一种基于语音识别的骚扰电话拨测系统
2013-05-15中国移动通信集团江苏有限公司网络部王玉申
中国移动通信集团江苏有限公司网络部 王玉申
现有骚扰电话治理中,存在的主要问题是:识别的号码数量多与客服拨测人员工作量大之间的矛盾。相比于目前通常采用的人工拨测方式,计算机自动处理有着速度快、效率高、误差率低等特点,尤其是针对重复内容的自动拨测和处理技术更是具有不可替代的作用。近年来,语音识别技术已经得到了长足的发展,通过引入语音识别技术对录音文件进行甄别,可以极大提高骚扰电话的拨测效率。
1 骚扰电话自动拨测系统构建
通过新增1套骚扰电话拨测识别系统,实现骚扰电话的自动拨测、识别、录音和取证功能。该系统与现有骚扰电话治理各系统间的关系如图1所示。
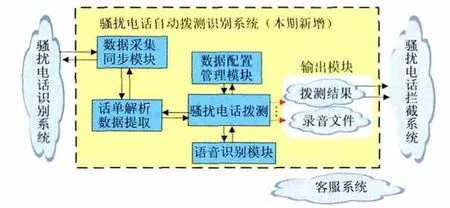
该系统通过文件接口从骚扰电话识别系统采集需要拨测的号码清单,对号码进行拨测、录音、语音识别,拨测结果输出到拦截系统和客服系统进行后续处理。通过骚扰电话自动拨测识别系统代替客服的人工拨测和审核,提升骚扰电话人工审核的效率和准确度,提高骚扰电话治理效果。
1.1 骚扰电话拨测系统处理流程
骚扰电话拨测系统的处理流程见图2。
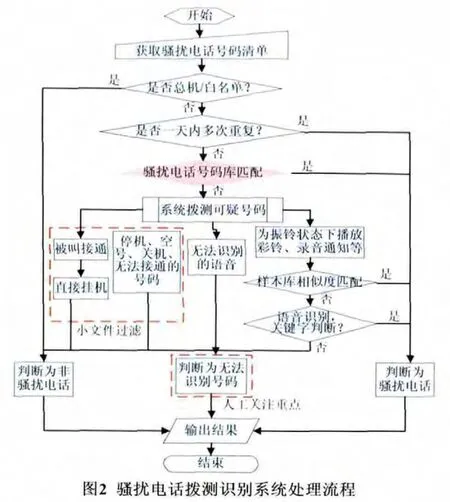
骚扰电话自动拨测识别系统的业务流程主要分为4步,分别是:待拨测号码的采集分析、对号码进行拨打呼叫、对骚扰电话的识别和判断、结果输出。
1.2 拨测系统构建
拨测录音模块设计了2个方案供选择:测试卡方案或模拟主叫号码方案。测试卡方案:利用自动拨测系统的拨测仪进行拨打。模拟主叫号码方案:利用自动拨测系统,采用PBX(专用小交换机)拨测设备进行拨打。
1.2.1 方案一 测试卡方案
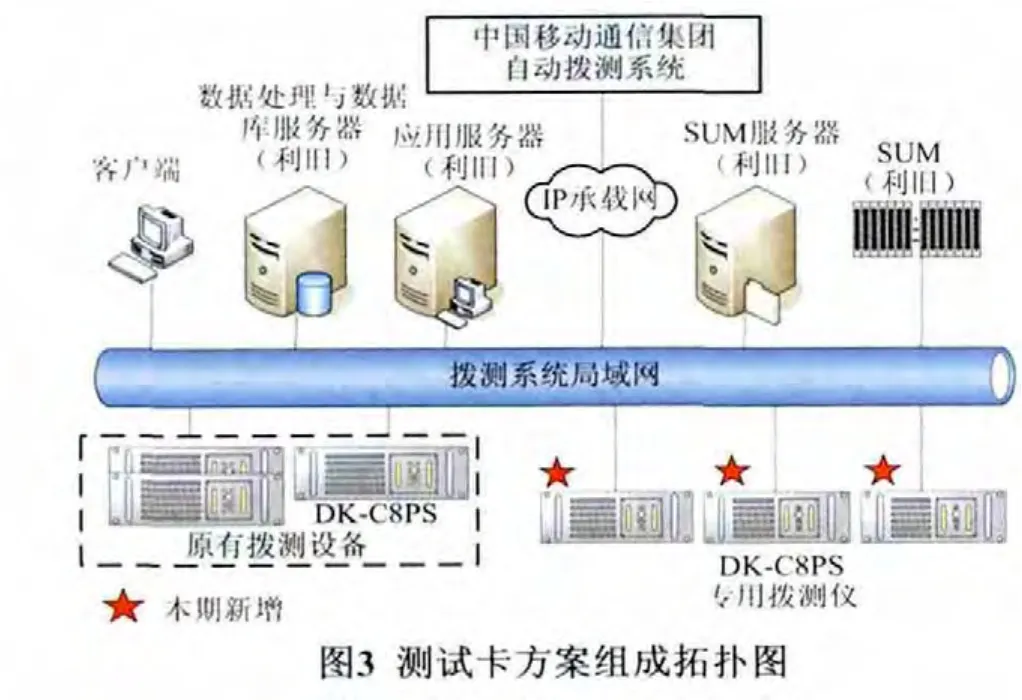
为满足多张本省和外省测试卡在拨测仪上进行测试,设计采用自动拨测系统上已配备的SUM(服务器集中监控管理)设备集中插放SIM(用户识别模块)卡,通过远程调用的方式实现SIM卡自动切换拨测,以达到测试的目的。系统构架图见图3。
1.2.2 方案二 模拟主叫号码方案
在现有自动拨测系统基础上,使用PBX中继拨测仪实现自动拨测与录音功能,以达到测试的目的。保持现网自动拨测系统网络结构不变,新增的专业拨测仪采用IP方式接入,接受自动拨测系统管理。组成拓扑见图4。
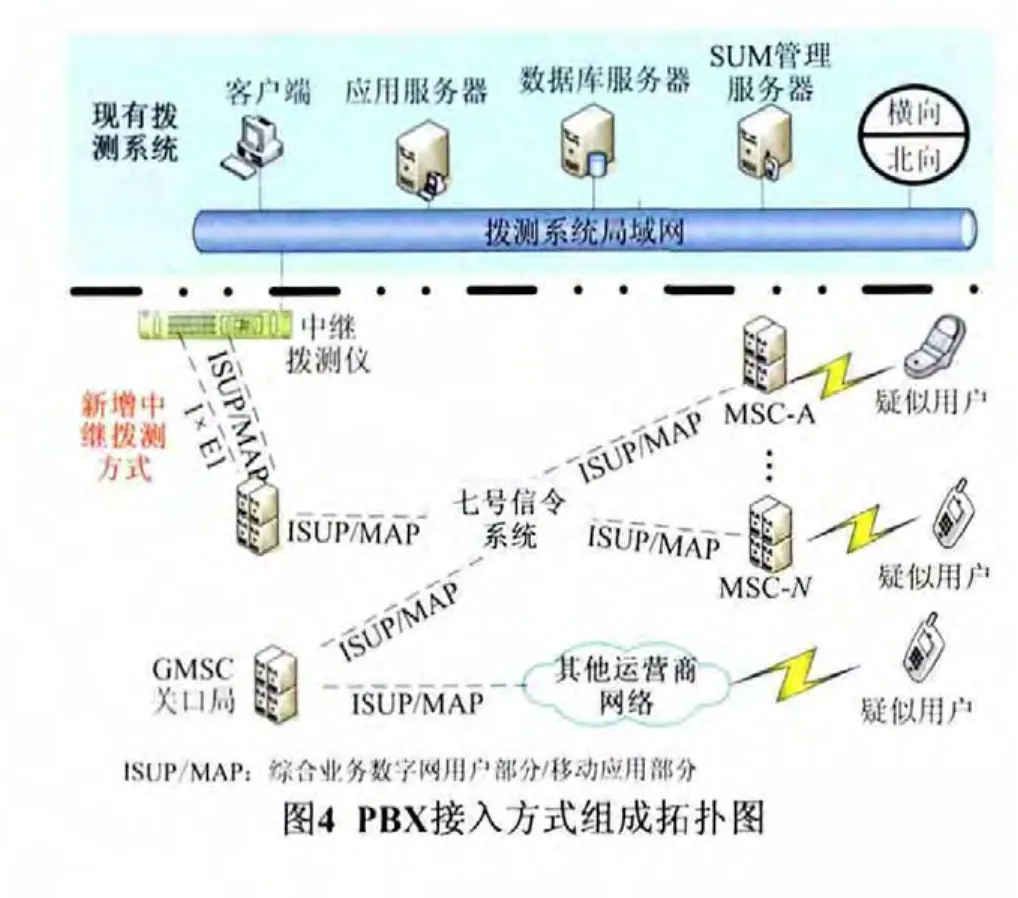
本方案中新增1台(PBX)中继拨测仪,通过TCP/IP(传输控制协议/网际协议)方式接入自动拨测系统,接受CMS(内容管理系统)的管理和维护。中继拨测设备通过E1中继专线方式连接汇接局或MSC(移动交换中心)、且与STP(信令转接点)间开链路。使中继拨测仪成为移动MSC下的一个专用PBX用户端局。通过汇接局或MSC可以实现与MSC、GMSC(网关移动交换中心)以及其他运营商网络的用户通信。为专用的E1(2.048 Mb/s数字同步传输)中继电路配置专用OPC(源信令点编码),并设置为免费,解决计费问题。
2 自动识别算法
为了提高骚扰电话拨测系统的识别准确率,降低骚扰电话误识别率,我们采用了多种组合算法进行骚扰电话的识别。具体的算法说明如下。
1)先进行较小文件过滤。通过对骚扰电话的录音分析,发现骚扰电话都有较长的通话时长(约30~100 s),录音文件也都比较大(起码大于800KB)。因此先将一部分较小的文件过滤掉(都是关机、停机、暂时无法接通等),这些小文件的几乎都可以确定都是非骚扰电话。获得较小文件大小的经验值为450KB,小于450KB的认为是非骚扰电话。
2)骚扰电话号码识别库过滤。骚扰电话号码识别库可以通过历史的自动拨测系统平台全国共享,避免同一个号码重复识别,节约系统资源,提高骚扰电话的判断效率和准确性。
3)PESQ(语音质量的感觉评定)过滤(过滤掉长时间的振铃、无人接听和来电提醒等)。参考文件为常见的非骚扰电话,score(ITU-TP.862)speech分数大于2,认为评估文件是非骚扰电话。
PESQ语音评估软件其本质就是一个相似度比对系统,原理是把无法自动判断的录音文件,比如怪异的接听应答音,先通过人为判定是否是骚扰电话,然后设取比对值,作为一个文件蓝本库保存。当下次拨测产生与之相似度高的录音文件时,自动判断成蓝本库所属内容,确定是不是骚扰电话。因此,随着不断的开展拨测工作,样本库文件会不断的丰富,最终的识别率也会不断提高。
4)语音识别。使用一系列常见的骚扰电话关键字进行识别,同时对正常带彩铃的号码进行识别。语音识别系统其本质是一套通过对录音文件中的关键字匹配来确认是否是骚扰电话的系统。关键字如“公证处”“抽奖”“中奖”“奖金”等,其内容库可以通过语音训练不断丰富,以提高最终的识别率。
语音识别软件采用定制的InterReco语音识别系统,是一款与说话人无关的语音识别系统,能够完成电话应用环境下的语音识别功能。定制的语音识别系统采用了ASR(自动语音识别)技术。它是一种使计算机能够识别人通过麦克风或者电话输入的词语或语句的技术。简单地说,就是能够让计算机听懂人说话。它的最终目标是使得计算机在不受词汇量限制,在各种噪声环境、语音信道下,能够实时、准确地识别不同方言、口音等特点的说话人的语句。包含了骚扰电话特征词,如:中奖、公证处、赌博、六合彩等。
由语音识别模块对经过“骚扰电话号码库”过滤的录音文件进行自动识别,判断出具有骚扰电话特征的录音文件,并判断为骚扰电话,随录音文件一起送至输出接口模块。语音识别中不符合骚扰电话特征的录音文件继续转交下一步处理。
5)PESQ语音再评估(语音识别的识别率只有70%~80%,还有20%~30%的疑似骚扰电话没有被识别出来)。我们对这些没有被识别出来的20%~30%的疑似骚扰电话进行PESQ语音评估,目的是提高被降低的语音识别漏判率。
3 应用情况
3.1 试点情况
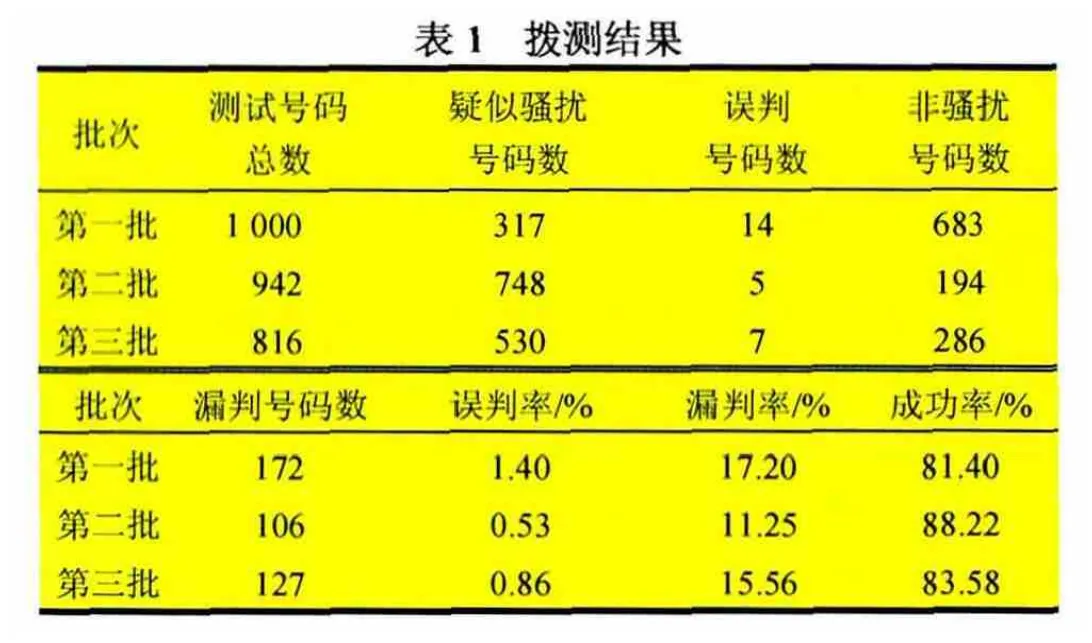
骚扰电话拨测系统于2013年3月底完成平台的搭建,实现了对骚扰电话的拨测测试。拨测系统初期对江苏移动提供过的三批共计2 758个骚扰电话样本做了识别判断,具体测试情况见表1。
?
采用基于语音识别的骚扰电话拨测系统对1 000个号码进行拨测和识别,需要的时间约为20min,存储空间约为12GB,大大提升了骚扰电话的人工审核效率。同时,对于无法确认的号码输出拨测录音,供客服人员人工判断,有效解决了部分号码无法通过系统进行识别的问题。
我们把完成1~5项步骤的判断机制定义为“模式一”,把仅完成1~3项步骤的判断机制定义为“模式二”。模式一是对模式二识别出来的疑似骚扰电话号码再进行一次语音识别和PESQ再评估,目的是降低误判率,而语音识别和PESQ再评估没有100%地将骚扰电话识别出来,因此,漏判率增加了。
模式二的思路是排除非骚扰电话,剩下的认为是骚扰电话;模式一的思路是排除非骚扰电话,剩下的进行语音识别和PESQ再评估,识别出来的是骚扰电话,没有识别出来的是非骚扰电话。因此,模式一比模式二误判率低,漏判率高。
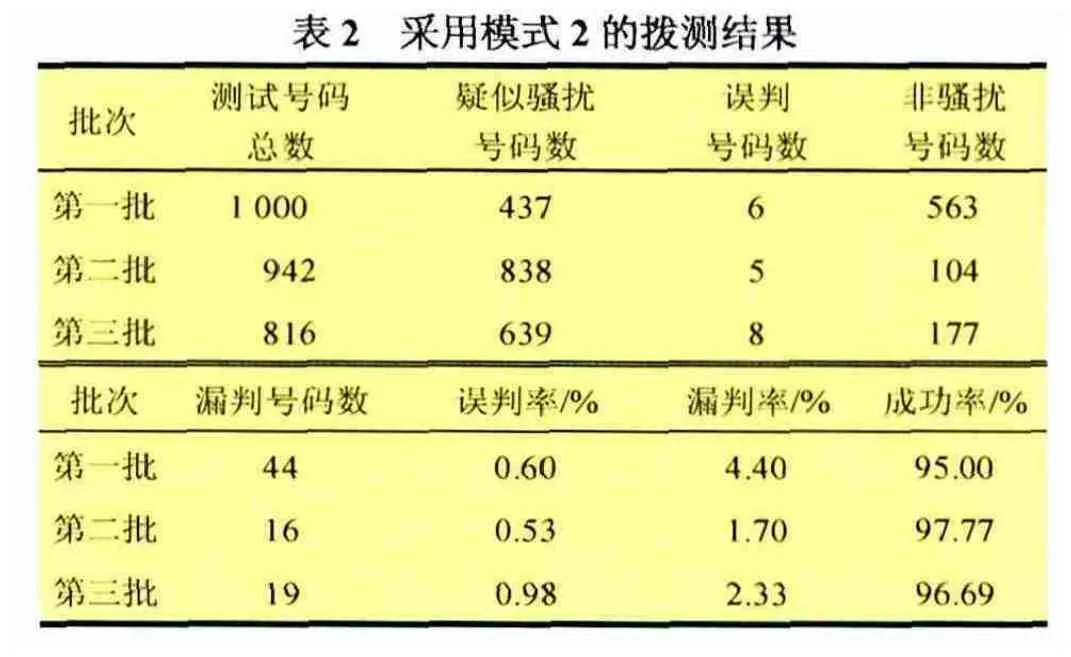
在实际使用中,可能还会存在正常带彩铃的录音文件,这个必须要借助语音识别系统来判断,所以说必须要用模式一的判断机制来进行拨测。当然模式二的测试结果给了我们一些参考,比如在测试当中发现和论证了这样一个问题:模式一比模式二误判率低,漏判率高。如果不使用语音识别软件(即模式二),漏判率反倒有明显的降低。结合上述三批测试,模式二测试情况见表2。
?
经过反复比对和论证,查明的原因是:第三方的语音识别软件本身也存在一定的不足,语音识别率只有70%~80%,即使我们已经通过PESQ语音评估进行补漏,也不能达到100%的识别率,会漏掉很多的骚扰电话,只能不断来优化完善它,后续需不断进行改进。
3.2 试点结论
从理论上分析,使用语音识别后可以减少误判的发生,随着语音识别软件的日益完善,这方面的效果会越来越得到体现。本着尽可能减低骚扰电话误判率(为此可以牺牲部分的漏判)的原则,体现真实的判断效果,且正确判断正常带彩铃的号码,建议继续使用语音识别系统,即模式一这样的全程判断机制来做骚扰电话拨测。
4 其他应用领域
基于语音识别的骚扰电话拨测系统,除了能够准确识别骚扰电话外,还可以广泛应用于基于语音识别的语音拨测系统,如:来电提醒系统的拨测、10086客服系统的拨测等,从而极大地提升系统拨测的效率,提高系统的运行稳定性。 ◆
