基于字符串相似度的维吾尔语中汉语借词识别
2013-04-23米成刚杨雅婷杨明忠
米成刚,杨雅婷,周 喜,李 晓,杨明忠
(1. 中国科学院 新疆理化技术研究所,乌鲁木齐 830011;2. 中国科学院大学,北京 100049; 3. 哈密地区电子政务办公室,新疆维吾尔自治区 哈密 839000)
1 引言
随着时代的快速发展,国与国之间、各民族之间的交流日益频繁。语言作为人们交流的主要工具,发挥着不可替代的作用。由于政治、地域等原因,使用一种语言的人们在交流过程中会用到另外一种语言中的词,经过一定时期,就会形成语言中的借词,也称外来词。例如,汉语中的“卡拉OK(からオケ)”等词借自日语,“麦克风(Microphone)”、“沙发(Sofa)”等借自英语。
新疆维吾尔自治区地处亚欧大陆中部,同时受东西方文化影响。维吾尔语本身也接受了一些外来词。维吾尔语借词主要来自于汉语、俄语和阿拉伯语,本文针对其中的汉语借词进行识别。
目前主流的自然语言处理方法是基于统计的方法[1],其最大的特点就是依赖于大规模语料。受语料规模及语言自身特性影响,在进行有关维吾尔语的自然语言处理(信息检索、语音识别、机器翻译等)研究过程中,会出现较多的未登录词[2],而其中的一部分未登录词就属于借词。本文根据借词发音较为相似这一特性,首先参考维吾尔语拉丁化规则,同时考虑维汉两种语言发音差异,将发音相似这一概念转化为字符串相似这一量化标准,同时考虑维吾尔语粘着性这一特点,提出了位置相关的最小距离模型(Position-related Minimum Edit Distance,PMED)以及加权的公共子序列模型(Weighted Common Subsequence,WCS)。在此基础上,进行两种模型的带参数融合。融合模型同时考虑维吾尔语中汉语借词识别的实际应用及维吾尔语语言特性,因而取得了最佳的识别效果。本文提出的将语音相似度转换为字符串相似度的方法,可以为发音较相似语言之间的机器翻译等研究提供新的思路。
2 相关工作介绍
借词(Loan words),又称外来词。在历史发展的过程中,国家与国家之间,民族与民族之间,总会发生交流,当某种物品的名字在交流一方使用的语言中并不存在,或其中的一方特别强大时,借词就产生了,顾名思义,所谓借词就是一种语言从另一种语言中“借”来的词,通常这种词大部分属于音译词。
目前,国内外对借词的研究大都停留在语言学的范畴。对于英语这一国际化语言,主要面向其中的汉语普通话借词[3],日语借词等展开研究;日语中的英语借词对日本社会、经济、文化等产生了巨大的影响[4]。通过调查社会上英语外来词的使用情况,研究人员对现代汉语中的英语外来词进行了全面、系统的分析[5-6]。
国内学者在汉维语外来词借入方法的对比[7],借词对维吾尔语词汇的影响[8],外来语对维吾尔语行业词的影响,现代维吾尔语中汉语借词[9]以及新疆地区方言借词[10]等方面对维吾尔语中的借词进行研究。针对维汉机器翻译中的具体应用,科研人员对维吾尔语中汉族人名的识别和翻译进行了研究[11]。
文中方法与以上论文中研究方法的区别在于,根据借词与原语言词发音相似这一特征,借鉴统计机器翻译中词对齐的思路获取维吾尔语字符与汉语拼音字母的最佳对齐规则(拉丁化规则),使用综合考虑实际应用(维吾尔语中汉语借词识别)及维吾尔语语言特性的字符串相似度计算模型,识别出维吾尔语中的汉语借词。
3 面向汉语发音习惯的维吾尔语词拉丁化模型

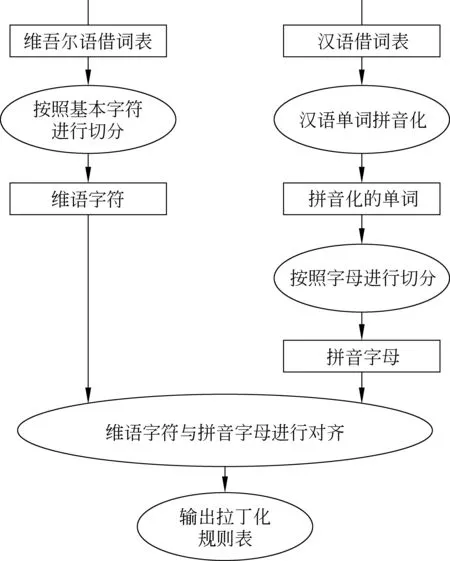
图1 面向维吾尔语中汉语借词识别的维语拉丁化规则训练
公式中的e和f分别是指分割后维吾尔语词字符向量以及分割后对应拼音化的汉语词字母向量。ε是归一化常数,le是e的长度,lf是f的长度,a(j)表示与维语词中第j个字符对齐的拼音字母在字母向量中的索引。 拉丁化规则的训练过程如图1所示。在进行拉丁化训练的过程中,首先对维吾尔语词按照字符进行切分,再对对应汉语词进行拼音化,并按字母切分,然后分别将维语端的字符和汉语端的字母作为向量e和向量f,进行对齐。得到面向维吾尔语中汉语借词识别的拉丁化规则。
4 维吾尔语中汉语借词识别
维吾尔语中汉语借词发现,是从维吾尔语单语语料中查找与汉语词发音相似的维吾尔语词的过程。本文提出的方法,是将语音层面的相似度通过维吾尔语词拉丁化(如本文第2节所示)和汉语词拼音化转化为字符串相似度进行计算,以获取最佳的识别效果。
本文选用字符串相似度算法进行计算。现有的字符串相似度算法属于通用的计算方法,不针对具体的应用场景。结合维吾尔语、 汉语语言特征及维吾尔语中汉语借词识别这一特殊应用, 本文以最小编辑距离算法和最长公共子序列算法为基础,提出了位置相关的最小编辑距离模型(Position-relatedMinimEditDistance,PMED)和加权的公共子序列模型(WeightedCommonSubsequence,WCS)以及两种模型的带参数融合模型(PMED_WCS)。
4.1位置相关的最小编辑距离模型(PMED)
4.1.1最小编辑距离算法
编辑距离,又称Levenshtein距离,是指将一个字符串转换为另一个字符串需要进行字符的增加、删除和交换等操作的次数。最小编辑距离,即是进行字符串转换所需上述三种操作的最少次数,如式(2)所示。
初始化:
(2)
递归方程:
4.1.2位置相关的最小编辑距离模型PMED
最小编辑距离算法可以全局地考虑两个字符串的相似度。针对本文中的问题,由于维吾尔语自身的语言特征及其构词方式(通过在词干后附加若干词缀构成新词),维吾尔语中的汉语借词词尾可能包括词缀,这就使得在使用编辑距离算法计算相似度时可能在词尾进行多次删除操作,导致编辑距离过大,影响最终的识别效果。PMED在继承最小编辑距离算法全局性这一优点的同时,关注拉丁化维吾尔语词与拼音化汉语词计算编辑距离时删除操作的位置,若有连续的删除操作发生在拉丁化维吾尔语词的词尾,则计算编辑距离时减去在词尾连续删除操作的次数,最终相似度得分取其与最小编辑距离两者中较小值。如式(3)所示:
式(3)中EDPMED(ui,cj)是拉丁化维吾尔语词ui与拼音化汉语词的编辑距离,MEDPMED(ui,cj)是最小编辑距离,timesECD(ui)是指计算维语词ui和汉语词编辑距离时,维语词ui结尾连续删除操作的次数。
4.2加权的公共子序列模型(WCS)
4.2.1最长公共子序列
最长公共子序列,英文缩写为LCS(Longest Common Subsequence)。其定义是,一个序列S,如果分别是两个或多个已知序列的子序列,并且是所有符合此条件序列中最长的,则S称为已知序列的最长公共子序列。
其核心算法可用式(4)表示:
4.2.2加权的公共子序列模型WCS
本文提出的识别模型,主要是根据借词与原词发音相似这一特征,进行维吾尔语中汉语借词的识别。由于两种语言发音的差异性,造成拉丁化的维吾尔语词与拼音化的汉语词之间不能做到完全对应,因此,基于最长公共子序列算法,本文提出了加权的公共子序列模型(WCS)[17]。此模型不仅考虑最长公共子序列,而是考虑所有的公共子序列,并为不同长度的公共子序列赋予不同的权值。对所有的公共子序列与权值乘积求和,以和最大者对应维语词为借词。此方法最大的特点是量化了“字符串连续相似”这一因素。如式(5)所示:
u和c分别是拉丁化维语词及拼音化汉语词,NUMi是长度为的公共子序列数目,LENi为可能的子序列长度。考虑到公共子序列长度的不可预测性,我们将最长公共子序列长度设置为两个字符串中较短字符串长度。为了使得较长的公共子序列获得较高的得分,本文在计算相似度时,求公共子序列长度与子序列数目的乘积,并将结果求和。
4.3融合两种模型的相似度计算(PMED+WCS)
基于最小编辑距离算法重点考量的是字符串之间进行互相转换(将字符串A转换为字符串B)时的最小代价,不能反映“连续子序列相似”这一事实,其改进算法PMED也存在这一问题;基于公共子串算法从局部相似出发,一定程度上解决了最小编辑距离算法存在的问题,然而,此算法及其改进算法WCS却有全局性不强的缺点。因此,结合两种模型的优点,构成最终的相似度计算模型SIMPMED+WCS。如式(6)所示:
由于SimPMED使用的是基于编辑距离的相似度计算方法,计算结果越小两个字符串越相似,因此,SimPMED中使用了(-SimPMED)。另外,针对本文中的具体应用,两种模型所占的比率有所不同;为了获取最佳的识别效果,分别在每个模型前附加参数α、β。参数通过EM(Expectation Maximization)模型[18]进行训练。
4.4举例
1) 维吾尔语词拉丁化
传统拉丁化: “jozangni”
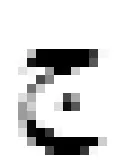
2) 汉语词拼音化
汉语词拼音化: “zhuozi”
3) 相似度计算
PMED模型
如式(3)所示
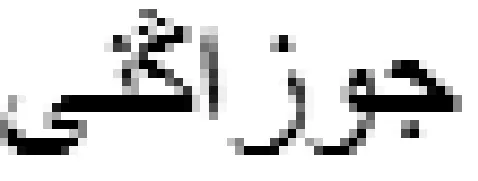
WCS模型
如式(5)所示
公式(8)中,NUMi是长度为i的公共子序列数目,LENi为可能的子序列长度。
5 实验设计与数据分析
5.1实验语料 本文实验所用语料包括: 一、维吾尔语拉丁化修正规则训练语料,主要是人名、地名等维汉对应的双语词(共1000词对);二、维吾尔语汉语借词识别语料,主要是借词识别测试语料(共50000句,平均每句含20个维吾尔语单词)及其参考测试结果语料(共5000词对),测试语料来自新闻领域。
5.2实验过程
以下分维吾尔语拉丁化规则修正和维吾尔语中汉语借词识别两个阶段进行实验。
5.2.1维吾尔语拉丁化规则修正
为了减小拉丁化后维吾尔语词与拼音化后汉语词的差异,根据现有的语料,借鉴统计机器翻译中的词对齐方法,获取适合本文实际应用的拉丁化规则。
首先,对维汉词对中的维吾尔语词按字符进行切分;对汉语词进行拼音化,并对汉语拼音按照字母进行切分,获得维吾尔语字符向量、汉语拼音字母向量对齐语料;
其次,将拉丁化规则的获取问题转换为维吾尔语字符与汉语拼音字母对齐问题;对齐采用统计机器翻译中广泛使用的词对齐工具GIZA++进行。综合考虑此处面临问题及其运行效率,使用其中的IBM模型2即可;

表1面向维吾尔语中汉语借词识别的维语拉丁化规则

5.2.2 维吾尔语中汉语借词识别
为了验证各个模型的有效性,分别在位置相关的最小编辑距离模型(PMED),加权的公共子序列模型(WCS)以及带参数融合模型(PMED+WCS)三种模型上进行实验。实验结果用准确率P(Precision)、召回率R(Recall)以及F1值来表示。
F1计算方法如式(9)所示。
实验1位置相关的最小编辑距离模型(PMED)
首先,分别进行汉语词的拼音化和维吾尔语词的拉丁化(使用5.2.1中得到的修正的维吾尔语拉丁化规则),根据4.1.2中的方法,从位置相关的最小编辑距离模型(PMED)中得到各个维吾尔语词-汉语词对应得分,取最小项作为最终结果。为了进行对比,此处也在最小编辑距离算法模型(MED)上进行了实验,结果如表2所示。
表2位置相关的最小编辑距离模型PMED和最小编辑距离模型MED识别结果

准确率(P)/%召回率(R)/%F1值/%MED62.3571.0966.43PMED64.7375.6869.78
实验2加权的公共子序列模型(WCS)
进行汉语词的拼音化和维吾尔语词的拉丁化(使用修正的维吾尔语拉丁化规则进行),根据4.2.2中的WCS模型(加权的公共子序列相似度计算模型),计算出各词对的相应得分,取得分最高的维吾尔语词为识别出的借词。为了与WCS模型进行对比,此处也在最长公共子序列模型(CS)上进行了实验,结果如表3所示。
表3加权的公共子序列模型WCS和公共子序列模型CS识别结果
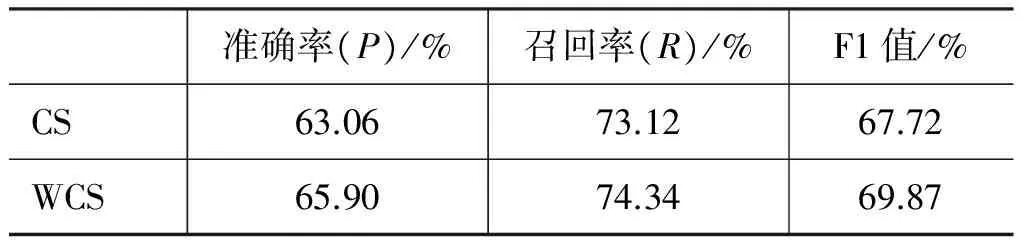
准确率(P)/%召回率(R)/%F1值/%CS63.0673.1267.72WCS65.9074.3469.87
实验3融合两种模型的维吾尔语中汉语借词识别
融合模型(PMED+WCS)是对两个模型(PMED和WCS) 进行带参数融合。首先对模型进行训练,确定两参数的最优值。使用拉丁化的维吾尔语汉语借词与拼音化的汉语词进行训练。根据EM算法的步骤,首先对参数进行初始化,再重复执行E步和M步,直到F1值收敛。F1值最高时对应的α和β作为参数的取值,其中的训练语料使用 10 000词测试语料,F1值评价采用对应的200词参考语料。参考实验1中的方法进行借词识别实验。为了显示带参数模型的有效性,同时使用无参数模型(PMED+WCS_P1)进行实验。结果如表4所示。
表4带参数的融合模型和未带参数融合模型识别结果
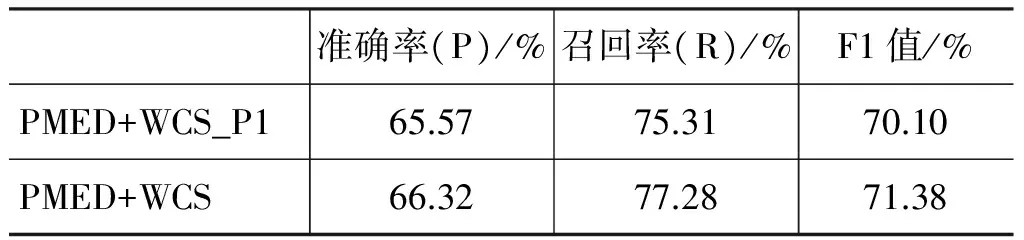
准确率(P)/%召回率(R)/%F1值/%PMED+WCS_P165.5775.3170.10PMED+WCS66.3277.2871.38
5.3 实验数据分析
对实验数据进行分析,可以得出以下结论。
实验1使用位置相关的最小编辑距离模型求取拉丁化后维吾尔语词与拼音化汉语词的字符串相似度,最小值对应汉语词为识别出的借词。与最小编辑距离算法相比,位置相关的最小编辑距离模型考虑到了维吾尔语的构词方式(词干加若干词缀),在计算编辑距离的同时,监测进行连续删除操作的位置,若发生在维语词尾,则对编辑距离计算结果进行修正。PMED模型兼顾字符串相似全局性以及维吾尔语语言特点,因此,与最小编辑距离算法相比,PMED模型取得了较高的识别准确率,如表2所示。
实验2根据提出的加权公共子序列模型,不仅考虑到了字符串的局部相似性,而且对所有的公共子序列根据其长度赋予不同的权值。相比于传统的最长公共子序列算法,加权的公共子序列模型(WCS)更好地反映了拉丁化维语词与拼音化汉语词的相似性,因而对借词的识别准确率较高,如表3所示。
实验3中的带参数融合模型(PMED+WCS)结合了PMED和WCS的优点。从维吾尔语中汉语借词识别这一具体任务出发,考察维吾尔语构词特点以及维汉两种语言发音差异,综合字符串的全局相似性与局部相似性,并使用EM算法,分别赋予两种模型(PMED和WCS)不同参数,更好地反映了具体语料中不同模型对最终识别结果的影响。实验结果表明,与上述两种模型相比,PMED+WCS模型取得了最佳的借词识别效果,如表4所示。
6 结束语
本文根据维吾尔语中汉语借词与原汉语词发音相似这一特点,将语音相似度转换为字符串之间相似度进行维吾尔语中汉语借词的识别。对现有的维吾尔语词借词—汉语语料进行处理,对维吾尔语词进行字符切分,对对应汉语词进行拼音化,借鉴词对齐方法,训练出适合汉语拼音发音的维吾尔语拉丁化规则;根据字符串相似度这一量化标准,分别将测试语料中维吾尔语词进行拉丁化(修正的拉丁化规则),汉语词拼音化,使用文中提出的三个模型PMED、WCS和PMED+WCS进行实验。结果显示,综合考虑字符串全局相似性、局部相似性以及维吾尔语语言特性等因素的PMED+WCS模型获得了较高的识别准确率。文中采用的方法为发音较相似语言对之间的翻译提供一种研究思路;本文的实验结果可以作为维汉机器翻译的辅助知识源;另外,可以应用本文提出的方法根据汉语中发现的新词进行相应维吾尔语文本中新词的发现。然而,汉语中存在多音字的情况,会影响到借词识别结果,从而影响到最终的应用(如维汉机器翻译),后续将针对这一问题展开研究。
[1] Chris Manning, Hinrich Schütze. Foundations of Statistical Natural Language Processing [M],Cambridge: MIT Press, 1999.
[2] Chung-Chi Huang and Ho-Ching Yen and Ping-Che Yang, et al. Using Sublexical Translations to Handle the OOV Problem in Machine Translation [J]. ACM Transactions on Asian Language Information Processing, 2011, 10(3): 16.
[3] Lauren Asia Hall-Lew. English Loanwords in Mandarin Chinese [D]. Arizona: the University of Arizona, 2002.
[4] Gillian Kay. English loanwords in Japanese [J]. World Englishes, 1995, 14(1): 67-76.
[5] 潘子助. 试谈汉语中的英语借词[J]. 湖北函授大学学报,2011,24(7):110-111.
[6] Kui Zhu.On Chinese-English Language Contact through Loanwords[J]. English Language and Literature Studies,2011,1(2):100-105.
[7] 陈燕,陈平. 汉维语外来词借入方法对比研究[J]. 喀什师范学院学报,2011,32(2):51-55.
[8] 郑燕. 借词对维吾尔语词汇的影响[J]. 湖北第二师范学院学报, 2011,28(1):37-39 .
[9] 陈世明. 维吾尔语汉语借词新探[J]. 西北民族研究,2007,1: 5.
[10] 周磊. 乌鲁木齐方言借词研究[J]. 方言,2004,4: 347-355.
[11] 李佳正,刘凯,麦热哈巴·艾力,吕雅娟,刘群,吐尔根·依布拉音. 维吾尔语中汉族人名的识别及翻译[J]. 中文信息学报,2011,25(4): 82-87.
[12] Philipp Koehn, Franz Josef Och, Daniel Marcu. Statistical Phrase-Based Translation[C]//Proceeding NAACL ’03 Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language. Edmonton, Canada: ACL, 2003:48-54.
[13] Peter F.Brown, Stephen A.Della Pietra, Vincent J. Della Pietra, et al. The Mathematics of Statistical Machine Translation: Parameter Estimation [J]. Computational Linguistics, 1993, 19(2): 263-311.
[14] Yang Liu, Qun Liu, Shouxun Lin. Log-linear Models for Word Alignment[C]//Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics. Ann Arbor: ACL, 2005: 459-466.
[15] Chris Dyer, Jonathan Clark, Alon Lavle, et al. Unsupervised Word Alignment with Arbitrary Features[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. Portland, Oregon: ACL, 2011: 409-419.
[16] Robert C.MOORE. Improving IBM Word-Alignment Model1[C]//Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics. Barcelona, Spain: ACL, 2004:519-526.
[17] 阿依克孜·卡德尔,开沙尔·卡德尔,吐尔根·依布拉音. 面向自然语言信息处理的维吾尔语名词形态分析研究[J]. 中文信息学报, 2006, 20(3): 43-48.
[18] Mehryar Mohri, Fernando Pereira, Michael Riley. Weighted Automata in Text and Speech Processing[C]//Proceedings of 12th European Conference on Artificial Intelligence. Budapest: John Wiley & Sons, Ltd, 1996: 5.
