“http://weather... /inc/07_dc125.htm”;
WebBrowser tmpIE1 = new WebBrowser();
tmpIE1.Navigate(URL);
执行Navigate 以后并不能立即从加载的HTML 文档提取数据,因为此时尚不能保证整个文档已被完整加载。对此可有如下两种方法进行处理:
(1)循环查看tmpIE1 的就绪状态,未就绪则等待:
while (tmpIE1. ReadyState ! = WebBrowserReadyState.Complete)Application.DoEvents();
(2)为tmpIE1 的DocumentCompleted 事件添加委托:
tmpIE1.DocumentCompleted + =
new WebBrowserDocumentCompletedEventHandler(
tmpIE1_DocumentCompleted);
文档完整载入后所执行的程序如下:
HTMLDocument mhtd = (HTMLDocument)
(tmpIE1.Document.DomDocument);
if (mhtd != null){/* 调用下一节讨论的递归算法* /
/* Domx1((IHTMLDOMNode)mhtd.firstChild);* /
/* Domx2 ((IHTMLElementCollection ) mhtd. body.children);* /
/* 输出气象信息文本str* / }
上述代码可放在方法(1)所示代码之后,也可放在方法(2 )所定义的委托内。注意其中HTMLDocument 所表示的是mshtml. HTMLDocument。此 外,文 档 对 象 还 可 以 通 过 mshtml.HTMLDocumentClass类 及IHTMLDocument2、IHTMLDocument4 接口创建。
2.3 全文信息提取算法
DOM 所定义的结点不仅包含所有的HTML 标记,对于其中的文本内容,DOM 也将其单独定义为Text 结点类型,观察图1 可知该Web 页的所有气象信息文本正 好 全 部 处 于 Text 结 点 内。显 然,通 过IHTMLDOMNode 结点接口提供的编程能力,特别是其重要属性firstChild 及nextSilbling,使用递归即可实现对整个树的先序遍历,遍历过程中每当遇到nodeType属性值为3(即TEXT_NODE)的Text 结点时即取得其结点值(nodeValue),递归结束时即可取得全文信息。下面给出的递归算法Domx1 基于DOM 树结点接口实现对全文信息的提取:
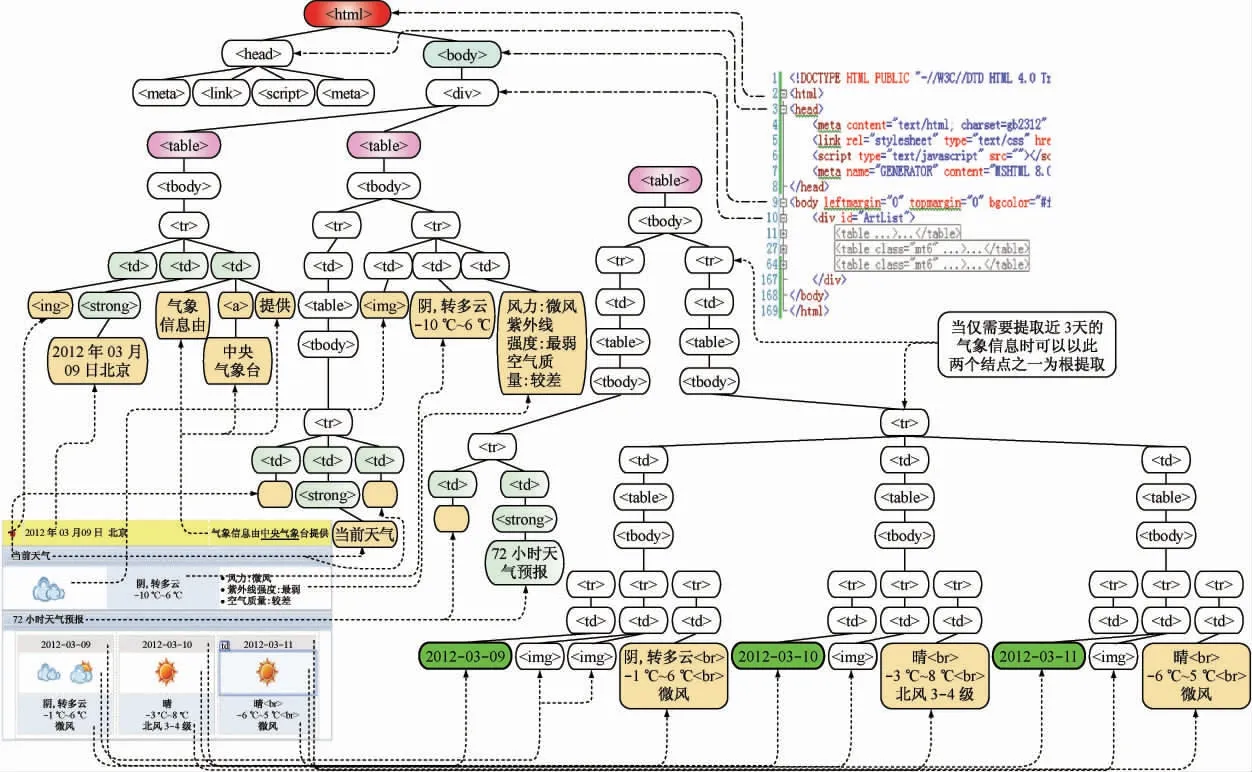
图1 气象信息Web 页HTML 树型标记结构图
void Domx1(IHTMLDOMNode Node){
if (Node != null){
if (Node.nodeType = = 3)//为Text 结点
str.Append(Node.nodeValue.ToString());
Domx1(Node.firstChild);//遍历子树结点
Domx1(Node.nextSibling);//遍历兄弟结点
}}
其中str 用于保存提取的气象信息文本:
StringBuilder str = new StringBuilder();
点击Web 气象信息树型提取算法测试界面图中的“全文提取(1)”时可观察到Domx1 的提取效果,递归共遍历124 个树结点(注意图1 未绘制出<br >,<!--注释-->等结点),限于篇幅,本文略去树型视图构建代码及HTML 标记显示代码。
为提取图1 中的气象信息,还可以基于IHtmlElement 及IHtmlElementCollection(元素接口及元素集合接口)实现。虽然所有气象信息均处于图1 中的<td >元素结点之下,但遍历过程中并不能在每次遇到<td >元素时即通过innerText 提取它所包含的文本,因为结点树中多个<td >元素存在嵌套,其下有<table >及更底层的<td >等元素,在递归遍历过程中,只能提取最底层<td >元素的innerText 属性值。为解决这一问题,算法中引入了全局元素变量msLtd,其定义为HTMLElement msLtd = null,用于保存最近<td>结点。以下给出的Domx2 算法基于DOM 树元素及元素集合接口实现全文信息提取:
void Domx2(IHTMLElementCollection Elems){
foreach (IHTMLElement elem in Elems){
if (elem.tagName.ToUpper()= =“TD”)msLtd=elem;
/* 递归遍历当前元素elem 的所有孩子元素* /
Domx2((IHTMLElementCollection)elem.children);
if (elem.tagName.ToUpper()= =“TD”&&
msLtd = = elem){str.Append(elem.innerText+“”);
msLtd = null;}}
DOM 元素结点的innerText 属性功能非常强大,图1 中<body >元素下子树中的所有文本信息还可以仅仅使用str. Append(mhtd. body. innerText)一次性提取,然而,实际上很多时候所需要的并不是全文信息,而是仅仅需要其中局部板块的有效信息。
2.4 局部信息提取算法
如果Web 页所有内容全部与气象信息相关,且全部需要提取,上述全文提取算法就能满足要求,但实际应用中遇到的Web 页往往含有大量无关信息,对此还需要进一步重新设计实现局部信息的提取算法,下面分别针对较为简单的及相对复杂的页面进行讨论:
(1)从结构及内容相对简单的页面提取。仍以腾讯公司的07_dc125.htm 页面为例,现假设仅需提取近3 天的气象信息,考察图1 树型结构可知,在递归遍历过程中遇到Text 结点且nodeValue 为当天日期时,逐一提取当前及此后遇到的所有Text 结点值,如此即可得到近3 天的气象信息,类似的,还可以通过IHTMLDOMNode 结点接口的lastChild 属性通过循环定位于右子树的第1 个(或第2 个)<tr >结点,然后以之为根调用递归算法Domx1。以后者为例,其具体实现如下:
IHTMLDOMNode Node = mhtd.lastChild;
while (Node != null){if (Node.nodeName.ToUpper()
= =“TR”)break;else Node = Node.lastChild;}
Domx1(Node);//以<tr >为根调用Domx1
/* 递归结束后输出近3 天的气象信息文本* /
此外还可选择使用元素接口IHTMLElement 首先定位于树型结构最右端的<tr >元素,然后通过innerText 一次提取近三天的气象信息,其具体实现如下:
IHTMLElement le = null;//当前层最右元素结点
while (Elems.length != 0){//循环搜索最右的<tr >
foreach (IHTMLElement elem in Elems)le = elem;
if (le.tagName.ToUpper()= =“TR”)break;
Elems = (IHTMLElementCollection)le.children;}
if (le != null)/* 由le.innerText 获取所需要信息* /;
(2)从结构复杂且含有大量无关内容的页面提取。以从中国天气网提供的北京市气象信息页中提取指定的局部板块气象信息为例,其URL 为:
http://www.weather.com.cn/weather/101010100.shtml
该Web 页结构复杂,除了含有当天与后3 天以及未来4-7 天的气象信息以外,其间还夹杂有宣传广告、各类链接等大量无关内容,当直接以Domx1 递归算法对该Web 页进行全文提取时,共检索到1406 个DOM树结点,限于篇幅,通过检索构建的图2 右边所示树型视图仅截取了与气象信息相关的部分内容。

图2 中国气象网北京市气象信息页标记对照图(部分)
现假设需要提取的是图2 所示近4 天的气象信息,观察其右边由Domx1 所构建的树型视图可知,它们与5 个<table >结点对应,其中第1 个为表头,后4个则分别对应4 天的信息,且每个<table >结点前均有一注释结点,在Domx1 中加入注释结点详细信息显示功能,可观察到它们分别为<!--day 1-->~<!--day 4-->,其后的数字8 是#comment 结点的类型值(nodeType),定位于该Web 页<!--day 1-->注释附近时,可找到如下内容(部分):
<div class=“weatherYubaoBox”>
<table class =“tableTop”width =“100%”border =“0”cellspacing=“0”cellpadding=“0”>……//表头(略)
<!--day 1-->…//当天开始近4 天的天气信息(略)
<table class=“yuBaoTable”width =“100%”border =“0”cellspacing=“0”cellpadding =“0”>……//共4 个<table >(略)
<div class=“weatherYubao”id=“weatherYubao2”>
<h1 class=“weatheH1”>未来4-7 天….. </h1 >
<div class=“weatherYubaoBox”><!---day 5-->…
观察图2 及上述相关HTML 标记可知,提取近4天信息时可先递归遍历至comment 结点<!--day 1-->,然后连续提取Text 结点信息,直至遇到<div >结点,该结点实际上是后4 天气象信息的起始结点(即后4 天气象信息板块的顶层父结点)。综合上述分析,以Domx1 为基础改写的提取近4 天气象信息的递归算法Domx3 具体实现如下:
int flag = 0;//提取文本的控制标识
void Domx3(IHTMLDOMNode Node){
if (Node != null && (flag = = 0 || flag = = 1)){
if (Node.nodeName = =“#comment”&&
Node.nodeValue.ToString()= =“day 1”)flag = 1;
if (flag = = 1 && Node.nodeName. ToUpper ()= =
“DIV”)flag = 2;
if (flag = = 1 && Node.nodeType = = 3)
str.Append(Node.nodeValue.ToString()+ “”);
Domx3(Node.firstChild);//遍历子树结点
Domx3(Node.nextSibling);//遍历兄弟结点
}}
算法中的标识变量flag 取值为0 ~2,分别表示允许递归遍历(尚未到达<!--day 1-->)、允许遍历并提取文本(在4 天的信息范围内)、停止递归遍历(遇到<div >结点),特别是当其取值为2 时,后续结点的遍历将被跳过。
2.5 气象信息源页面结构变化的处理
为适应气象信息发布网站页面结构可能变更的情况,公司研发带气象信息显示功能LED 电子屏时可考虑将控制软件读取气象信息的URL 地址固定设置为指向研发公司提供的URL,该URL 具备统一的、固定的、规范的格式,每当源网站页面结构变化时研发公司只需要改写提取程序适应新的Web 结构即可。
3 气象信息在LED 电子屏的显示设计
3.1 基于取模方式发送LED 电子屏显示
(1)点阵字库取模。基于取模方式发送LED 刷新显示,需要获取字符点阵数据。假定某LED 电子屏由微控制器(如Atmega128 或PIC18F452),多片74HC595 串 行 级 联(提 供 列 码)[10],74HC138/APM4953(提供行扫及驱动),系统硬字库由EEPROM提供,烧写于EEPROM 的字库由HZK16(16* 16)与ASC(8* 16)两个文件合并构成,微控制器提取EEPROM 点阵时,其偏移地址计算公式如下:
Offset汉字= (94* (* d-0xa0-1)+(* (d+1)-0xa0-1))* 32
Offset英文= 267616 +(* d)* 16
其中,d 为取字符指针。由于英文字库烧录于中文之后,后者添加了固定偏移量267616。根据偏移地址从EEPROM 读取32 或16 字节数据即可分别得到中、英文字符点阵。取得的字库点阵还需转换为LED 点阵,图3 以一个汉字为例给出了转换示意图。设源点阵与目标点阵分别保存于32 字节的数组A、B,转换时可将16* 16 字库点阵分为上、下、左、右四块(4 个8* 8 点阵)进行,转换算法具体实现如下:
for(i = 0;i <8;i+ +){for(j = 0;j <8;j+ +){
byte r = (byte)(0x80 >>i),c = (byte)(0x01 <<j);
for (k = 0;k <4;k+ +){/* 注意k >>1 <<4≠k <<3* /
if ((A [(j <<1)+ (k >>1 <<4)+ (k&1)]& r)!= 0)
B[i +(k <<3)]| = c;}}}
如果下位机没有提供字库,点阵取模及转换任务将由上位机完成,二者的点阵提取及转换算法相似,主要差别是C#可通过FileStream 类读取点阵,而下位机如果没有移植嵌入式操作系统及字库文件,则需要通过接口程序从指定的EEPROM 偏移地址读取。
(2)图像或矢量字库取模。为了使电子屏字符显示更加清晰美观,还可以选用TrueType 字体[11],它采用二次贝塞尔(Bézier)曲线及直线描述字体的外形轮廓,TrueType 字体文件用树型表组织,包括文件头、描述表目录及一系列的描述表[12-13],文件格式非常复杂,驱动开发难度较高。上位机获取矢量字体数据时,可选用Graphics 实例方法将文本输出到Form 窗体或PictureBox,然后通过getPixel 取得像素数据并进行转换。此外还可以通过操作系统提供的字体与图形API从矢量字库提取或通过开源字体操作函数库Freetype提取[14]。
3.2 基于挂载第三方EXE 方式发送LED 电子屏显示
为了使上位机软件具备更好的兼容性,对于第三方开发的提取任意Web 信息的软件,上位机软件不需要重新设计也能将该信息发送LED 电子屏显示,此时可考虑在上位机软件中开发第三方EXE 的挂载功能。对于.NET 平台,其Process 类可用于启动第三方程序,利用Windows API 可将启动的第三方程序界面(如气象信息提取与显示界面)设为挂到主屏内的某个区域(即以之为Parent 窗口),这里所说的主屏指上位机循环扫描并提取像素点阵以便发送LED 显示的专用窗体(例如图4 所示的LED_Form)。显然,扫描主屏区域读取的像素将包括挂载于主屏内某个区域的第三方EXE 界面像素,例如图4 中主屏下的显示气象信息的EXE 窗体(其FormBorderStyle 属性为None)。在这种方式下,除了使用Process 类以外,涉及的Windows API包 括: ShowWindow、 SetParent、 SendMessage、PostMessage、SetWindowPos 等,这 些 API 要 通 过[DllImport(“user32.dll”)]声明。
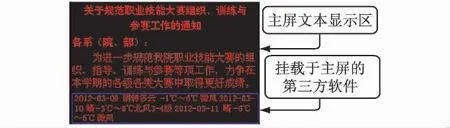
图4 通过挂载于主屏的EXE 实现气象信息扫描显示
3.3 数据信息的传输设计
上位机发送气象信息时,在. NET 平台可通过SerialPort 类(基于RS-232/485)或TCPClient 类分别选择串口或网口实现,后者需要在电子屏微控制器应用TCP/IP 协议栈,例如PIC + Microchip TCP/IP Stack、AVR+Ethernut TCP/IP Stack,或者基于ARM 微控制器移植带以太网模块的嵌入式操作系统等。此外还可选择无线方式传输气象数据[15]。
4 结 语
所提出的Web 气象信息树型提取算法所取得的气象信息在取模及外挂EXE 两种方式下发送LED 显示,均通过了实测运行,取得了很好的效果,验证了该算法及系统设计的可行性。本文的研究将为电子屏研发公司进一步增强产品功能,充分挖掘网络Web 气象信息及其他相关信息,显示于发布公共信息的LED 电子屏提供参考方案。
[1] 刘松业. 正则表达式的Web 数据提取研究[J]. 电脑编程技巧与维护,2008(16):89-91.
[2] Document Object Model[OL]. [2012]:http://en.wikipedia.org/wiki/Document_Object_Model.
[3] 刘 军,张 净. 基于DOM 的网页主题信息的抽取[J]. 计算机应用与软件. 2010,27(5):188-190.
[4] 张瑞雪,宋明秋,公衍磊. 逆序解析DOM 树及网页正文信息提取[J]. 计算机科学,2011,38(4):213-216.
[5] 李 霞,蒋盛益. 基于DOM 树及行文本统计去噪的网页文本抽取技术[J]. 山东大学学报(理学版),2012,47(3):38-42.
[6] 杨 俊,李志蜀. 基于DOM 的WEB 主题信息抽取[J]. 四川大学学报(自然科学版)2008,45(5):1077-1080.
[7] 张云雷,周 军,刘海霞.. 一种基于DOM 的Web 关键信息提取方法[J]. 现代计算机(专业版),2011(12):1-6.
[8] 韩存鸽,燕 敏. Web 信息抽取方法研究[J]. 计算机系统应用,2009(7):172-173,189.
[9] 彭祥礼,朱小军,查志勇. Web 信息抽取和展现系统的设计与实现[J]. 计算机系统应用. 2012,10(2):23-26.
[10] 黄桂梅,刘永立. 小型LED 点阵屏实用软件设计与实现[J]. 计算机测量与控制,2011,19(12):3165-3168.
[11] 陈文文,奚宏生. 嵌入式系统中的TrueType 字体驱动[J]. 计算机工程,2010,36(7):257-259.
[12] 王诗彬,林聪仁.. 用于嵌入式系统的汉字点阵提取方法[J]. 电子技术应用,2007(7):162-165.
[13] 张正华,徐云生. Windows 矢量字库在大屏幕显示中的应用[J]. 电子工程师,2004,30(1):46-48,73.
[14] 黄秀珍,何加铭,邰晓英. 基于FreeType 嵌入式矢量字体引擎的研究[J]. 宁波大学学报(理工版),2010,23(4):58-61.
[15] 刘忠平,郭俊福. 基于GSM 短信无线式LED 气象信息发布屏系统设计[J]. 气象科技息,2007,35(2):303-306.
