基于免疫算法的Web数据挖掘技术的研究
2012-10-14周自斌
周自斌
(安徽经济管理学院 信息工程系,安徽 合肥 230059)
基于免疫算法的Web数据挖掘技术的研究
周自斌
(安徽经济管理学院 信息工程系,安徽 合肥 230059)
现代计算机网络的迅速发展和网络数据量的大幅增加导致了对网络数据挖掘的需求变的越来越迫切.网络数据具有分布范围广、数据量大、时间跨度长等特点.如何对这些海量数据进行高效查询并对查询结果进行最优收敛成为研究的热点.免疫算法以遗传算法的全局性群体搜索方式为基础,模拟生物免疫系统对本代群体进行优化,有利于查询结果的快速收敛,大大提高了查询效果.
免疫算法;数据挖掘;最优查询
Web数据挖掘(Web Data Mining),是指在网络环境中,从大量的分布在异构网络中的Web文档库中发现潜在的、有价值的信息,并对其加以分析,筛选和优化,最终提交给用户.随着Internet的飞速发展,网络用户与日俱增,Web数据量也相应的有了快速的增长.Web站点已经被用户广泛接纳为新的数据储藏库,在这些庞大的信息资源库中蕴含着具有巨大潜在价值的知识.同样由于Web数据的分布化和多样化,使得Web数据挖掘技术比单个数据仓库的数据挖掘技术要复杂得多,如何提高Web数据挖掘技术的效率及稳定性,已经成为数据挖掘领域研究的热点.
1 Web数据挖掘的工作原理
1.1 Web数据的特点
1.1.1 异构网络环境.在网络环境中,每一个Web站点就是一个数据源,而由于这些站点的采用的网络连接方式、网络协议、操作系统等差异,导致了Web数据源的异构性,直接影响了数据挖掘技术的效率和容错率.
1.1.2 海量动态数据.由于网络中Web站点的数量不断增加,Web数据量也在飞速增多,而且由于网络数据的动态特性,导致数据更新快、淘汰快.如何提高数据挖掘技术的有效性以确保搜索结果是真正有价值的,已经成为Web数据挖掘要解决的重点问题.
1.1.3 Web数据的结构复杂性和多样性.Web上的数据非常复杂,没有特定的模型,每一站点的数据都是各自独立设计,缺乏统一标准,而且每个站点蕴含的信息呈多样化,例如文本数据、图表、音频数据以及视频数据等.这些差异都增加了Web数据挖掘的困难度.
1.1.4 用户群体的广泛性.数据挖掘最终是要为用户提供服务的,而Internet庞大的用户群导致众口难调的问题格外突出,因此,需要Web数据挖掘系统有一定的智能性和相应的学习机制,不断跟踪不同用户的兴趣和关注点,直至获取最贴近用户需求的结果.
1.2 Web数据挖掘的组成步骤
如图1所示,Web数据挖掘包含以下几个步骤和内容:

图1 Web数据挖掘的组成
1.2.1 信息检索:自动对网络中存在关联关系的文档进行搜索,主要包括文档的表示、索引的搜索.
1.2.2 信息提取:在文档被检索并初步筛选之后,自动从中提取有价值的信息,这一步骤主要是通过对页面内主要字段的语义进行识别来完成的.
1.2.3 信息集成:针对提取的文档进行归纳和优化,得到概要知识.自学习、自适应的一些智能算法就在这一过程当中被应用.
1.2.4 信息分析:这一阶段将对信息集成阶段所生成的模式进行解释说明.即针对用户提供的先验信息,对集成的数据再次优化,使之符合用户的需求.最终生成有价值的信息提交给用户.
2 免疫算法原理
以往经常使用的遗传算法或者以其为代表的进化算法,在智能化处理事务的能力还有很大的不足,尤其对多峰值求解问题存在较大的缺陷,所以必须更加深入地挖掘与利用人类的智能资源.免疫算法(Immune Genetic Algorithm-IGA)基于生物免疫系统的自适应学习、自我识别和主动攻击侵入机体的抗原的原理,将生物免疫系统的特点引入遗传算法.
在采用免疫算法进行优化求解时,将目标函数和对应的约束条件(可根据用户的需求和关注点的差异而进行调整)作为抗原输入.随后,产生初始抗体群,并通过遗传操作及对抗体亲和度的计算评价,在多代优化后,找出针对该抗原的抗体,即问题的最优解,同时保持了抗体多样性,避免了局部过早收敛.
免疫算法的重点是在于合理的提取疫苗,即合适的抑制和刺激函数,并通过接种疫苗和免疫选择两步内容来完成的.接种疫苗是为了提高适应度,免疫选择是为了防止群体的退化.
由此可以看出,免疫算法是在遗传算法的基础上,融入了免疫机制而形成的一种优化算法,它解决了遗传算法中经常会出现的过早收敛与局部极值,也就是“早熟”的情况,大量的实验数据证明,免疫算法是一种局部搜索能力更强,收敛性更好、鲁棒性更高的新型优化算法.
2.1 生物免疫系统
免疫是生物体的一种特性生理反应.生物的免疫系统在检测到外来侵犯的抗原时,可自动产生相应的抗体来抵抗乃至消灭抗原.抗体在攻击抗原时,会产生一系列的反应,通过吞噬作用来达到毁坏抗原的目的.在生物体中,淋巴细胞和抗体分子共同组成了免疫系统,而起到关键作用的淋巴细胞又包括T细胞(由胸腺产生)和B细胞(由骨髓产生)两类.
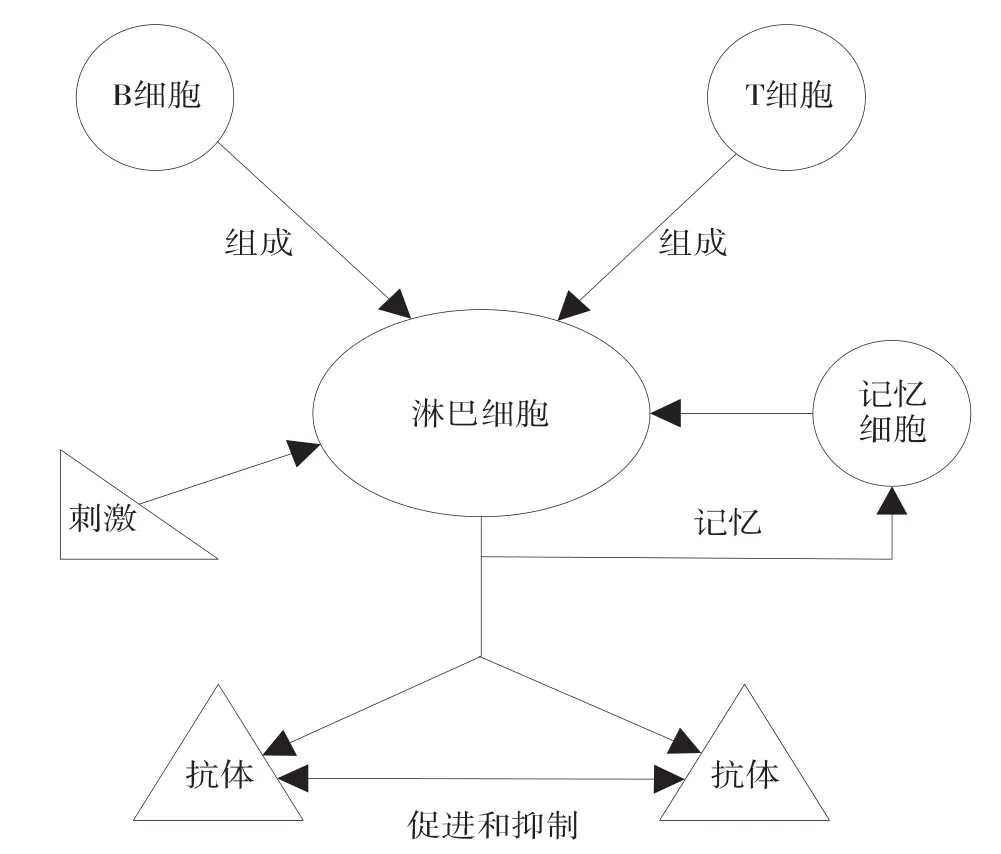
图2 生物免疫机制的抽象模型
免疫系统的功能主要是依靠抑制机理和主反馈机理之间的相互协作来实现的.免疫系统作为复杂的自适应系统,具有能够自我识别和消除异已的能力,并且有分布广、自适应性强、样体呈多样化、自组织及快速应答等特点.图2为生物免疫机制的抽象模型图.
2.2 免疫算法的流程
免疫算法在基本遗传算法的基础框架上,利用求解问题的特征对遗传算法的种群进行疫苗接种,即根据先验知识保留种群中的最优群体,并保留最优个体作为记忆细胞,以提高优化速度,具体的流程如图3所示.

图3 免疫算法流程图
以下为免疫算法的整体流程:
2.2.1 抗原识别:免疫算法所要解决的问题对象即为抗原,我们假设机体收到抗原的入侵,而免疫算法求解即为抵御抗原入侵的过程,那么首先就需要对抗原进行识别,判断此时侵入的抗原是不是类似于曾经遇到过的抗原,这一步骤采用相似度函数进行判断,如果是的话,就可以调用以往的解决策略快速优化.
2.2.2 初始抗体产生:如果第一步抗原识别的结果是此次入侵的抗原同以往抗原具有高相似度的特征,则从即记忆单元中抽取同以往抗原相对应的抗体组成初始群体.否则,初始群体由随机算法产生,同时也可根据先验知识,实现设定好某些特定的抗体加入初始群体中,显然,这种方式加快了免疫算法的搜索速度.
2.2.3 抗体适应度评价:在当前的群体中,计算所有抗体的适应度,适应度是筛选优化操作所依赖的重要依据.在免疫算法中,适应度函数通常是用待优化问题的目标函数进行变换得到的.
这里我们采用Marghny等人提出的适应度函数:
n:用户输入的关键字的数量,#ki:在链接L中关键字 出现的次数;
M:页面中总的链接数;
Fmax(p)和Fmin(p)分别表示为采用优化算法后本代页面质量函数的最大值和最小值,显然,最大值为m*n,最小值为0.
2.2.4 向记忆细胞分化:这一操作的目的即为更新数据库,如果抗原是新的,则在当前的抗体群中,抽取出适应度高的抗体,并计算它与记忆单元中保存的抗体的相似度,并用这个抗体替换掉记忆单元中亲和度最高的抗体.
定义抗原Ag和抗体Ab的亲和度dij以及抗体Abi和抗体Abj间的亲和度dij.抗体间亲和度值越大,说明两个抗体越相似,这里采用欧氏距离评价抗体间的亲和度:

式中n为抗体属性个数;Abik、Abjk分别为抗体Abi和Abj的第k个属性;
任意两个数据向量的最大距离定义为Dmax=
细胞分化的作用是将适应度高的抗体存入记忆单元中,但并不对记忆单元中抗体的多样性产生影响.
2.2.5 抗体的促进和抑制:抗体的浓度和适应度直接关系到对某一抗体究竟是采用刺激促进还是抑制.抗体的浓度越高,该抗体被促进的概率越小,而抗体的适应度越高,该抗体被促进的概率就越大,这样做的目的是为了改善错误收敛与局部极值的情况.这里采用cooke等人提出的刺激度计算公式:
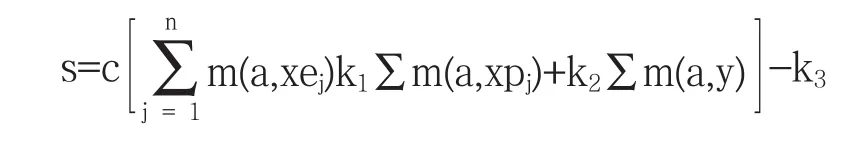
式中,第一项为抗原与抗体的适应度;第二项为抗体之间的相互抑制程度;第三项为抗体之间的相互刺激作用;第四项为抗体的死亡(即淘汰)概率.
2.2.6 提取和接种疫苗:免疫算法的优势之一就是利用局部特征数据来群体优化的过程,这是通过疫苗操作来完成的.在提取和接种疫苗时候,对局部特征信息加以关注,甚至搜索进程围绕数个局部特征信息展开,这就减少了求解过程中的一些重复和无效的工作,这也是免疫算法比遗传算法更快收敛到最优解的重要因素.
2.2.7 抗体产生:对上一个步骤所筛选出的抗体进行交叉和变异操作,更新抗体群.交叉、变异算子是免疫算法中的核心运算环节,这一点是同遗传算法相类似的.对于最常使用的二进制编码,通常有单点交又,两点交叉等交方式;变异算子就是对某个抗体中的某一基因位做二进制取反操作.而对于其它更复杂的编码方式,交叉和变异要考虑的因素就大大增加了,例如要保证抗体的多样性,避免未成熟收敛,又要确保抗体的有效性,避免无效搜索.
2.2.8 群体更新模:本代优化完成后,把新产生的群体替换上代群体,同时淘汰掉抗体群适应度最低的一部分,再随机生成同样数量的新抗体加入本代样本群体中去,进行下一代的进化.
3 基于免疫学习算法的Web数据挖掘
将免疫优化算法用于Web数据挖掘,可根据用户需求的不同,合理的安排抗原和疫苗,在这里我们将用户请求看作抗原,根据用户请求得到目标集,并进行预处理后得到的有效数据看作抗体,以此为基础数据,Web数据挖掘流程如图4所示.
3.1 数据信息获取和处理
Web页面首先需创建一个数据集,此数据集必须是可以合并到现有数据库的,然后才能被检索和处理,处理过程如下:
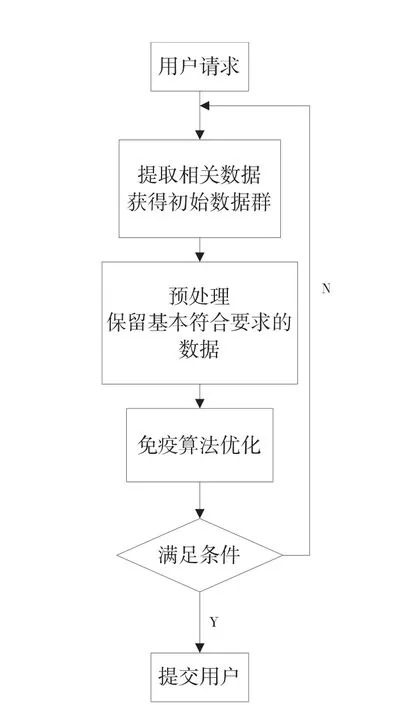
图4 Web数据挖掘流程
(1)标识数据源,之后把它映射成可扩展标识语言XHTML,并查找数据内的引用点;
(2)将数据映射成扩展标记语言XML;
(3)合并结果并对数据做进一步分析处理.XML可以很便利的将XML的文档描述与关系数据库中的属性对应查找并建立映射关系,实施精确地查询与模型抽取.应用XML格式的最大优势是不仅可以兼容原有的Web应用和原有信息,而且针对Web中不断生成、更新的信息实现共享和交换.
3.2 仿真结果与分析
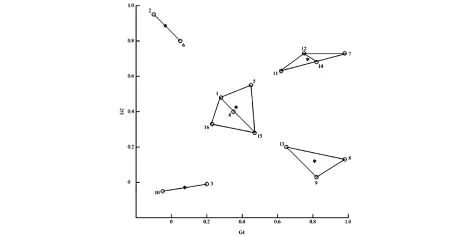
图5 仿真结果
在实际应用中,用户可能会对多种数据特征感兴趣,显然,特征越多,算法越复杂,查询耗时也更多,在仿真实验中,为简单起见,仅选取两个反映数据特征的属性,记为G1和G2.从数据集中选取400个数据作为初始训练样本,16个数据为有效测试数据.刺激阈值参数设定在[0,1]范围内,选择初始抗体集合中的20%进行克隆和变异,用400个样本数据进行训练后,对测试数据进行仿真,将测试数据分为5类,对应用户可能感兴趣的5个数据种类.仿真结果如图5所示.由仿真结果可以看出,免疫算法能够能够较快的实现收敛,并可根据先验知识对最优解集合加以分类,效率和实用性都能够得到保证.
4 总结
Web网络数据挖掘是一个快速发展的新的研究方向,由于数据量大、分布广、动态性和多样性等特点,使得Web数据挖掘一直是智能化查询领域的难点和热点以往研究人员提出各种方法对查询优化方法进行改进,不断的提高网络数据查询的智能化和人性化.本文阐述了Web数据挖掘的特点和操作步骤,详细讨论了免疫算法在Web数据挖掘中应用中的实际可行的方法.仿真结果表明,本文所设计的方法可以有效的提高网络数据查询的收敛速度,并能够实现分类提交数据,满足用户的个性化需求.
〔1〕Hunt J E,Cooke D E.Learning using an artificial immune system[J].Journal of:Network and Computer Applications,1996,19(2):189-212.
〔2〕Marghny,M.H.andA.F.Ali.Webminingbased on genetic algorithm [J].In Proceedingsof ICGST InternationalConference on Articial Intelligence and Machine Learning(AIML-05),2005.
〔3〕Goldberg D E.Genetic Algorithms in Search,Optimization&Machine learing.Addison-Wesley Publishing,1989.
〔4〕王昕昕.遗传算法与网络数据挖掘[J].电脑知识与技术,2010,6(2).
〔5〕王继成,潘金贵,张福炎.Web文本挖掘技术研究[J].计算机研究与发展,2000,37(5):513-520.
〔6〕张向锋,丁斗章.基于免疫学习算法的Web数据挖掘方法[J].上海电机学院学报,2007(9):213-216.
〔7〕毛国君,段立娟,王实,等.数据挖掘原理与算法[M].北京:清华大学出版社,2005.
TP311.13
A
1673-260X(2012)09-0030-04
