基于TCAM的范围匹配方法——C-TCAM
2012-11-06朱国胜余少华
朱国胜,余少华,2
(1. 华中科技大学 计算机学院,湖北 武汉 430074;
2. 武汉邮电科学研究院 新一代光纤通信技术和网络国家重点实验室,湖北 武汉 430074)
1 引言
互联网路由交换网络设备需要采用分组分类技术,将到达分组的头部信息和分类规则库中的规则条件进行匹配,并根据匹配结果实现规则动作,包括转发、丢弃、队列排队等,从而实现访问控制、安全过滤、带宽控制等。和IP路由查找一样,分组分类功能处在网络设备的数据平面,需要进行每分组处理,对性能要求很高。
目前,业界普遍采用三态内容寻址存储器(TCAM, ternary content-addressable memory)来实现高速分组分类,Cisco的Catalyst 6500高端交换机采用多片TCAM来分别实现3层IP路由、访问控制列表ACL、分组分类以及NETFLOW等功能[1]。TCAM 可配置成 36bit、72bit、144bit、288bit、576bit等宽度,用于存储固定宽度的查找条件。和普通内存通过地址寻找内容不同,TCAM通过内容来定位地址,它将查找关键字和所有TCAM表项进行并行比较来定位关键字匹配的存储地址,根据得到的地址来得到存储在快速SRAM中的规则动作。TCAM的并行特性使得分组分类查找可以在固定的时钟周期内完成,目前TCAM的时钟周期可以做到2ns,可以实现 500MSPS的查找速率[2],TCAM 三态特性需要采用多达 16个晶体管来实现一个比特的存储,导致芯片面积较大而且价格较高,而TCAM的并行比较特性使得功耗很高,一个18Mbit的TCAM功耗高达15W[3]。因此在单板线卡设计中必须考虑TCAM 的成本、功耗和体积,并充分利用 TCAM的每个比特。
有效利用 TCAM 来完成高速分组分类的主要障碍是TCAM不适合实现范围匹配,TCAM的三态特性可以很容易地实现规则条件中的前缀匹配和精确匹配,比如规则条件中的地址字段和协议字段匹配,而规则条件中的范围字段比如端口范围则无法直接实现,必须转换成前缀匹配和精确匹配,一个包含范围字段的规则需要转换成多个规则才能存放在 TCAM 中,称之为范围扩张(range expansion),范围扩张一方面降低了TCAM的空间使用效率,另一方面TCAM的功耗和参与比较的表项的数目成正比,因此范围扩张会导致TCAM功耗的增加。
如图1所示为4bit宽度的范围字段范围扩张的示例,范围[1,14]需要扩张成6个前缀匹配或者精确匹配的条目,在 TCAM 中进行存放并参与匹配比较,范围[1,14]的范围扩张因子为6,每条携带范围[1,14]的匹配规则需要扩张成6条规则。
因此,基于TCAM的范围匹配主要解决如下的2个问题:①如何减少范围扩张,以有效利用TCAM的空间;②如何设计有效的TCAM匹配算法以降低功耗。
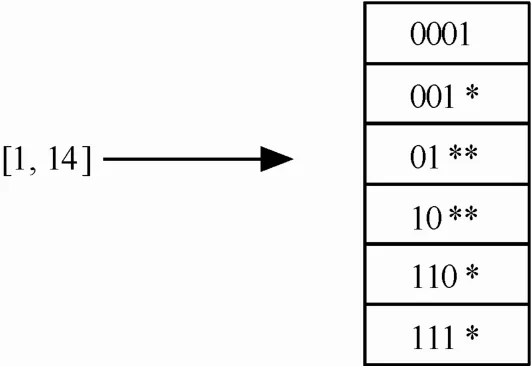
图1 宽度为4bit的范围扩张示例
2 相关工作
2.1 规则库无关范围匹配方法
对每个范围单独进行转换,无需考虑规则库里各种范围的分布以及和其他范围的关系。文献[4]提出了一种前缀扩展(PE, prefix expansion)方法,该方法将范围转换成若干个前缀,每个前缀对应一个TCAM表项,在最坏情况下一个范围需要转换成2(W-1)个前缀,其中,W为范围字段的长度,范围Rw=[1,2w-2]就是这种情况(前面的引言的范围[1,14]是4bit示例);对于长度为16的源端口和目的端口来说,最坏情况下一条规则需要转换成(2×16-2)2=900个TCAM表项,对于真实分类规则库转换显示平均会导致6倍的表项扩张[5]。文献[6]提出了利用 TCAM 额外比特对范围进行独立编码的DIRPE(database independent range preenconding )方法,假定TCAM的额外比特为2w,则每个范围只需要一个TCAM表项就可完成转换,由于TCAM的额外比特数有限,在配置为144bit宽度时,额外比特数仅为40,为减少对TCAM额外比特的需求,提出了对范围字段进行分段编码以及结合规则库相关的编码方法,增加了每个范围需要的TCAM表项数目,因此,该方法的效率和范围字段的长度和TCAM的额外比特数量相关。文献[7]提出了基于格雷码(Gray code)的范围编码方法SRGE,该方法利用了格雷码的相邻编码之间只有一个比特不同从而可以合并成一个TCAM表项的特点(将该不同比特用通配符‘*’来表示),在最坏情况下一个范围需要转换成 2(W-2)个前缀,该方法无需利用TCAM的额外比特,但仅对于短的范围比较有效。
2.2 规则库相关范围匹配方法
文献[8]提出了对每个单独的范围用一个额外的TCAM比特来表示的规则库相关范围匹配方法,只需要一个 TCAM 表项就可以完成一个范围规则的表示。由于目前规则库中单独的范围在增加,已经超过 300个,而且还在不断地增加,而额外的TCAM比特数量非常有限,同样,作者也提出分段编码方法(region-based encoding)增加TCAM表项从而减少对TCAM额外比特的需求。为了进一步对范围进行有效地编码并减少编码的比特数,文献[9]提出层次化编码方法,在每个层次里面,范围都是不相交的,对每个层次里面的范围进行单独编码,假定层Li中的不相交范围个数为Ni,则需要的比特数位lb Ni,而前述方法中每个范围需要一个TCAM比特,从而减少了每个范围需要的比特。
另外,文献[10]提出了E-TCAM方法,该方法直接修改TCAM硬件设计支持范围匹配,可以降低90%的功耗,由于需要对TCAM硬件进行修改,因此会增加每比特成本,存在兼容性和扩展性问题,短期内无法大规模部署和实现。
相比而言,规则库无关范围匹配方法和具体规则库无关,在规则更新方面具有优势。
3 C-TCAM方法
3.1 C-TCAM算法思想
我们发现:一条规则经过前缀扩展转换或者格雷码转换成多条规则后,规则条件里面的非范围字段是一样的,仅范围字段不一样,可以将多条规则存放在一个TCAM表项中,而且,只需保存一份非范围字段的拷贝,比如对于IPv4分组分类来说,采用144bit TCAM位宽,非范围字段包括源地址、目的地址、协议字段共72bit,范围字段包括源端口、目的端口共32bit,还剩余40bit可以再保存一份源端口、目的端口字段,这样可以将二条规则压缩在一个TCAM表项里面,可以成倍地减少最坏情况下范围扩张,有效利用昂贵的TCAM空间。
另外,查找时,现有商用TCAM芯片都支持全局掩码寄存器(GMR, global mask register)和分区掩码寄存器(BMR, block mask register)[2],GMR寄存器可以从纵向确定 TCAM 芯片中参与比较的比特,BMR寄存器用于支持在横向上将TCAM芯片进行分区,支持分区禁用,本方法利用了TCAM芯片的特性,在查找时通过GMR和BMR动态地选择参与比较的比特和参与比较的TCAM表项,在减少范围扩张的同时减少参与比较的 TCAM 表项数目,从而降低功耗。
3.2 问题定义和相关术语
分组分类的相关术语和定义沿用文献[6,7]的说法。分组的头部由若干个字段组成,每个字段包含若干个比特。查找关键字 KEY是从分组头部提取的K个字段的组合。查找关键字需要和存储在分类规则库中的规则条件进行匹配。
规则包含规则条件和规则动作,规则条件由相应的K个字段组成,如果分组P的K个关键字字段和规则 R的 K个规则条件匹配,则认为分组 P匹配规则R,相应会对分组P采取规则R规定的规则动作。每个规则字段f可以指定3种类型的匹配条件。
1) 精确匹配:关键字字段和规则条件字段指定的值相等。
2) 前缀匹配:规则条件字段是关键字字段的前缀。
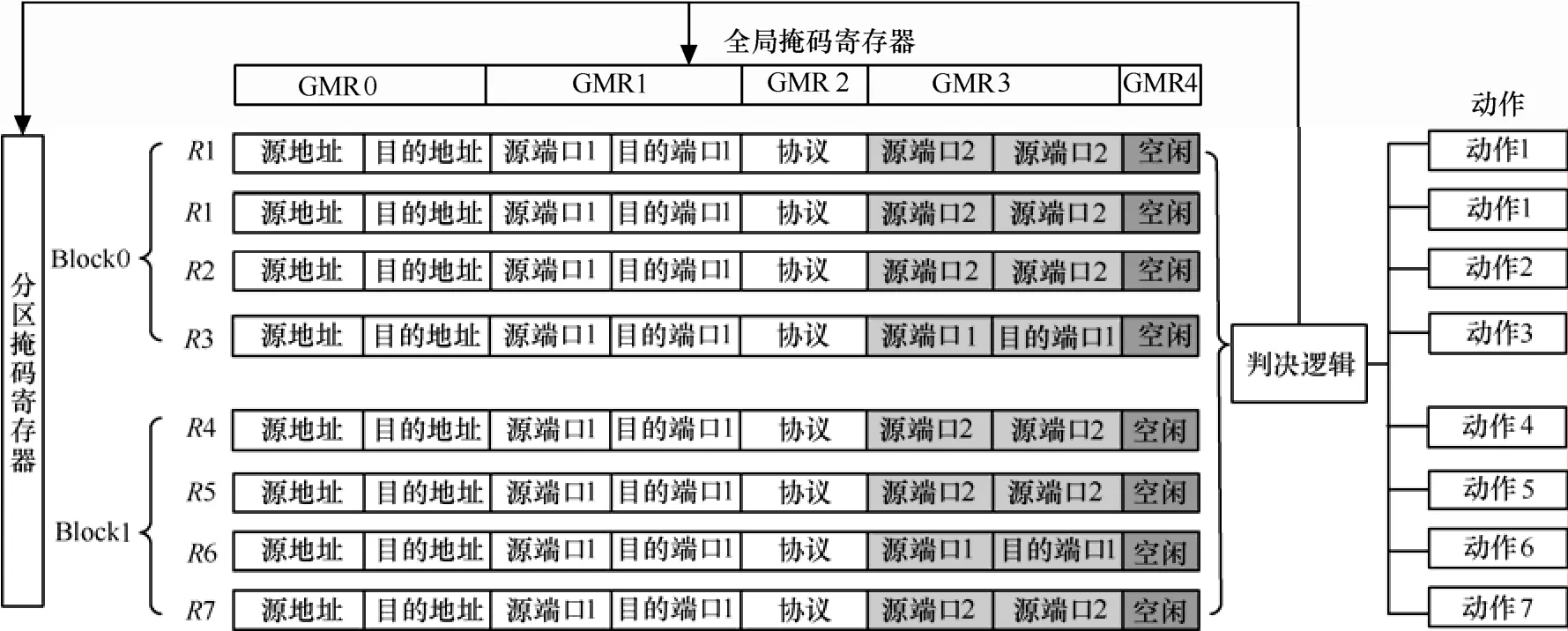
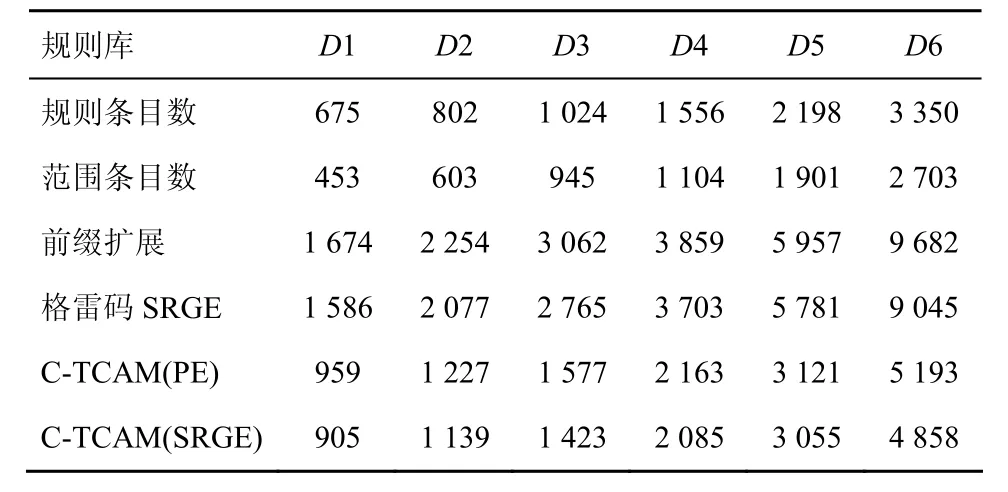
3) 范围匹配:关键字字段在规则条件指定的范围里面,比如规则条件指定的范围为[s, e],s和 e为整数,s 分类规则库可以存放在 TCAM 中以实现高速分组分类,规则在TCAM中按照优先级从高到低排序存放,高优先级存放在TCAM低地址区,TCAM总是返回第一个匹配的结果(低地址区)。TCAM的每个比特支持“0”、“1”和“*”3种状态,精确匹配规则条件和前缀匹配规则条件可以直接存放,而范围匹配则需要转换成相应的精确匹配和前缀匹配,因此一条规则R需要采用转换方法E转换成多个TCAM表项TCAMR[1, nR],范围R的扩张因子RE=nR,假定n(D)为分类规则库D的规则数量,nE(D)采用转换方法 E对分类规则库进行转换后所有TCAM表项的数目,则分类规则库D的扩张因子DE表示为 由于规则库里存在不包含范围匹配的规则,为进一步考察范围规则转换的有效性,假定r(D)表示规则库里面包含范围的规则数,rE(D)表示对这些包含范围的规则进行转换后的TCAM表项数,规则库D的范围冗余因子FRE(D)表示为 而某条规则R的范围冗余因子FRE(R),也就是规则R需要的额外的TCAM表项的个数 文章的第5节的仿真实验中将通过实验对不同算法的规则库扩张因子 DE和规则库冗余因子FRE(D)进行比较。 图2所示为C-TCAM的体系结构,对规则库中包含范围的规则进行前缀扩展或者格雷码扩展,扩展后的规则在TCAM中进行按照规则优先级排序,在每行TCAM中存放二条规则,这二条规则除了源端口和目的端口不同外,其他比如源地址、目的地址、协议和规则动作均相同,因此除了源端口和目的端口外的其他字段只需要保存一份拷贝。图2所示假定规则库D包含R1到R7 7条规则,并且按照优先级进行排序,经过前缀扩展编码或者格雷码编码转换后,R1需要4个TCAM表项(表示为R11、R12、R13、R14)、R3和R6需要一个TCAM表项,其他规则需要2个TCAM表项,转换后的规则存储如图 2所示,R1的 4个 TCAM 表项占据 2行TCAM,其他规则均占据一行TCAM,需要注意的是,虽然R3和R6只需要一个TCAM表项,但依然在GMR3对应的比特存放了R3和R6对应的源端口和目的端口,而且和 GMR1对应的源端口和目的端口相同,这主要是为了保证匹配算法返回的结果正确,具体原因在3.4节的C-TCAM查找部分进行说明。 图中的GMR用于从纵向上选择和查找关键字进行匹配的比特,当选择 GMR=GMR0+ GMR1+GMR2,GMR3和GMR4对应的比特不参与匹配比较;当选择 GMR=GMR0+GMR2+GMR3,GMR1和GMR4对应的比特不参与匹配比较,可以看出,GMR4对应的比特为空闲比特,在2种情况下都不参与比较,对于IPv4分组分类,TCAM配置为144bit宽度,GMR4的宽度为 8bit,某些规则条件还包括TCP标志字段,这时这些空闲比特可以进一步被利用。 图中的BMR用于从横向上选择参与匹配比较的TCAM表项,由于规则存在重叠关系,C-TCAM方案需要经过二轮匹配才能确定匹配的规则,比如R7的规则条件包含R14,但是R7定义的动作和R1不同,为保证结果正确(选择优先级高的 R14),C-TCAM需要查找匹配需要进行二轮匹配,判决逻辑用于对二次匹配的结果进行比较,并选择低地址区的匹配结果作为最终分组分类结果,对分组执行规则条件对应的动作。 经过上述的扩展和压缩存储后,减少了范围扩张数目,有效利用TCAM的空间,较好地解决了基于TCAM的范围匹配的第一个问题;对于第二个问题,需要设计有效的TCAM匹配算法减少参与比较的表项数目以降低功耗。 可以看出,表项通过压缩存储后,为了返回正确的结果,需要进行两轮查找,并选择两轮查找的索引小者作为查找结果用于定位规则动作。 在上节曾提到,虽然 R3和 R6只需要一个TCAM 表项,但依然在 GMR3对应的比特存放了R3和R6对应的源端口和目的端口,而且和GMR1对应的源端口和目的端口相同,主要是因为如果R3和R6的GMR3对应的比特放置通配,则在第二轮查找时R3和R6总是会返回匹配,会导致结果的不正确。例如,假定某关键字KEY应该匹配R72,在第二轮匹配时,R3、R6和R72都返回匹配,R3优先级最高,判决逻辑会选择 R3作为匹配结果,从而导致结果错误,如果在GMR3的对应比特放置一份和GMR1相同的源端口和目的端口,则可避免该问题的出现。 C-TCAM匹配算法如图3所示,该算法输入为查找关键字KEY,输出为匹配的规则在TCAM中的地址对应的索引,用于定位规则动作。在获取Index1之后,计算Index1所在的Block,BMR被赋值给Index1所在Block及其以上的Block,匹配得到Index2,将Index1和Index2中的较小者返回。原因是在第一轮匹配时,对于存放位置大于Index1的表项的比较是没有意义的,而且会增加功耗,通过对大于Index1的Block进行禁用,在第二轮只允许 Index1所在的 Block及其以上的Block参与比较,从而降低功耗,也不会影响结果的正确性。 图2 C-TCAM体系结构 图3 C-TCAM-MATCH2算法 上述C-TCAM方法将2个表项进行压缩存储,称之为二级C-TCAM。由于TCAM的位宽是可配的,如果经过二级C-TCAM压缩存储后还有空闲比特可用,可以进行多级压缩存储进一步提供空间利用率,查找算法经简单修改后依然适用。必须注意,多级扩展会导致查找性能的下降,因此,必须综合考虑空间、功耗和性能等因素。 表1所示为不同算法的关键指标对比,包括最坏情况下的范围转换扩张因子、对TCAM额外比特的占用需求、规则更新的代价、功耗以及匹配性能等。表中F为包含范围匹配的字段的个数(对于IP分组分类来说为2:源端口字段和目的端口字段),W为包含范围匹配的字段的长度,N为规则库规则条目总数。 最坏情况下扩张因子方面,二级C-TCAM方法比前缀扩展方法和格雷码方法降低一倍,优势比较明显。 表1 不同算法的指标对比 TCAM额外比特方面,前缀扩展和格雷码无需额外比特,二级C-TCAM方法需要2Wbit,在IP分组分类下为2×16=32bit,C-TCAM方法的额外比特是利用空闲的TCAM bit,不但不会新增另外的TCAM空间,而且对空闲空间进行了充分的利用。 规则更新方面,C-TCAM方法与前缀扩展和格雷码方法相同,一条规则的添加、删除和规则库里其他规则无关,支持规则的增量更新。 功耗方面:最坏情况下的功耗Pmax是硬件设计的功耗预算计算和电源设计时必须考虑的内容。TCAM功耗和参与比较的 TCAM 条目总数相关,前缀扩展方法和格雷码方法的最坏情况下功耗分别为 二级C-TCAM方法的功耗为 或者 参数 ρ的取值和第一轮匹配时 Index1所在的Block号相关,假定Index1所在Block号为B1,所用到的TCAM的所有Block数量为B,则 B1总是小于等于B,因此ρ总是小于等于1,C-TCAM方法功耗最低。 查找性能方面,其他方法需要一个时钟周期,二级C-TCAM需要2个时钟周期,但是可以看到,现有商用TCAM时钟周期可以做到2ns,以最小以太网分组长 672bit(包括前导码、帧间隔)来计算,为保证 100Gbit/s接口的线速转发,分组转发率要达到148.8Mpacket/s,每分组处理时延小于6.72ns,二级C-TCAM依然可以满足要求。 由于真实的分类规则包含隐私信息无法公开获取,采用Classbench[11]工具来生成分类规则库和测试用Trace文件。Classbench是华盛顿大学圣路易斯分校Taylor等开发的开放源代码分组分类规则和测试用Trace文件生成工具,Classbench通过分析真实的访问控制列表、防火墙和 Linux的IPChains,得到种子文件,这些种子文件包含用于生成分类规则库的相关参数,比如地址字段长度分布、协议字段分布、端口字段通配分布、端口范围和精确匹配分布等。Classbench生成的Trace文件包含随机的头部信息,用于分类匹配算法的测试。 利用Classbench,生成了6个规则库D1到D6,规则库的规则条目以及经过前缀扩展转换、格雷码转换、C-TCAM转换后的规则条目如表2所示。 表2 测试用规则库规则转换 从表2可以看出,经过C-TCAM转换后,TCAM规则条目大大减少。为便于比较,图4和图5给出了基于表2的不同算法的规则库扩张因子DE对比和规则库冗余因子FRE(D)对比,从图中可以看出,C-TCAM 方法的扩张因子和冗余因子比前缀扩展方法和格雷码方法的要低。因此在TCAM空间方面具有优势。 图4 不同算法的规则库扩张因子DE对比 图5 不同算法的规则库冗余因子FRE(D)对比 功耗方面,TCAM的功耗和参与比较的TCAM的条目数相关。基于规则库D3的1 024条规则,选择 TCAM Block大小为 128bit,TCAM 宽度为144bit,利用 Classbench生成测试用 Trace文件,Trace文件包含2 000个分组头信息。将2 000个分组输入不同的分类匹配方案进行仿真测试,记录每个分组头需要比较的TCAM条目的数,如图6所示。 图6(a)为前缀扩展方法和C-TCAM的匹配条目对比,图6(b)为格雷码方法和C-TCAM的匹配条目对比。图中,横轴表示2 000次实验,纵轴表示每次实验需要比较的TCAM条目数。 从图6(a)可以看出,前缀扩展方法每次需要比较的TCAM条目数固定为3 062,表现为直线,C-TCAM(PE)方法需要比较的TCAM条目数在1 577和3 154之间波动,其均值为2 457,小于前缀扩展方法的3 062。 同样,从图6(b)可以看出,格雷码方法每次需要比较的TCAM条目数固定为2 765,表现为直线,C-TCAM (SRGE)方法需要比较的TCAM条目数在1 423和2 826之间波动,其均值为2 258,小于格雷码方法的2 765。 图6 不同匹配算法需要比较的TCAM条目数(规则库D3) 针对基于 TCAM 分组分类在实现范围匹配时存在的TCAM空间利用率低和功耗高的问题,本文提出了一种新的基于 TCAM 的范围匹配方法C-TCAM:空间方面,通过二级压缩存储,C-TCAM可以将2个扩展后的TCAM表项压缩成一个,最坏情况下表项扩张因子为W-1或者W-2,提高了空间利用率;功耗方面,通过查找算法来避免无效表项参与比较从而降低了功耗;分析和仿真显示C-TCAM 方法在实现高速分组分类的同时在空间利用率、功耗等方面具有优势。 必须看到,虽然基于现有商用TCAM,C-TCAM可以支持 100Gbit/s的线速分组分类,但是该方法需要经过多个 TCAM 时钟周期才能完成一次分组分类,因此,它是一种在性能、空间和功耗上做出选择的方案。 [1] Suran de Silva. Cisco 6500 FIB forwarding capacities[EB/OL].http://www.nanog.org/mtg-0702/presentations/fib-desilva.pdf,2007. [2] Netlogic microsystems[EB/OL]. http://www.netlogicmicro.com/,2010. [3] ZANE F, NARLIKAR G, BASU A. CoolCAMs: power-efficient TCAMs for forwarding engines[A]. Proceedings of the 22nd IEEE INFOCOM[C]. San Francisco, USA, 2003. 42-52. [4] TAYLOR D, SPITZNAGEL E, TURNER J. Packet classification using extended tcams[A]. ICNP '03 Proceedings of the 11th IEEE International Conference on Network Protocols[C]. 2003.120-131. [5] SRINIVASAN V, VARGHESE G, SURI S, et al. Fast and scalable layer four switching[A]. ACM SIGCOMM 98[C]. 1998.191-202. [6] TAYLOR D E. Survey and taxonomy of packet classification techniques[J]. ACM Computer Surverys, 2005,37(3): 238-275. [7] VENKATACHARY S, LAKSHMINARAYANAN K, RANGARAJAN A. Algorithms for advanced packet classification with ternary cams[J].ACM SIGCOMM Computer Communication Review, 2005 35(4):193-204. [8] BREMLER-BARR A, HENDLER D. Space-efficient TCAM-based classification using gray coding[A]. INFOCOM 2007, The 26th IEEE International Conference on Computer Communications[C]. 2007.1388-1396. [9] LIU H. Efficient mapping of range classifier into ternary-cam[A].High Performance Interconnects[C]. 2002.95-100. [10] BREMLER-BARR A, HAY D, HENDLER D, et al. Layered interval codes for tcam-based classification[A]. INFOCOM 2009, the 28th IEEE International Conference on Computer Communications[C].2009.1305-1313. [11] TAYLOR D E, TURNER J S. ClassBench: a packet classification benchmark[J]. IEEE/ACM Transactions on Networking, 2007, 15(3):499-511.
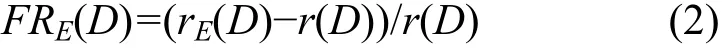
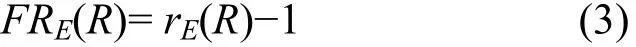
3.3 C-TCAM体系结构
3.4 C-TCAM匹配算法

4 算法比较和分析


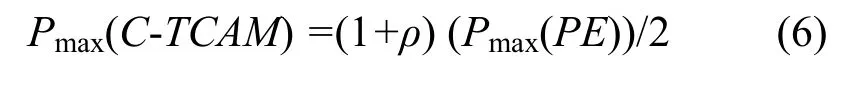


5 实验仿真



6 结束语
