基于Bloom Filter的云内容路由优化
2013-04-25金逸超尹丽英
俞 冶,金逸超,尹丽英
(1.嘉兴市广播电视集团 总工程师办公室,浙江 嘉兴314001;2.南洋理工大学,新加坡639798;3.西安邮电大学 经济管理学院,陕西 西安710121;4.西安电子科技大学 经济管理学院,陕西 西安710071)
随着全媒体时代的来临,媒体内容分发经历了从模拟到数字,从标清到高清,从信息孤岛到互联互通的一系列重大革新。当前,媒体业务系统的IT化程度越来越高,用户对于媒体互联互通业务需求的不断增长以及国家三网融合战略的高速推进,传统广电业务系统低效、响应时间长、可扩展性差等问题也逐渐暴露出来。在此背景下,云计算技术与广电业务系统的结合,媒体云已成为实现广电媒体内容的弹性部署、高效分发的必经之路[1]。系统的建设目标为,使媒体内容的管理与分发,能够按需分配、灵活调整、高效运行。
在构建媒体云的过程中,如何进一步改善用户的响应时延是必须考虑的因素。媒体内容响应时延的长短将直接决定终端用户的体验,并最终成为用户是否认可并购买媒体云服务的依据。本文以此为目标,考虑在广电混合云环境下,提出利用全局Bloom Filter优化媒体云网络中的内容路由。在此基础上,提出两种优化路由设计,使得用户的平均响应时延得到有效下降。
文中将从理论推导和仿真实验两方面,对所提出的方案进行验证。在理论上,采用Jackson排队网络对传统以及优化后的路由策略进行系统建模。在仿真实验中,使用OMNeT++[2]网络仿真器对路由策略进行仿真。其结论与仿真结果的一致性良好。
1 基于全局Bloom Filter的路由设计
1.1 广电云内容分发系统架构
典型的广电音视频云系统如图1所示,主要包括位于省广电总台的广电云数据中心,以及分散在各个地市县的小型内容分发节点构成的内容分发网络。广电云数据中心包含集群式的虚拟化主机群,以提供基于存储区域网络(SAN)的媒体数据海量存储,以及强大的云计算资源用于媒资信息的高效与弹性管理。广电内容分发网络则用来备份与存储媒体内容到靠近终端用户的地市县广电分发节点[3],从而缩短媒体内容与用户间的距离,提升用户体验。基于此系统架构,位于不同地理位置区域的用户均能得到一致的、低时延的、快速响应的用户媒体内容服务。

图1 广电云内容分发系统架构内容分发
基于现有的广电云内容分发系统架构,本文将研究如何通过改善内容分发策略,从而进一步减少用户响应时延,提升用户体验。并将首先分析广电云内容分发进程的排队网络模型。在此基础上,讨论基于分布式哈希表(DHT)的传统内容路由策略,同时给出了两种利用Bloom Filter的新型内容路由策略。
1.2 媒体云内容分发队列分析
媒体云内容分发过程主要涉及到4个不同功能的处理与执行队列如图2所示,其中3个队列路由队列、检索队列以及响应队列,位于每个内容分发节点上;此外,还有位于媒体云数据中心的内容提取队列。路由队列主要负责将特定的用户请求路由到特定的内容分发节点,在基于DHT的内容路由策略中,节点和内容会被哈希到同一个数据空间,根据内容和节点的哈希值匹配映射,每个节点将会服务特定范围的内容请求。本文用μij标识为从内容分发网络入口节点i路由到负责该请求分发节点j的处理速率。当内容请求达到该节点时,检索队列则负责本地检测所请求的内容是否已被分发节点缓存。标识μl为分发节点的内容检测速率。若请求内容已被缓存,则请求直接进入响应队列,以服务用户请求。标识μr为内容分发节点的请求响应速率。若请求内容未被缓存,则分发节点将首先向后端数据中心请求提取数据,该请求将进入数据中心的内容提取队列,待分发节点得到该内容后,再响应用户请求。标识μo为数据中心的请求响应速率。

图2 媒体云内容分发网络的排队网络模型
1.3 传统内容分发路由策略
基于所给出的排队网络模型,给出了传统的线性内容路由策略的数据流分析,如图3所示。在该策略中,用户请求首先以一定的速率λ到达距离最近的内容分发节点。在完成路由后,节点进行本地内容检测,并根据是否缓存当前请求内容的情况,决定是否需要从数据中心获取请求内容。若缓存(cache)命中,则直接返回请求内容;否则缓存丢失,该节点将向数据中心获取请求内容。最终,指定节点才对用户请求做出响应。
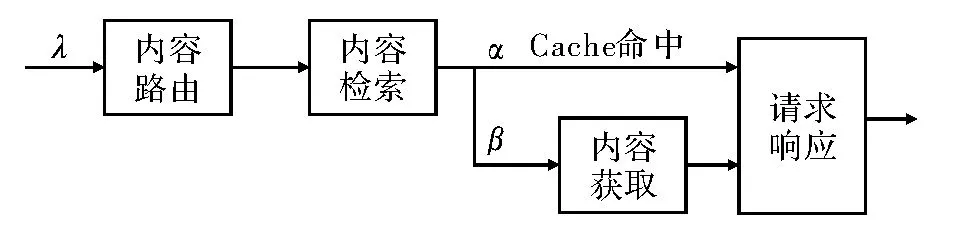
图3 传统线性内容路由策略
1.4 利用Bloom Filter优化内容路由策略
1.4.1 基本思路
从对传统线性路由策略的分析中可发现,由于入口节点并不知道用户所请求的内容是否已经存在于内容分发网络中,因此,大部分时间将被消耗在内容路由和内容检索的过程中。
基于此判断,本文提出利用一个由所有内容分发节点共同维护的全局Bloom Filter[4]来标识已经缓存在网络中的内容信息,从而使得每个内容分发节点都能够了解整个网络中内容缓存的情况。这样,在内容没有被缓存的情况下,内容分发节点可直接将用户请求告知数据中心,从而减少整个用户响应时延。即根据内容获取的方式不同,将提出两种新型的内容路由策略,并行式路由和直通式路由。
1.4.2 并行式路由
并行式路由策略的数据流分析如图4所示。当用户请求在进入第一个内容分发节点时,即根据Bloom Filter的标识,来判断所请求的内容是否已被缓存。若缓存命中,则按照与传统路由相同的策略,依次进入内容路由队列、内容检索队列以及请求响应队列。若请求内容没有被缓存,则入口节点通过多播(Multicast)的方式,并行地将请求发送至特定的内容分发节点以及后端数据中心。后端数据中心首先将该内容发送至入口节点,并回复给用户。然后通过路由找到该内容的指定节点后,再将该缓存从入口节点移至本地。这样,在缓存丢失的情况下,该策略提高了内容路由、内容检索与内容获取的串行执行效率,减少了用户的响应时延。

图4 并行式路由策略
1.4.3 直通式路由
直通式路由策略的数据流分析如图5所示。同样的,当用户请求在进入第一个内容分发节点时,首先根据Bloom Filter判断内容是否被缓存。若缓存命中,则依照相同的数据流策略。若缓存丢失,则一方面将请求路由到指定节点就行缓存;另一方面将请求直接重定向到数据中心,绕过内容分发网络直接由数据中心给用户响应。在缓存丢失的情况下,相比并行式路由,该策略进一步减少了响应请求队列的处理时间。但该方案也有显著的缺点,其同时将请求的内容推送至用户端和指定的内容分发节点,这将使数据中心端的数据吞吐量增加一倍。

图5 直通式路由策略
2 内容路由策略建模分析
2.1 系统假设
为了对本文所提出的路由策略进行理论建模,文中给出一系列系统假设:(1)在内容分发网络中,本文只考虑队列处理时延,而忽略数据传输时延与传播时延。事实上,在网络系统中,相比较大的队列处理时延,数据的传输时延与传播时延较小,故可忽略不计。(2)根据文献[5]对大规模媒体系统的分析,用户的请求模型基本符合泊松过程[6]。本文假设进入到每个内容分发节点的用户请求均符合泊松过程,并标识λci为以内容分发节点i为入口请求内容为c的用户请求速率期望。(3)假设每个队列的处理速率服从指数分布,且所有分发节点的处理能力大致相同。这样所有的服务队列都能够被建模成为M/M/1排队模型。这些M/M/1队列所组成的队列流则可利用Jackson排队网络模型[7]进行建模,从而得到这些策略下的平均用户响应时延的期望值。(4)假设内容分发网络中共有N个位于不同地点的内容分发节点,内容分发网络中的节点i到节点j的网络带宽资源为Cij,内容分发网络到后端数据中心的网络带宽资源为Co。(5)根据已有文献[8]对大规模网络系统的分析,假设用户请求媒体内容的分布符合Zipf分布,即大量的用户请求只针对小部分的媒体内容。
2.2 系统稳定性
在对路由策略进行建模前,必须保证系统模型是稳定的,否则得到的用户响应时延将趋向于无穷大。具体来说,为了保证系统稳定,则在任意时间段内,每个队列的长度必须是有限的,且网络传输量不能超过网络带宽资源。
首先考虑各个内容分发节点的稳定性。内容分发节点之间通过信息交互,完成内容路由功能。因此,内容路由的速率必须大于用户请求的速率。此外用户请求的速率也不能大于节点间的网络带宽。即式(1)必须被满足来保证内容分发节点的稳定性。

此外,后端数据中心的稳定性也必须得到保证。由于只有在内容分发网络缓存丢失的情况下,才会产生到数据中心的请求,所以到达数据中心的用户速率取决于内容是否已被缓存。标识pc为内容c是否被缓存,若已被缓存则pc=1,否则pc=0。这样,到达数据中心的请求速率表示为。同样,该速率不能超过数据中心的处理速率以及其带宽资源。

2.3 平均响应时延
在保证系统稳定性的前提下,对上文中的3种路由策略所产生的平均响应时延进行理论分析。
2.3.1 传统内容路由
根据数据流分析,可以得到各个队列上的请求到达速率如式(3)
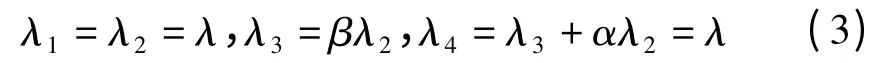
其中,λ1,λ2,λ3,λ4分别为内容路由队列、内容检索队列、内容提取队列以及请求响应队列的处理速率;λ为总用户请求速率;β为真实缓存丢失率。
通过Jackson网络模型,能够得到各个队列上的平均处理时延的期望。式(4)首先给出了内容路由队列的平均时延期望

其中,N为内容分发节点数,「log2N⏋是基于DHT结构的路由策略所要经过节点的期望值;后一项则为每个内容分发节点上处理时延的期望值。
式(5)给出了传统路由策略下,内容检索队列的处理时延期望

其中,μl为分发节点的内容检测速率。
式(6)给出了传统路由策略下,内容提取队列的处理时延期望

其中,μo为数据中心的请求响应速率。
式(7)则给出了传统路由策略下,请求响应队列的处理时延期望

其中,μr为内容分发节点的请求响应速率。
基于4个队列上的处理时延期望,可得到传统策略的总用户平均响应时延Rt,如式(8)
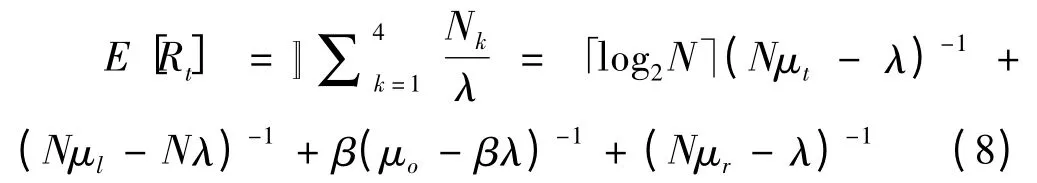
2.3.2 并行式路由
采用同样的方式,依照并行式路由数据流模型,对并行式路由进行理论分析,各个队列上的请求到达速率如下

其中,α'=α+fp-fn为系统判断缓存命中的概率;α为真实缓存命中率;fp为引入Bloom Filter所产生的伪命中率;fn为同步全局Bloom Filter时,在两次同步之间所产生的伪丢失率。fp和fn的理论分析将在下文给出。同样,β'=1-α-fp+fn为系统判断缓存丢失的概率。
在并行式路由策略中,各个队列的处理时延如式(10)~式(13)所示
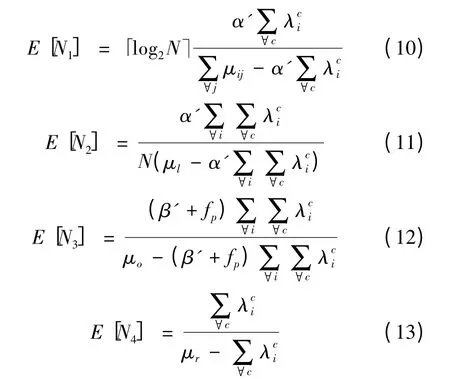
由此,可得到并行式路由策略下的平均用户时延Rp
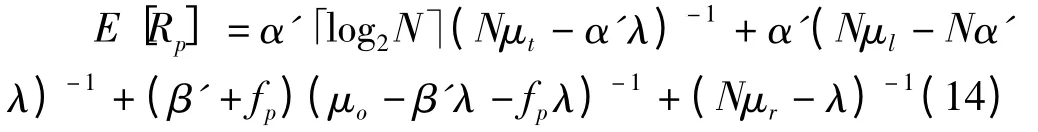
2.3.3 直通式路由
在直通式路由策略下,各个队列上的请求到达速率如下

可以发现,λ1,λ2,λ3的表达式与并行式完全相同,因而直通式路由策略中的前3个队列的处理时延也与并行式路由相同。直通式策略的不同点在于,在内容响应队列上,缓存丢失情况下的用户请求已经直接由数据中心给予响应,因此其请求到达速率将会相应减小为λ4=(α'-fp)λ。这样可得到直通式路由策略下的平均用户时延Rc如式
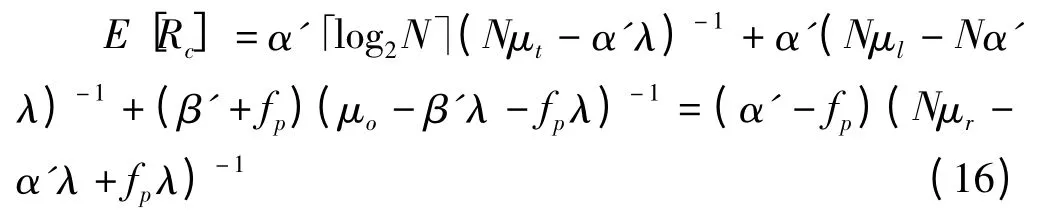
3 内容路由策略仿真分析
3.1 仿真环境与参数设置
本文利用OMNet++对广电云内容分发网络进行了仿真。仿真实验设置共N=50个同构的位于不同地理位置的内容分发节点,这些节点按照DHT环的方式基于Chord协议[9]进行协同工作。所有内容分发节点的存储空间为数据中心保存的总媒体内容的2%。分发网络的缓存替换策略采用最近最少使用(LRU)。实验采用GT-ITM[10]来生成真实的Internet网络拓扑模型,Transit-Stub模型。本实验只考虑一个媒体云数据中心,其中存有50 000个不同的媒体内容,其总大小约为5 GB。每个内容分发节点的处理速率为600个请求/秒,而数据中心的处理速率为1 200个请求/秒。本文假设用户请求数据包的大小为60 Byte(即Sr=60 Byte)。此外,还设定每个分发节点的带宽限制为100 MB/s,数据中心端的带宽限制与之相同。
实验同时也设置了100个位于不同区域的用户群,总请求速率符合泊松过程,其期望值为100个请求/秒。这些用户通过Zipf分布生成,其分布参数为γ=0.79。在此设置下,式(1)和式(2)得以满足,从而保证了系统的稳定性。
对于Bloom Filter的设置,本实验为每个内容的URL生成一个128位的MD5签名[11],并将改签名顺序分为4个32位的Byte,每个Byte的模即为对应的哈希值。因每个节点大致需要缓存1 000个不同的媒体内容,因此每个节点负责的Bloom Filter的大小可设置为5 kB,而总的全局Bloom Filter即为250 kB。此外,采用Delta压缩方式,对Bloom Filter和同步数据进行压缩,使得网络数据传输量可减少约20%。仿真实验将考虑两种同步机制,定时同步和事件触发同步。
3.2 平均响应时延
在此试验中,模拟了两种数据量环境。一种是低网络流量场景,即内容访问量和内容大小成反比,最小的媒体内容拥有最多的访问量;另一种是大网络流量场景,即内容访问量与内容大小成正比,最大的媒体内容拥有最多的访问量。本实验采用基于事件的同步方式,同步周期设置为每个内容分发节点每服务400个请求进行一次同步。通过设定Bloom Filter的初始状态,控制不同的缓存命中率,从而考察这些命中率下,用户的平均响应时延。该仿真持续了1 000 s。
图6给出了不同网络环境和3种路由策略,用户平均响应时延与缓存命中率的关系。其中独立的点为实验仿真结果,而连续的线则为根据式(8)、式(14)和式(16),所得到的理论结果。由此可以发现,实验仿真结果与理论推导结果一致性良好。
图6(a)给出了低网络流量场景下的实验结果。其中根据仿真实验的设置,理论推导的参数设置如下,λ=100 req/s,μt=300 req/s,μl=500 req/s,μo=1 200 req/s,μr=60 req/s。可发现,在所有的缓存命中率下,直通式路由策略下的用户平均时延总是最小,而传统线性策略所产生的用户平均时延总是最大。在缓存命中率在0~100%变化时,当缓存命中率为0时,并行路由与直通式路由所降低的用户时延最多。其中并行式路由则降低了23.6%的用户响应时延,而直通式路由降低了65.2%的响应时延。随着缓存命中率的上升,3种路由策略下的平均用户响应时延逐渐变得一致。这是由于,在缓存命中的情况下,3种路由策略的数据流模型均是一致的。当缓存命中率为100%时,3种路由策略取得了完全一致的用户响应时延。
从图6(a)中,还有一个有趣的现象,随着缓存命中率的上升,传统路由与并行式路由所产生的用户响应时延均逐渐变小,而直通式路由产生的响应时延则逐渐变大。该现象说明只要数据中心端没有产生网络拥塞,将缓存丢失的用户请求直接重定向到数据中心可有效降低用户响应时延。
图6(b)给出了大网络流量场景下的实验结果。其中根据仿真实验的设置,理论推导的参数设置如下μt=100 req/s,μl=500 req/s,μo=260 req/s,μr=8 req/s。在该仿真设置中,相比传统路由策略,并行式路由仍能够在所有的缓存命中率下,一定程度的降低平均用户响应时延。而直通式路由在缓存命中率低于30%时,则会引发网络拥塞,从而导致响应时延甚至高过传统式路由。但当缓存命中率高于40%时,网络拥塞现象消失,其产生的用户响应时延重新变为3种策略中的最小值。通过该现象的启发将在下一步的工作中,提出一种基于文中3种内容路由策略的自适应路由方法。当不会产生网络拥塞时,采用直通式路由,而当数据量变大时,则采用并行式路由来降低用户响应时延。
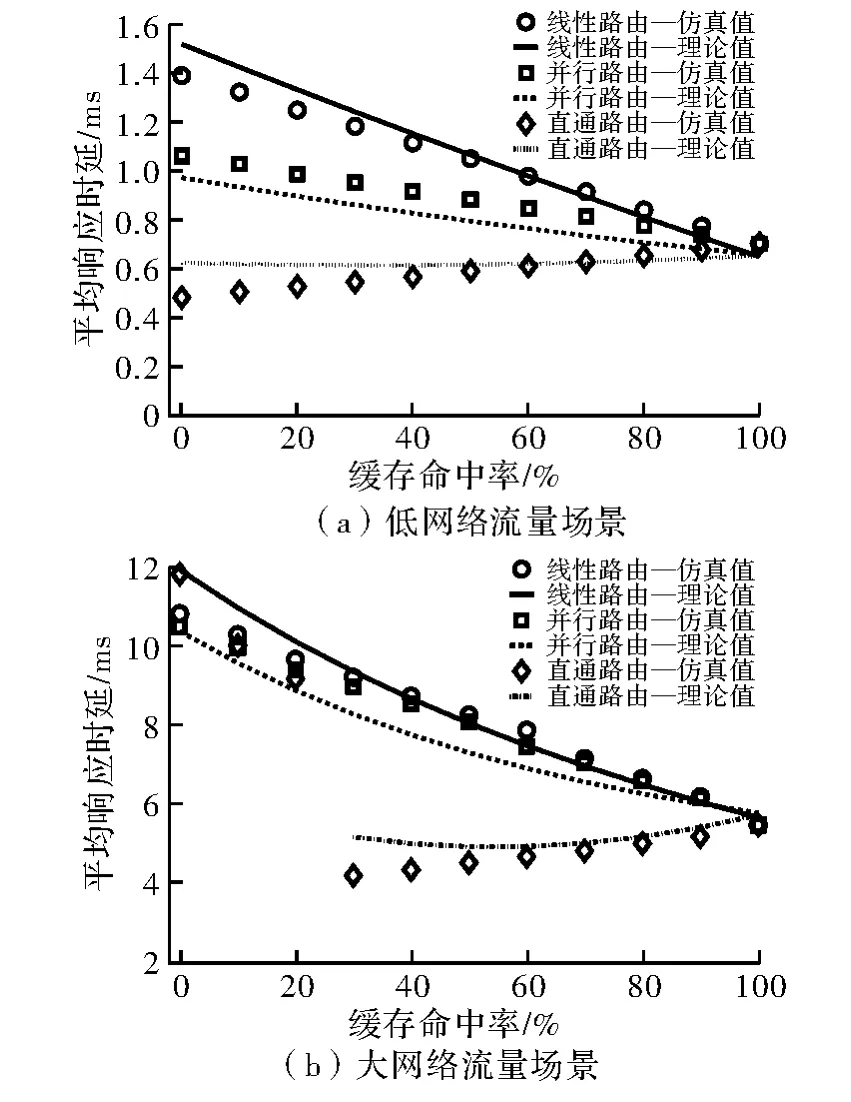
图6 不同网络环境下,用户平均响应时延与缓存命中率的关系
4 结束语
本文在媒体云日益成为下一代广电网络核心发展方向的背景下,研究了媒体云内容分发网络的路由策略,以进一步减少用户响应时延。在分析现有广电云系统架构以及内容分发网络特性的基础上,提出利用全局Bloom Filter优化媒体云网络中的内容路由,并通过两种优化的路由设计,使得用户的平均响应时延得到有效下降。此外采用Jackson排队网络模型对传统的线性路由以及所提出的两种路由策略进行理论建模和数学分析,给出了平均用户响应时延的理论结果。同时使用OMNeT++网络仿真器对媒体云内容分发系统进行了仿真,其仿真结果与理论结论均表现出良好的一致性。结果显示,优化后的路由策略,在不同的场景下,最多能够节省65.2%的平均响应时延。文中对广电云内容分发网络中的内容路由策略进行了完整与全面的研究,所提出的新型路由策略将有利于媒体云网络的构建与优化。
[1] 卢群,姚永晖.云计算及广电应用需求探析[J].广播与电视技术,2010(10):44-53.
[2]VARGA A.OMNeT++[EB/OL].(2007-01-05)[2013-04-06]http://www.hit.bme.hu/phd/vargaa/omnetpp.htm
[3]VENKATA N P,WANG H J,PHILIP A,et al.Distributing streaming media content using cooperative networking[C].Proceedings of the 12th International Workshop on Network and Operating Systems Support for Digital Audio And Video,2002.
[4]BLOOM B H.Space/time tradeoffs in hash coding with allowable errors[J].Communications of the ACM,1970(13):422-426.
[5]H YU,ZHENG D,ZHAO B Y,et al.Understanding user behavior in large-scale video-on-demand systems[C].In Proceedings of ACM Eurosys,2006.
[6]ARLITT M F,WILLIAMSON C L.Internet web servers:workload characterization and performance implications[J].IEEE/ACM Transactions on Networking,1997(5):631-645.
[7]JACKSON J R.Jobshop-like queueing systems[J].Management Science,1963(10):131-142.
[8]BRESLAU L,CAO P,FAN L,et al,Web caching and zipflike distributions:evidence and implications[C].Hangzhou:IEEE Infocom,1999.
[9]ION S,ROBERT M,DAVID L N,et al.Chord:A scalable peer-to-peer lookup protocol for internet applications[J].Beijing:IEEE/ACM Transactions on Networking,2003(11):17-32.
[10]ZEGURA E,CALVERT K,BHATTACHARJEE S.How to model an internetwork[C].IEEE Infocom,1996.
[11]RIVEST R L.The md5 message digest algorithm[R].MA USA:Request for Comments(RFC)1321,1992.
