一种基于抽样统计改进的CHOKe算法
2013-04-29李学锋郑毅
李学锋 郑毅

摘 要: 对流行的几种CHOKe算法进行了分析,深入研究了CHOKe算法存在的对高速非适应流的处罚力度不够,不能够很好地实现带宽的公平性的问题。利用到达分组的统计特性,提出一种改进的CHOKe算法,仿真结果表明,在不保持流的状态信息下,该机制对非适应流具有更好的识别和控制能力,与其他CHOKe算法相比,能进一步加强对非适应流的惩罚,实现更为公平的带宽分配。
关键词: 主动队列管理; CHOKe; 非适应流; 公平性
中图分类号:TP393 文献标志码:A 文章编号:1006-8228(2013)08-49-03
0 引言
目前Internet网络拥塞控制的主要方法是采用端到端的TCP拥塞控制与中间结点(路由器)拥塞控制相结合的方法[1]。端到端的TCP拥塞控制根据网络的丢包情况来判断网络的拥塞情况,从而调整源端的发送速率,从源头来控制进入网络的包的数量;中间结点的拥塞控制主要依据既定的策略对包进行丢弃,以达到对网络的拥塞控制。
随着非响应流在Internet所占比例的增加,中间结点的拥塞控制在整个拥塞控制中占的比重也随之增加,中间结点拥寒控制算法越来越多地受到人们的关注。CHOKe[2]作为一种工作机制其相对简单、实现容易的无状态的中间结点拥塞控制算法受到人们的青睐,但如何进一步提高其对非适应流的识别的精确率,实现转发流公平性成为当前研究的热点。本文在深入分析现有的CHOKe各种算法基础上,提出一种新的改进的CHOKe,并通过NS2模拟验证了此算法对各流的公平性与对非适应流的精准性的效果。
1 CHOKe算法及其发展
CHOKe(choose and keep for responsive flows, choose and kill for unresponsive flows)算法是一种基于RED的改进算法,是一种完全无状态的近似公平的队列管理算法,即无需保留任何流的状态信息就能实现一定公平的主动队列管理算法(AQM)。当前CHOKe主要有B_CHOKe、M_CHOKe、A_CHOKe和LA_CHOKe等版本。
B_CHOKe算法:即基本的CHOKe算法,当一个分组到达时,就随机从当前队列中取出一个分组与之比较,如果二个分组都属于同一个流,就同时丢弃这两个分组;否则对将取出的分组放回队列中,对刚到达的分组根据当时的拥塞水平计算丢弃概率(该丢弃概率的计算与RED算法相同),再按该概率对到达的分组进行丢弃。
M_CHOKe算法[3]:在B_CHOKe算法的基础上,加大了从当前队列中取出的分组的个数,即增加了比较次数。M_CHOKe算法从当前的队列缓存中取出m(m>1),将所有的m个分组与刚到达的分组进行比较,若有与刚到达的分组有相同的流ID则丢弃。事实上,B_CHOKe算法是M_CHOKe算法当m=1的特例。
A_CHOKe算法[3]:由于CHOKe的完全无状态的设计,事先并不能知道有多个非适应流,比较难以选取合适的m参数,为此CHOKe还有一种自适应改进类型,即A_CHOKe算法,该算法将minth和maxth之间划分为k个区间,分别标记为R1,R2,…,Rk。当平均队列长度位于不同的区间时,就选择不同的m值。比如,当平均队列长度位于Ri区间时,m=2i。当平均队列长度越长,则比较的次数越多,从而能够自适应地提高CHOKe算法识别出非适应流的能力。
ECHOKe算法[4]:在M_CHOKe的基础上加大了对非适应流的惩罚力度,将m个分组中与到达分组的流标识匹配,若匹配,将所有匹配分组及到达分组都丢弃;若匹配不成功,将m个分组中的流标识相同者最大者(大于1)的一个分组丢弃。
S_CHOKe算法[5]:按间隔时间T对到达的分组进行采样,将采样分组的流标识放入采样列表,对每一个到达的分组,先从采样列表中随机抽取一个流标识进行比较,若相同,则认为是采样击中,然后再与路由器队列中m个分组相比较,若再次一样,则称为队列击中,删除击中分组。S_CHOKe算法以采样击中来代替提高击中概率。
对上面的算法进一步分析,发现存在以下的不足。
⑴ B_CHOKe算法采用只比较一次,当网络中流较多时,公平性与惩罚力度都会下降。
⑵ M_CHOKe算法与A_CHOKe算法通过增加比较的次数,提高了击中概率,在击中精度方面仍存在问题。同时也只是丢弃一个分组,惩罚力度也不够大;另外,m个分组是从整个队列中随机抽出,没能充分体现网络数据包的突发性,同时也没有充分地利用抽出的m个分组的统计信息来进一步加大对非适应流的识别精度。
⑶ ECHOKe将m个分组中击中的所有分组全部丢弃,在增加了非适应流分组丢弃概率的同时,也增加了适应流的丢弃量。而适应流具有源端响应机制,一旦发现丢包,就会降低发送速率,从而更加不利于公平。因此,ECHOKe的惩罚精度不理想[6]。
⑷ S_CHOKe算法单独设置的采样队列中存放的是到来分组的流ID的采样,反映的不是路由器输出队列的统计特性,按照采样击中而进行的丢弃,也就不能体现路出器输出的公平性,同时单独设置的采样队列也占用了路由器的内存。
2 改进的CHOKe算法
针对现有CHOKe的不足,我们提出一种基于抽样统计的改进方案——N_CHOKe,算法流程如图1所示。
N_CHOKe算法的基本思想:路由器FIFO的平均队列长度计算与RED相同,维持最小门限minth和最大门限maxth两个阈值。当平均队列长度小于minth时,新到达分组直接进入到FIFO队列中;当平均队列长度大于maxth时,丢弃新到分组;当平均队列长度在minth与maxth之间时,从现FIFO队列中的minth处到当前实际队列结尾处这一段按照一定的间隔抽样出m个分组,并统计出这个m个分组所属的流k,以及这k个流包含的分组数。
将新到分组与k个流进行比较,比较结果如下。
⑴ 如果击中,且被击中的流的分组数大于等于[m/k]时,丢弃新到分组,并丢弃被击中流中的一个分组;其余分组返回队列。这样做的目的是既要提高对高速非适应流的识别精度,也要在一定程度上加大对非适应流的惩罚力度。如果被击中流的分组没有超过[m/k],则到达分组按照RED计算丢弃概率,并进行相应的处理。
⑵ 如果没有击中,新到达分组按照RED计算丢弃概率,并进行相应的处理;且查看k个流的分组长度,如果k个流中有分组数量大于或等于2倍[m/k],丢弃此流的最后的一个分组。
与以往的其他CHOKe算法相比,N_CHOKe算法主要引入了以下三点措施。
⑴ 抽样分组的区间的改变。抽样分组将从队列的minth处到队列结尾(缓存区满)之间抽取,将此区间分成K个小区间,当前平均队列长度位于区间i时,m=2i。m个分组从minth处到当前队列长度处抽样得到,这样可以更好地反映网络数据的实时特性。
⑵ 通过统计抽样出的m个分组所属流,以及每个流所有的分组个数,充分地利用抽样分组的统计特性,只有击中的流的分组数目大于等于平均数时,才认为本次击中是有效的,即是击中了非适应流,这样加大击中非适应流的准确性,减少误击中适应流的比率。
⑶ 当没有击中时,通过将分组数目大于等于2*[m/k]的流丢弃一个分组,来加大对非适应流的处罚。
3 仿真试验与性能分析
为了验证N_CHOKe算法的有效性,在NS2仿真软件上进行仿真实验,对CHOKe、M_CHOKe、ECHOKe、SCHOKe和N_CHOKe进行性能比较。仿真实验的网络拓扑如图2所示。
S1--Sn为发送端,D1--Dn为对应接收端。所有发送端到R1之间的链路与R2到接收端之间的链路的带宽为10Mbps,延时为10ms。R1与R2之间的链路带宽为1Mbps,延时为10ms。分组大小500字节,队列参数minth=100,maxth=300,缓冲队列长度为500。
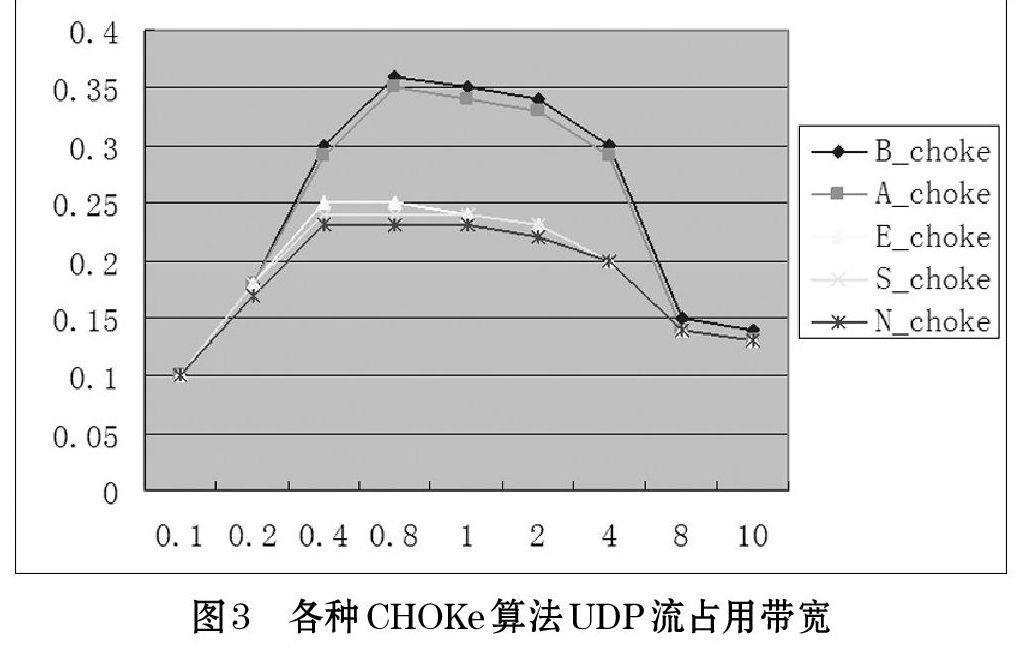
本次实验选择9个TCP发送流,发送速率为0.1Mbps的FTP流;1个UDP流,UDP流的速率依次为0.1Mbps、0.2Mbps、0.4Mbps、0.8Mbps、1Mbps、2Mbps、4Mbps、8Mbps、10Mbps,每个速率持续发送10s。观察当UDP速率逐渐提高的情况下,R1与R2间的带宽分配情况。
通过仿真分析,得到各种UDP流实际占用带宽如图3所示,从图3中可以看出,本文提出的N_CHOKe算法在TCP流与UDP流共存的情况下,对于公平性有了较大的提升。
4 结束语
本文在研究了现有的多种CHOKe算法的基础上,提出了一种更加有效的N_CHOKe算法,此算法针对非适应流的特点,调整了取出分组的区域,重新设计了分组的丢弃策略,在保护适应流的同时,增加了对非适应流的识别精确度与惩罚力度,更好地分配了网络资源,提高了网络上各流之间的公平性。通过NS2进行了模拟实验,结果显示N_CHOKe算法提高了网络上各流之间的公平性。
参考文献:
[1] 曾振平,汪秉文.因特网拥塞控制的公平性研究综述[J].计算机科学,2008.35(1):19-23
[2] BRANDEN B, CLARK D,et al. Recommendations on Queue Management and Congestion Avoidance in the Internet[S].IETF RFC 2309,1998.
[3] PAN R, PRABHAKAR B, PSOUNIS K. CHOKe: A stateless active queue management scheme for approximating fair bandwidth allocation[A]. Proceedings of IEEE INFOCOM2000[C].Piscataway:IEEE Press,2000.2:942-951
[4] 王建新,周雄伟,杨湘.一种惩罚非适应流的无状态主动队列管理算法[J].系统工程与电子技术,2006.28(12):1935-1939
[5] 龚静,吴春明.S_CHOKe:一种增强CHOKe公平性的主动队列管理算法[J].电子学报,2010.38(5):1100-1104
[6] 姜明,边浩,陈勤.HCHOKe:改进的公平主动队列管理算法[J].计算机工程,2010.36(10):115-116
