面向社交网络的用户数据挖掘技术研究
2013-02-28朱应坚
陈 康,朱应坚,向 勇
(1.中国电信股份有限公司广州研究院 广州510630;2.中国电信股份有限公司广东分公司 广州510081)
1 引言
近年来社交媒体风靡全球,与此同时产生了大量的用户数据,如何充分有效地挖掘和利用这些社交数据成为最热门的课题。利用社交媒体数据,可提高理解新现象的能力,实现商业智能化,为用户提供更好的服务,并自动发现创新性商机。例如,社交数据挖掘将识别出在互联网社交环境中具有重要影响力的人;发现和归类隐藏在社交网站中拥有不同兴趣的群组;识别特定用户并根据用户某一时刻的主观情感进行主动规划;开发商品购买推荐系统和朋友推荐的应用;掌握IP网络的演化和实体关系的改变过程;保护社交网络的用户隐私和安全;建立和加强用户与用户之间、用户与实体之间的信任度等。社交媒体的数据挖掘是一个生机勃勃的交叉学科领域,不同学科背景的学者为社交媒体发展做出了巨大贡献。
2 社交网络数据
2.1 社交媒体的分类
社交媒体主要分类如表1所示。

表1 社交媒体主要分类
2.2 社交数据的特点
社交媒体数据与传统数据有很大的差异性,呈现出数量大、噪声大、非结构化、分散、动态的趋势,这给数据挖掘任务带来挑战,同时对于新型、高效的数据算法的需求也越来越强烈。
2.3 社交数据的价值
很多关于人类行为学的问题都可以通过社交网络媒体的数据挖掘这个课题来解决。例如,社交媒体可以帮助广告商发现对其产品感兴趣的客户,最大化广告投放效益;也可以帮助社会科学学家分析人类活动行为特征,如群组内活动和群组外活动。
3 社交数据主要研究方向
3.1 社团分析
社团是由个体组成的,并且社团内个体之间的交互活动比个体与外面的活动更为频繁。基于此定义,社团也常常被称为群组、集群、凝聚子群或者模块。在社交网络中,社团大致可以分为显性和隐性的群体。显性群体是由用户间明显的关注关系产生的,而隐性群体则是由自然的网络交流活动产生。社团分析普遍面临的问题有社团的发现、形成和演变。
社团检测往往是指在社交网络中的隐性群体的抽取。社团检测的主要挑战有:
·社团的定义可以是主观的;
·社团评估的标准可以多样化,往往没有决定性正确的。
社团检测可以分为以下4类:
·以节点为中心的社团检测,其中每个节点满足某些特性,如相互完整性、可达性、节点度、内外联系的频繁性等,典型例子包括cliques、k-cliques和kclubs;
·以群组为中心的社团检测,其中每个群组需要满足一些特性,如最小群密度(minimum group density);
·以网络为中心的社团检测,其中群组的形成是依靠把网络分区成不相交的子集来实现的,典型的例子有 谱 聚 类 (spectral clustering)和 模 块 最 大 化(modularity maximization);
·以层次为中心的社团检测,其目标是建立一个社团层级结构,分析者可以采用不同的策略实现,典型的方法分为分裂式聚类(divisive clustering)和合并式聚类(agglomerative clustering)。
本文所使用的,也是最为通用的基于模块化(modularity)值最大化算法。如一个社交网络被划分为K个社团Pk,模块化值M(Pk)用于评价社交网络社团划分质量的度量,计算式为:
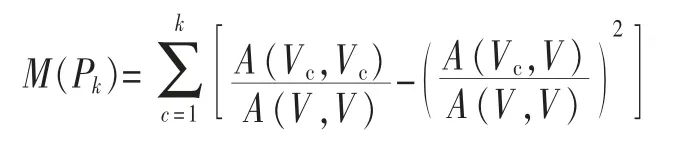
社交网络的K个社团结构特征越显著,其M(Pk)值越大。社交媒体网络是高度动态性的,因此社团会在动态的网络中随时扩大、收缩或消失,因此社团进化分析的目标包括探索一个社团随着时间迁移在动态网络中的交互活动演变模式。
3.2 影响力建模
分析潜在社交网络是由影响力驱动还是同质性驱动的,这点非常重要。例如在广告行业,如果该社交网络是影响力推动,那么有影响力的用户被分辨出来后就可以有偿性地让他们向社交网络的用户推荐产品或服务;如果这个网络是同质性(相似性)驱动的,那么就应该将某些用户作为目标直接向其推销商品。目前大多数社交网络兼有同质性和影响力驱动,因而如何分辨哪一个为主导力是一个巨大挑战。检测出社交网络中具有影响力的核心节点极为重要,下面介绍几种对影响力建模的实现方式。
(1)一个用户在社交网络中的度数越大,其影响力也越大:
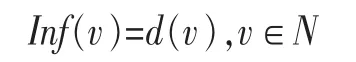
其中,v为某一用户节点,N为整个社交网络。
(2)考虑社交网络的信息(如微博)的交互活动,根据用户的消息记录计算每条社交消息的平均转发率,以每条消息引起的转发行为作为用户影响力的衡量指标:
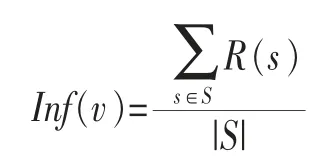
其中,s为用户v所产生的社交消息,R(s)为s的评价转发数量,S为用户v所有消息的集合。
(3)基于谷歌的PageRank算法思想,如果社交网络某一用户被越多的优质用户所关注,其影响力就越大,以此为根据得到社交关注排名的影响力算法如下:
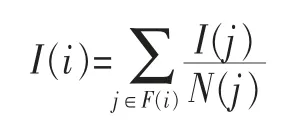
其中,I(i)为用户i的影响力,F(i)为关注用户i的所有用户集合,N(j)为用户j的关注用户数量。
3.3 情感分析与意见挖掘
情感分析和意见挖掘的目标是从用户发布的内容中自动抽取出观点。由于自然语言存在歧义性,情感分析相当有难度。情感分析的主要步骤为:
(1)找出相关文档;
(2)找出相关的部分;
(3)找出全部感情;
(4)量化分析每个感情;
(5)聚集所有感情形成一个概述判断。
意见挖掘的主要组成部分是:
·意见表达的对象是谁;
·对这个对象表达了什么意见;
·意见是由谁来表达的。
3.4 社交推荐
传统推荐系统是根据用户对物品的关注程度或历史购买记录来推荐相关物品。社交推荐在原有方法的基础上,充分利用了用户的社交网络数据及其关联信息。社交推荐建立在3个假设的基础上:
·人们倾向于与自己有社交好友关系的用户分享相同或相近的兴趣(同质性);
·用户更容易被他们信任的朋友影响;
·与随机推荐相比,用户更愿意相信朋友的推荐。
3.5 信息散布和溯源
信息散布和溯源主要研究信息是如何散布的,并探索出了信息散布的不同模型,包括独立级联模型(independent cascade model)、阈值模型(threshold model)、易受感染模型(susceptible-infected model) 和 易 受 感 染 恢 复 模 型(susceptible-infected-recovered model)。例如分析流言、病毒和疾病暴发期间的传播速度。
从社交媒体视角思考信息数据的两个重要问题:
·信息如何通过社交媒体网络传播及其影响因素;
·那些合理的信息实质上来源于哪里。
4 社交数据的挖掘分析
本文对豆瓣、Flickr、Facebook、Twitter等主流社交媒体网站进行了用户数据的获取、计算和统计分析,并重点分析节点度数(即某节点与其他节点联系的数量)分布、节点度数相关性等。
4.1 节点度数分布
本文假设社交网络的数据与结构是通过图(graph)来表示的,其定义为:
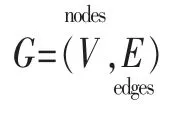
节点(node)为用户;边(edge)为用户之间产生的所有联系,既可以是有向的,即每个联系都来源于一个节点并终止于另外一个节点;也可以是无向的,即两个节点之间的联系是不区分来源和目标的。
定义一个节点i的度数为di,即该节点与其他节点联系的数量。
(1)入度
入度(in degree)表示到该节点发生联系的数量,如图1所示是社交网站入度值的互补累积分布函数(complementary cumulative distribution function,CCDF)分布。
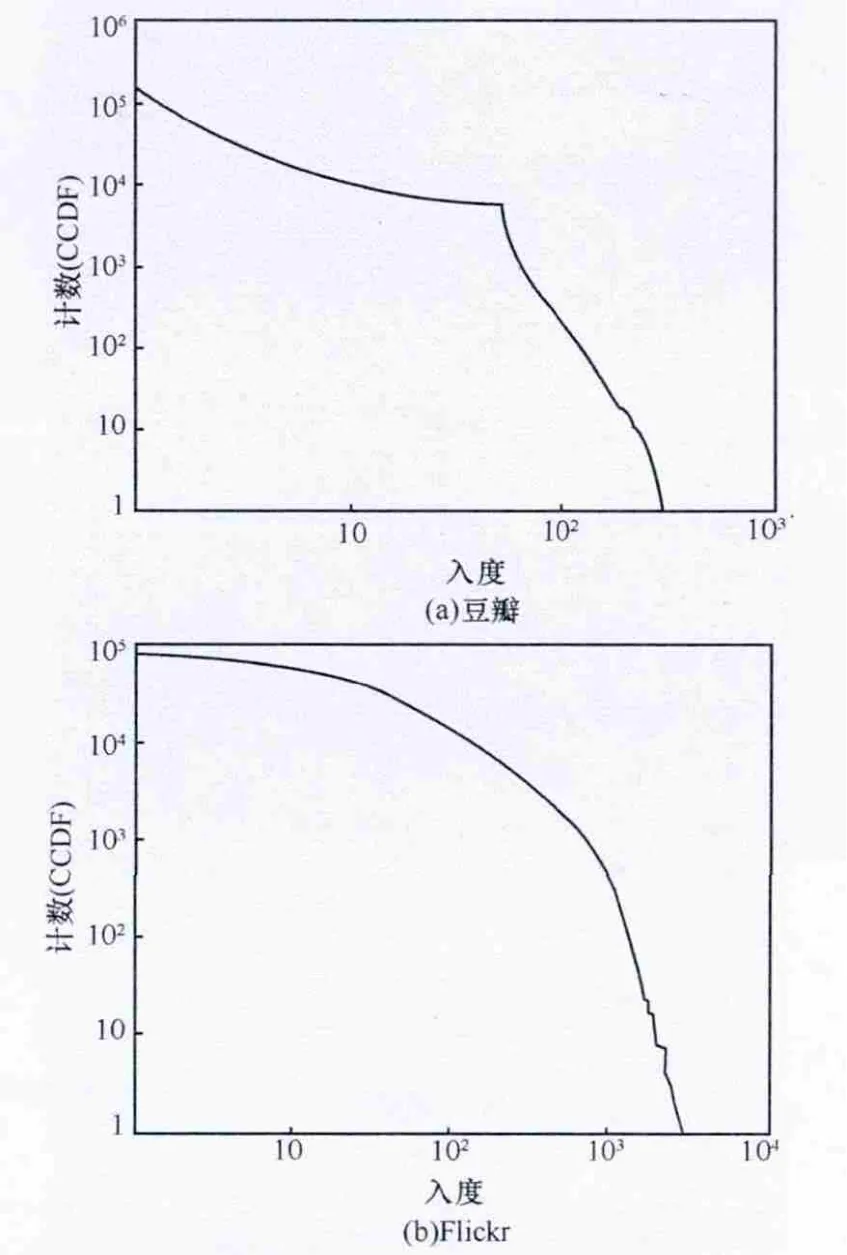
图1 社交网站入度值的CCDF分布示例
(2)出度
出度(out degree)表示从该节点出去发生联系的数量,如图2所示是社交网站出度值的互补累积分布函数分布。
节点度数的分布情况是对社交网络结构最好的刻画。从以上的入度和出度的CCDF图和社交网站的计算结果来看,其分布都是遵循指数定律(Power-Law)的。
普通网站与社交网站的节点联系分布有明显区别,结果表明:5%的普通网站节点占据了75%的进站链接(入度),但只占了25%的出站链接(出度)。普通网站中的进站链接比起出站链接更容易集中在一些少数的高度数节点中,而Flickr等大多数社交网站,节点的进站和出站链接占比非常相近。
在社交网络中拥有高出度的节点往往也拥有非常高的入度。本文分析的社交网络在入度值和出度值排名前1%的节点中有65%是重叠的,而在普通网站中只有20%是重叠的。这说明社交网络中活跃的用户创建了大量连接,同时也是很多连接的目标,起到了网络核心点作用。
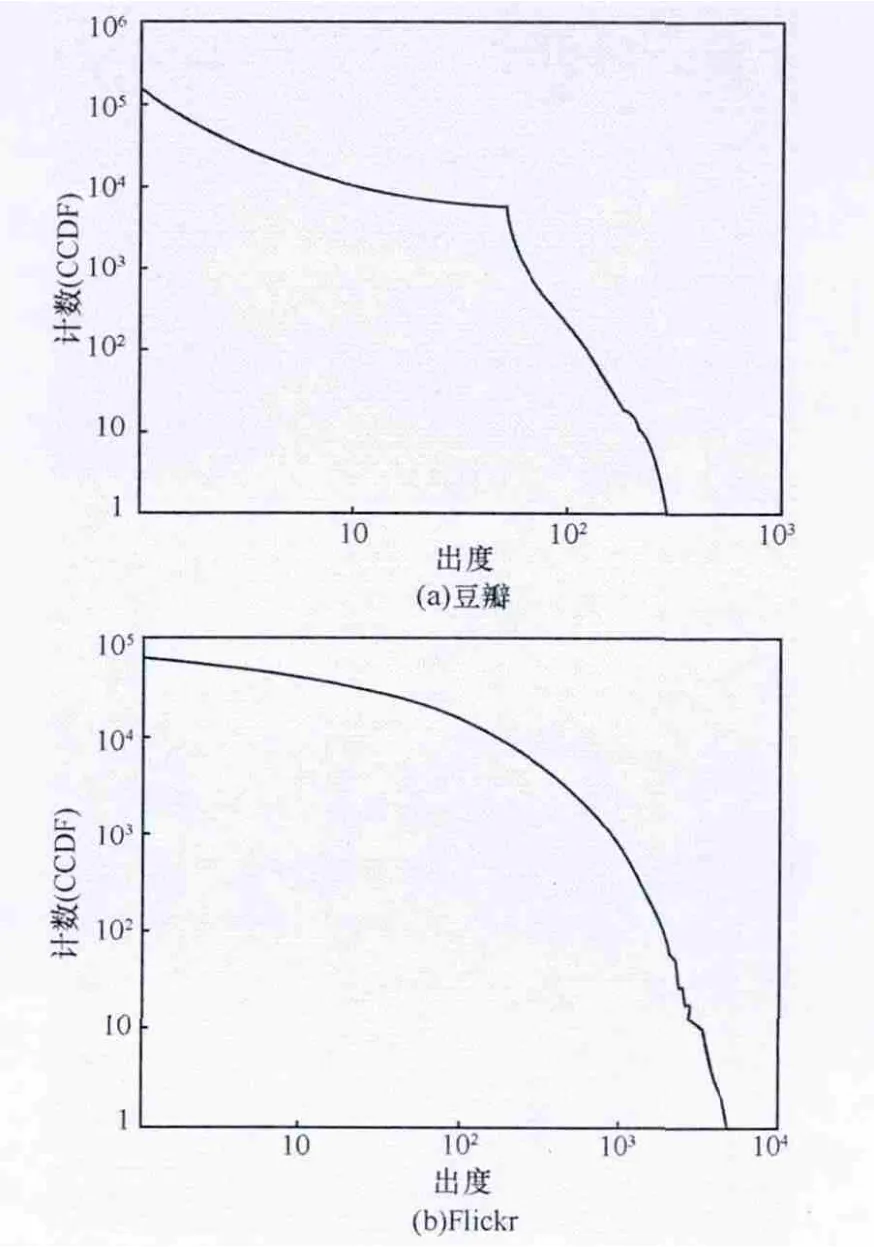
图2 社交网站出度值的CCDF分布示例
4.2 节点度数的相关性
(1)联合社交度分布
联合社交度分布(joint degree distribution)意为某一度数节点连接到其他度数节点的可能性,度量值为knn,计算方式为:给定一个社交度(social degree,即di)的值N,knn为链接到度数为N的所有节点的社交度平均值。
图3表明了Facebook为上升knn分布;但并不是每个社交网络都是这样,如YouTube为下降趋势,这是由于“名人效应”产生的合理结果:一群不受欢迎的用户关注了少量的炙手可热的明星。
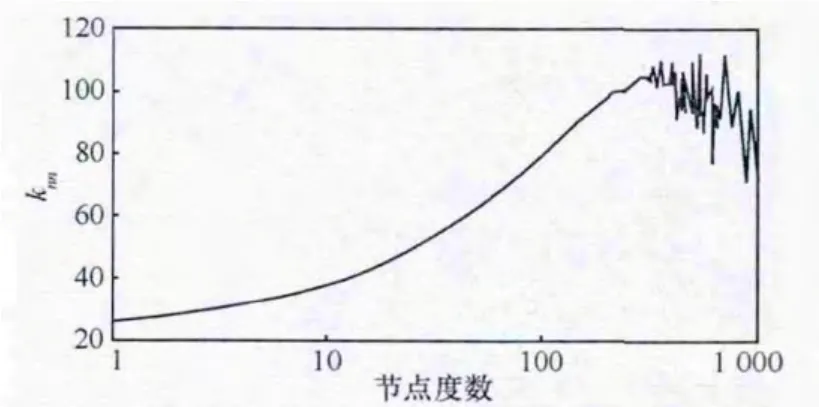
图3 Facebook不同社交度的用户与knn值的关系
(2)同配性系数
同配性系数(assortativity coefficient),缩写r,为节点连接到其他类似度数节点的可能性,取值范围为[-1,1]。当r>0,节点连接到其他类似度数节点的概率则大,大部分社交网站的r都为正值;当r<0,节点倾向于连接到不相同度数的其他节点,如YouTube和普通网站。表2所示为各社交网络的同配性系数值。

表2 各社交网络的同配性系数值
正数的同配性系数值也说明了该社交网站的高度数节点紧密联结在一起形成核心,而低度数节点则分布在网络的边缘地带。
4.3 路径长度、直径与半径
通常使用平均路径长度、半径和直径用来衡量一个社交网络(区域或全局性)中用户之间的距离。
·离心率(eccentricity):一个节点与社交图中所有其他节点的最大距离。
·半径(radius):该社交图中所有社交离心率的最小值。
·直径(diameter):该社交图中所有社交离心率的最大值。
·平均路径长度(average path length):该社交图中所有节点对之间最短路径距离值的平均值。
表3说明社交网站的3个距离度量值都远小于普通网站,而平均路径长度都小于6,这也验证了社交服务网站符合“六度分隔理论”或称为“小世界理论”,即“最多通过6个人就能够认识任何一个陌生人”。
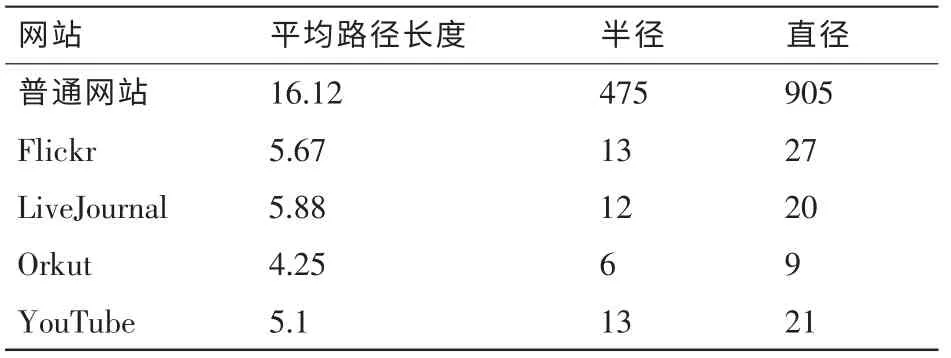
表3 普通网站与社交网络的平均路径长度、半径和直径
4.4 社区聚类与网络核心
(1)用户之间的群组聚类
聚类系数(clustering coefficient)用来刻画用户节点之间联系的紧密程度,其计算式为:
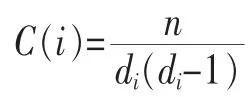
其中,n为节点i的所有邻居间的联系数量。
而一个社交图G的平均聚类系数(average clustering coefficient)的计算式为:
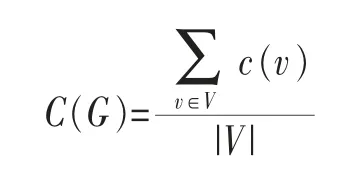
平均聚类系数的值越高,说明该群组中节点间的联系越紧密。图4所示表明小群组的成员往往比大群组成员的聚类系数高,也结合得更为紧密;低度数节点往往只参与少量的群组,而高度数节点倾向于成为多个群组的成员。
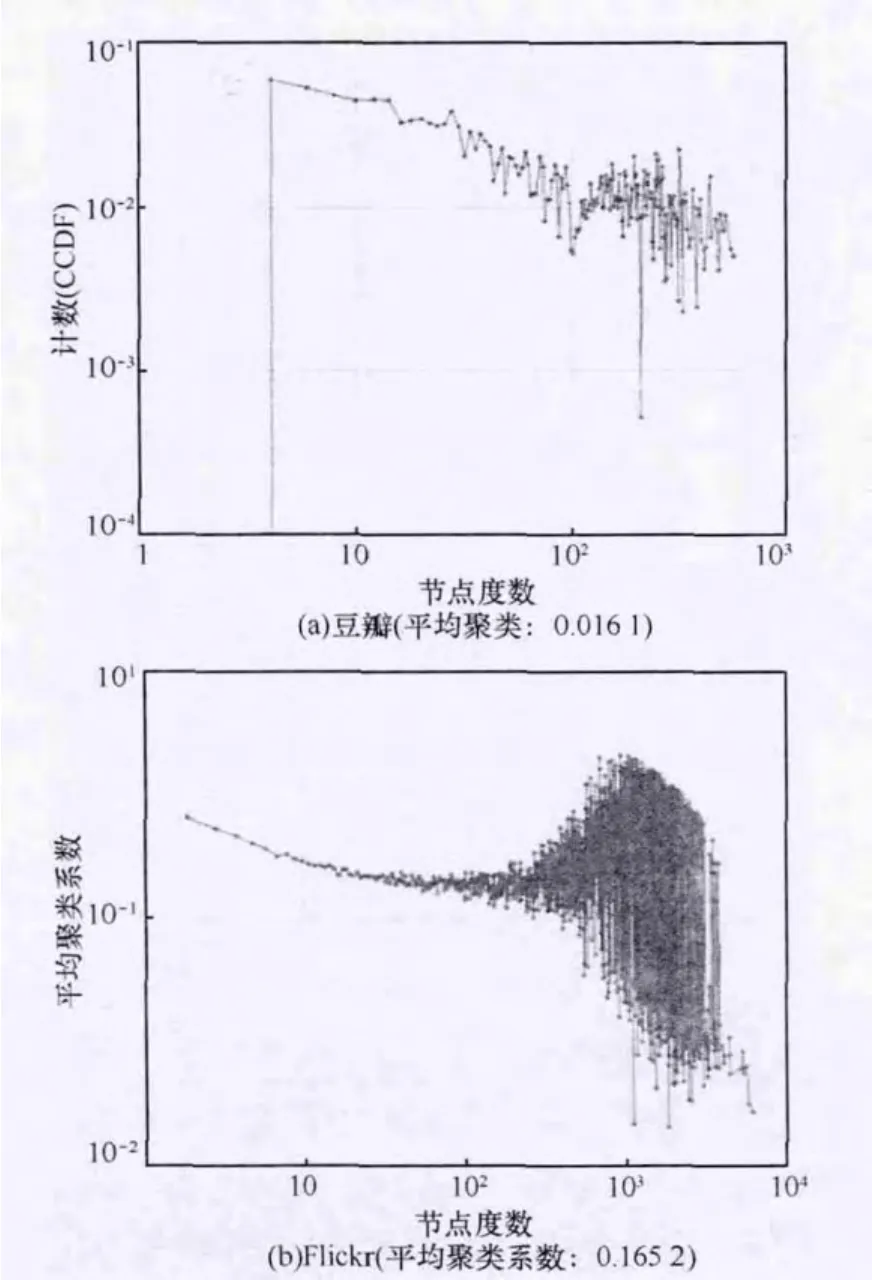
图4 关系图中节点度数与平均群组聚类系数大小的关系
(2)社交网络的核心节点
社交网络结构的核心必须满足两个条件。首先,是不可替代的连接作用,除去网络核心使得其他的节点被分割成许多细小群组;其次,核心必须是通过很小的直径值相连的。因此核心就是能使网络的其他部分保持紧密连接的小群组。本文研究数据表明,大部分社交网络都拥有紧密联系在一起的核心点,占高度数节点的1%~10%,删除这些核心将会完全破坏社交网络图的结构。
5 社交关系图的可视分析
在Twitter中,以“@name”方式向其他用户发送一个或多个以“#theme”方式标记的主题信息,以达到传递信息。本文以此为例,介绍社交关系图的可视分析过程。
5.1 数据的预处理
通过Twitter API,用户可发表信息、主题、用户信息、模板和背景等内容。预处理后的数据含有560个节点和1 257条边(其格式分别如表4、表5所示)。

表4 节点信息示例
表5 边信息示例
5.2 结果的可视化
(1)社交图的可视化
使用Gephi可视化软件对数据进行处理和可视化:
·在数据资料面板对数据进行添加、删除以及合并等处理;
·在统计面板分别进行“网络直径”和“模块化”分析;
·在 流 程 面 板 对 图 分 别 使 用 “Force Atlas”、“FruchtermanReingold”和“Label Adjust”3个 算 法,并在排序面板设计节点、边和标签的颜色与大小。
·对子网络(社团)进行详细分析,在滤波面板选择库中的“属性”文件夹,并添加其中的模块化分析,对图形结果进行过滤和分析。
Twitter数据的可视化结果如图5所示,含有@字符的节点是用户节点,含有#字符的节点是主题节点,而箭头表示用户发表的主题或是一个用户@向另外一个用户。由整图可以看出,用户ddjournalism、mirkolorenz、jplusplus、jeanabbiateci为digiphile最活跃、影响力最大的用户,而opendata、dataviz、data以及projectk是讨论得最多的主题。
(2)社团检测
社团的识别和输出就是将用户间的关系进行可视化显示,了解社团的成员情况。在图5的基础上,以用户“ddjournlism”为中心,进一步分析了其社团结构,如图6所示。
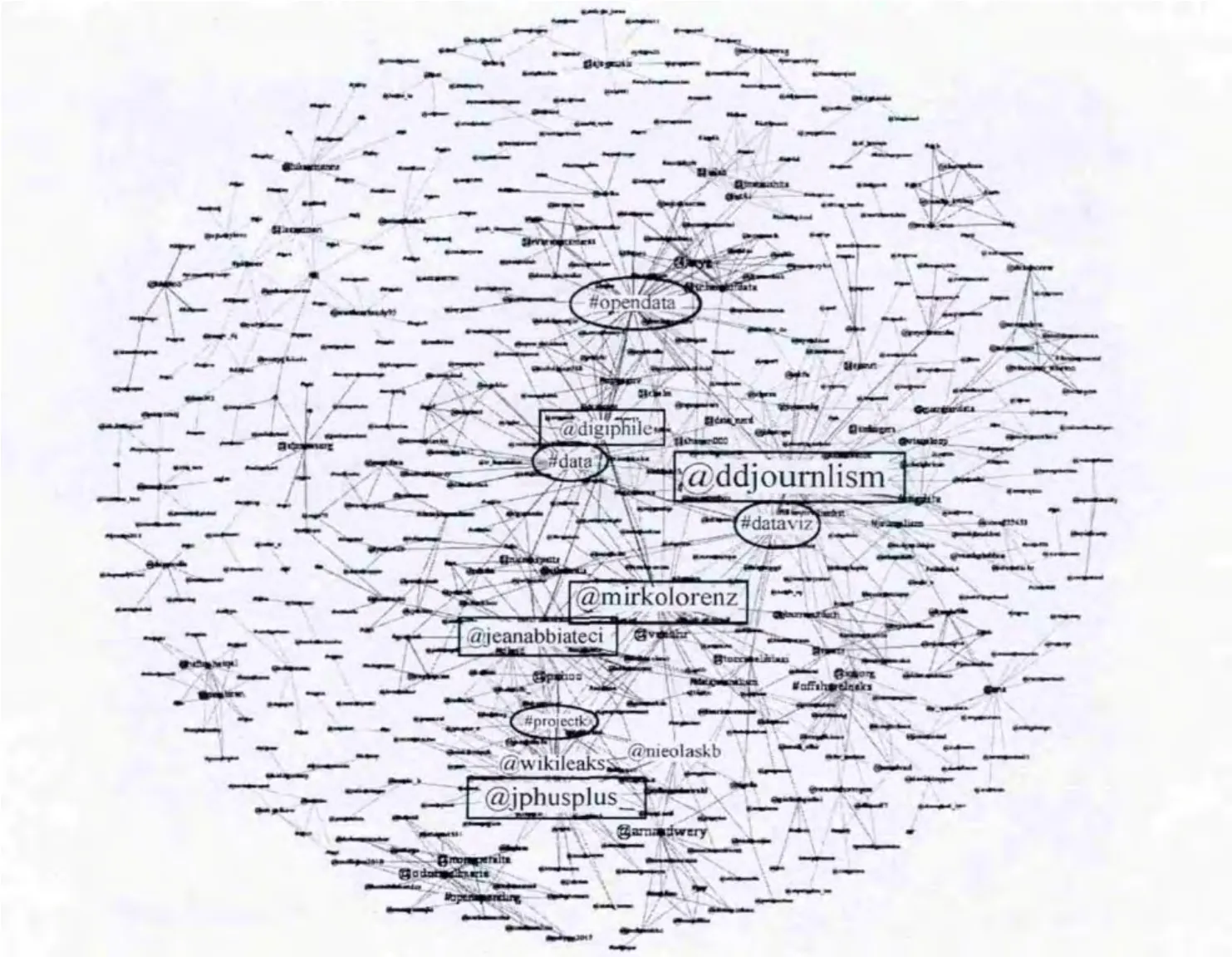
图5 Twitter用户关系网络的可视化效果
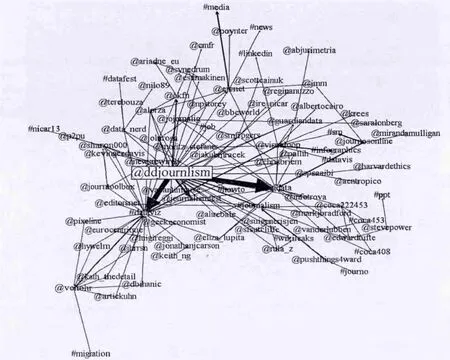
图6 以用户“ddjournlism”为中心的社团结构
(3)主题分析
对特定的话题进行分析,以了解哪些用户讨论了某个话题。图7展示了以“opendata”主题为中心的主题结构。

图7 以主题“opendata”为中心的主题结构
(4)社团与主题分析的关系
在一个同时包含用户和主题的数据集中进行社团与主题分析,这两个分析之间必然有区别与联系。区别在于一个社团之间交流信息可以不带主题,而主题则必须要用户创造和传播,因此社团中用户可以形成链、树或图,而一个主题则必须直接连接到用户;联系则是当一个社团在交流时,总会有一个特定的话题,如用户ddjournalism创造了话题dataviz,而讨论和传播这个话题的用户大多都在以创造者为中心的社团内。
6 结束语
社交媒体作为大数据的主要类型,正展现出它的革新性应用,例如政治选举、工作申请、商务推广和网络化客户服务;而挖掘社交网络的商业应用模式能加速传染式营销,使各类基层团体快速增长,用于趋势分析和销售预测。社交数据挖掘研究的初步成功验证了社交媒体数据挖掘社团的光明前景,有助于扩大和发展对在线和离线的人类活动和交互模式的研究。社交媒体数据会继续着它的高速增长步伐,而新算法和新工具亟需我们继续探索研究。
1 Newman M E J,Girvan M.Finding and evaluating community structure in networks.Phys Rev E,2004,69(2)
2 White S,Smyth P.A spectral clustering approach to finding communities in graphs.Proceedings of 5th SIAM Int’l Conference on Data Mining,Philadelphia,USA,2005
3 Girvan M,Newman M E J.Community structure in social and biological networks.Proceedings of National Academy of Sciences of the United States of America,2002,99(12):7821~7826
4 Alon A,Tennenholtz M.Ranking systems:the PageRank axioms.Proceedings of the 6th ACM conference on Electronic commerce(EC-05),Vancouver,Canada,2005
5 李绍华,高文宇.搜索引擎页面排序算法研究综述.计算机应用研究,2007,24(6):4~7
