一种基于反馈的Raptor码编码改进方案
2013-04-05雷维嘉谢显中
张 伟,雷维嘉,谢显中
(重庆邮电大学移动通信技术重庆市重点实验室,重庆400065)
0 引言
文献[1]在1998年首次提出数字喷泉码这一概念,文献[2]在2002年给出了第1种实用的数字喷泉码—LT码。对于LT码,编译码k个源数据包需要k ln k次异或(XOR)运算,也就是说LT码并不具有线性时间译码[3]。基于此,2006年文献[4]提出了另外一类数字喷泉码,即Raptor码,它由外码和内码通过级联编码的方式实现。外码是传统的信道纠删码,内码是弱化的LT码。这里,弱化的LT码是指其度分布中最大度为一个较小的值,且平均度d*是个常数,编译码k个源数据包需要kd*次XOR运算。因此,Raptor码实现了线性时间译码。
为了提高喷泉码的译码效率,许多方案都引入了反馈。文献[5]提出一种实时遗漏纠错方案,接收端向发送端反馈译出的源数据包个数,发送端根据反馈信息选择一个固定的度分布,使接收端译出全部源数据包的时间减短。同样,文献[6]给出一种混合喷泉码,发送端根据反馈信息直接发送相应的源数据包,加速了译码进程。又有学者针对短码给出一种无率反馈码方案[7],该方案通过多次反馈并改变度分布,使译码开销减少等。
以上方案虽然通过反馈提高了译码效率,但忽略了译码效率变化的特点。本文针对Raptor码译码的最后阶段出现译码效率明显降低的问题,提出了一种带反馈的编码改进方案,并给出最佳的反馈控制点。仿真结果显示:改进的方案明显提高了译码效率,减小了译码开销等。
1 Raptor码
1.1 Raptor码的编码和译码
Raptor码的编码包括预编码和LT编码两部分。预编码:编码器对k个源数据包使用纠删码(比如,LDPC码[8])产生K个中间数据包,其中K比k略大一点。LT编码:根据弱化的LT码度分布对K个中间数据包进行喷泉编码,产生需要的编码包数量。
相应地,Raptor码的译码包括了两阶段译码,采用与LT码相同的置信传播算法[2]。LT译码:编码包译出绝大多数中间数据包。预编码的译码:由译出的这部分中间数据包恢复全部源数据包。
Mackay在文献[9]中指出:当译码器接收N(N比k略大一点)个编码包后进行译码,有一部分中间数据包不能恢复出来,其比例为f=exp(-d*)。对此,他提出了一种编译码策略:预编码阶段应产生k/(1-f)个中间数据包,而译码器只需译出大约k个中间数据包,然后通过预编码的译码恢复全部的源数据包。
1.2 弱化的LT码度分布
在LT码的译码过程中,为了避免冗余,希望每次迭代中只有一个度为1的编码包。由此得到一种理想孤子分布ρ:
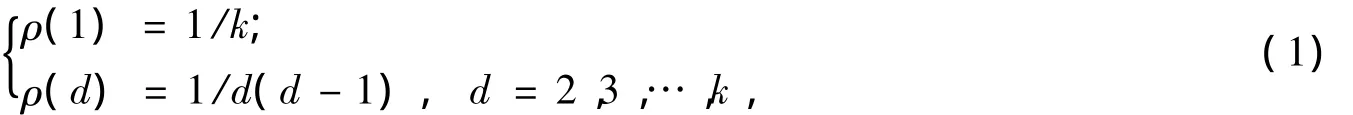
其中,ρ(d)为选到度为d的概率。
然而实际中,理想孤子分布的效果并不好。一方面,译码过程中很可能因为没有度为1的编码包而出现译码中断;另一方面,编码时可能有些源数据包没有被覆盖,导致无法译出。Luby对理想孤子分布进行了修改[2],设计了一个正数函数τ:

其中,参数с和δ保证了译码过程中期望产生度为1的编码包个数大约为:

式中,с为0和1之间的某一常数;δ为接收一定数量的编码包后,未能成功译出全部源数据包的概率。然后,将ρ与τ相加再归一化得到鲁棒孤子分布μ:

鲁棒孤子分布的最大度是k,而弱化的LT码度分布是将鲁棒孤子分布的最大度设置成一个较小的值,但理想孤子分布和正数函数的最大度不变[9],下面定义其表达式:
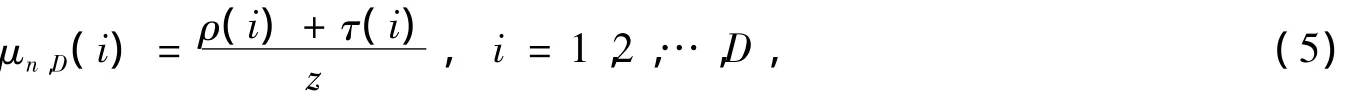
式中,n为参与编码的数据包个数;D为最大度;i为度;z=ρ(i)+τ(i)。特别地,对于不同的n,当D取8时,μn,D的平均度d*均为3。
2 译码性能及改进的编码方案
2.1 译码性能
这里主要研究Raptor码的LT译码阶段,即由编码包译出k个中间数据包这一过程。预编码采用LDPC码,其度分布Ω(x)=(2x+3x2)/5[4],码率为0.95。为了便于分析,定义4个参数:译码比例β,表示译出的中间数据包个数M占源数据包个数k的比例,即β=M/k;接收比例θ,表示接收的编码包个数N占k的比例,即θ=N/k;译码效率η=M/N;译码开销ε[10],表示成功译码时接收的编码包个数与k的差值占k的比例。图1给出了k分别取1 000和5 000时,多次仿真其译码比例β随接收比例θ变化的曲线,其中每条曲线代表每次仿真的结果。
观察图1a中k=1 000的译码曲线,当横坐标0<θ<0.8时,曲线比较平缓,纵坐标β的值非常小,只译出少部分中间数据包,说明译码效率很低;当θ大约为0.9时,曲线出现陡增,β迅速增大到0.8左右,表明译出了大约0.8k个中间数据包,译码效率大大提高;最后一段曲线变平缓,β变化缓慢,说明译码效率明显降低,当θ大约为1.2时,译码结束,译码开销约为0.2。观察图1b,k=5 000时表现出与k=1 000相似的译码曲线。
2.2 理论分析
度分布的设计对于数字喷泉码来说是至关重要的,它的好坏直接决定了译码性能。在译码过程中,度为1和其他低度的编码包的数量决定了译码能否开始并持续进行,但这些数据包携带的原始信息较少,可能不会覆盖全部的源数据包。为了译出全部源数据包,译码器需要接收更多的编码包。度分布的平均度代表了平均的编译码复杂度。因此,较小的平均度确保了译码过程的流畅性,但可能造成译码开销增大。比如,当d*=3,不同k值的译码开销ε均达到了0.2之多,而这个值并不理想。
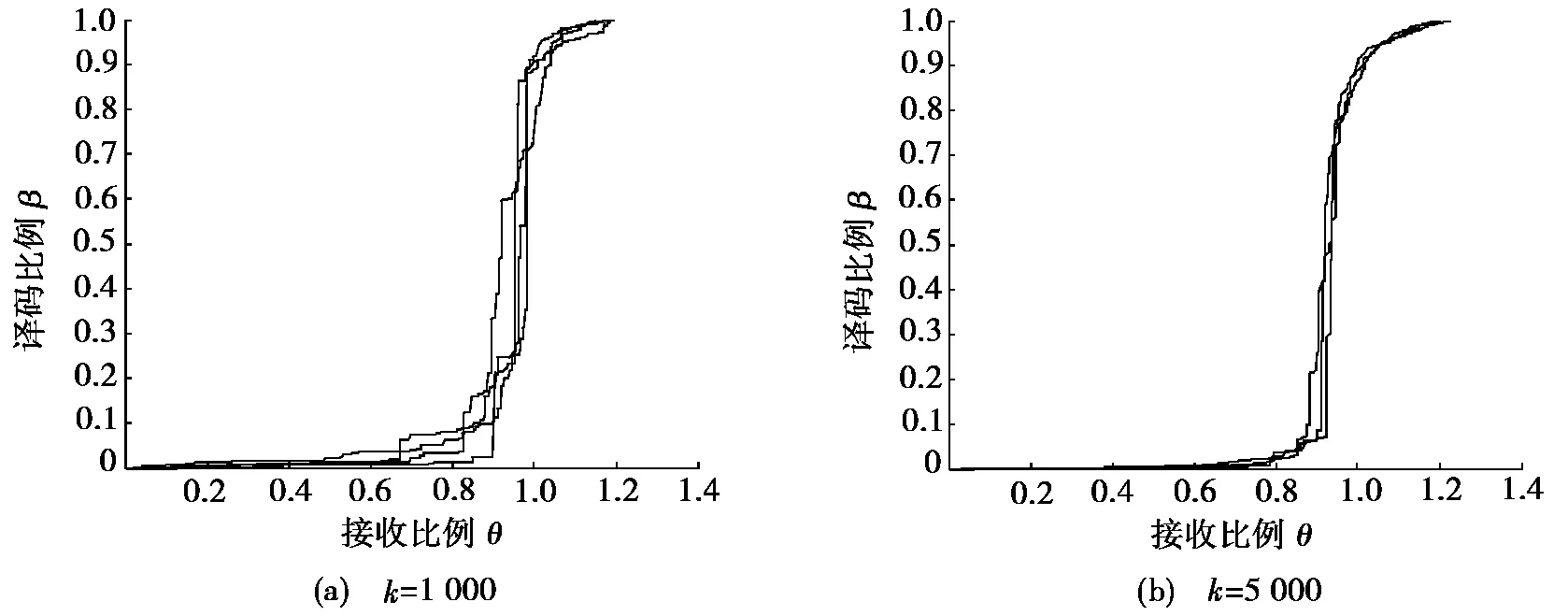
图1 不同的源数据包数k,译码比例β随接收比例θ变化的曲线
译码开销增大主要是因为译码的最后阶段译码效率明显降低。分析认为:当译码器译出大约βk个中间数据包后,编码器新生成的编码包中只包含译出数据包信息的比例为P=βd*,而这些编码包对未译出的数据包是冗余信息。由图1可看出:当β大约为0.8时,曲线开始变平缓。这时,P=0.83,大约为50%。因此,最后阶段接收的编码包中有一半是不包含未译出的数据包信息,导致了译码效率明显降低。
为了提高这一阶段的译码效率,编码器再编码时可以考虑只对未译出的数据包进行编码,但需要译码器反馈这部分数据包的包号。下面给出具体的改进方案。
2.3 改进的编码方案
根据反馈控制编码器中参与编码的数据包的思想,改进的编码方案为:
(Ⅰ)编码器按照度分布μK,8对K个中间数据包进行喷泉编码。
(Ⅱ)译码器接收一定数量的编码包后开始译码;当译出大约αk个中间数据包时,向编码器反馈剩余未译出的数据包个数(K-αk)和具体数据包的包号。
(Ⅲ)编码器根据反馈信息,仅对这(K-αk)个数据包按照度分布μ(K-αk),8喷泉编码。
(Ⅳ)译码器译出大约k个中间数据包后,由这k个数据包恢复出全部的源数据包。
这里,称α为反馈控制点。从图1中曲线的变化趋势来看,曲线在α=0.8左右开始变平缓,而改进方案的关键是α取何值时,可使译码开销最少,即寻找最佳的反馈控制点。从理论上推导最佳的反馈控制点α的值比较困难,本文通过仿真的方法,对不同的源数据包数k、α分别取0.75、0.80、0.85和0.90这4个值,比较各自的译码开销来得到最佳的反馈控制点。图2仿真了不同的源数据包数k,译码开销ε随反馈控制点α变化的关系。从该图可得到最佳的反馈控制点α为0.8,此时译码开销均最少。
改进方案需要译码器反馈未译出数据包的包号,这样虽然增加了系统的复杂度,但译码开销的大幅降低远弥补了这一不足。另外,当源数据包数k较大时,反馈数据较多,复杂度增加,也会使总的效率降低。例如k=5 000时,反馈量达到1 000。因此,改进方案更适合k不超过1 000的情况。
3 性能仿真
本文通过仿真的方法,与原来无反馈的编码方案作比较,验证改进方案的性能。仿真中,弱化的LT码度分布中с和δ分别取0.03和0.50。首先,比较两种方案的译码开销。原来的方案(图2中,当α= 1.00时纵坐标ε的取值),对于不同的源数据包k,译码开销都达到了0.22;而改进的方案(图2中,当α=0.80时纵坐标ε的取值),译码开销减小了10%左右,且随着k的增大,译码开销逐渐减小,当k=1 000时,ε仅为0.096。
译码效率η是衡量一种方案的性能很重要的参数,η越趋近1说明方案的性能越好。图3为不同的源数据包数k,两种方案的译码效率对比情况,原来方案的η大约为0.82且随k的变化很小;改进方案的η随k的增大而增大,当k=1 000时,η达到了0.91,体现了很好的性能。
为了更清楚表明译码的最后阶段,改进方案明显提高了译码效率,这里定义另外一个参数,最后阶段的译码效率η0=0.2k/△N,△N表示译出最后0.2k个中间数据包,译码器还需接收的编码包数。η0的具体含义为译码器接收一个编码包平均能译出中间数据包的个数。表1为不同的源数据包数k,两种方案最后阶段的译码效率η0对比,由表1可看出:译码的最后阶段,无反馈的方案中译码器接收一个编码包可译出一个中间数据包,而改进的方案可译出两个中间数据包,效率提高了一倍以上。

图2 不同的源数据包数k,译码开销ε和反馈控制点α的关系

图3 不同的源数据包数k,两种方案的译码效率对比情况
4 结束语
本文给出了一种基于反馈的Raptor码编码改进方案,它通过反馈来控制编码器中参与编码的数据包,减少了冗余信息,提高了最后阶段的译码效率。经仿真得到最佳的反馈控制点。仿真结果显示:与原来无反馈的编码方案比较,改进方案的译码性能得到明显改善。

表1 不同的源数据包数k,两种方案最后阶段的译码效率η0对比
[1] Byers J,Luby M,Mitzenmacher M,et al.A Digital Fountain Approach Distribution of Bulk Data[J].ACM Sigcomm Computer Communication Review,1998,28(4):56-67.
[2] Luby M.LT Codes[C]//Proceedings of 43rd Annual IEEE Symposium on Foundations of Computer Science(FOCS’02).USA:IEEE Press,2002:271-280.
[3] 慕建君,焦晓鹏,曹训志.数字喷泉码及其应用的研究进展与展望[J].电子学报,2009,37(7):1571-1577.
[4] Shokrollahi A.Raptor Codes[J].IEEE Transactions on Information Theory,2006,52(6):2551-2567.
[5] Beimel A,Dolev S,Singer N.RTOblivious Erasure Correcting[J].IEEE/ACM Transactions on Networking,2007,15(6): 1321-1332.
[6] Kokalj-Filipovic S,Spasojevic P.ARQ with Doped Fountain Decoding[C]//IEEE ISSSTA’08.2008:780-784.
[7] Jesper H S,Toshiaki K A,Philip O.Rateless Feedback Codes[C]//IEEE International Symposium on Information Theory Proceedings.2012:1767-1771.
[8] 王立新,刘跃军,吴亮.基于LDPC优化图结构的ACE改进算法[J].河南科技大学学报:自然科学版,2010,31(4):46-52.
[9] Mackay D JC.Fountain Codes[C]//IEE Communications Proceedings.2005:1062-1068.
[10] Mitzenmacher M.Digital Fountains:A Survey and Look Forward[C]//IEEE Information Theory Workshop.USA:IEEE Press,2004:271-276.
