Big-Data Analytics:Challenges,Key Technologies and Prospects
2013-06-06ShengmeiLuoZhikunWangandZhipingWang
Shengmei Luo,Zhikun Wang,and Zhiping Wang
(Cloud Computingand ITInstituteof ZTECorporation,Nanjing 210012,China)
Abstract With the rapid development of the internet,internet of things,mobile internet,and cloud computing,the amount of data in circulation has grown rapidly.More social information has contributed to the growth of big data,and data has become a core asset.Big data is challenging in terms of effective storage,efficient computation and analysis,and deep data mining.In this paper,we discuss the signif⁃icance of big data and discuss key technologies and problems in big-data analytics.We also discuss the future prospects of big-data analytics.
Keyw ords big data;mass storage;data mining;business intelligence
1 Introduction
F ollowing on the heels of the PC and internet,cloud computing will be the third wave of IT and will fun⁃damentally change production and business models.Cloud computing improves data convergence,stor⁃age,and processing and makes it easier to extract value from data.More and more intelligent terminals and sensing devices are being connected to networks,and data is rapidly becoming morevaried and extensive(Fig.1).
Data-processing technologies have developed steadily for a long time,but big data has suddenly caused two significant changes.Now,all data can be saved.This means that applica⁃tions that require data to be accumulated prior to implementa⁃tion can be more easily implemented.Also,there has been a shift from data shortage to data flood.Such a flood has created new challenges for data applications.Simply acquiring data from search engines is no longer sufficient for today's applica⁃tions.It is increasingly difficult to efficiently obtain and pro⁃cess useful data froma massof data.
In 2012 Hype Cycle for Emerging Technologies,Gartner stated that cloud computing was falling into a“trough of disil⁃lusionment,”meaning that technology was set to mature after years of being hyped(Fig.2)[1].Big data is rapidly moving from the phase of“technology trigger”to the phase of“peak of inflated expectations.”Technological breakthroughs in big da⁃ta will continue to be made so that big data will be widely used in thenext twotofiveyears.
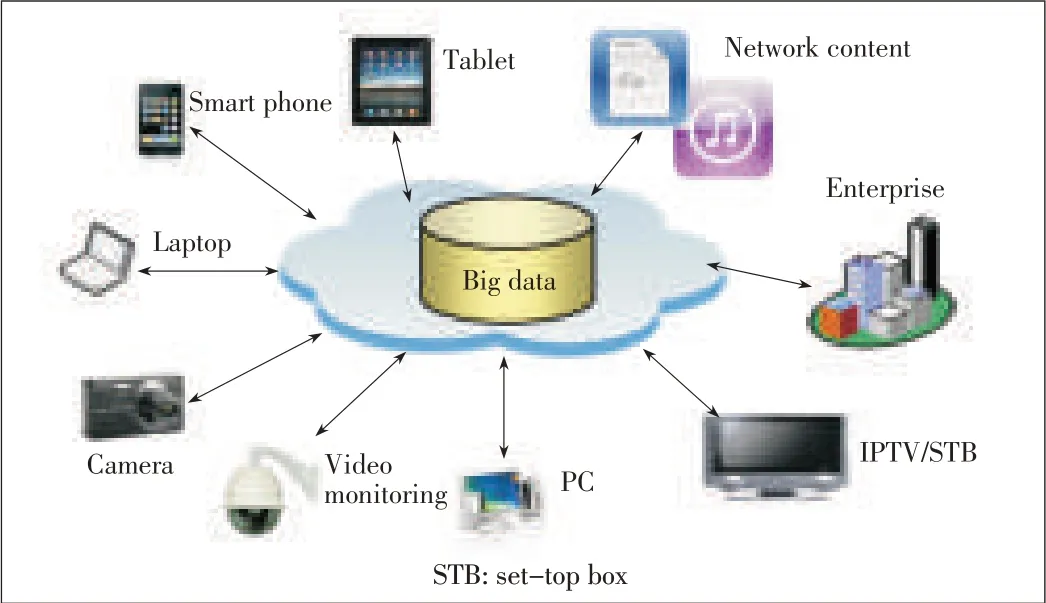
▲Figure1.A big-data scenario.
2 Definition and Featuresof Big Data
Big data implies a collection of data sets that are so large and complex that they are difficult to manage using traditional database management tools or data-processing applications[2].Compared with traditional data,big data has greater vol⁃ume;it is more varied;and it derives from a greater range of sources.Big data is not a simple mass of data nor is it only a cloud computing application.The key to big data is deriving valuable information from a mass of data.The features of big data can be summarized as the“four Vs”:volume,variety,ve⁃locity,and value(Fig.3).
2.1 Volume
Because of the decreasing cost of generating data,the world⁃wide volume of data has grown sharply.Ubiquitous mobile de⁃vices and wireless sensors are generating data every minute,and bulk data exchanges are occurring every second between billions of the internet services.Scientific applications,video surveillance,medical records,enterprise operational data,dis⁃crete manufacturing,and e-commerce are all sources of big da⁃ta.In 2011,the International Data Corporation claimed that“The world's information is doubling every two years”[4].In that year,the world generated a staggering 1.8 ZB(1021B)of data,an increase of 0.6 ZB year-on-year.By 2020,the world will generate up to 35 ZB of data,and this poses significant challengesfor storage(Fig.4[4]).
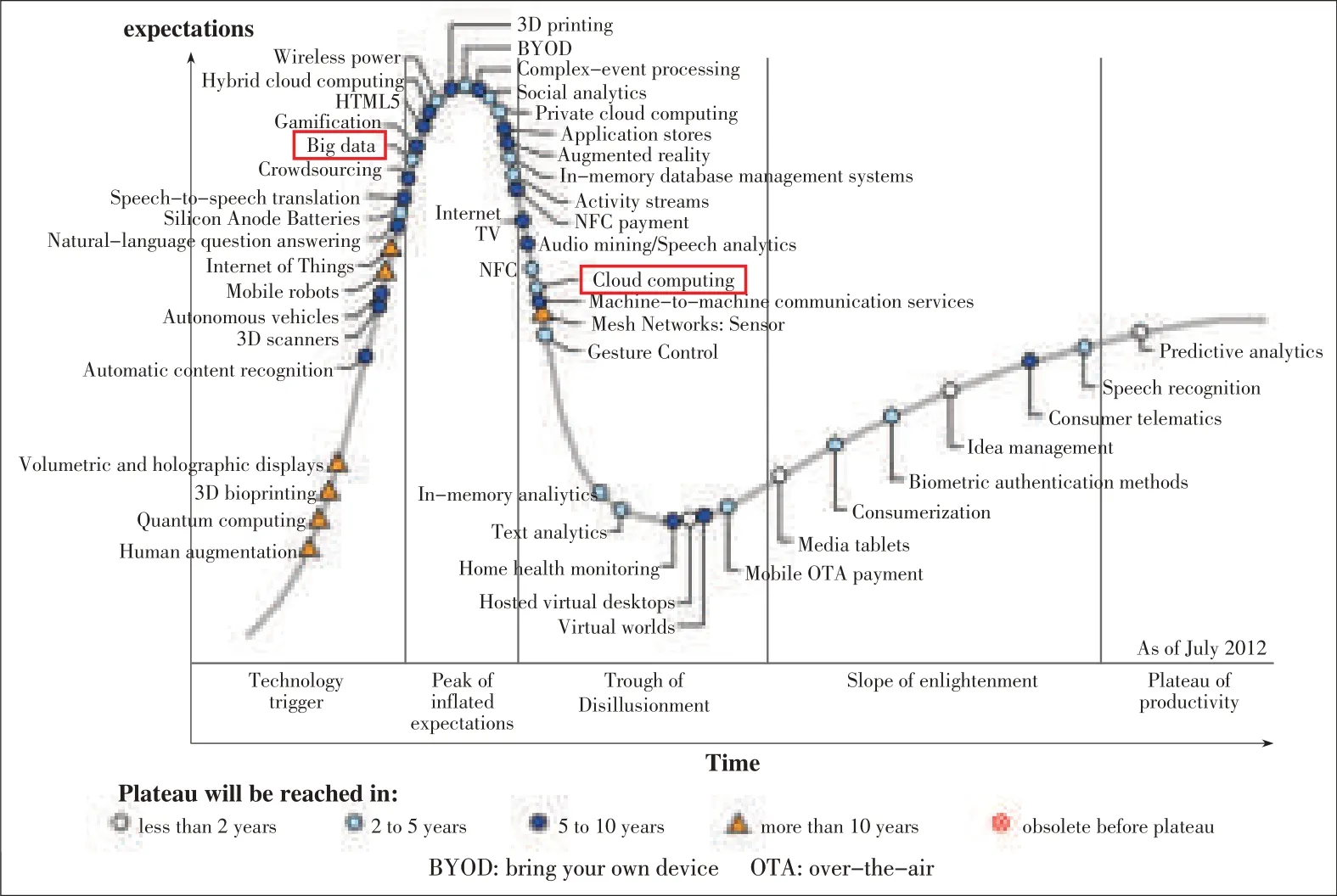
▲Figure2.Gartner 2012hypecycle.
2.2 Variety
Data may be structured,unstructured or semi-structured,and all three types of data are frequently and extensively inter⁃changed.Structured data only accounts for 20%of the big data stored in databases.Data from the internet—including data cre⁃ated by users,data exchanged in social networks,and data from physical sensing devices and the internet of things—is dynamic and unstructured.Unstructured data accounts for 80%of big data stored in databases.
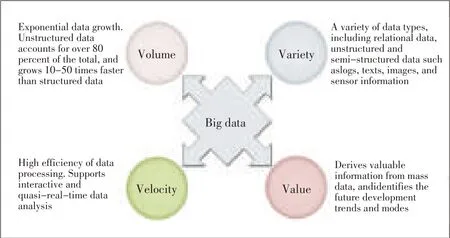
▲Figure3.The“four Vs”of big data.
2.3 Velocity
Velocity refers to the high re⁃quirements on real-time process⁃ing and quasi-real-time analysis of big data.With traditional data warehousing and business intelli⁃gence, real-time requirements are lower.In the big-data era,the value of data decreases rapid⁃ly over time,so data needs to be exploited assoon aspossible.
2.4 Value
Structured data of an enterprise has traditionally been used for statistics and historical analysis.However,big data in⁃volves extracting valuable information from mass data to pre⁃dict future trends and make decisions.In addition,big data has low value density.For example,continuous video surveil⁃lance may produce a great deal of data,but only a few seconds of thevideomay actually beuseful.
3 Challengeswith Big-Data Analytics
Traditionally,data originates from a single source and has relatively low volume.Storing,managing,and analyzing such data does not present great challenges,and most processing is done through relational databases and data warehouses.In a big-data environment,the volume of data is so great that tradi⁃tional information processing systems cannot cope with stor⁃age,mining,and analysis.Traditional business intelligence software lacks effective tools and methods for processing and analyzing unstructured data.Here,we discuss some problems in big-dataanalytics.

▲Figure4.Forecast of thevolumeof global data.
3.1 Extensive Data Sourcesand Poor Data Quality
Big-data scenarios are characterized by heterogeneous data sources,such as transaction records,text,images,and videos.Such data is described in different ways,and the data input rate may reach up to hundreds of megabits or even gigabits per second.Traditional methods for describing structured data are not suitable for describing big data.In addition,bigdata iseas⁃ily affected by noise and may be lost or inconsistent.Filtering and integrating incomplete,noisy,and inconsistent data is a prerequisite for efficiently storing and processing big data.
3.2 Highly Efficient Storageof Big Data
The way that big data is stored affectsnot only cost but anal⁃ysis and processing efficiency.Big data is often measured in petabytes or even exabytes and cannot be handled by enter⁃prise storage area networks or network-attached storage.To meet service and analysis requirementsin the big-data era,re⁃liable,high-performance,high-availability,low-cost storage solutions need to be developed.Because big data comes from various sources,the same data may exist in the system and cause absolute redundancy.Detecting and eliminating redun⁃dancy increases storage space and is a fundamental require⁃ment for big-datastorageplatforms.
3.3 Efficiently Processing Unstructured and Semi-Structured Data
Enterprise data is mainly processed in relational databases and data warehouses;however,such databases and warehouses are unsatisfactory for processing unstructured or semi-struc⁃tured big data.With big data,read/write operations need to be highly concurrent for a mass number of users;storage of and access to big data needs to be highly efficient;and the system must be highly scalable.As the size of datasets increases,algo⁃rithms may become inefficient,and the atomicity,consistency,isolation,durability(ACID)features of relational databases are resource intensive.The CAPtheorem states that it is impossi⁃blefor adistributed computer systemto simultaneously guaran⁃tee consistency,availability,and partition tolerance[5].Be⁃cause consistency is required in parallel relational databases,these databases are not highly scalable or available.High sys⁃tem scalability is the most important requirement for big-data analytics,and highly extensible data analysis techniques must bedeveloped.
3.4 Mass Data Mining
With an increase in the size of data sets,more and more ma⁃chine learning algorithms and data-mining algorithms for big data have emerged.Research has shown that for larger data sets,machinelearning is more accurate and there isless differ⁃ence between machine-learningalgorithms.However,largeda⁃ta sets are problematic for traditional machine-learning as well as data-mining algorithms.In fact,most traditional da⁃ta-miningalgorithmsarerendered invalid by bigdata sets.Ma⁃chine-learning and data-mining algorithms with difficulty lev⁃elsof O(n),O(n log n),O(n 2),and O(n 3)can be used for small data sets.However,when the size of a data set reaches pet⁃abytes,serial algorithms may fail to compute within an accept⁃able timeframe.Effective machine-learning and data-mining algorithmsneed tobedeveloped for bigdatasets.
4 Big-Data Analytics
4.1 Architecture
A typical big-data processing system includes collection and preprocessing,storage,analysis,mining,and value appli⁃cation.Fig.5 shows the architecture of a big-data system.In the data-source layer,data comes from enterprises,industry,the internet,and the internet of things.In the data-collection layer,the collected data ispreprocessed.This preprocessing in⁃cludes data cleanup and heterogeneous data processing.In the data-storage layer,structured,unstructured,and semi-struc⁃tured data is stored and managed.In the data-processing lay⁃er,dataisanalyzed and mined sothat userscan analyze servic⁃es,such as common telecommunications and internet services,on the platform.
4.2 Big-Data Technology
4.2.1 Collection and Preprocessing
Converting the format of mass amounts of data is expensive,and adds to the difficulty of data collection.Traditional da⁃ta-collection tools have become obsolete,and most internet companies have their own big-data collection systems.Exam⁃ples of such systems are Apache Chukwa[6],Facebook Scribe[7],Cloudera Flume[8],and Linkedin Kafka[9].

▲Figure5.Big-data architecture.
Cleaning and extracting technologies are used to clean out damaged,redundant,and useless mass data in networks and extract quality data for analysis.Hadoop is used to expedite da⁃tacleaning,conversion,and loadingand toimprovepreprocess⁃ing of parallel data[10].Big-data collection and preprocessing technologies are also designed to optimize the quality of multi⁃source and multimode data.These technologies perform the computations necessary for the integration of multimode data.They transform high-quality data into information,control the quality of information derived from different sources,and lay thefoundation for dataanalysis.
4.2.2 Storage
Unstructured and semi-structured data account for 80%of stored big data.At present,big-data storage is based on inex⁃pensive X86 server cluster systems that are highly scalable us⁃ingcertain methods.
Unstructured data is stored in distributed file systems.Un⁃like the traditional Network File System(NFS),a distributed file system separates control streams from data streams in or⁃der to improve scalability[11].In a distributed file system,the metadata servers manage all the metadata and cluster informa⁃tion of data-storage servers.For example,the capacities of Google File System(GFS)[12],Hadoop Distributed File Sys⁃tem(HDFS)[10],Lustre[13],and Ceph[14]can be up to 10 PB or even 100 PB.These storage systems provide file access semantics through POSIX interfaces.If a metadata server fails in a storage system of this kind,the whole file system fails to provide services to users.The processing and storage capacity of a single-node metadata server is also quite limited.As the amount of data traffic in the system increases,the processing capability of metadata servers becomes a bottleneck for system scalability.
Metadata servers can therefore be used in active/standby mode(Fig.6).In normal conditions,the active metadata server processes all requests,manages the whole distributed file sys⁃tem,and regularly sends data to the standby metadata server for synchronization.If the active server fails,the standby serv⁃er takes over all activities without interrupting services.Data that has not been sent to the standby server may be lost.Using this mode,single-point failures can be solved,but the system cannot be scaled.Therefore,a highly scalable metadata server cluster is critical in a distributed file system.The design of such a cluster includes static subtree partitioning,static hash⁃ing,dynamic subtreepartitioning,and dynamic hashing[15].
Big data includes semi-structured data,which is more struc⁃tured than plain-text data but has more flexible models than data in relational databases.Semi-structured data does not re⁃quire strict database transactions.It mainly involves simple single-table query,and in some cases,it has low consistency requirements.Therefore,database transaction management is a burden in heavily loaded databases.The NoSQL database is,broadly speaking,a non-relational database in which the link between relational database and ACID theory is broken.NoSQL data storage does not require a fixed-table structure or connection operations,and this provides significant advantages in termsof accesstobigdata.
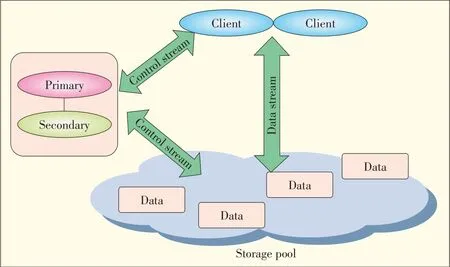
▲Figure6.Architectureof a metadata server cluster in active/standby mode.
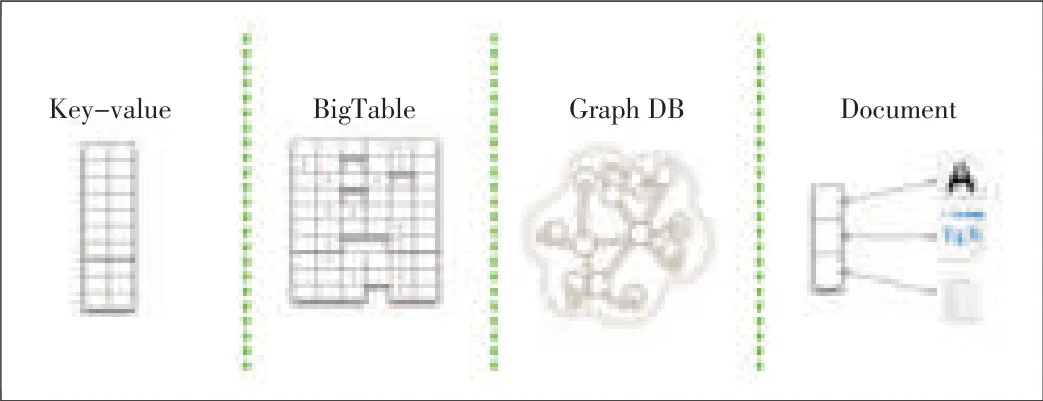
In NoSQL databases,relational data storage models are dis⁃carded in favor of a schema-free principle that supports dis⁃tributed horizontal expansion and big data.There are many NoSQL database products and open-source projects,including Dynamo[16],BigTable[17],Cassandra[18],and MongoDB[19].Fig.7 shows four types of NoSQL databases based on the data model.From left to right,key-value,column-oriented,graph-oriented,and document-oriented databases are in as⁃cending order of complexity and in descending order of scal⁃ability(Fig.7).A database can beselected accordingto the ap⁃plication scenario.
NoSQL systems are not yet mature:Most are open-source projects that have little commercial support.NoSQL systems lack unified application program interfaces(APIs)and do not support SQL,which is costly in terms of learning and applica⁃tion migration.
4.2.3 Processing
Processing large data sets with mixed loads is complex,and certain processing requirements should be met(Table 1).
The data warehouse is the primary means of processing the traditional structured enterprise data.In the big-data era,the datawarehousehaschanged in termsof
·distributed architecture.A typical data warehouse includes complicated data processing and comprehensive analysis;therefore,the system should be capable of high I/Oprocess⁃ing,and the storage system should provide sufficient I/O bandwidth.Most data warehouses use massive parallel pro⁃cessing(MPP)architecture for scalability and to improve ac⁃cessefficiency.
▲Figure7.NoSQL databasemodels.

▼Table1.Big data processing requirements
·storage model.There are two methods for storing physical data in databases:row and column.Row storage is used in traditional databases where OLTP applications read and write in rows and have low data traffic.Column storage is used in data warehouses where most OLAP applications do not need toselect all columns.Thismethod of storagecan re⁃duceunnecessary I/Oconsumption and makesdatacompres⁃sion easier.A high data compression ratio can be achieved because thedata in a column is the same type.
·hardware platform.Traditional databases are mainly found on midrange computers.If data traffic increases sharply,the cost of upgrading hardware can increase significantly.In the big-data era,parallel data warehouses are based on univer⁃sal X86 servers.
Big unstructured data is mainly processed using a distribut⁃ed computing architecture(Fig.8).This architecture,located at the distributed storage layer,encompasses parallel comput⁃ing,task scheduling,fault tolerance,data distribution,and load balancing.It provides computation services for the upper layer.The language layer encapsulates service interfaces and provides SQL-like programming interfaces.The SQL-like lan⁃guagesvary with thecomputingarchitectures.
There are three types of distributed computing based on dif⁃ferent computation models:
1)MapReduce.This model can be expressed as(input key,in⁃put value)→(output key,output value).The output key/val⁃ue pairs are processed,and the input key/value pairs are generated using the MAP or Reduce functions.This model hasasimplelogic and iswidely used[20].
2)Bulk Synchronous Parallel(BSP)model[21].This is an iter⁃ative computation model that is similar to a simple computa⁃tion model;however,the difference lies in communication.In this model,all nodes are synchronized after each round of computation.This is suitable for iterative scenarios.Google Pregel,for example,isbased on BSParchitecture[22].
3)Directed Acyclic Graph(DAG)model.This model uses DAGto describe complicated computing processes and rela⁃tionships between them.Microsoft uses this computing mod⁃el in its Dryad project[23].
Real-time stream processing platforms such as Yahoo S4[24]and Twitter Storm[25]have been created to meet big-data processing requirements.These platforms process a data stream in real time in the memory and do not retain much data.
4.2.4 Mining
Big-dataminingtechnology isused to effectively extract val⁃ue from big data.Such technology includes parallel data min⁃ing,search engine,recommendation engine,and social net⁃work analysis.
Parallel data mining greatly increases the speed of big-data mining by implementing data-mining algorithms in parallel.Hadoop[10]and HDFS aid in this implementation.The da⁃ta-mining algorithms include parallel classification algorithm and parallel clustering algorithm.Fig.9 shows a parallel da⁃ta-mining system architecture based on cloud computing plat⁃forms.
▲Figure8.Servicesystem of adistributed computingarchitecture.

▲Figure9.Parallel data-mining system architecturebased on cloud platform.
A search engine is an information retrieval system that col⁃lects data from various services or application systems.It stores,processes,and reorganizes the data and provides users with query functions and results.The search engine is an im⁃portant tool for data management after the big data has been obtained by a storage system.The search engine allows users to input simple queries and obtain useful collections of infor⁃mation.Fig.10 showsthe architecture of a universal search en⁃gine comprising many technology modules.The key technolo⁃gies include the Web crawler,document understanding,docu⁃ment indexing,relevance computing,and user understanding.
The recommendation engine helps users to obtain personal⁃ized services or content from a mass of information.It is the driver of the transition from a search era to a discovery era.The main challenges for recommendation systems are cold start,scarcity,and scalability.The quality of recommendations depends not only on the models and algorithms but also on non-technical factors,such asproduct formand servicemode.
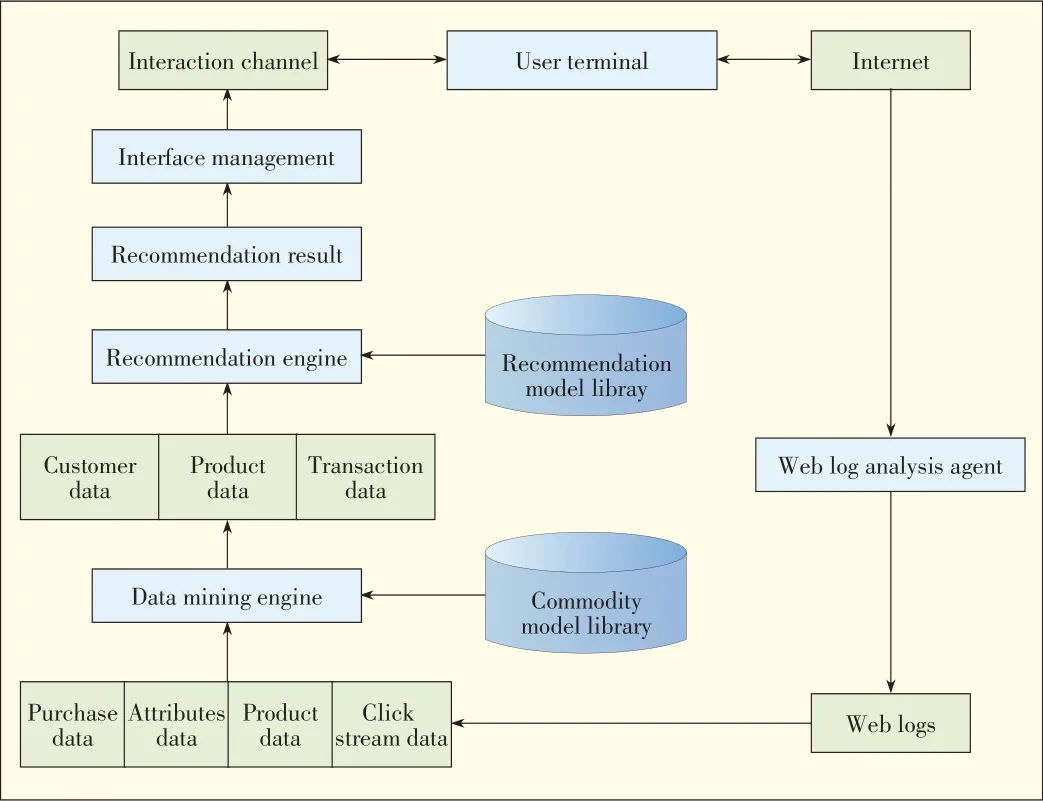
Fig.11 shows the typical architecture of a recommendation system,including the user operation database,data-mining en⁃gine,data warehouse,recommendation model library,recom⁃mendation engine,and user interaction agent.Together,these subsystems,databases,and basic operations provide users with personalized services.The main algorithms in a recommenda⁃tion engine are content-based filtering algorithm,collabora⁃tive-filteringalgorithm,and relevance-analysisalgorithm.
Social network analysis is a new concept for analyzing new problems.It is based on the relationships between members and provides the methods and tools for interactive data mining.It displays crowd-sourced intelligence and ideas and is impor⁃tant for social filtering,marketing,recommendations,and searching.Social network analysis involves user relationship,topic,interest,identification,influence,and emotion analysis.It also involves community discovery.
5 Prospectsof Big-Data Analytics
5.1 Representing and Understanding Multisourceand Multimode Data
Big data comes from different sources and comes in different formats.During preprocessing,different attributes of the data need to be determined for multidimensional description and al⁃so to improve explainability and flexibly so that analysis re⁃quirements are met.In the future,research needs to be done on semantic analysis,network data context resolution,and visu⁃al media analysisand learning.Theories and methodsof intrin⁃sic data representation and mapping from high-dimensional data space to low-dimensional manifold need to be developed toresolveand integrateheterogeneousnetwork data.
▲Figure11.Intelligent recommendation system architecture.
5.2 Low-Cost,Highly Efficient Data Storage Technology
The storage of big data affects not only the efficiency of data analysis and processing but also cost.With the emergence of big data,research into parallel data compression,distributed data de-duplication,thin provisioning,automated tiered stor⁃age(ATS),energy-saving,and freeing up of storage space needs to be done.This will reduce the storage pressure on serv⁃ers,increase transmission efficiency,improve data analysis,and reducecosts.
5.3 New Parallel Computing Model and Big-Data Architecture

▲Figure10.Search enginearchitecture.
Big data seriously affects computation and storage.Big data is so large that the existing computation methods and algorithms cannot compute within an accept⁃able timeframe.Therefore,new processing meth⁃odsarerequired.
With unstructured data processing and large-scale parallel processing,non-relational data analysis models have greatly improved search and analysis of mass internet data.Such models include MapReduce and have become commonplace for big-data analysis[20].Howev⁃er,MapReduce still has many performance prob⁃lems.To make parallel computation more effi⁃cient for big data,more effective and useful pro⁃gramming models and architectures need to be developed.Hy⁃brid programming models and architecture have already been developed.These include MapReduce[20],BSP[21],Message Passing Interface(MPI)[26],Compute Unified Device Archi⁃tecture(CUDA)[27],and shared-memory parallel program⁃mingand computation models[28].
5.4 Multidimensional and Multimode Data Mining and Knowledge Discovery
Big data includes multidimensional and multimode data.At⁃tributes and dimensions can be reduced in big-data mining to classify data nodes and measure data relevance and integration mechanisms.Data-mining algorithms can meet the special re⁃quirements of big data,expand the scope of data-mining appli⁃cations,and satisfy the requirements of users at different da⁃ta-mining terminals.Application-oriented data-mining algo⁃rithms should be developed according to the application envi⁃ronment and an understanding of semantics.With natural lan⁃guage processing and machine learning,knowledge derived from big data can be more practically used in commerce and science.
6 Summary
With the rise of social networks and the widespread applica⁃tion of cloud computing,mobile internet,and the internet of things,big data has become the focus of attention.There are various types of big data,and processing methods are becom⁃ing more complex.This has created many challenges.Tradi⁃tional data-processing architecturessuch asrelational databas⁃es and data warehouses struggle to process big data.Systems tailored to big data have distributed storage,MapReduce paral⁃lel computing,and data mining.However,these are in a fledg⁃ling state.To improve big-data analysis,research on represen⁃tation,measurement,and semanticsfor bigdatamust beunder⁃taken.The cost of storing big data should also be reduced,and flexible,highly efficient big-data computing architectures and data-mining algorithmsshould be developed.
Manuscript received:April 18,2013
Biographies
