基于KD-Tree的KNN文本分类算法
2012-10-17刘忠刘洋建晓
刘忠 刘洋 建晓
桂林理工大学信息科学与工程学院 广西 541004
0 引言
文本分类是在预定义的分类体系下,根据文本的特征(内容或属性),将给定文本与一个或多个类别相关联的过程。常见的分类算法包括:朴素贝叶斯分类法、支持向量机分类法,k-最近邻法,神经网络法,决策树分类法等。
KNN分类法因其思想简单,效果较好得到了广泛的应用。但是KNN是一种惰性学习法,模型仅对训练样本进行简单的存储或稍加处理,一直等到给定一个检验样本时才进行泛化。通过给定的检验样本与和它相似的训练样本进行比较来预测类别。然而,在文本分类中,由于训练样本集很大和文本特征向量的维数很高,计算训练样本的最近邻样本需要花费很多时间。
1 KNN算法的改进
针对KNN算法在文本分类上效率低下的问题,目前已经提出了很多的改进算法。归纳起来有两种途径:①降低文本向量的维度,采用的主要方法有:聚合文本向量中相关联的特征词的方法,基于隐含语义的kNN文本分类方法;②裁剪训练集,使用小样本代替大样本,采用的主要方法有:基于中心向量的分类法,基于质心的文本分类算法,基于簇的K最近邻分类算法,基于粗糙集的快速KNN文本分类算法。
本文提出的基于KD-Tree的KNN文本分类算法就是在保持原有KNN算法训练时间为零的前提下,通过对训练文本向量集建立KD-Tree,测试时,只需要对KD-Tree进行搜索,而不是对整个无序的训练集进行搜索,这样,测试时间为,远小于原始算法的,使得总的分类时间大大减小。
2 基本概念
2.1 二叉查找树
二叉查找树是一种特殊的二叉树。二叉查找树的存储规则是:在一棵二叉查找树中,节点的元素可以使用一个全序语义比较,每个节点n都要遵循下面这两个规则:
(1) n的左子树的每个节点的元素小于等于节点n的元素。
(2) n的右子树的每个节点的元素大于等于节点n的元素。
2.2 KD-Tree
KD-Tree指k维的二叉查找树,在其上可实现对给定k维数据的快速最近邻查找。与二叉查找树不同的,KD-Tree的每个节点代表k维空间的一个点,并且树的每一层都根据这一层的分辨器做出分枝决策。第i层的分辨器定义为:i mod k。
存储规则为:对第 i层的任意一个节点 n,若它的左子树非空,则其左子树上所有节点的第i mod k维值均小于节点n的第i mod k维值;若它的右子树非空,则其右子树上所有节点的第i mod k维值均大于节点n的第i mod k维值;并且它的左右子树也分别为KD-Tree。
3 基于KD-Tree的KNN文本分类算法
3.1 算法思想
传统的knn算法认为训练文本集是一个无序的集合,所以在测试时需要一个一个地比较训练文本和测试文本的相似度。其实训练文本集是一个同类文本相互聚集,不同类文本距离较大的集合。KD-Tree可以近似的描述文本集的这种关系,在KD-Tree中,某个节点的分辨器(即i mod k)都大于左子树中所有节点的第i mod k维值,都小于右子树中所有节点的第i mod k维值。可以KD-Tree利用这个特性,把训练文本向量集插入一棵KD-Tree后,在KD-Tree中搜索待测文本向量时,搜索路径所经过的节点和待测文本的相似度越来越大,而那些和待测文本相似度较小的节点则在搜索中被忽略了。这样就能通过步得到个相似文本,再计算这个相似文本中哪个与待测文本最为相似。
文本表示通常采用向量空间模型,一个文档看成是n维空间中的一个向量。文本向量维数一般成千上万,因此传统KNN算法计算开销非常大。而改进算法通过搜索 KD-Tree大大减少了需要计算相似度的文本数量,所以虽然文本维数很高,但是改进算法效率依然很高。
3.2 算法步骤
(1) 建立一个空 KD-Tree,将训练集文本向量依次插入KD-Tree中。
(2) 在测试集中取出一个待测文本向量,在KD-Tree中搜索这个文本向量,得到祖先节点集。
(3) 依次计算待测文本向量与祖先节点的相似度,相似度最大的文本类型就是待测文本的文本类型。
(4) 测试集文本是否计算完毕,是则结束,不是则转到第(2)步。
4 实验结果与分析
4.1 实验数据来源
本文选取了复旦大学李荣陆博士的文本分类语料库,共分为20个类别,分别是:Art,Literature,Education,Philosophy,History,Space,Energy,Electronics,Communication,Computer,Mine,Transport,Environment,Agriculture,Economy,Law,Medical,Military,Politics,Sports。原始训练集有 9804个文本,测试集有9833个文本。去除无效文本和重复文本后,训练集剩余8333个有效文本,测试集剩余8345个有效文本。复旦语料库不是一个均衡的语料库,比如:训练集中computer,Economy,Politics,Sports类别的文本量都超过1000个,而 Energy,Electronics,Communication类别的文本量则不超过30个。
4.2 评价手段
本文使用正确率、召回率和F1测度值来评价算法的分类效果。

4.3 结果及分析
实验分词使用的是开源分词程序IKAnalyzer3.2.8,然后去除停用词,用信息增益法选取前 1000个贡献最大的词为特征词集。使用TF-IDF作为计算文本向量特征的权重函数。结果如表1、表2、表3。
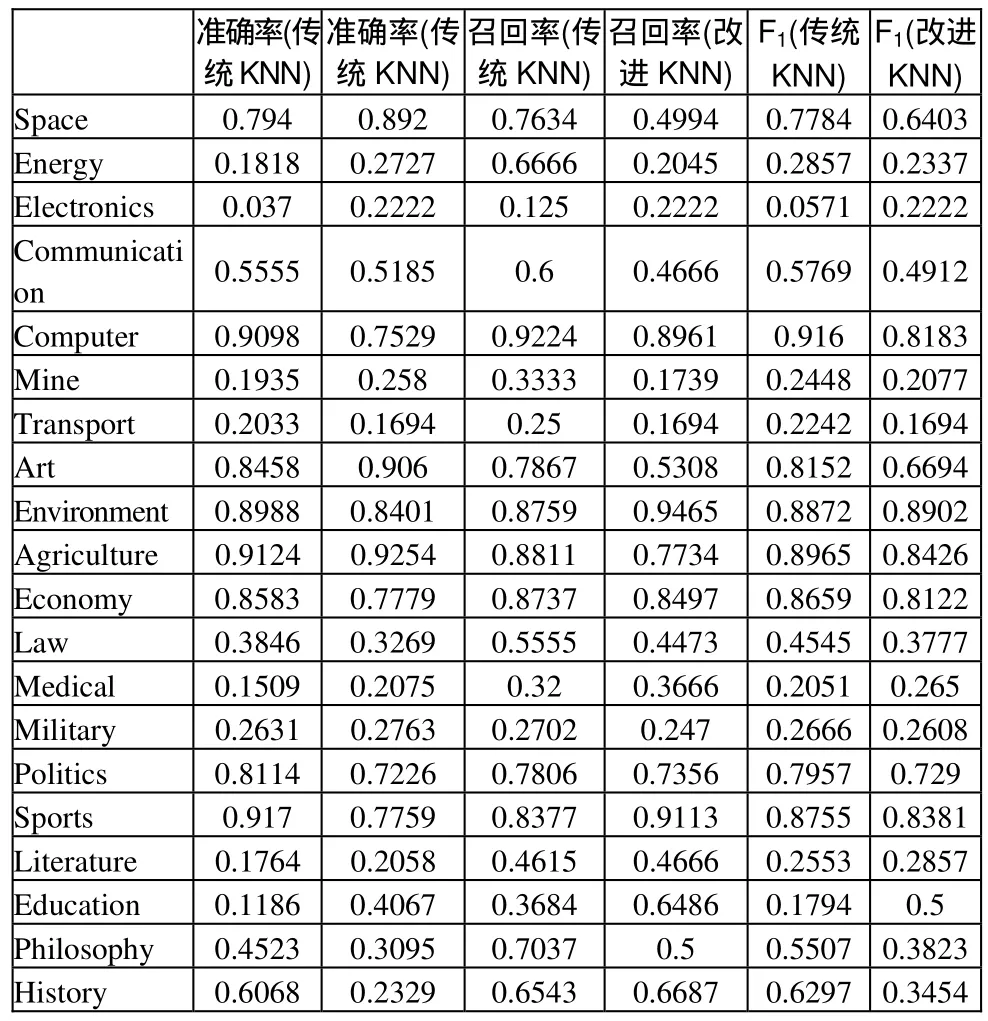
表1 算法分类精度比较

表2 算法平均准确率比较

表3 算法分类时间比较
从准确率和召回率来看,对于语料库中文本数量相对较多的类别,传统KNN和改进KNN都具有较好的分类效果,文本数量相对较少的类别,分类效果则较差。但因为语料库分布不均衡,贫样本类别的文本总量占语料库文本总数比例过少,所以平均准确率还是很高的。
从分类时间上来看,改进的KNN的效率是极高的,提高了近 60倍。这是由于 KD-Tree的时间复杂度仅有的缘故。
5 结论
针对传统KNN文本分类算法的缺点,本文提出一种基于KD-Tree的KNN文本分类算法。实验表明,改进的KNN算法的效率是非常高效的,并且随着文本数目的增加,效率也不会显著变慢。比如,假设训练集有一百万个文本,log106≈20,即比较20个文本即可计算出待测样本的类别,所以该算法有一定的Web海量文本分类和挖掘的潜力。并且该算法只需额外建立一个 KD-Tree,所以非常容易集成到已有的分类系统中,另外结合其他算法的话,比如基于语义等方法,效率和准确度会更高。
今后的工作是在改进算法的基础上,继续寻找提升准确度的更好的方法,并且进一步提升算法的效率和精度。
[1]李莹,张晓辉,王华勇.一种应用向量聚合技术的 KNN 中文文本分类方法[J].小型微型计算机系统.2004.
[2]李永平,程莉,叶卫国.基于隐含语义的 kNN 文本分类研究.计算机工程与应用.2004.
[3]鲁婷,王浩,姚宏亮.一种基于中心文档的 KNN 中文文本分类算法.计算机工程与应用.2011.
[4]柴玉梅.基于质心的文本分类算法.计算机工程.2009.
[5]潘丽芳,杨炳儒.基于簇的K最近邻(KNN)分类算法研究.计算机工程与设计.2009.
[6]孙荣宗.基于粗糙集的快速KNN文本分类算法.计算机工程.
