基于文本挖掘技术的读者知识管理在学术图书馆中的应用
2013-07-14丁海德周晓梅青岛科技大学图书馆山东青岛266061
●张 岩,丁海德,周晓梅(青岛科技大学 图书馆,山东 青岛 266061)
1 引言
图书馆数字化的迅猛发展给我们带来了海量的读者相关信息。[1]在数字化学术图书馆中,对海量非结构化读者相关知识的管理问题已经成为学者感兴趣的研究领域。
研究人员设计开发了许多挖掘算法和知识管理系统,其中,文本挖掘是一种基于自然语言处理、信息检索、信息抽取和数据挖掘等技术,在海量非结构化文本中半自动的发现模式和趋势的挖掘技术。[2-4]通常文本挖掘被视为面向功能的方法,它专注于数据挖掘任务的需求和目标。这种目标驱动的方法将文本挖掘研究和现实的应用紧密地结合起来。然而,由于数据类型的多样化和知识存在的不同形式,文本挖掘不得不面对各种难题。对于不同目的的不同功能需要考虑使用不同的文本挖掘系统。
2 文本挖掘技术
文本挖掘是基于先进的信息技术,对“隐藏”于海量非结构化文本中的没有检测到的新颖的非结构化知识进行提取的过程。[5]它使得知识工作者得以揭示文本集中的关系并从中发现新的知识。因此,文本挖掘和数据挖掘是相似的,二者都要处理海量数据并获得知识。但数据挖掘是从结构化的数据集中获取,如数据库等其他结构化形式。而文本挖掘所面对的是各种类型的不断增加的文本数据流。
文本挖掘系统由三部分组成:最基本的部分包括机器学习、数理统计和自然语言处理;在此基础之上五种基本技术构成了第二部分,分别为文本数据提取、文本分类、文本聚类、文本数据压缩和文本数据处理;第三部分是在前者基础之上的应用、信息获取(如信息检索、信息过滤等) 和知识发现(如数据分析和数据预测等)。
其中,文本数据提取可以自动发现和索引文本中的重要词句,如标题、作者、关键词等,同时还可以检测存档中出现的重复文件。
文本分类用以将文本文件归为预先定义好的类别。例如,将不同的新闻分别归类为“体育”、“政治”和“文艺”等。不论采用何种方法,文本分类过程总是由一个事先分类 l∈L的训练集D=(d1,…,dn)开始。然后确定一个分类模型

用以将域内新文件d归入正确的类别。这是一种可被用于很多应用中的监督学习。
文本聚类通过基于数据的属性来计算聚类和比较相似度,将具有相似内容的文本分别聚集为不同的群组。最为常用的聚类方法有K均值算法、模型估计、混合模型估计、层次聚类和其他方法。[6]
3 基于文本挖掘技术的读者知识管理
Alexandre等人提出的文本挖掘方法利用信息的提取、检索和文本挖掘,通过估计协作网络或知识地图揭示实体中不同级别的连通性。这种网络能够有效洞察学术图书馆中诸如读者知识(包括来自读者的知识、关于读者的知识和能为读者提供的知识) 和读者之间的关系,使具有相同研究兴趣的读者可以自动获取各自所需的信息。
本文提出方案的具体流程:① 将读者和学术图书馆提供的各种资源如论文、书籍、博客以及关于读者的相关知识整理为待处理文本;② 文本经信息提取得到实体和索引数据库;③ 对所得实体进行相关性计算得到实体的相关数据;④ 经数据挖掘、模式的形成及信息检索完成对文档的文本挖掘处理。随后为可视化工具和评价工具以及读者知识管理的知识管理系统。经以上两个模块的处理,读者即可获得完备、有序的与研究领域相关的读者知识。
3.1 实体提取
实体提取阶段被称为命名实体 (Named Entity,NE) 识别,用于发现正确的名称和它们的变化及所属的类别。[7]这里NE是指能够表达现实世界或抽象世界中的对象的文本元素。例如,一个实体可被定义为一个矢量,该矢量由描述、类别和附加信息构成E={description, class,<additional information>} 。 附加信息可以用来说明诸如模式在文本中的位置等信息。
实体提取过程由两部分组成:有关字的结构和模式。其中,有关字的结构对于实体提取过程和知识库的表达至关重要。[8]每一个纳入考虑的类都和一个相关字表相对应,每一个相关字表都存储了一组可自辨识的词。模式在书面语言中得到广泛应用,它们表达了可被分类的一系列的词。
3.2 实体的相关
相关性方法是用以区分搭配的最常用方法,可用于其他文本元素的相近词辨别和相关程度的度量。LRD(Latent Relation Discovery) 方法通过对三种因素的考虑来确定实体间的关系。① 共现性。如果两个实体出现在同一文本中即为共现。② 距离。计算在同一文本中所有具有共现性之间的距离。③ 相关程度。给定实体E1,则实体E1和E2之间的相关程度可由式(2) 给出。均值距离越大说明二者的相关程度越低。一般而言,E1和E2之间的相关程度是不对称的,其值取决与E1还是E2是目标实体。

式 中 f( Freqi( E1) ) =tfidfi( E1) ,( Freqi( E2) )=tfidfi(E2) , 且Freqi(E1) 和Freqi(E2) 存在于第i个文本之中。tfidfi即词频—逆文档频率法,是利用统计的方式计算出字词与文件中的关联性,进而推导出此次检索该文件在整个资料库中的重要程度。定义为:

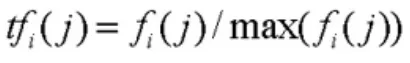
在构造向量过程中,我们利用式(2) 计算每对实体之间的相关程度。
3.3 构造实体数据库
为进行实体提取和相关过程,需要建立相关实体的数据库。用LRD方法计算由源实体(Source Entity,SE) 和目标实体 (Target Entity,TE) 构成的实体对,从而将每一组给定实体对〈SE,TE〉其相关程度存储在数据库中。如表1所示,从三个文本中提取出七个实体,计算出了其相关程度。
因此,对于任意给定SE,可以依据相关程度检索出所有相关的TE。例如,表1中的E3和E1之间的相关程度可由下式得出。
R(E1,E3) =2/3*(0.4938+0.5850) =0.7192 (4)
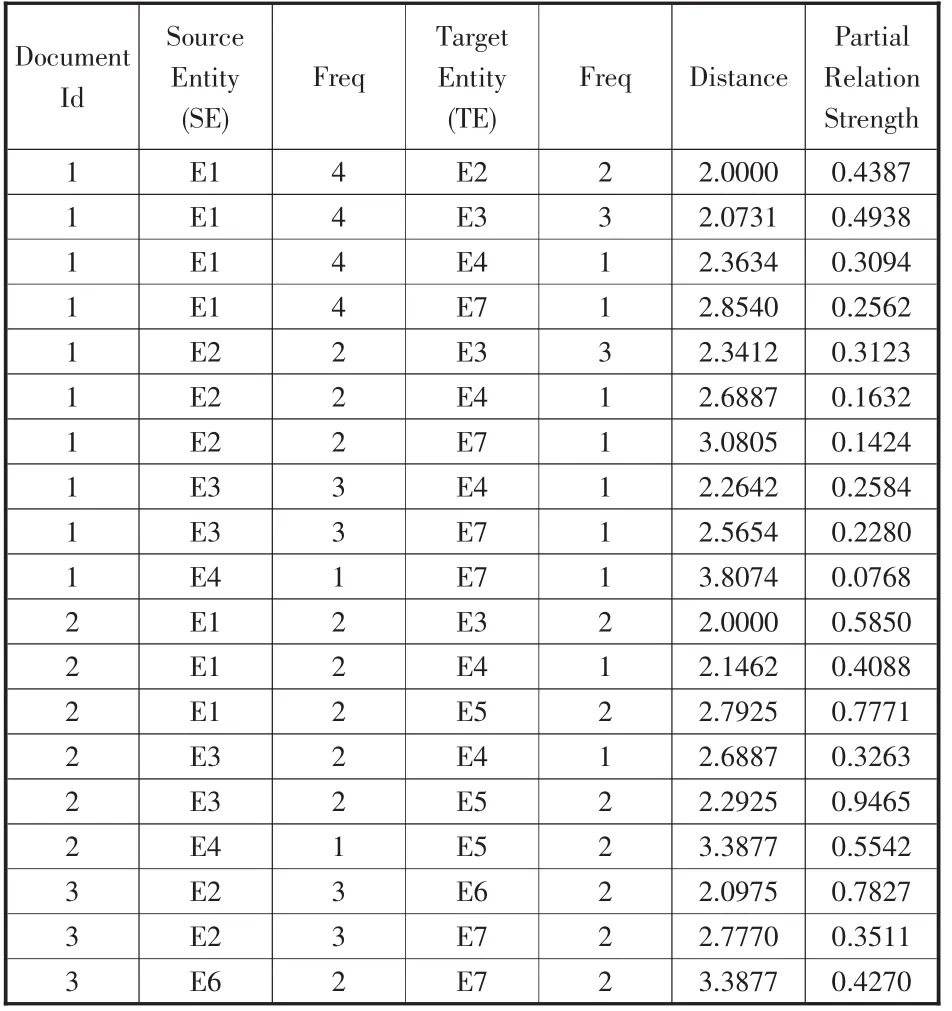
表1 三个文本中七个实体文本间相关权值清单
3.4 信息检索与模式生成
为了可以查询分级文本,计算每一文本的扩展向量和基于词的查询向量的余弦系数。其精度由检索文本过程中余弦系数的阈值来控制。本方案采用聚类算法生成模式,以进一步分析文本和实体是如何相互关联的,采用半径参数方法来控制聚类形成。[9]
首先,选择一个矢量形成第一个聚类。重复这个过程,选择下一个矢量并通过如式 (5) 所示余弦方法和第一个聚类比较。

式中ti和tk是矢量t中第i个和第j个实体的归一化的频率,qi和qj是矢量q中第i个和第j个实体的归一化的频率。如果一个矢量和一个聚类质心被1减的差大于参数r则该矢量形成一个性聚类。否则,该矢量被分配如某一聚类且计算该聚类的质心值。
当聚类过程达到会聚,过程停止,这取决于与当前和前一个过程的平均差之和。聚类过程结束后我们得到包含矢量和聚类平均质心的聚类。
3.5 实验结果
在实验中,以来自读者在图像压缩和传热学领域的3000篇研究论文为实验对象,对每一篇论文进行实体识别处理并将结果以矢量的形式存储。由此,矢量中的元素表达了由描述、类别和在文档中的位置信息组成的实体。实验共提取出了2101个实体,其中包含342个组织名称,1283个个人和476个研究领域。通过实体分析工具对其进行分析以获得它们之间的相互关系,并应用于知识管理系统。例如,对于给定的SE,我们可以得到最为相关的TE;对于每个类,分析最为相关的关系,从而提供一种简单的方法来检查性能,甚至用以检索某一研究领域的专家。实体相互关系表达了不同的目标,从而对某一研究感兴趣的成员就自然地形成了一个群组,由此而形成的社会网络将使各个研究群组的成员受益。
4 结论与展望
在本研究中,我们致力于通过文本挖掘和知识管理技术的应用,在学术图书馆中构建一种各个研究领域都可以分享和学习的研究群体。通过基于共现性的文本挖掘方法来获得文本元素间的相关程度,从而揭示隐藏的知识为知识管理中的决策提供支持。实验结果表明,本文提出的方案可有效地用于处理海量文本,并且对于新增文本并不需要额外的操作。因此,本文方法能够处理隐匿于学术图书馆或其他组织的海量文档中的知识,并对其进行管理。
[ 1] DaneshgarF, BosanquetL.Organizingcustomerknowledge in academic libraries[ J].Electronic Journal of KnowledgeManagement, 2010, 8 ( 1) : 21-32.
[ 2] M Hearst.UntanglingTextDataMining[ C]//The37th Annual Meeting of the Association for Computer Linguistics( ACL’99).Stroudsburg, PA, USA: AssociationforComputationalLinguistica, 1999: 3-10.
[ 3] Gene Ontology Consortium [ EB/OL].[ 2010-06-22].http://www.geneontology.org.
[ 4] R Agrawal, R Srikant.Fast Algorithms for Mining Association Rules in Large Database[ C]//Proceedings of the 20th International Conference on Very Large Databases(VLDB).SantiagodeChile, Chile: MorganKaufmamm, 1994: 487-499.
[ 5] Antonis Spinakis.Text Mining: A Powerful Tool for KnowledgeManagement[ EB/OL].[ 2010-07-29].http://www.quantos-stat.com/articles/Text_Mining.pdf.
[ 6] Xu L, et al.Maximum margin clustering[ J].Advances in Neural Information Processing Systems,2005(17) : 1537-1544.
[ 7] CunninghamHGate.Ageneralarchitecturefortextengineering [ J].Computers and the Humanities,2002, 36 (2) : 223-254.
[ 8] GuthrieL, etal.Theroleoflexiconsinnaturelanguage processing[J].Communications of the ACM, 1996,39(1) : 63-72.
[9] Alexandre G, et al.LRD: Latent Relation Discovery for Vector Space Expansion and Information Retrieval[ C]//Proceedings of the 7th International Conference on Web-Age Information Management.Hong Kong:Know ledge Media Institute, 2006: 122-133.
