基于多特征表示的本体概念挂载
2012-10-15徐立恒来斯惟王渝丽
徐立恒,刘 洋,来斯惟,刘 康,田 野,王渝丽,赵 军
(1.中国科学院 自动化研究所 模式识别国家重点实验室,北京100190;2.中国大百科全书出版社,北京100037)
1 引言
近年来,本体被广泛应用于信息集成、智能信息检索、自然语言处理等领域,并被视为语义网应用和解决异构信息系统互操作问题的关键技术之一。现有本体如 CYC[1]和 HowNet[2]等大多依靠专家知识人工编撰。随着知识呈爆炸式地增长,本体创建已经遇到了知识获取瓶颈:手工编撰不仅费时费力,而且知识覆盖率低,数据稀疏,更新缓慢。因此,有必要发展监督或半监督的自动本体构建方法。人工协同创建本体是现阶段较可行的方法之一,同时 Wikipedia、Freebase[3]等大规模知识库的迅速发展,为基于网络知识库构建本体新方法[4-5]提供了契机。
目前中文网络知识库(如维基百科中文版)没有一个规范统一的分类体系,无法被用作实际应用系统的支撑。中国大百科提供了一个由专家制定的权威的体系结构,但该知识体系概念数量较少。本文使用中国大百科知识体系作为目标本体的分类体系,从网络知识库抽取概念,并将概念实例挂载到大百科知识体系的层级结构中,从而构建一个分类体系规范的海量中文本体。传统方法往往认为这个过程是一个文本分类问题,而忽略了网络百科条目中所包含的半结构化信息与语义信息。因此本文提出一种基于多特征表示的本体概念挂载方法。我们的主要贡献在于以下两点。
(1)提出了一种融合概念的文本内容、语义标签和半结构化特征判断概念类别的方法。通过对网络知识库条目中多特征的综合描述,能够有效地捕捉条目之间语义关联;
(2)构建了一个百万规模概念的多领域中文本体,并为下一步抽取本体概念属性、概念之间的非层级关系及问答服务等应用建立了良好的基础。
本文的其他部分按照以下安排:第二节简要地回顾本体构建与本体概念挂载相关工作;第三节详细描述了我们的工作及方法;第四节展示我们构建的大规模中文本体的相关性能与实验结果;第五节中我们对已完成的工作进行综述并对将来工作进行了展望。
2 相关工作
目前本体构建方法主要有以下三种:基于结构化数据的方法、基于非结构化或半结构化数据的方法[6]和基于网络知识库的方法。
基于结构化数据的本体构建主要从关系数据库或面向对象数据库中获取概念。这类方法主要通过对关系模式进行语义分析,利用规则获取本体概念和概念间关系,如 Man Li等[7]的工作。目前基于结构化数据的本体构建大多使用规则方法,因此扩展性较差。
基于非结构化或半结构化数据的本体构建主要从纯文本或半结构化网页中获取概念。主要方法有:模板方法、概念聚类方法和机器学习方法。模板方法的经典模式是使用Hearst模板[8](形如“NP such as{NP,}* (and|or)NP”等)从纯文本语料中获取概念实例。这类方法的主要缺点是获取候选概念的准确度低,因为大量无用的概念往往也会匹配这些模式。概念聚类方法是利用同一类概念之间的语义近似关系对概念进行聚类,如Bisson和Emde等人[9]等提出的基于FOL的聚类方法。聚类方法对概念间的层级关系抽取效果较好,但是候选概念却需要人工输入或使用其他工具获得。机器学习方法通常利用监督或半监督方法学习分类模型并获取概念。Cimianonce等人[10]融合了模板、句法结构和WordNet层级分类结构等多种信息,使用多种分类器比较了获取概念并生成层级结构的效果,但是其分类效果最好的SVM分类器取得的F值仅33%。
随着网络知识库日渐成熟,基于网络知识库的本体构建方法成为主流技术。DBpedia[5]通过分析Wikipedia网页中的Category Page、Infobox等半结构化信息将概念归入人工定义的知识体系中,获得约260万概念。YAGO[4]以 WordNet的层级结构作为知识体系,使用启发式规则从Wikipedia中抽取概念并挂载到 WordNet类(synset)中,获得了超过100万个概念。这两项工作为我们提供了一种良好的本体构建框架:即用一种人工定义的、体系结构良好的小规模本体作为核心,向其中大规模添加概念并获得概念间关系。下文中我们采用这种框架进行大规模中文本体概念挂载。
3 基于多特征表示的概念挂载
本体概念挂载包含知识体系构建、候选概念抽取和概念间层级关系抽取三部分。本文的方法中,知识体系已由专家构建完成,候选概念抽取自网络百科条目,我们将工作的重点放在概念间层级关系的抽取上,即新增概念实例与大百科知识体系概念之间的层级关系抽取。我们综合利用了网络百科条目的多种分类特征信息抽取概念之间的层级关系。
3.1 动机
图1是一个网络百科条目示例。图中可以表达该条目类别的信息有以下几部分:1)标题,如标题“鲁迅”说明该条目可能是一个人;2)正文,正文内容详细介绍了该知识条目;3)属性框,属性框(Infobox)是描述条目属性信息的表格,图1中右侧属性框中的“出生”、“配偶”等属性名强烈提示该条目是一个人;4)开放分类,开放分类(Folksonomies)是用户使用开放标签对条目的归类信息,图1中底部开放分类文本直接指明了“鲁迅”属于“中国现代作家”。5)相关词条,条目中大量HTML链接指示了与“鲁迅”相关的其他条目。
在分析了大量类似的百科知识条目后,针对概念间层级关系抽取问题,我们的思路大致如下:

图1 网络百科知识条目示例
(1)利用概念之间的语义相似度推断概念所属的类别。如描述“鲁迅”的概念通常会与“郭沫若”、“郁达夫”等概念在正文、开放分类、相关词条等内容上相似。表1是使用3.3节中概念语义相似度计算方法得到的不同类别概念之间的相似度示例。
(2)利用上文中所述的多种特征信息综合推断概念所属的类别。不同的特征表达概念类别的信息量不同,如属性框信息中属性“职业”的属性值是提示概念分类的直接证据,而开放分类标签数量多、歧义大,很难分析出主要分类标签。因此我们使用统计分类算法结合启发式规则的方法适应不同强度的特征。分类算法利用概念之间的语义相似度对概念归类,并限制规则适用范围;启发式规则用于发现提示概念类别的直接证据,并监督指导分类算法。

表1 概念间相似度得分示例
根据以上思路,本文使用层级kNN算法结合启发式规则方法实现本体概念间层级关系抽取。下文将对本体概念挂载方法进行详细介绍。
3.2 层级分类算法
我们将大百科知识库层级体系定义为T,所有概念实例集合定义为S,需要被添加进入大百科体系的网络知识条目网页集合定义为D。算法输入待分类条目d∈D,输出一个大百科类c∈T且知识条目d是类c的一个实例。算法核心思想是将条目d在树结构T中自上而下逐层分类,在每一层使用一次kNN分类与启发式规则相结合的方法。下面是层级分类算法伪代码。

3.3 概念语义相似度计算
概念之间的语义相似度计算是分类算法的关键。由于大百科知识体系中原有的概念没有语义信息与半结构化信息,首先需要使用函数f(s)将大百科概念s通过简单名称匹配映射为网络知识条目。此后,我们融合了知识条目的正文信息(BW)、开放分类信息(TG)和相关词条信息(RL)计算语义相似度,计算方法如式(1)所示,其中α、β、γ为加权值。
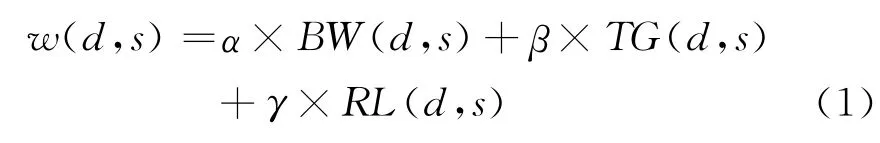
下面介绍语义相似度值各部分的计算方法。
3.3.1 正文相似度计算
将网络知识条目的正文所有内容看作一个词袋,则可用向量v(t1,t2,…,tn)表示正文,其中ti是词i在条目正文中的tf-idf值。我们使用工具[9]分词,在进行相似度计算时,只保留名词和动词。则条目d与概念s映射后的条目f(s)的正文相似度为:
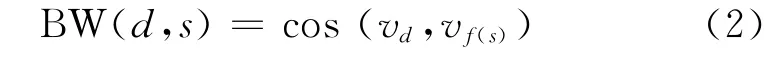
3.3.2 开放分类相似度计算
开放分类指用户对知识条目的归类标签。由于标签文本是开放的,因此同一个类的条目会拥有不同的标签文本。如描述地理类条目的标签可能有“地理”、“地点”、“地名”等多种形式,简单的字符串匹配无法处理意思相同而形式不同的标签。L.Specia等在文献[11]中提供了一种计算标签之间两两相似度的方法:设所有标签集合为T,构建一个T×T的共现矩阵P,其中Pij为标签ti与tj在条目中的共现次数。则标签tm与tn的相似度得分为向量Pm与Pn的cos值,从而可以得到一个T×T的标签相似度矩阵M,其中Mnn为1.0。设条目d与概念s映射后的条目f(s)的开放分类标签集合分别为Td与Tf(s),两者交集为U,Td与U 的差集为Id,Tf(s)与U 的差集为If(s),则
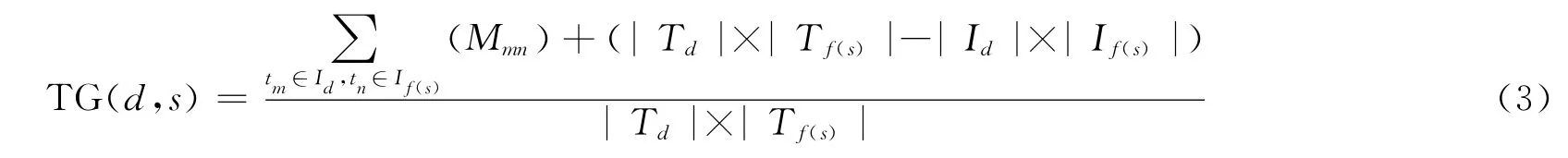
3.3.3 相关词条相似度计算
相关词条是知识条目网页描述中用户标出的与之相关的同类知识条目,同时条目正文中的相互链接也可以视为相关词条。设rf(s)(d1,d2,…,dn)表示概念s的相关词条向量,其中d1,d2,…,dn是集合D中的所有条目。条目di与s相关定义为概念s映射为条目f(s)后的正文中存在指向di的HTML链接。则rf(s)中与s相关的条目di的值为1,与s不相关的条目dj的值为0,则

3.4 启发式规则
统计分类方法容易湮没知识条目中表征条目类别的直接证据,因此我们在统计方法的基础上还利用了一些启发式规则来识别表示条目类别信息的直接证据。同时,启发式规则的应用范围由统计分类算法限制,以提高规则的准确率。下面按照优先级从高到低顺序详细介绍启发式规则。
3.4.1 属性框规则
当检测到待分类条目d包含属性框时,分类规则自动抽取属性框中的属性名与对应属性值。属性框规则分为两类:1)粗分类规则:由多个属性名及一个大百科第一级类组成。若一个条目的属性框中抽取的属性名与粗分类规则的属性名相符个数大于等于三个,则判定该条目属于规则指定类;2)细分类规则:对应一条粗分类规则并由多个属性名构成。在判断一个条目满足某条粗分类规则后,检测条目的属性框中是否包含对应的细分类规则的属性名。若包含,则直接使用属性名对应的属性值与统计分类结果的前三个类名进行匹配,判断条目所属的具体类别;若不包含或属性值无法匹配类名,则仍使用层级分类结果。表2中是一些属性框规则示例。

表2 属性框规则示例
3.4.2 命名实体规则
初步统计网络知识条目的类别,我们发现命名实体(人名、地名、机构名)占条目总数约20%以上。如果可以较准确识别命名实体,那么可以有效阻止机构被识别为人物、人物被识别为著作等情况。我们使用工具[9]识别命名实体。若一个条目的标题在正文中被识别为命名实体的比率超过75%,则认为该条目是一个命名实体。在分类时,人工指定某些类为命名实体类,在判断第一级类时仍使用分类算法,在下层分类中根据规则将被识别为命名实体的条目分入相应的命名实体类中。表3中是一些命名实体规则示例。

表3 命名实体规则示例
3.4.3 定义句规则
正文中用于定义知识条目是什么的句子被称作定义句。定义句中往往会直接给出知识条目的分类信息。我们使用句法分析工具[12]对正文首段中所有包含条目标题的句子进行句法分析,若句子满足定义句规则并且规则抽取得到的分类结果存在于层级分类算法每一层的前三个结果中,则分类器采用定义句规则抽取的结果。表4中是一些定义句规则示例。

表4 定义句规则示例
4 实验与结果
4.1 实验数据与设置
我们从网络百科知识库爬取知识条目147万条构成上文中所述的待挂载条目集合D。大百科知识库经过人工整理得到一级类45个,类5 263个,概念实例78 292个,选取实例数目较多的大类共851个构成层级体系T。大百科知识库中有58 032个概念通过f(s)函数映射到网络百科知识条目,这些概念构成语义相似度计算概念实例集合S。我们设置了两组对比实验:1)对比正文(BW)、开放分类(TG)和相关词条(RL)三个特征单独使用与三个特征融合的挂载效果;2)对比只用统计分类算法的挂载效果与统计分类算法和启发式规则结合的挂载效果。
实验参数设置如下:阈值根据经验指定为θ=0.35,k、α、β、γ值由概念集S上的集内kNN分类封闭测试得到,取k=17,令α+β+γ=1,则α=0.57,β=0.12,γ=0.31。
4.2 实验结果与分析
对比实验一在概念集S上进行层级kNN分类封闭测试。表5显示使用不同特征的每一层分类的准确率。由表可知三种特征融合后比单独使用正文文本信息的准确率提升了11.8个百分点。

表5 语义相似度衡量方法效果对比
对比实验二是大规模挂载网络百科条目的开放测试,共挂载条目974 984个。我们采用随机抽取结果并人工标注的方式评价结果。对大百科每个大类按挂载比例随机抽取共4 347个新增概念进行标注。结果如表6所示,其中BS为只使用语义相似度统计分类结果,HR为结合规则方法所得结果。由表可知分类算法结合启发式规则方法比单纯使用分类方法准确率提高了7.6%。
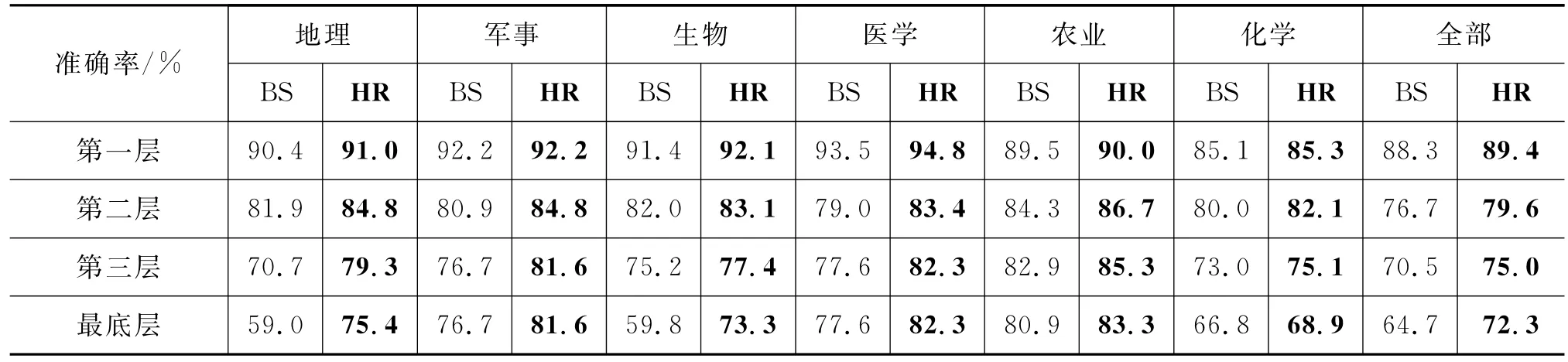
表6 概念挂载准确率
图2与图3对比了实验参数设置对概念挂载准确率的影响。图2显示不同k值下对S集封闭分类测试的准确率,图3是使用不同权重参数下的准确率对比结果。由图3与表5可知采用合适加权值后的分类准确率可以提升4.5%。
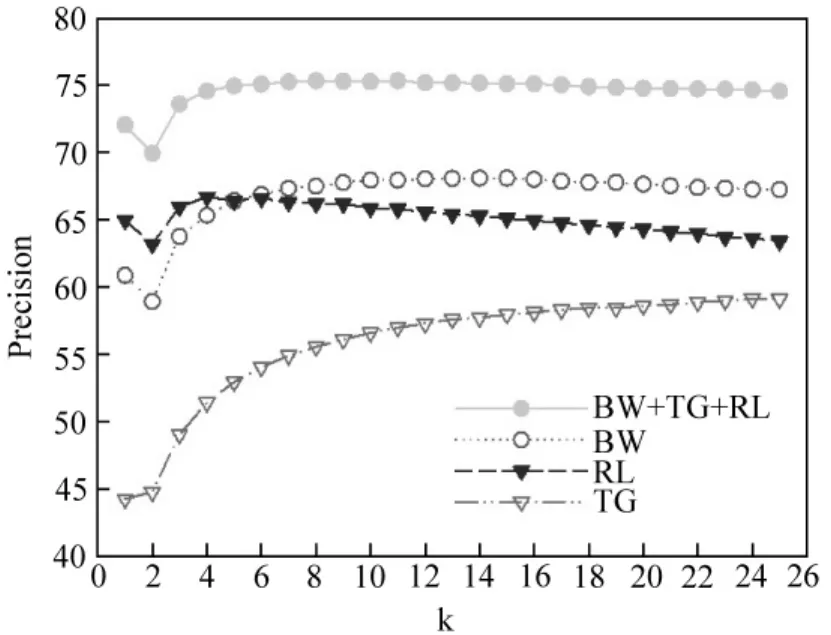
图2 不同k值下准确率
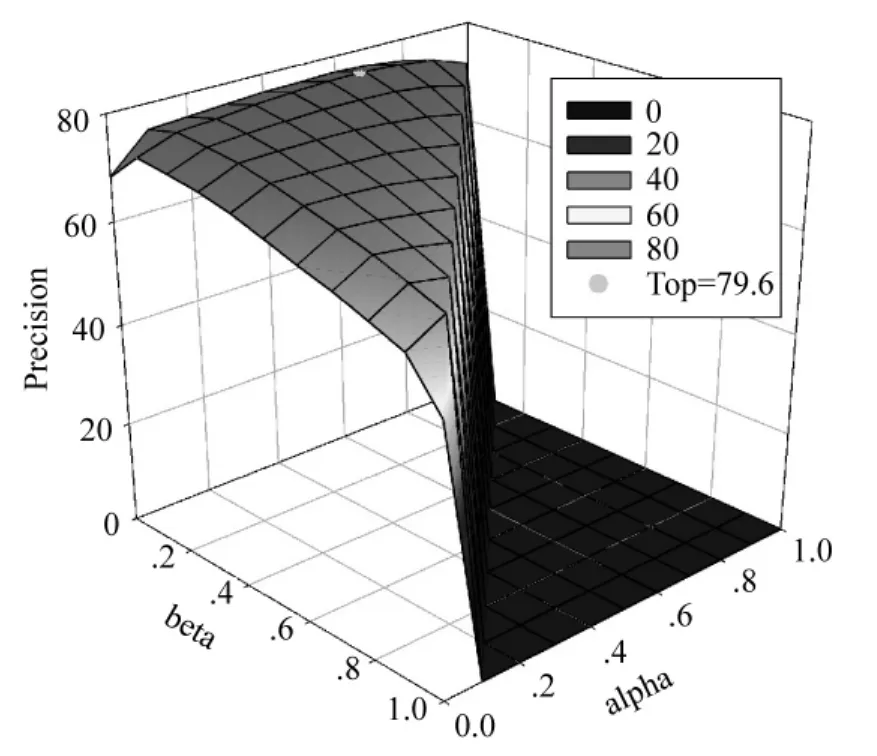
图3 不同权重下准确率
我们分析了知识体系的层级结构与概念类的划分对概念挂载精度的影响。大百科知识体系中,深度大于三层的类约为42%。随着层级的加深,同层类之间的相似性增大,挂载难度随之增加。在挂载错误的实例中,约46%的实例在浅层挂载正确。分类体系数据稀疏以及实例数不平衡是导致挂载错误的另一个问题。如我们的分类体系中“交通->船舶”只有5个概念实例,而“军事->军舰”有56个实例,则使用分类算法时“船舶”容易被分类为“军舰”,此类错误约占19%。另一方面,不同类之间的相似性易混淆概念实例的挂载。例如,“医学->药品”与“化学”相似、“生物->植物界”与“农业->蔬菜”易混淆。同时,一个概念可能属于多个类,例如,“阿司匹林”既可以是“药品”,也可以属于“化学”,这将是我们未来研究的重点。此外,还有一些实例难以确定其所属类,例如,“腐败”、“非主流”等,这类实例约占挂载总数的7%。
5 结论与展望
本文研究了一种多特征表示的本体概念挂载技术,并成功将中国大百科分类体系扩展为一个拥有百万级概念的全领域中文本体。在本体概念挂载时,限定了一个概念只能拥有一个父节点,未考虑实体消歧,同时也未使用共指消解技术,这两项工作是我们后续改进工作的重点。另外,本体构建不仅需要概念挂载技术,也需要抽取概念的属性以及概念之间的非层级关系。下一步工作可以在本文基础上进行概念属性与关系的抽取。
致谢
感谢清华信息科学与技术国家实验室(筹)对本项目的资助。
[1]D.B.Lenat,et al.CYC:A Large-Scale Investment in Knowledge Infrastructure[J].Communications of the ACM.Nov.1995.38(11):33-38.
[2]Dong Z., Dong Q.2000. HowNet [EB/OL].Available at http://www.keenage.com/
[3]Kurt Bollacker,et al.Freebase:a collaboratively created graph database for structuring human knowledge[C]//Proceedings of the SIGMOD.New York:ACM..2008:1247-1250.
[4]Fabian M. Suchanek,Gjergji Kasneci, Gerhard Weikum.Yago:A Core of Semantic Knowledge[C]//Proceedings of the 16th international World Wide Web conference.New York,NY,USA:ACM Press.2007.
[5]S.Auer,et al.Dbpedia:A nucleus for a web of open data[C]//Proceedings of the 11th ISWC conference.Boston,MA,USA:Springer.2007:4825,722-735.
[6]杜小勇,李曼,王珊.本体学习研究综述[J].软件学报,2006,17(9):1837-1847.
[7]Li,M.,Du,X.,Wang,S.Learning Ontology from Relational Database [C]//Proceedings of the 4th International Conference on Machine Learning and Cybernetics.Guangzhou,China.2005:Vol.6:3410-3415.
[8]M.Hearst.Automatic acquisition of hyponyms from large text corpora [C]//Proceedings of the 14th International Conference on Computational Linguistics.Nantes,France.1992:539-545.
[9]Bisson,G.Learning in Fol with a Similarity Measure[C]//Proceedings of the 10th National Conference on Artificial Intelligence (AAAI'92). San Jose,California:AAAI Press.1992:82-87.
[10]Cimiano P.,et al.Learning taxonomic relations from heterogenous sources of evidence.P.Buitelaar,P.Cimiano & B.Magnini(Eds.),Ontology Learning from Text:Methods,Evaluation and Applications[M].Amsterdam,The Netherlands:IOS Press.2005:59-73.
[11]Youzheng Wu,Jun Zhao,Xu Bo.Chinese Named Entity Recognition Model Based on Multiple Features[C]//Proceedings of the Joint Conference of Human Language Technology and Empirical Methods in Natural Language Processing(HLT/EMNLP 2005).Vancouver.2005:427-434.
[12]L.Specia,E.Motta.Integrating Folksonomies with the Semantic Web [C]//Proceedings of the 4thEuropean Semantic Web Conference(ESWC 2007).Innsbruck,Austria:LNCS.2007:624-639.
[13]Xiangyu Duan,Jun Zhao. Probabilistic Parsing Action Models for Multi-Lingual Dependency Parsing[C]//Proceedings of the 2007Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning(EMNLP-CoNLL-2007).Prague,Czech Republic:LNCS.2007:940-946.
