基于QM算术编码器的CX序列的反推原理及实现
2013-07-07徐世寅徐妮妮杨雪玲
徐世寅,徐妮妮,杨雪玲,王 静
(天津工业大学电子与信息工程学院,天津 300387)
基于QM算术编码器的CX序列的反推原理及实现
徐世寅,徐妮妮,杨雪玲,王 静
(天津工业大学电子与信息工程学院,天津 300387)
通过对ISO/IEC 10918-1:1993(E)中的QM算术编码器流程图和测试序列进行分析,得出CX序列反推原理.利用测试序列中已有的D、MPS、Qe 3列数据,结合QM算术编码器的概率推断状态机和最小化原则,将QM算术编码器的测试序列中所缺的CX序列补充完整,同时得到MPS、Index的初始值,然后将所得数据输入QM算术编码器,验证所产生CX序列的正确性.
CX序列;QM算术编码;最小化原则;反推原理
QM算术编码是一种自适应二进制算术编码[1-5],是IBM公司的专利技术.它采用递归划分概率区间的编码方式,当有足够多的数据输入时,QM算术编码能够逼近香农熵编码极限,比霍夫曼编码拥有更高的编码效率和灵活性,被广泛应用于JBIG[1]和JPEG[6]国际标准中.国内算术编码方面的文献相当缺乏,仅有的一篇论文原理还不正确,并且算术编码器方面的测试实例更是难以找到. ISO/IEC10918-1:1993(E)国际标准[6]给使用者设置了相当高的门槛,并且标准中给出的流程图存在瑕疵,导致使用者无法看懂和正确理解QM算术编码器.在标准中虽然给出了QM算术编码器的流程图和测试序列,但是标准制定者却故意把测试序列中的CX序列隐去了,让初学者很难通过流程图和测试序列看懂和正确使用QM算术编码器.因此,本文在QM算术编码器的基础上,给出CX序列的反推原理、实现及相关分析,编程产生CX序列、MPS的初始值、Index的初始值,使测试序列成为一个完整的实例,并将产生的各序列输入QM算术编码程序,验证其正确性.
1 CX反推原理
1.1CX在QM算术编码器中的作用
QM算术编码的编码器、解码器如图1所示.

图1 QM算术编码的编码器与解码器Fig.1 Encoder and decoder of QM arithmetic
在编码器中,上下文索引CX和待压缩二进制数据D构成比特、索引对,例如(1,17),(1,19),(0,36)输入编码器编码产生压缩数据,压缩数据以十六进制字节的形式存储,例如0X65,0X7D,0X46;在解码器中,与编码器中相同的上下文索引CX和存储的压缩数据共同输入解码器,解码产生原始二进制数据D.上下文索引CX由DCT变换的量化系数所得,具体产生过程请参考ISO/IEC 10918-1:1993(E)国际标准中的相关说明.
1.2 CX反推原理变量说明
反推原理中用到的变量包括:CX、D、MPS(CX)、Index(CX)、NMPS、NLPS、Switch.上下文索引CX为所求的变量,它的取值变化范围为0~294;待压缩数据D为二进制,它的取值范围为0,1;MPS(CX)是对应于每个CX的大小概率判断标志,MPS(CX)取值范围为0,1;Index(CX)是对应于每个CX的概率推断状态机中的索引值,Index(CX)取值范围为0~113,在概率推断状态机中每个Index(CX)都对应NMPS、NLPS、Switch 3个变量;NMPS为下一个大概率索引值;NLPS为下一个小概率索引值;Switch为大小概率判断标志的反转标志.NMPS、NLPS的取值范围与Index(CX)相同,Switch的取值范围为0,1.为便于查看,上述变量的取值范围如表1所示.
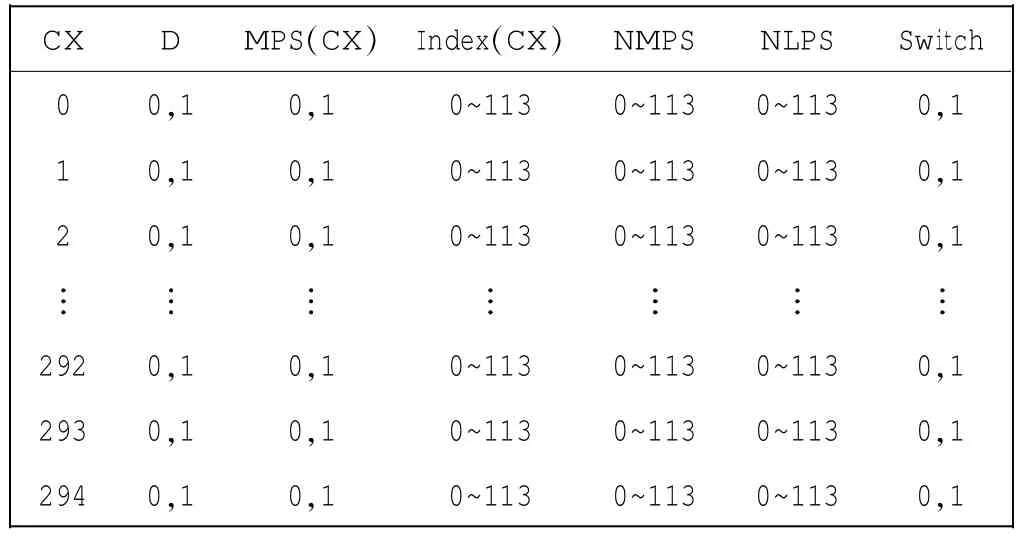
表1 变量取值表Tab.1 Variable value table
Qe、Index(CX)、NMPS、NLPS、Switch共同组成概率推断状态机,在编解码中用到的变量Qe值与概率推断状态机中的Index(CX)相对应,根据Qe值可在概率推断状态机中查到与之对应的Index(CX)、NMPS、NLPS、Switch值,以便确定下一个状态.
1.3 MPS(CX)与CX的关系
待压缩数据D输入算术编码器后,根据D是0或1,选择是CODE1还是CODE0流程,如图2所示.
在进入子程序后,根据MPS(CX)的值选择是大概率还是小概率子程序.由流程图可知,当D和MPS(CX)的值相同时进行大概率编码,不同时进行小概率编码.MPS(CX)为当前CX大小概率标志,程序初始化时默认MPS(CX)=1为大概率,MPS(CX)=0为小概率;当遇到大小概率判断标志的反转标志Switch=1时,MPS(CX)的大小概率判断标准发生反转,MPS(CX)=0为大概率,MPS(CX)=1为小概率;当再次遇到Switch=1时,MPS(CX)将反转回默认值.
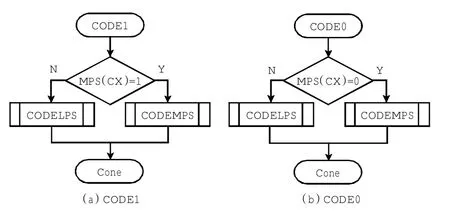
图2 编码1和0的流程Fig.2 CODE1 and CODE0 procedure
1.4 Qe、Index(CX)与CX的关系
当进入大小概率编码子程序时,程序根据CX的值查概率推断状态机找到相应Index(CX)对应的Qe值进行编解码,操作相关区间寄存器和编码寄存器,然后根据CX对应的Index(CX)值查概率推断状态机找到对应的下一个迁移状态的Index(CX),即NMPS、NLPS值,并根据Switch的值完成MPS(CX)的条件性反转.
1.5 CX反推原理说明
根据以上CX自身及相关量的描述,可以确定基于ISO/IEC 10918-1:1993(E)中测试序列的CX反推原理.在测试序列中,MPS(CX)是测试序列的最终结果,并不是每个CX对应的MPS(CX)初始值,同时在测试序列中,根据Qe值,查找概率推断状态机可找到对应的Index(CX)值.将测试序列中的Qe值替换成Index(CX)值,构成新数据表,由于篇幅限制,读者可自行完成新数据表,此处仅列出部分数据,如表2所示.
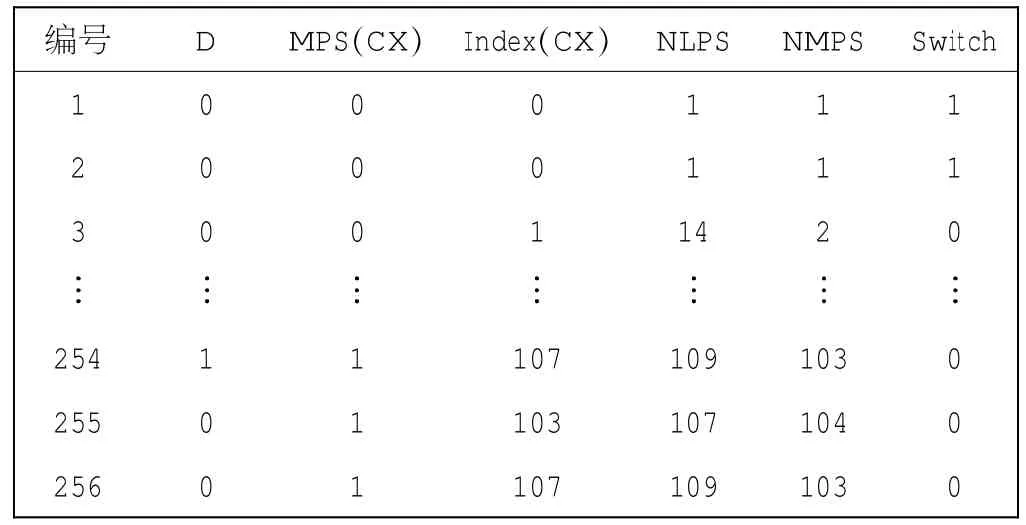
表2 数据表Tab.2 Data table
设变量index(CX)(CX为变量,变化范围为0~ 294),用以记录当前正在使用的Index(CX)值(Index(CX)代表数据表2中的256个数据中的一个,仅是代表值的符号而已);设变量mps(CX)(CX为变量,变化范围为0~294),用以记录当前正在使用的MPS(CX)值(MPS(CX)代表数据表2中的256个数据中的一个,仅是代表值的符号而已).初始化第一个index(CX=0)=0,mps(CX=0)=0.
CX反推原理主要分为2部分:①已有值index(CX)的处理;②新赋值index(CX)的处理.反推原理中用到了产生CX的最小化原则,即每次都将原CX加1赋给下一个新CX,这样产生的CX的数值范围最小.反推原理通过处理index(CX)值来产生CX值,并通过最小化原则控制产生CX的数值范围最小.
对于选择哪一部分产生CX,需要判断index(CX)所记录的值中是否有与当前Index(CX)相等的值,即遍历所有已有值index(CX)查找.如果有,则选择已有值index(CX)部分处理;如果没有,则选择新赋值index(CX)部分处理.
对于已有值index(CX)部分,首先判断数据表2中与Index(CX)对应的D与MPS(CX)是否相等,以便确定是大概率还是小概率.如果是大概率,将与数据表2中Index(CX)对应的NMPS值赋给index(CX),确定下一个index(CX)的更新值,然后判断当前mps(CX)值是否与数据表2中当前Index(CX)对应的MPS(CX)值相同.如果相同,则将数据表2中当前MPS(CX)值的下一个值赋给当前mps(CX);如果不相同,则需要从新赋值的index(CX)处重新开始.如果是小概率,将与数据表2中Index(CX)对应的NLPS值赋给index(CX),重复大概率index(CX)更新值后的过程,最后将出现过的CX记录下来.
对于新赋值index(CX)部分,即产生新的CX,将数据表2中Index(CX)当前值赋给index(CX),然后判断D与MPS(CX)是否相等,以便确定是大概率还是小概率.如果是大概率,将与数据表2中Index(CX)对应的NMPS值赋给index(CX),确定下一个index(CX)的更新值,然后将数据表2中当前Index(CX)对应的MPS(CX)值赋给mps(CX);如果是小概率,将数据表2中与Index(CX)对应的NLPS值赋给index(CX),确定下一个index(CX)的更新值,然后将数据表2中当前Index(CX)对应的MPS(CX)值赋给mps(CX).将期间使用过的CX记录下来.
在新赋值index(CX)部分,每次都是产生新的CX,即index(CX)和mps(CX)记录的都是Index(CX)和MPS(CX)的初始值.因此可以通过以上过程获得CX值,Index(CX)、MPS(CX)初始值.
2 CX反推原理流程图
CX反推原理总流程图如图3所示.程序通过Initialize程序初始化所需的变量,通过Find index[CX]程序查找与Index[CX]相等的index[CX],如果找到则执行Old_index[CX]子程序(已有值index(CX)部分),如果没有找到,则执行New_index[CX]子程序(新赋值index(CX)部分).

图3GET_CX流程Fig.3 GET_CX procedure
Initialize程序如图4所示.初始化各变量,初始化CX=0,变量CX用以记录当前正在使用的CX的值;初始化y=0,变量y用以记录新产生CX的值;初始化result=0,变量用以记录当前Old_index[CX]和New_index[CX]的选择标志位,即是否找到了匹配的index [CX],result=0表示未找到,result=1表示已找到;初始化数组index[295],用以记录各个CX对应的index [CX]值;初始化数组mps[295],用以记录各个CX对应的mps[CX]值;初始化数组cx[256],用以记录测试序列中使用过的CX.
Find index[CX]程序如图5所示,通过遍历所有已有的index[CX]来查找与Index[CX]匹配的index[CX],返回已有的CX值和子程序选择标志位result以确认使用Old_index[CX]和New_index[CX]哪一个子程序来产生CX.
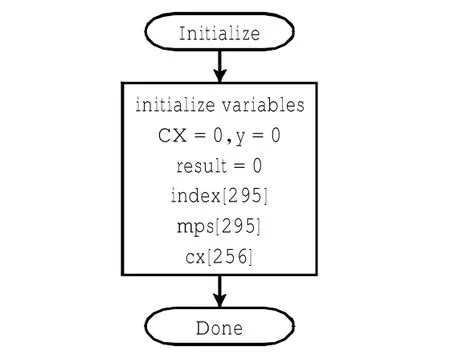
图4 初始化流程Fig.4 Initialisation procedure
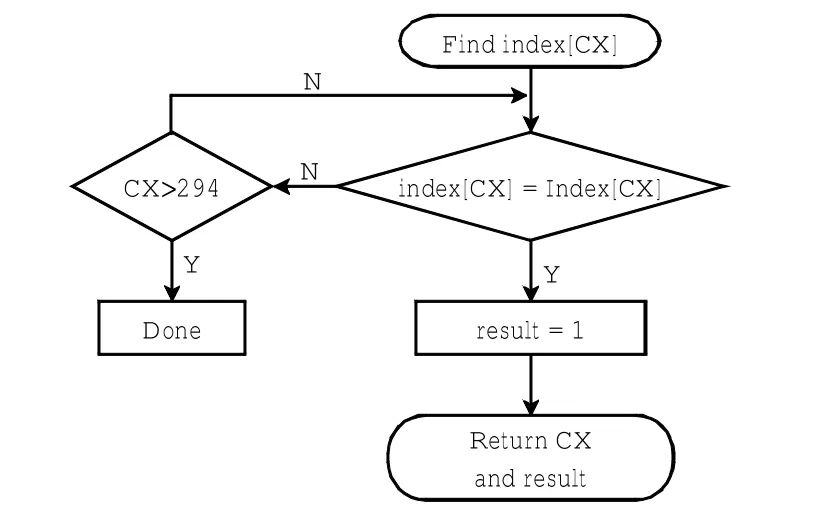
图5 Find index[CX]流程Fig.5 Find index[CX]procedure
图6所示为Old_index[CX]子程序流程,在流程中存在无条件跳转Go to Mark,跳转到主程序Mark处转而执行New_index[CX]子程序.图7所示为New_index [CX]子程序流程.

图6 Old_index[CX]流程Fig.6 Old_index[CX]procedure
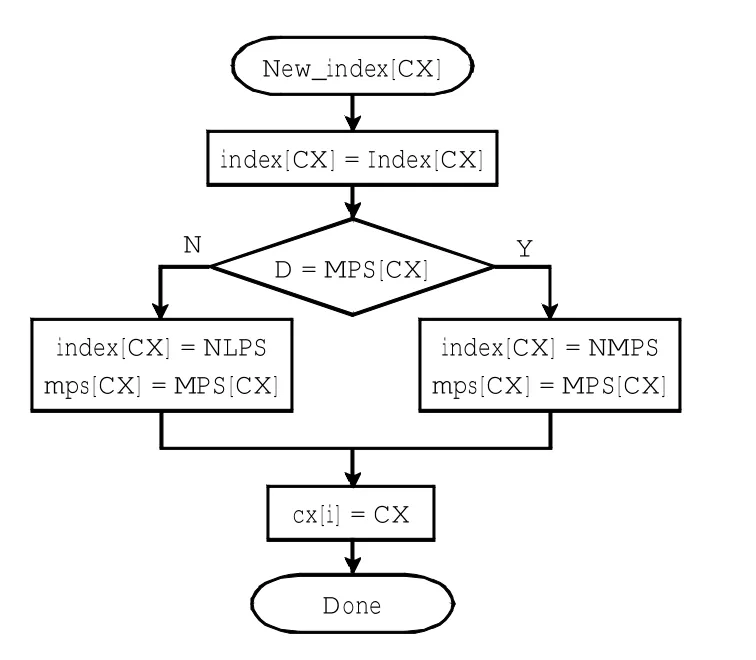
图7 New_index[CX]流程Fig.7 New_index[CX]procedure
3 实验结果验证
实验是在VC6.0[7]环境下测试通过的,运行程序得到数据CX、MPS初始值、Index初始值,如表3所示.
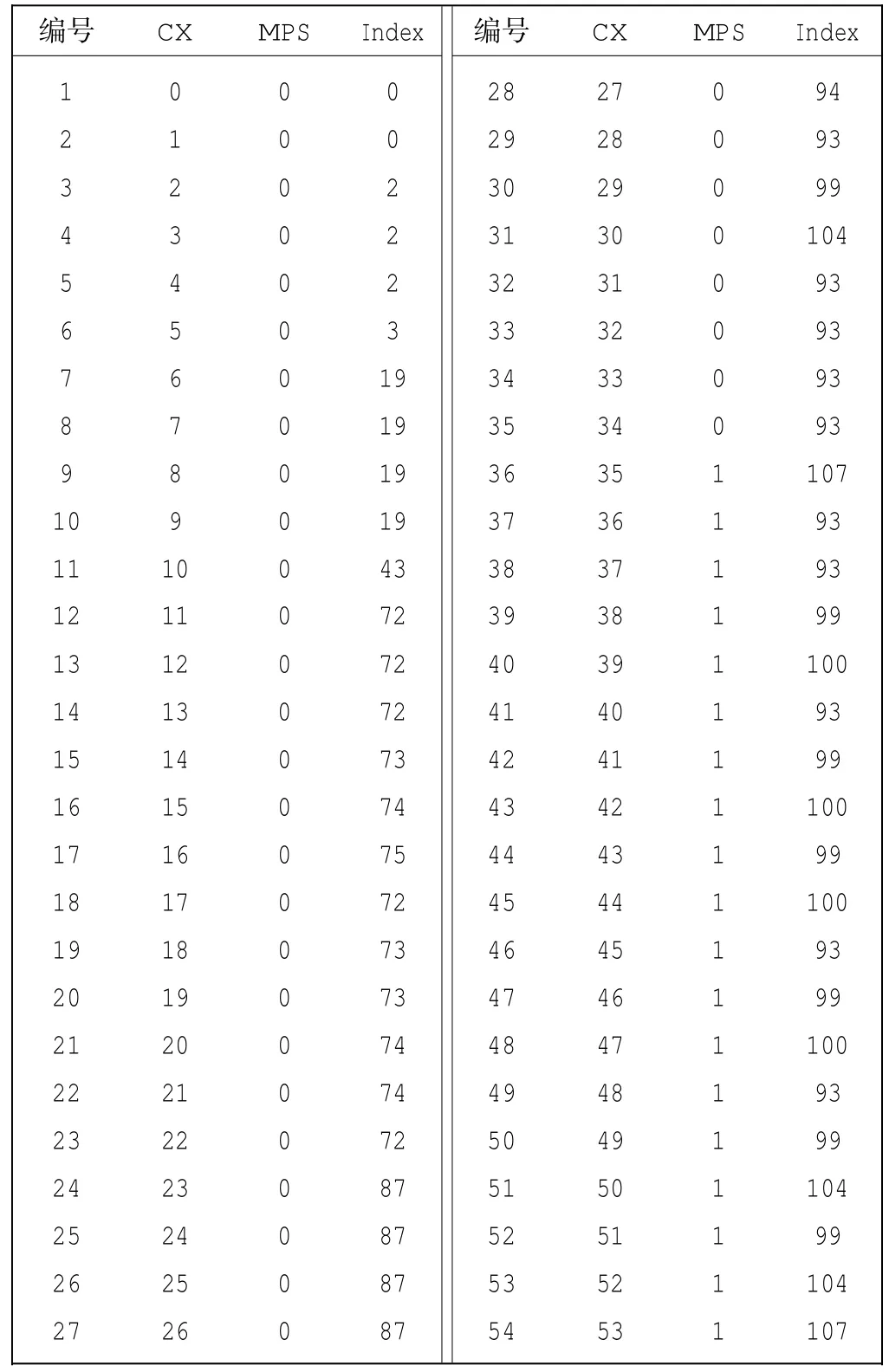
表3 CX对应MPS和Index初始值Tab.3 Initial value of MPS and Index corresponding to CX
测试序列中共256个CX取值,CX取值如表4所示.

表4 所有CX值Tab.4 All values of CX
为了验证GET_CX程序的正确性,将程序中所得的数据和待压缩数据D输入QM算术编码器,QM算术编码器程序仍然在VC6.0环境下运行,程序运行正确,在此仅将测试序列编码表的部分数据列出,测试序列的解码表中的CX与编码表中对应CX值相同,程序结果如表5所示.

表5 测试序列Tab.5 Test sequence
4 结束语
故意缺省CX列的测试序列,给人们学习QM算术编码器带来诸多困难.本文设计的CX序列反推程序很好地解决了这个问题,并且提供了完整的测试序列所需的CX、MPS和Index初始值,供人们测试自己编写的QM算术编码器;而且在设计CX反推程序的过程中,涉及到一些QM算术编码器的概念理解,对人们学习QM算术编码器起到了一定的启发作用,举一反三,对理解其他算术编码器也有一定的帮助.
[1] 小野定康,铃木纯司(日).JPEG技术[M].叶明,译.北京:科学出版社,2003.
[2] 小野定康,铃木纯司(日).JPEG2000技术[M].强增福,译.北京:科学出版社,2004.
[3] LANGDON G.IBM J Res Develop:An Introduction to Arithmetic Coding[Z].1984.
[4] ONO F,YOSHIDA M,KIMURA T,et al.Subtraction-type arithmetic coding with MPS/LPS conditional exchange[C]//Annual Spring Conference of IECED.Japan:D-288,1990.
[5] LANGDON G.Method for carry-over control in a fifo arithmetic code string[J].IBM Technical Disclosure Bulletin,1980,23(1):310-312.
[6] CCITT.ISO/IEC 10918-1,T.81(09/92)[Z].FRENCH:CCITT,1992.
[7] HANLY Jeri R,KOFFMAN Elliot B.Problem Solving and Program Design in C[M].万波,潘蓉,郑海红,译.北京:人民邮电出版社,2007.
Backstepping principle and implementation of CX sequence based on QM arithmetic encoder
XU Shi-yin,XU Ni-ni,YANG Xue-ling,WANG Jing
(School of Electronics and Information Engineering,Tianjin Polytechnic University,Tianjin 300387,China)
The backstepping principle of CX sequence is obtained by the analysis of the flow chart and test sequence about QM arithmetic encoder in ISO/IEC 10918-1:1993(E).Using D,MPS,Qe,the three columns of data in test sequence,and combining probability estimation state machine of QM arithmetic encoder and the minimization principle,the test sequence of QM arithmetic encoder is supplemented with its lacking CX sequence,meanwhile,initial values of MPS and Index is gotten.Then,the obtained data are entered into QM arithmetic encoder and the correctness of produced CX sequence is verified.
CX sequence;QM arithmetic encoder;minimization principle;backstepping principle
TN911.7
:A
:1671-024X(2013)01-0061-05
2012-05-16
:国家自然科学基金资助项目(60602036)
徐世寅(1986—),男,硕士研究生.
徐妮妮(1974—),女,博士,副教授,硕士生导师.E-mail:xunini@tjpu.edu.cn
