改进的Fp-Growth数据关联挖掘算法研究
2013-03-27邹永平
邹永平
(江苏省无锡交通高等职业技术学校,江苏无锡 214151)
引言
数据关联规则的挖掘一般包括两个过程:首先寻找具有最小置信支持度的所有频繁项集;基于满足最小置信支持度和最小置信度的要求,再由频繁项集产生强相数据关联规则。数据关联规则挖掘算法的研究重点是如何快速有效地找出满足最小置信支持度的所有频繁项集。由于Apriori算法在不停扫描数据库时会通过产生大量的候选项集,并由此找出所有的频繁项集,这就给算法在时间和空间上带来太大的开销。Han等人提出一种新的基于所谓Fp-Tree的频繁模式增长算法已克服数据关联规则的严重不足之处。
Fp-Growth算法采用新的分而治之的策略。该策略的原理是:首先将可以提供频繁项集的数据源数据库压缩到一颗频繁模式树(frequent patern tree,简称为Fp-Tree),但项集关联信息仍要保留;再通过一组条件数据库(一种特殊类型的投影数据库)将通过压缩后的数据库分成得到,频繁项由条件数据库关联,每个条件数据库分别被挖掘。
1.改进的Fp-Growth算法的挖掘过程
Fp-Growth数据关联挖掘算法在性能上比以往的挖掘算法都有较大的改进,但还是存在前面曾经提到的不足。基于此,本文基于分隔方法对Fp-Growth算法进行改进。
1.1 改进的Fp-Growth算法描述
改进算法中数据库分隔,约束项挖掘以及频繁项合并的具体过程描述如下:
输入:M—数据源数据库;min_sup—最小置信支持度阈值。
输出:M中的频繁项集。
改进算法具体过程描述如下:
(1)对数据库M进行扫描,找出由候选l-项集构成的集合,得到其置信支持度计数。按置信支持度计数递减顺序对候选1-项集的各项进行排列,得到候选1,项集的集合F。将F中置信支持度小于最小置信支持度的项删除,得到频繁1-项集的集合L。设 L={Im,Im-1,…I1},其中,Im为最高置信支持度,I1为最小的置信支持度。
(2)对数据库M进行再次扫描,删除各数据源中置信支持度小于最小置信支持度的项,按照递增次序,基于各项置信支持度计数,对各数据源中的项进行排列,得到数据库为“M”。
(3)对数据库“M”进行扫描,将所有第一项为项 Ii(i=1,2,…,m -1,m)的数据源进行提取,在相应的数据链表Vi中存放这些数据源。“M”中所有数据源信息被保存在V={V1,V2,…,Vm}的数据链表组。
(4)根据前述过程中各项的置信支持度计数,在一定的规则下递增地构造各项的数据库子集,通过Fp-Growth算法对其运行约束频繁项挖掘。
(5)将从Vi中导出的数据存放于数据库“M”中,对“M”用Fp-Growth算法运行包含项的约束频繁项挖掘。挖掘过程包括:
①对数据库“M”进行扫描,按置信支持度计数递减次序将“M”的数据源重新排列。
②通过“M”构造Fp-Growth,创建项头表HT。
注:构造项头表HT时,该HT中各项的次序等于L的排列次序,HT中的最后一项标示的就是项Ii的置信支持度计数及其节点链信息。
③通过HT中的最后一项所表示的信息构造该项的条件模式基,构造其条件Fp-Tree,包含该项的频繁项集ZLi就能在该条件Fp-Tree上挖掘出来,从而完成数据库子集“M”上的约束频繁项挖掘。
(6)删除Vi中的头元素,基于其不同的后继元素,在其它相应的数据链表中叠加去掉头元素的数据源。
(7)在L中所有项的约束频繁项集ZLi被依次挖掘出来后,将这些约束频繁项集合并,即取这些约束频繁项集ZLi的并集,从而得到M中的所有频繁项集,挖掘工作完成。
2.具体应用
为了说明该算法的有效性,以列于图1左侧所示的数据源数据库为例,说明改进算法的挖掘过程。共有10个数据源存在于数据库中。其最小置信支持度设置为3,也就是min_sup=30%。
通过对该数据库首次扫描,得到F(候选1-项集的集合)及其置信支持度计数,置信支持度小于最小置信支持度3的从F中删除,及删除g和f,得到频繁1-项集的集合。再次扫描数据库,将置信支持度小于最小置信支持度的项从各数据源中删除,按置信支持度计数递增的顺序对各项数据源中的项重新排列,得到数据库M,如图1所示。
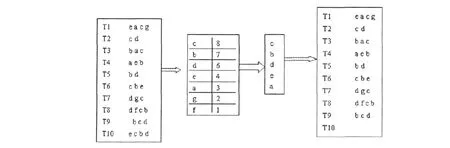
图1 数据库“M”形成
将M中的各数据源按照第一项的不同分别保存到数据链表组v中的不同数据链表。以递增顺序对L中各项的置信支持度计数进行排序,在数据库M中导入保存在数据链表中头项为α的数据,基于Fp-Growth算法,对约束频繁项进行挖掘。运行约束频繁项挖掘时生成的Fp-Tree和相应的项头表示于图2。
以项头表中的最后一项所标示的信息为基础,构造该项α的条件模式基,构造条件Fp-Tree,该条件Fp-Tree就可以将包含项α的约束频繁项集挖掘出来。挖掘出来的频繁项集及其置信支持度为(a)(30%)。随后,头元素α将从头项为α的数据链表中的删除,如果后继元素不同的话,就可以再其它相应的数据链表中迭加去掉头元素的数据源,新的数据链表组就可以得到了。
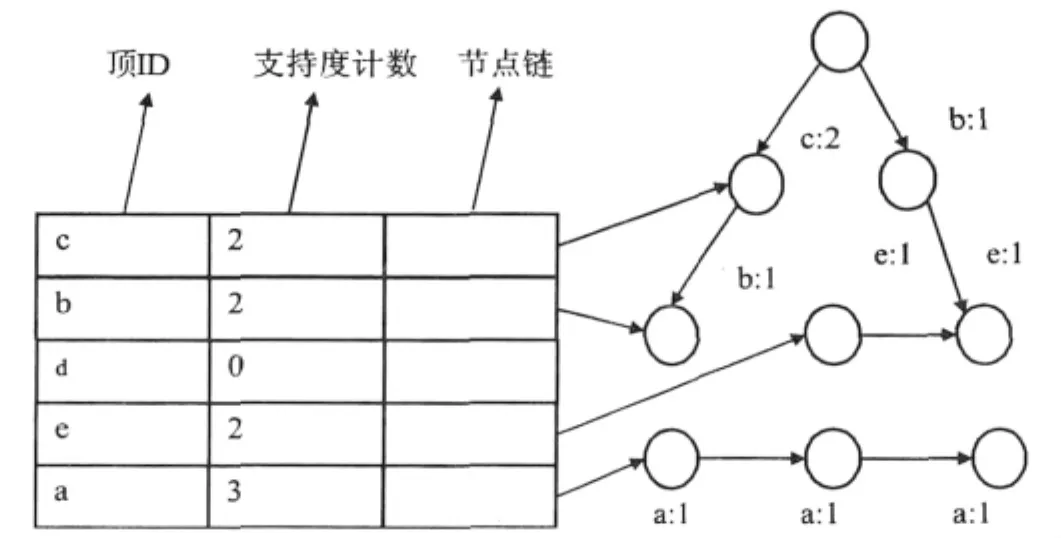
图2 头项为a的数据库M生成的的项头表
最后可以在数据库“M”中导入来自新数据链表组中头项为e的数据链表中的数据,基于Fp-Growth算法,进行约束频繁项挖掘,将该头元素和组合形成新的数据链表组删除。当所有项的约束频繁项集被挖掘出来后就停止挖掘,对约束项频繁项集进行合并,就可以得到实例数据库的所有频繁项集及其置信支持度,结束挖掘过程。
Apriori算法是现今研究数据关联规则中最具代表性的方法,虽然之后有许多算法被提出。
2.2 实验过程分析
本文通过在 WebDocs,accidents和 bio-train等三个数据库中的测试结果来分析和比较Fp-Growth算法及其改进算法的性能。基于c语言,编制测试算法,算法运行环境为 Petium IV2.8G,内存512M。表1~表4列出了实验结果。其中,表1和表2分别列出了从数据库WebDocs中抽取了300M,40万条左右的数据和500M,58万条左右的数据运行测试所得的结果。
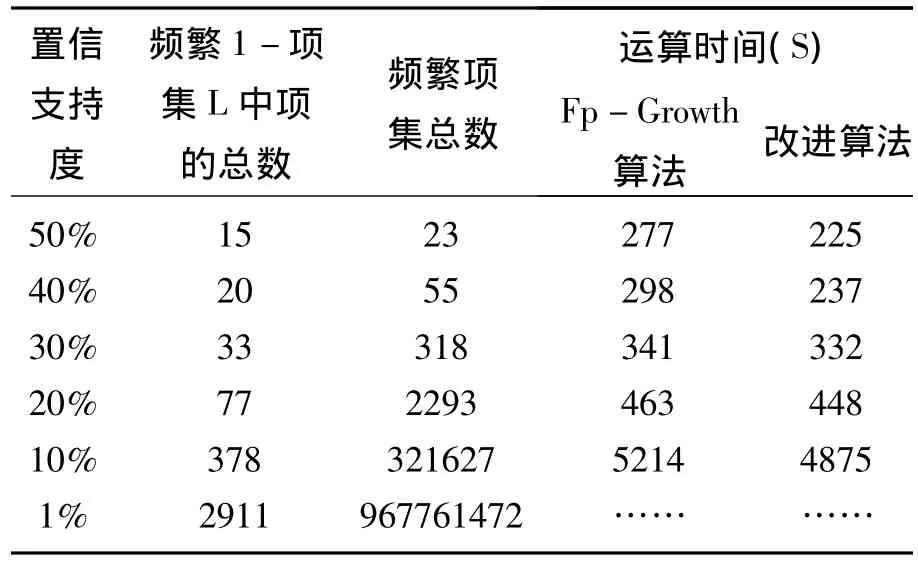
表1 改进算法在(350M)数据库上的测试结果
由此可以看出,对于webDocs(350M)数据库,相比较于未改进的算法,改进的Fp-Growth算法在不同置信支持度下的运行时间要大大缩短。
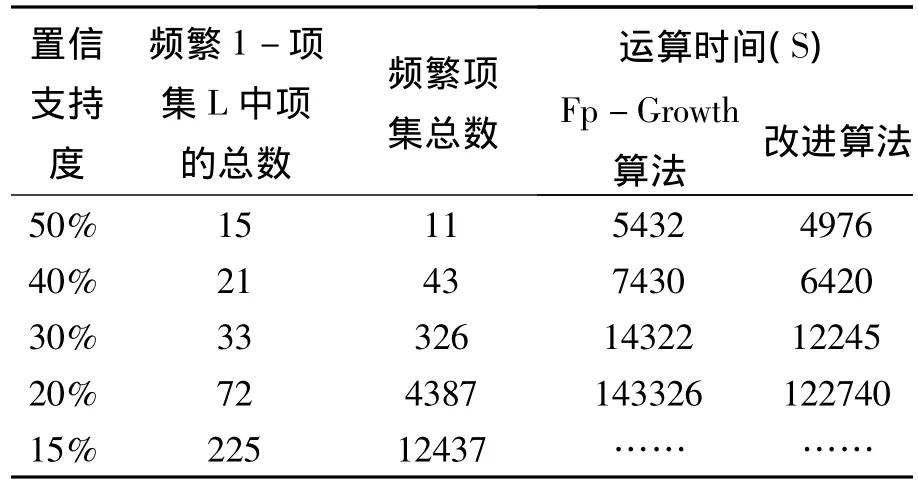
表2 改进算法在webDocs(500M)数据库上的测试结果
从表2中可以看出,在webDocs(500M)数据库上,改进的Fp-Growth算法在不同置信支持度下其运行时间也均比未改进的算法要短。

表3 改进算法在accidents(33.8M)数据库上的测试结果
表3的结果表明,在accidents(33.8M)数据库上,相比较于未改进的算法,改进的Fp-Growth算法在不同置信支持度下其运行时间也要缩短。

表4 改进算法在bio_train(66.4M)数据库上的测试结果
表4的结果表明,在bio_train(66.4M)数据库上,相比较于未改进的算法,改进的Fp-Growth算法在不同置信支持度下其运行时间也有所缩短。
综合上述4种情况的结果表明,改进算法要明显快于原算法,因为改进算法只需对数据库进行一次扫描就可以创建数据库子集,而原算法则需要对频繁1-项集的项总数的数据库扫描,改进算法的实时性更强。
基于 Fp-Growth算法,提出了改进的 Fp-Growth挖掘算法,改进后的Fp-Growth挖掘算法可以适用于对大型数据库的数据关联规则的挖掘。改进算法基于一种新的数据库分隔方法来分隔数据库,并对分隔得到的各数据库子集用Fp-Growth算法进行约束频繁项集挖掘。基于三个测试数据集上的实验测试,对改进算法与Fp-Growth算法的运行情况进行了比较分析。可以得出这样的结论,如果最小置信支持度较小或数据库很大时,Fp-Growth算法单独使用时需要十分巨大的内存,而改进的数据库划分策略克服了这种缺陷,明显减小了占用的内存,并导致比更高的挖掘速度,特别适合于对大型数据库的数据关联规则的挖掘。并且改进算法创建子集的时间开销也有所缩短,使得改进算法的运行速度更快了。
3.结束语
虽然Fp-Growth数据关联挖掘算法比以往的挖掘算法在求解性能上有了较大的改进,但仍然存在2个主要缺点:建树和挖掘过程都要求占用大量的内存;挖掘大型数据库时运算速度慢。以Fp-Growth算法为基础,针对其存在的不足,本文提出一种改进的数据关联挖掘算法,改进后的Fp-Growth算法的主要性能得到一定程度的提高,算法有效性在几个具体应用中得到体现。
[1]N.Pasquier,YBastide,R.Taouil,and L.Lakhal.Closed set based discovery of small covers for association rules[J].Proc.BDA conL,October 1999.361—381.
[2]Brachman,R.,and Anand,T.The Process of Knowledge Discovery Databases[J]:A Human - Centered Approach,In Advance in Knowledge Discovery and DatMining,37—58,eds.U.Fryyad,G.Piatetsky—Shapiro.P.Smyth and R.Uthurusamy.Menlo Park.Calif,APress.1996.
[3]Jackson G.A.,Leclair R.S.,Ohmer C.M.,et a1.Rough set applied to materials data.Acta Material ia,1996,44(11).4475—4484.
[4] Wang Dexing,Hu Xuegang,Wang Hao.The Research on Model of MiningAssociation Rules Based on Quantitative Extended Concept Lattice[J].IEEE The First International Conference on Machine Learning and Cybernetics,Nov.4 -5,2002,Beijing.
[5]文拯.关联规则算法的研究[D]:[硕士学位论文].长沙:中南大学信息科学与工程学院,2009
