Turbo码的DSP和FPGA实现之比较
2013-01-14张永超张志丽
张永超,蒋 博,张志丽
(1.河北远东通信系统工程有限公司,河北石家庄050200;2.中国电子科技集团公司第五十四研究所,河北石家庄050081)
0 引言
法国学者C.Berrou等人于1993年提出了具有几乎接近Shannon极限的Turbo码,其不仅在低信噪比的高噪声环境下性能优越,而且具有很强的抗衰落和抗干扰能力。3GPP、LTE及Wimax等无线标准组织纷纷将其作为其信道编码方式。同时,卫星移动通信系统由于其受移动性及环境影响,更需要Turbo码这类纠错性能强大的信道编码来进行保障。
Turbo码采用交织器将信息序列与交织之后的序列分别经过卷积编码器得到并行级联卷积码,然后采用软信息反复迭代译码。Turbo码译码算法主要有:逐序列译码的软输出的维特比译码算法(SOVA)和逐比特译码的最大后验概率译码算法(MAP)。MAP算法由于其相对于Shannon容量,在Eb/N0小于1 dB时,便可得到可接受的译码性能,得到了广泛应用。
Turbo码在工程实现上一般采用DSP方式或者FPGA方式。本文对该2种实现方式进行了设计和比较。
1 Turbo码编译码原理
1.1 Turbo编码器原理
Turbo码编码器是由2个递归系统卷积码(RSC)通过交织器连接而成。图1是并行级联卷积码(PCCC)的编码结构图。输入的信息序列,及该序列经过交织处理之后的序列分别被送入2个并行级联的分量编码器,这2个分量编码器结构相同,且工作在相同的时钟,仅是由于输入序列不同,所以得到的输出序列也不同。
假设输入信息序列为u=(u1,u2,…uN),交织器对该输入信息序列进行交织之后的序列为u1=分量编码器1对原始输入信息序列进行编码,编码后的输出序列为Xp1,分量编码器2对交织后的序列进行编码,编码后的输出序列为Xp2。为了得到不同码率的码字,可以对Xp1和Xp2进行删余,删余之后的序列为Xp,将信息序列和Xp进行复接即可得到编码后的输出。

图1 Turbo码编码器原理图
1.2 Turbo译码器原理
Turbo码的译码一般采用软输入软输出(SISO)的反馈迭代递推算法。其译码模块一般包含2个相同的、并行连接的RSC分量译码器,与编码器中的2个分量编码器相对应,另外还包含一个与编码器中相同的交织器和一个相应的解交织器。其译码模块的构成框图如图2所示。

图2 Turbo码译码器原理图
Turbo码的译码时通过2个分量译码器交错重复译码来完成的。首先将信息序列ys和校验序列y1p送入到分量译码器1,计算出相应的软信息L1。将信息序列和L1经过交织器后,连同y2p共同送入分量译码器2,计算出相应的软信息L2,将L2进行解交织作为先验信息送入到分量译码器1;这便是一次迭代的过程。2个分量译码器之间互相反馈软信息,进行迭代运算。经过一定迭代次数后,2个分量译码器的输出便趋于一致,对其进行判决,即可得到译码结果。
2个分量译码器采用相同的结构。基于最大后验概率(MAP)算法可以取得最佳的Turbo码译码性能,但是由于其采用了大量的指数及乘法运算,硬件实现比较困难。Log-MAP是MAP算法在对数域的简化,它避免了指数运算,将乘法运算转换为加法运算。Max-Log-MAP在Log-MAP基础上,将对数运算转换为max*运算,大大降低了硬件实现的难度。
Max-log-MAP算法是逐比特最大后验概率算法。该算法定义的max*运算为:
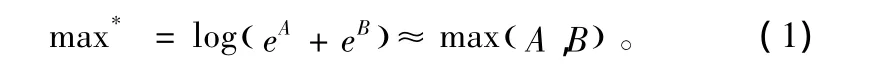
该算法需要对每个比特计算其前向传递概率、分支转移概率和后向传递概率。
分支转移概率:
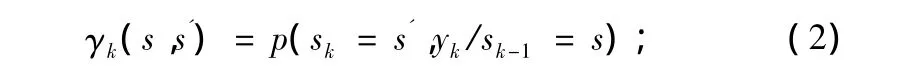
前向传递概率:
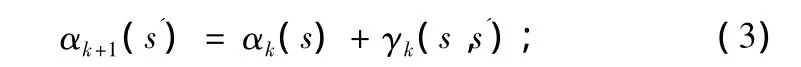
反向传递概率:
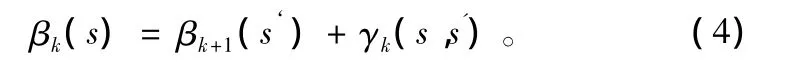
2 Turbo码实现及性能
本次试验采用的3GPP标准中的RSC编码器(其生成方式如式(5)和式(6)所示)。交织器为QPP(二项式置换)交织器,译码算法为Max-Log-Map算法。迭代次数为4次。
2.1 DSP实现
验证设计所采用的DSP是ADI公司推出的TigerSHARC(TS)系列信号处理器 ADSP-TS201S。它是一种超高性能静态超标量浮点DSP,可运行主钟达600 MHz,非常适合于对计算能力和实时性有苛刻要求的大计算量的信号处理任务。
在验证过程中,RSC码的结构可用生成矩阵的方式表示。当前编码器的状态为(reg1,reg2,reg3),则其公式如下所示:

编码是通过建立Trellis转移图进行实现的。Trellis图是一个事先生成存储好的一个状态转移表,只要给出编码器当前状态以及输入的信息比特,便可通过查表的方式得到编码器下一转移状态和对应的输出比特。该状态转移表可以用C语言的结构体实现。Trellis转移图可根据式(5)和式(6)生成。
交织可通过查表完成。QPP-Interleaver函数用来实现QPP算法生成交织矩阵。QPP交织需要确定二项式置换的2个系数。该系数可通过文献[4]来确定。
Max-Log-Map算法对3种度量值进行归一化,做了防溢出处理。本实现中,采用浮点实现,送入到译码模块的数是浮点型数据,精度较高。
2.2 FPGA实现
验证设计所采用的FPGA是ALTERA公司推出的StratixⅡ系列芯片EP2S180F1020I4。该芯片具有多达180 K个等效逻辑单元(LE)和9 Mb的RAM。
在FPGA上对Turbo码编码器的设计关键在于RSC编码模块的设计、交织模块的设计、打孔模块的设计以及各模块时序的控制上。
交织矩阵表可作为参数由MATLAB提供,存储在ROM表中。打孔根据所要求的码率按照“尽量平均”的方式打孔,即删除的校验比特在整个校验序列中最好均匀分布。
编码部分的FPGA框图如图3所示。

图3 编码模块结构框图
编码模块的输入为外部提供的待编码的二进制序列x,输出为编码之后的码字序列。输入数据首先经过RSC编码器进行编码;其次,输入数据经过交织得到交织之后的数据;之后,交织后的数据经过RSC编码器编码;最后,根据所需的码率进行打孔。
译码部分FPGA框图如图4所示。

图4 译码模块的结构框图
译码模块的输入首先经过解打孔,分解出信息序列x,校验序列z1,校验序列z2。之后,将信息序列进行交织,此处的交织器采用和编码时完全相同的交织器,得到交织之后的序列x_interleaved。将该4组序列送入到迭代译码模块,进行一定次数的迭代译码。最终迭代的结果以软信息形式存储在存储器2中,以待最后的判决。
迭代译码模块是2个子译码器的相互传递软信息迭代译码的综合。其中,译码器来实现Max-Log-Map算法,解交织器是交织器的逆过程。
2.3 性能分析与比较
以Turbo码(104,220)为例,比较了 DSP实现和FPGA实现的差异。
在DSP上实现时,程序中调用time.h头文件,利用clock()函数,计算出了Turbo编译码所使用的时钟周期数,如表1所示。

表1 DSP的处理时间
在FPGA上实现时,用QuartusⅡ编译综合后的资源占用情况,如表2所示。

表2 FPGA资源占用情况
通过SignalTapⅡLogic Analyzer捕捉片内信号计算出,完成编码需要429个时钟周期,完成译码模块需要8 424个时钟周期。如果FPGA运行在50 MHz时钟频率下,则编码需要约8.6 μs,译码需要约 168.5 μs。
在验证时,DSP芯片工作在600 MHz,而FPGA芯片工作在50 MHz。在FPGA上编译码所需要的总时间约是DSP上的十分之一。可见在处理时间上FPGA的优势还是显而易见的。
但是在前期代码的设计和编写周期上,FPGA并不占优势,相反DSP以其代码编修改灵活,编译时间快,容易调试等特点体现出了其优势。
3 结束语
本文既用DSP实现了Turbo码,又用FGPA实现了Turbo码,为工程实际应用提出了有效的、可靠的参考。通过综合出的信息可以更准确、迅速地估计和判断出系统中用哪种方式进行Turbo编译码更有利于实现。
[1] BERROU C,GLAVIEUX A.THITIMAJSHIMA P.Near Shannon Limit Error-correcting Coding and Decoding:Turbo-codes[C]∥ Geneva:Communications,1993.ICC '93 Geneva ,1993,2:1064-1070.
[2] 杨海芬.Turbo码编译码方法研究与实现[D].成都:西南交通大学,2003.
[3] 王新梅,肖国镇.纠错码-原理与方法[M].西安:西安电子科技大学出版社,2001.
[4] Motorola.QPP Interleaver Design for LTE[C]∥3GPP TSG RAN WG1#47bis,R1-070060,Sorrento,Italy,2007:15-19,.
[5] 冯小平,曹向海,鲍丹.TigerSHARC处理器技术及其应用[M].西安:西安电子科技大学出版社,2010.
[6] WANG Ying,DU Xinjun.LI Hui,et al.Tail-bitting Theory for Turbo Codes[J].IEEE Annual WAMICON’06,2006:1-4.
[7] 罗少兰.基于C语言的Turbo码的DSP实现[J].计算机与现代化,2006(6):28-30.
