Reliability:What type,please!
2013-06-09WeimoZhu
Weimo Zhu
Department of Kinesiology&Community Health,University of Illinois at Urbana-Champaign,Urbana,IL 61801,USA
Opinion
Reliability:What type,please!
Weimo Zhu
Department of Kinesiology&Community Health,University of Illinois at Urbana-Champaign,Urbana,IL 61801,USA
Validity and reliability,as we all learned in our first research methods class,are two of the most important qualities of any test,measurement or assessment.When compared with validity,reliability is actually more important since without it, there would be no validity.Since reliability is so important, almost all research journals today have some articles related to reliability.Unfortunately,many of these articles fail to report one of the important pieces of information regarding reliability—its type.In addition,if the type of reliability is reported,it is oftennotsupportedbyitsstudydesign.Tofullyunderstandwhy reporting the type of reliability and the related study design is important,a short review on the definition of reliability,its types,and their relationship with errors may be helpful.
Reliability is popularly defined as“the consistency of measurements when the testing procedure is repeated”.1Assume that a test taker did a test once and there is no change in the ability or underlying trait being measured;then suppose that the same test was administered again to that same test taker.One would expect the scores from these two trials should be quite similar.If not,the test would be unreliable. According toclassical testingtheory2,aifweadminister onetest manytimestoatesttaker,thisperson’stestscores,knownasthe observed scores,will not be the same all the time.If we plot the scoresinafrequencydistribution,thenassumingthatthereisno learning or fatigue effect,this distribution should look like a normal distribution with most scores close to the center (mean)of the score distribution,with a few very large or verysmall scores(Fig.1).The mean in this case represents the level of ability or intrinsic traits of the test taker,which is known as the“true score”,“universe score”,or“ability/trait”depending on the testing theory employed.The distance between an observed score and the true score is often called“error”,which could represent natural variations in the ability being measured or may be caused by some sort of systematic error.Thus,any observed score can be conceptually considered to have two parts:a true score plus an error.When the error is zero,the observed score(X1in Fig.1)will be equal to the true score.A true score is unknown in real life,but it can be estimated by determining the measurement error and subtracting it from the obtained score.The observedscoreX2hasa slightlylargererror on the positive side of the true score,whereas the observed scoreX3has a much larger error,but on the negative side.The relationshipamong the observedscore,truescore,and errorcan therefore be summarized as:observed score(X)=true score (T)+error(E).
Many factors can contribute to the error or variability:a test taker may try harder,be more anxious,be in better health,or simply make a lucky guess.Since most of these variations function randomly and do not apply to every test taker,they are called“random errors”.In contrast,other variations could be caused by a systematic error:a mechanical problem with the scale when it was used in a retest,or instead of collecting physical activity data on weekdays as was done during the first data collection,the retest data were collected during the weekend.This kind of error is called a“systematic error”because it will apply to every individual test taker.With careful design,the magnitude of the systematic error can be detected (e.g.,collecting physical activity on both weekdays and weekends).In contrast,the magnitude of random errors cannot be detected because they are random,inconsistent,and unpredictable in nature.In most reliability studies,only a simple test—retest design is employed;therefore,both errors are confounded.There may be a variation observed between the testand retest scores,butyouwill NOTbeable todetermine the proportion or contribution of the random versus systematic errors.To do so,a more complex design is needed.

Fig.1.Schematic illustration of the observed score(X),true score(T),and error(E).
1.Commonly used reliability types
Depending on the specific interests of a study,various types of reliability can be employed.In the field of exercise science, the most commonly-used ones are test—retest reliability,single testadministration,andthe precisionofanindividual testscore.
1.1.Test—retest reliability
This is the most popular type of reliability,in which a given test is administered to the same group on two or more occasions. The intervalbetween testand retest is critical:a too short interval maysufferfromafatigueorlearning“carry-over”effect,whereas an overly long interval may suffer from effect growth.If test reliability is established based on two administrations of a given test,each one on a different occasion,then the test is expected to be reliable over that general period of time.If a test is used in a different situation than the one proposed by the test developer, then the test reliability must be re-established.At least,the reliabilitywithincreasedordecreasedtrialsshouldbeestimatedwith something similar to the Spearman—Brown prophecy formula, and the estimated reliability should be reported.
1.2.Single test administration
The reliability of a test can be estimated from a single administration of the test on any one occasion.There are two commonly-used methods for the single test administration reliability.One is to administer thesame test with multiple trials tothesamegroupoftesttakers,andestimatethereliabilityusing the between-trial information.The other way is to administer two or three forms of a test to the same group of test takers,and estimate the reliability using the between-form information.
Please note that there is no guarantee that a test taker’s score on the test would be similar if the test were administered again the next day.However,sometimes this does not matter.For instance,sport competition anxiety can be measured using an inventory developed by Martens.3Test users would not use this inventory unless it measured with consistency the anxiety level of an athlete before a game.However,the athlete would not be expected to obtain the same score on the next day(even if another game was being played),or even after the game ended. Anxiety levels usually fluctuate depending on the specific situation.If test reliability was established based on one administration of a test on a single occasion,the test would be expected to elicit reliable performance only for that occasion.
1.3.Precision of an individual test score
Thus far,reliability estimates that are determined for groups have been discussed.In other words,the reliability coefficient is appropriate for a group of examinees,such as a class of students.Sometimes,it is of greater interest to evaluate the reliability of an individual examinee’s score.This can be done using the standard error of measurement.Anytime an individual takes a test,the test score will be subject to measurement errors.If this error is small,we can be confident that the individual would receive a similar score if the test were taken again.On the other hand,a large error suggests that we can have little confidence in the score,because it could be vastly different if the test were taken again.
2.Objectivity:a special case of reliability
The degree of accuracy in scoring a test is often referred to as the objectivity of the test.If a test is labeled highly objective,this means that there will be little error in scoring the test.In contrast,a subjective test might be scored quite differently depending upon the scorer.Variability among scorers increases when the scorer is required to make judgments that are more subjective,as in rating playing ability in a sport.As the subjectivity of a test increases,the test developer is obligated to report an objectivity estimate.Two types of objectivity,intrarater and interrater,are reported.
Intrarater objectivity refers to consistency in scoring when a rater scores the same test two or more times.In testing motor skills,estimates of intrajudge objectivity are more difficult to obtain,because the same performance must be viewed and scored twice.This is usually facilitated by recording the performance on film or videotape.Interrater objectivity refers to consistency between two or more independent judgments of the same performance.Interrater objectivity is an important part of ranking events in gymnastics,diving and figure skating, where several judges rate the same performance.
3.Reliability type based on a specific interest and design
According to its definition,reliability is often considered an intrinsic property of a test,measure or assessment.This common belief has been challenged,because most reliability studies have mixed instrument reliability and personal stability together.As an example,when studying the“reliability”of physical activity monitors,researchers in many published studies often ask the subjects to wear a monitor for a set number of days,and then after a short or long-term interval,to wear the monitor again for the same number of days.The testand-retest data are then used to compute the reliability of the monitor.Since the device reliability in this kind of research design is confounded by variations in the subjects’physical activity participation,there is no way to determine the truereliability of the monitor.Furthermore,since most of the between-time differences represent variations in the participants’physical activity behavior,the reported device reliability is indeed mainly due to the stability of the subjects’physical activity behaviors.This kind of reliability is not device/instrument reliability,but rather“score reliability”.4
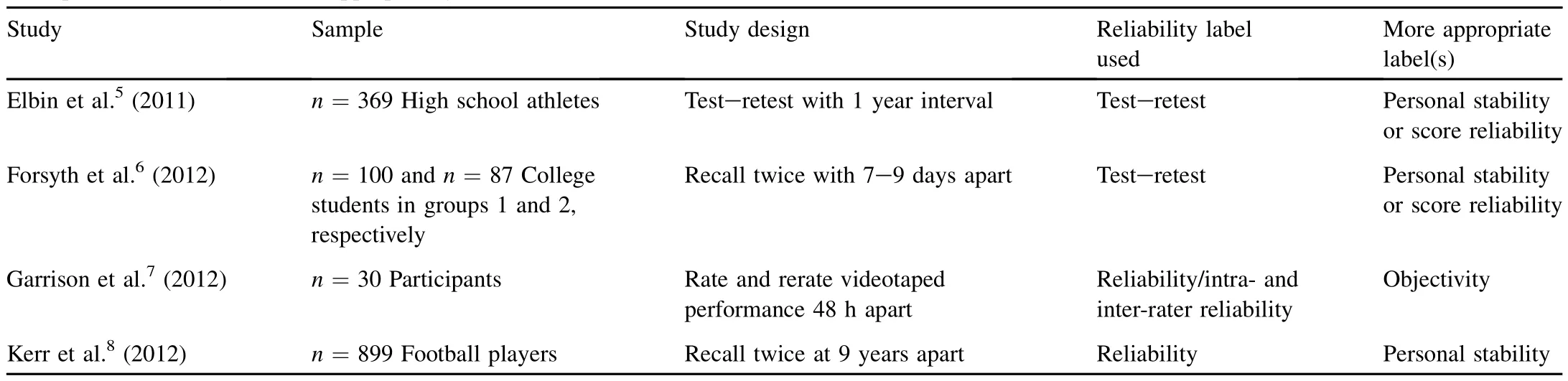
Table 1 Examples of reliability studies inappropriately labeled.
A closer look at several real reliability studies may help with this explanation.Table 1 illustrates a few recently published studies in which reliability was examined.As summarized in Table 1,the reliability labels used in these studies are not appropriately used:
·Elbin et al.5—Since most errors came from personal recollectionspacedoneyearapart,thereportedreliabilityislikely not the reliability of the online version of ImPACT,but the recall stability of the high-school athletes or their relative rank orders in the test—retest ImPACT data distributions.
·Forsyth et al.6— Since physical activity behavior likely varies from day to day and week to week,the reported survey reliability is of personal stability in physical activity behavior,and a much shorter interval(a few hours)should be included in the test—retest study design.
·Garrison et al.7—This study only examined the objectivity (specifically the intra-and inter-rater objectivity),but the authors used“reliability”in both the title and conclusion.
·Kerr et al.8—Although the study examined“the reliability ofthe self-reportconcussion history measure”and concluded the measure“had moderate reliability”,it mixed up several sources of error including test—retest reliability and personal stability in recall.Since the interval is so long (9 years),it is likely that a systematic error(the impact of aging on health and memory)was also included.
A more correct way tospecify a type ofreliability evidence is tofirsthavethereliabilityevidenceclearlyoperationallydefined, and then the research study with the evidence type(s)in mind should be designed.Finally,the appropriate statistical analyses are applied,and the specific evidence is labeled and interpreted. In general,instrument reliability should be distinguished from person stability,and where there is the need,further breakdowns should be included.Finally,more advanced theories and methods,such as generalizability theory,9should be employed whenmultiplereliabilityevidencesareexaminedsimultaneously.
4.Conclusion
Measurement specialists in exercise science have long advocated for distinguishing the error variances in reliability studies,and for determining the impact of these variances on reliability using more advanced reliability theory and methods.10,11Unfortunately,these recommendations have been largely ignored in most reliability research studies.As a result,the term reliability is often incorrectly labeled and interpreted.This paper calls for defining the reliability evidence to be studied/collected clearly,then designing the study accordingly,and finally reporting and interpreting the type of reliability studied appropriately.
1.American Educational Research Association,American Psychological Association,and National Council on Measurement in Education.Standards for educational and psychological testing.Washington:American Educational Research Association;1999.p.25.
2.Crocker L,Algina J.Introduction to classical and modern test theory. New York:Holt,Rinehart,and Winston;1986.
3.Martens R.Sport competition anxiety test.Champaign,IL:Human Kinetics Publishers,Inc.;1977.
4.Thompson B,editor.Score reliability:contemporary thinking on reliability issues.Thousand Oaks,CA:Sage Publications;2003.
5.Elbin RJ,Schatz P,Covassin T.One-year test—retest reliability on the online version of ImPACT in high school athletes.Am J Sports Med2011;39:2319—24.
6.Forsyth A,Krizek KJ,Agrawal AW,Stonebraker E.Reliability testing of the pedestrian and bicycling survey(PABS)method.J Phys Act Health2012;5:677—88.
7.Garrison JC,Shanley E,Thigpen C,Geary R,Osler M,DelGiorno J.The reliability of the vail sport test as a measure of physical performance following anterior cruciate ligament reconstruction.Int J Sports Phys Ther2012;7:20—30.
8.Kerr ZY,Marshall SW,Guskiewicz KM.Reliability of concussion history in formerprofessionalfootballplayers.MedSciSportsExerc2012;44:377—82.
9.Brennan RL.Generalizability theory.New York,NY:Springer;2001.
10.Safrit MJ,Atwater AE,Baumgartner TA,West C,editors.Reliability theory.Washington DC:American Alliance for Health,Physical Education and Recreation;1976.
11.Morrow Jr JR.Generalizability theory.In:Safrit MJ,Woods TM,editors.Measurement concepts in physical education and exercise science. Champaign,IL:Human Kinetics;1989.p.73—96.
Received 23 October 2012;accepted 28 October 2012
aThe definition of reliability also varies according to the testing theory employed.For example,when a test is constructed using the item response theory,the local precision(e.g.,standard error of measurement)is used rather than the traditional reliability.
E-mail address:weimozhu@illinois.edu
Peer review under responsibility of Shanghai University of Sport.
2095-2546/$-see front matter Copyright©2012,Shanghai University of Sport.Production and hosting by Elsevier B.V.All rights reserved. http://dx.doi.org/10.1016/j.jshs.2012.11.001
杂志排行

Journal of Sport and Health Science的其它文章
- Chronic disease and the link to physical activity
- Physical activity,sedentary behaviors,physical fitness,and their relation to health outcomes in youth with type 1 and type 2 diabetes: A review of the epidemiologic literature
- Physical activity and exercise training in young people with cystic fibrosis: Current recommendations and evidence
- Children and adolescents with Down syndrome,physical fitness and physical activity