CBTCCBTC综合测评技术的研究
2013-05-09李达明闫友为北京全路通信信号研究设计院有限公司北京100073
吴 昊 李达明 闫友为(北京全路通信信号研究设计院有限公司,北京 100073)

吴昊,男,硕士毕业于清华大学,工程师。主要研究方向为铁路通信信号,曾参与“CTCS-3级列控系统综合设计集成平台”、“CTCS-3级列控系统研发试验—C3列控实验室研究与测试”、“C3综合测评系统”、“列控系统优化技术研究”等项目工作。
作为CBTC设计开发和集成实施的重要环节,测试能够在系统设计、集成研究、工程实施以及运营维护等系统开发全生命周期中的各个阶段提供对CBTC系统功能的验证支持。然而在测试过程中将产生大量繁杂多样的数据,人工进行测试分析需要耗费大量的人力,占用不少的时间,直接影响了测试的效率,并且人工分析难免会出现失误和不全面,对测试评价的准确性和全面性有较大的影响,直接影响到对整个CBTC系统的评价。因此研究针对CBTC的综合测评技术,利用计算机辅助的手段,将测试分析的方法、知识和经验软件化,辅助人工快速、准确发现CBTC系统测试和运行过程的问题,并对CBTC系统进行综合评价,是解决这一问题的有效途径。
专家系统是人工智能技术与具体应用学科相结合的产物。它能运用知识进行推理,在问题所在的领域内推导出满意的答案[1-2]。一个专家系统,一般应该具备以下几个功能。
1)知识的表示:[3-4]即寻找领域知识与计算机表达之间的映射方式和途径。比较常用的知识表示方法有:谓词逻辑表示法、产生式规则表示法、语义网络表示法、框架表示法和基于本体的知识表示法[5]等。
2)知识的推理:即根据一定的原则(公理或规则)从已知的事实(或判断)推出新的事实(或另外的判断)的思维过程。专家系统的推理是建立在知识库中存储的大量领域知识的基础之上的,即是基于知识的。使用专家系统的过程就是对知识库中的知识进行选择和运用的思维过程[2]。
3)输入数据的预处理:即通过对输入专家系统数据的处理,解决数据丢失、数据不完整、数据间不一致、数据错误等问题,提高输入数据的质量,使推理过程更加有效和容易[2]。
针对CBTC的综合测评技术既具有一般专家系统技术的特征,又具有与CBTC系统领域知识相关的特殊属性。传统的专家系统技术在应用于CBTC系统时,存在以下问题。
传统专家系统通常采用某一类方法对领域知识进行描述。而CBTC系统结构复杂,信息类别繁多,很难单独用某一类知识表示方法对CBTC系统的所有领域知识进行描述,必须针对不同类型的领域知识,采用不同的知识表示方法进行描述。
2)推理机制的通用性要求低,专用性要求高。
传统专家系统为了满足在多领域中的通用性,对推理机的设计考虑了各种前提和可能发生的情况,采用了传统的模式匹配算法如Rete算法等。这样的设计使系统获得了很大的通用性,但也带来了推理效率不高等缺陷。CBTC综合测评不存在对其他领域支持的需求。因此,需要以提高推理效率为目标,对传统推理机制进行取舍和改进,使其适用于CBTC系统。
3)数据量巨大,数据来源多样,数据预处理需要有效提高输入数据的质量。
传统专家系统获取的输入数据通常来源于同一个途径,其数据量也相对不大。CBTC综合测评面向的是CBTC系统的数据,这些数据来源于不同的监测途径,而且数据量巨大,周期性数据和非周期性数据共存。因此,在数据进入推理机前,有必要对其进行甄别和筛选,剔除冗余和无用的信息,保留有用信息,否则推理机的效率会受到极大影响。
鉴于传统专家系统技术在应用于CBTC综合测评时存在以上所述的问题,本文基于传统专家系统技术,并对其进行改进和创新,提出了一种针对CBTC的综合测评技术,包括数据预处理技术、知识表示与规则提取技术、推理机技术,重点讨论基于传统专家系统实现的改进和创新。
肿头龙生活在距今7000万年至6600万年前的白垩纪晚期的北美洲。肿头龙与许多恐龙生活在一起,其中就包括了霸王龙、三角龙、甲龙、埃德蒙顿龙、似鸵龙等。霸王龙是肿头龙生存世界中的绝对王者,它能毫不费力地猎杀肿头龙。不过,生性机警、奔跑迅速的肿头龙是很难被捕捉到的。
1 CBTC综合测评技术
1.1 数据预处理技术
针对CBTC系统数据的特征,可以使用数据清理、数据集成、数据变换和数据规约等数据预处理技术,在推理之前对数据进行适当的预处理,以减少推理所需要的时间,提高综合测评的总体质量。
数据清理首先检测数据的各种偏差,包括数据退化(如数据发送、接收方不明确)、数据表示及编码不一致(如数据中时间戳格式不一致)、数据重复等,然后使用定义的一系列变换来纠正偏差,如将数据中时间戳变换成统一格式、根据数据的其他属性内容来填写已经退化的属性值、过滤重复数据等。
数据集成是将来自于多个数据源的数据进行合并。代表同一个概念的数据属性在不同的数据中可能有不同的名字,这将导致不一致性和冗余。这种命名的不一致还可能出现在数据属性的值中。数据大量冗余和不一致可能降低推理过程的性能或使之陷入混乱。因此需要定义关于各数据属性性质的知识,即数据属性的元数据,来避免模式集成的错误。每个数据属性的元数据包括名称、含义、数据类型、允许取值范围、空值规则等。
数据变换将数据转换或统一成适合于推理的形式。数据变换的主要内容如下。
1)数据聚集:对数据进行汇总或聚集。
2)数据泛化:使用概念分层,用高层概念替换低层或“原始”数据。分类的数据属性,如数据中的逻辑区段锁闭状态、区域控制器(Zone Control, ZC)发送给联锁的逻辑区段状态等类型的数据,其消息类型就可以映射到较高层概念,如逻辑区段;又如数据中联锁发送给ZC的进路消息,道岔的状态属性以两位原始数据00、01、10、11表示,也可以泛化为较高层的概念,以道岔定位、反位、故障来表示。通过这种数据泛化,尽管细节丢失了,但是泛化后的数据更有意义。
3)特征构造:由给定的属性构造新的属性并添加到数据的属性集中,以帮助提高准确率和对高维数据结构的理解。
数据归约通过聚集、删除冗余特征等方法来减小数据规模。用于推理的数据集太大,会降低推理的速度。数据归约技术可以用来得到数据集的归约表示,它虽然小得多,但仍接近保持元数据的完整性。这样,对归约后的数据集进行推理将更有效,并产生相同的测评结果。
此外,为了提高数据预处理的效率,可以对数据预处理过程进行并行处理。对于接收到的数据,首先进行统一的数据清理。这是因为数据清理与输入数据的类型无关,只是对数据错误、数据属性退化、数据表示不一致、数据重复等进行处理;并且只有通过数据清理,才能正确地按照某种规则对数据进行分发和并行处理。数据清理之后,根据数据的类型等属性,将数据分发到不同的并行预处理单元。每个并行预处理单元都有一个待处理的数据队列。并行预处理单元从队列中依次取出数据,对数据进行数据集成、数据变换和数据归约。
1.2 知识表示技术
可以采用两种知识表示方法对CBTC系统的领域知识进行完整的描述:
1)产生式规则表示法;
2)面向对象表示法。
产生式规则表示法是根据产生式规则来表述知识的方法,其基本形式为:“IF P THEN Q”,其中P为产生式的前提条件,描述了结果产生所依赖的条件,Q是当前提条件成立时得出的结论。产生式规则能够将知识形式直观、自然地表现出来,而且每条规则都具有相同的形式,方便知识的增加,删除和修改,推理时哪一个条件不成立在推理时清晰可见,能及时反映当时的情况。对于不具备时序性的领域知识,例如有源应答器报文规则,始终可以根据系统当前某些条件或条件的组合推导出固定的结论,这些结论并不依赖于系统的历史状态,因此使用产生式规则表示法可以很好地对CBTC系统中的这类知识进行表示。
然而对于具备时序性的领域知识,系统输出不仅依赖于系统的当前状态,还与系统的历史状态有关。这类领域知识的载体无法采用“IF-TH EN”的形式来实现,而需要载体里包含系统的某些历史状态。系统当前的某些状态数据与载体里历史状态数据进行某些逻辑、算数运算,进而得到预期结论。这些载体里需要包含“数据”和“行为”,因此,适合采用面向对象表示法对这类领域知识进行描述。
1.3 推理机技术
针对CBTC的综合测评,具有实时和大量推理需求的特点,传统推理技术的推理效率会成为系统性能的一个瓶颈。为此,在CBTC的综合测评中,采用以下3种方式提高推理效率:
1)迭代推理规避
传统的推理机对于迭代推理的需求来源于当前的推理“结果”可以作为“事实”进入推理机进行下一次推理,多用于各规则间存在因果关系的专家系统。而CBTC系统由于各领域知识相互独立,且采用1.2节所描述的两种知识表示技术使得各规则之间没有直接联系,因此,推理机不用将推理“结果”作为“事实”进行迭代推理,有效降低了推理机设计的复杂程度,提高了推理效率。
2)模式匹配学习
对于采用产生式知识表示法描述的规则,假设一个包含n个条件和K条规则的规则集,通过对n个条件状态的判断在这K条规则中找到满足条件的结果。如果不进行模式匹配学习,则搜索的时间复杂度为O(n)。实际上对于CBTC的测评,前后两次推理通常并非所有n个条件都发生改变,因此可以“学习”前次推理的模式匹配过程,即只对改变了的条件重新进行搜索,这样可以避免对不必要条件的搜索,减小时间复杂度。此外还可以通过“学习”各条件发生变化的概率,按照概率从小到大的顺序排列条件,进一步减小时间复杂度。
3)事件注册机制
对于采用面向对象知识表示法描述的规则,如果每次推理都对规则库进行遍历,虽然可以保证所有满足条件的规则都被触发,但是会造成众多不满足条件的规则被再次遍历,导致推理效率降低。采用该类知识表示法描述的规则,其触发条件是输入事件,只有当新的输入事件产生,才会进行推理;而且,每类输入事件通常只会触发一小部分的规则,如果推理机仅对这一部分规则进行遍历,将大大缩短每次推理所用的时间。为此,对于每条规则,采用事件注册机制,预先对每类输入事件可能激活的规则进行注册。这样,当新的输入事件产生时,推理机首先根据事件类型在注册表里找到可能激活的规则,然后对这些规则逐一进行模式匹配,匹配成功的规则将执行。这样的设计使得推理机不再遍历不满足触发条件的规则,极大地提高推理效率。
另外,由于传统推理技术通常只适用于由某一类规则组成的专家系统。而对于由多种类型规则混合组成的专家系统,现有技术的缺点在于推理机对外接口难以统一,输入输出数据的内容、格式等与规则库类型产生耦合。为了消除这一影响,有必要对推理机的结构进行重新设计,解除输入输出数据与内部规则之间的耦合,保持推理机对外视图的一致性。
采用产生式知识表示法或面向对象知识表示法描述的规则进行推理,其过程遵循以下步骤:“输入事件→模式匹配→产生预期结果→验证结果→测评结论”,两种知识表示方法唯一的不同在于模式匹配阶段。因此,在设计推理机的结构时,将变化的部分与不变的部分分离,最大程度地保持各设计模块对于由两种知识表示法描述的规则的通用性。
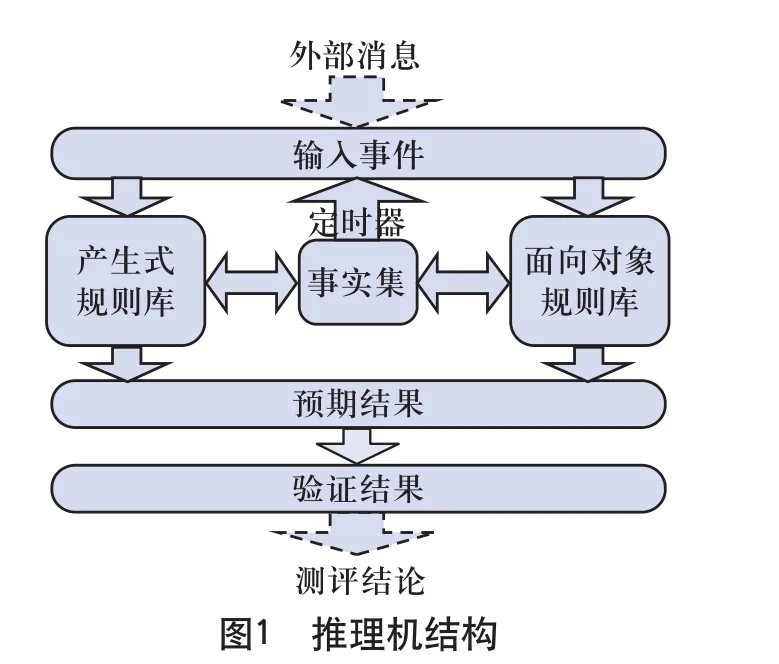
在图1所示的推理机结构中,推理机不断扫描外部消息和内部定时器,当有外部新消息输入或事实集里有定时事件产生时,便将其作为输入事件,发送给对该类型事件注册过的规则集。规则集根据规则的类型进行推理,推理完成后,更新与规则相关的事实集部分。如果推理过程中模式匹配成功,则产生预期结果,放入预期结果存储区。然后,推理机不断扫描预期结果存储区,对比预期结果和已有的监测数据或将要到达的监测数据,得出测评结论。从上述推理过程可以看出,图1所示的推理机与外部系统的接口不依赖于规则库的构建方式,因而具备较强的适用性。
2 应用讨论
应用CBTC综合测评技术可以实现对CBTC系统测试和运行过程的综合评价,可以节省测试验证过程中的人力和时间,提高测试验证中各类问题的发现率,全面、准确地对CBTC系统的功能进行综合评价。在未来,通过进一步的研究和开发,CBTC综合测评技术可以进一步服务于CBTC系统的后期运营维护中,为CBTC系统的持续优化提供扎实的技术支撑。
[1] 金聪. 人工智能教程[M]. 北京: 清华大学出版社, 2007.
[2] Giarratano,Joseph C,Riley, et al. Expert Systems Principles and Programming[M]. 北京: 机械工业出版社, 2006
[3] 徐宝祥, 叶培华. 知识表示的方法研究[J]. 情报科学, 2007(05):690-694.
[4] W.L. Xu, L. Kuhnert, K. Foster, et al, Object-oriented knowledge representation and discovery of human chewing behaviours[J].Engineering Applications of Artificial Intelligence, 2007(20):1000-1012.
[5] 邓志鸿,唐世渭,张铭,等. Ontology 研究综述[J].北京大学学报:自然科学版, 2002, (5):730-738.
