大规模无参考译文质量自动评测技术的研究
2012-10-04尹宝生苗雪雷蔡东风张桂平
尹宝生,苗雪雷,季 铎,蔡东风,张桂平
(沈阳航空航天大学人机智能研究中心,沈阳 110136)
随着全球经济一体化发展的快速推进,多语信息处理将成为一个巨大的产业,对人工翻译和机器翻译技术都有着极大的需求。无论采用人工翻译、机器翻译还是人机协同翻译来完成翻译任务,其工作的重点都是保证译文质量并提高翻译效率。对译文质量的评测方法分为自动评测和人工评测2种。
目前著名的自动评测方法主要有IBM提出的 BLEU(Bilingual Evaluation Understudy)方法[1]和美国国家标准与技术局(NIST:National Institute of Standards and Technology)在BLUE方法上改进提出的NIST评测标准[2]。现有的自动评测方法必须给定参考译文的情况下才能对机器翻译的译文做出评价,通过将机器翻译的译文与参考译文相比较,认为越接近参考译文的自动翻译结果正确率越高。这类自动评测方法重点在于评价机器翻译系统的性能,而对翻译结果的评价却依赖于给定的参考译文。这在实际的翻译工作中是不现实的,因为不可能要求所有的资料都事先给出参考译文。
在对质量要求高的实际翻译项目中,多采用人工评测的方式来评价译文质量。人工评测主要是在翻译过程中设置一个审校环节,由审校人员对翻译环节产生的译文进行评测来控制翻译质量。对于未通过评测的译文要返回给翻译人员修改,如此往复直到通过质量审查。由此可见,人工评测是确保翻译质量的核心步骤,但是人工评测耗时费力,效率低下,而且由于人的主观因素,对于同一篇译文不同的评测人员可能给出不同的判断。
在多人参与的大规模资料翻译项目中,人工评测时常常发现译员之间存在术语不一致、表达不规范、语义错误和漏译情况多的现象,甚至存在大量低级的拼写错误和语法错误。
传统的语法拼写检查工具能够帮助译员解决部分拼写和语法问题,但由于这类语法拼写工具只对译文进行检查,而不能检查译文的忠实情况;词库规模小,无法识别大量的专业术语;语法检查规则简单,不能适用专业领域的特殊翻译规则;不能解决不同译员间的一致性问题;不能对译文质量形成量化评价。
本文提出一种译文质量自动评测方法,该方法可以在无参考译文的情况下,从流畅性、正确性和忠实程度等方面对译文进行客观的质量评价。
基于该方法实现的译文质量自动检查系统应用于国家知识产权局百万专利翻译项目中(总字数超过3亿字,数百人同时翻译)。在该项目中,自动评测系统主要用于帮助翻译人员发现并纠正翻译错误、评价译文质量。应用效果表明,译文质量评测技术有效保证了翻译质量并提高了整体翻译效率。
1 相关工作
译文质量的自动评测方法主要分为有参考的译文质量评测方法和无参考的译文质量评测方法。目前对于有参考的译文质量评测的研究较多,并且主要应用于机器翻译的译文质量评测中。
1.1 有参考的译文质量评测方法
2002年6月,NIST举办了首次正式的机器翻译评测活动。包括IBM公司,卡内基梅隆大学(Carnegie Mellon University),南加州信息科学研究所(USC/ISI),德国亚琛(RWTH Aachen)大学,微软研究院(Redmond)和中国科学院计算研究所在内的6家研究机构的机器翻译系统参加了评测,同时,NIST还评测了SYSTRAN公司的商用机器翻译系统作为一个横向比较。测试语言包括中英翻译和阿拉伯语到英语的翻译,实验表明,它们的评测结果和人工评测有较大的相关性。
国内针对有参考的译文质量评价方法的研究,主要是由北京大学计算语言学研究所俞士汶教授研究开发的MTE系统,该系统是世界上第一个机器翻译自动评测系统,该系统采用的就是基于测试集的评价方法,以测试点和题库相结合的方法解决译文质量自动评测的难题,并建立了机器翻译评测大纲[3]。它是以句子为评测单位,还借鉴了语言测试中分离式测试方法,即对于一个句子不是评测整个句子的翻译,而是每句侧重一个测试点(每个测试点代表一个语言点),只评测测试点的翻译,用测试集做评测是一种有意义的尝试,这种方法使机器翻译摆脱了评测过程的主观性,同时也节省了人力物力,但是这种自动评测集的建立是一个繁琐复杂的任务,需要机器翻译专家、机器翻译系统的开发者、语言学家和软件工程师的密切配合,同时建立一个测试集是一个长期的过程,测试点的建立与描述需要不断完善。另外,国家863计划也组织了几次专家评测,对当时的汉英和英汉翻译系统进行了现场评测。
1.2 无参考的译文质量评测方法
无参考的译文质量评测主要是基于统计的N-Gram语言模型来衡量,语言模型可以通过对目标语言的特定语料训练得到,它可以给出一个混乱度来反映测试句子在训练语料中观察到的可能性,该方法已经用于机器翻译系统译文质量的评测中[5]。使用大规模的语料训练出来的语言模型对于预测某个在训练语料中学习到的字符序列出现的概率可以取得较好的效果,但是在实际的应用中,由于训练语料的不平衡性,难免会出现数据稀疏问题,所以在训练模型时就需要一些平滑技术来预测未知事件,目前常见的数据平滑算法有加法平滑,Good-Turning平滑,线形插值平滑,回退式平滑,kneser-Ney平滑和Witten-Bell平滑等。
Jones利用句法树的平衡性、n元模型、语义共现等信息作为翻译质量的衡量尺度。Brew利用词频、词性标记的分布规律以及其它文本特征来评价翻译质量。Quirk采用人工评注过的翻译句子作特征向量,并以此训练出一个分类器来给译文打分,他所使用的特征包括根据语言模型所得到的句子混乱度、源语言句子长度、以及一些翻译特征,包括所学习到的翻译映射对,以及译文中的单词是否来自翻译映射或者是来自词典,实验证明这种基于机器学习的方法对句子级别的评测有较好的效果。
本文从实际应用出发,提出多策略的大规模无参考译文质量自动评测方法,采用语言模型结合Kneser-Ney平滑算法来进行译文流畅度衡量;采用句法分析结合大量的规则来对译文的正确性进行衡量;采用基于统计的词对齐方法来进行译文忠实度评测。与传统的自动评测方法相比,该方法无需预先选取带有参考译文的测试集,在大规模工程化的翻译项目中,对个人或者整体的翻译质量进行评测,一方面可以帮助翻译人员提高翻译质量,另一方面可以减轻翻译审校人员的工作量,具有重要的实用价值。
2 大规模无参考译文质量自动评测方法
本文从译文的流畅度(语句是否流畅),忠实度(译文是否如实的表达了原文的意思)以及正确度(语法或语义的正确度)3个方面来衡量译文质量。在实际的研究应用中,译文忠实度的评价远比流畅度的评价困难的多[4]。
2.1 译文流畅度衡量
对于大规模的语料资源,能够较好地获得期语言模型数据。语言模型是自然语言的数学模型,它主要描述自然语言的统计和结构方面的内在规律,并通过概率的大小描述当前语言片段的结构合理性,概率越高,语言片段的结构越合理,流利程度越高。由卡耐基梅隆大学开发的CMU和美国的语言技术研究实验室开发的Srilm[6]是2种比较流行的语言模型训练工具。
由于人类的语言现象千差万别,因此会造成语言模型在概率统计上的不准确,必须采用一定平滑手段。

Kneser-Ney给出的平滑公式被定义为:

本文采用CMU语言模型结合Kneser-Ney平滑算法来进行译文流畅度衡量。该方法能够依据语言模型对出现概率较低的语言现象进行打分,并提示译员更高概率的表述方式。在专业性越强的资料翻译项目中,这种语言模型的效果越明显。
2.2 译文正确性的衡量
译文的正确性主要是指译文是否存在目标语系中的拼写错误、语法错误和规范性错误。以汉英翻译为例,英语重结构,汉语重语义。英语是用大量的关系词、连接词和引导词等连接起来的结构清楚、层次分明、逻辑严密的“形态语”,所以可通过有效的句法分析规则对译文进行语法分析,分清句子中各成分之间的语法关系,即找出句子的主干,弄清句子的各个修饰成分以及修饰关系,进而寻找译文中的语法错误。下图为基于语法分析的谓语动词单复数错误问题。
本文在句法结构分析的基础上,制定了2400条用户规则来对译文正确性进行评价和提示。该方法可以检查汉英翻译中最常见的主谓一致错误、拼写错误、规范性错误等。
2.3 译文忠实度的评测

图1 基于语法分析的谓语动词单复数错误识别举例
译文忠实度主要是指译文是否对原文进行完全的翻译,做到不漏译。译文是否存在漏译可以通过原文中每个词语在译文中的对译来体现。因此,对于忠实度的评测可以采用词对齐的策略进行衡量,例如:

图2 双语词对齐结果举例
现有词对齐方法主要分为2类:统计(statistical)方法和启发式(heuristic)方法。统计方法通过建立模型来描述平行文本之间的关系,模型参数可以从训练语料库中自动学习(例如,Brown 1993;Vogel 1996)。统计方法和启发式方法的主要区别在于统计方法是基于概率模型而启发式方法则依赖于相似度函数。研究表明,统计对齐模型要优于简单的Dice系数方法。本文在基于统计方法实现词对齐的基础上,结合忠实度判断规则(长度比例规则、领域规则、次序规则等)进行译文忠实度评测。
3 应用实验
3.1 应用实验条件
在应用验证中,我们基于中国1985~2006年的中文专利摘要语料库进行(中译英),英文语料库为Derwent英文专利摘要库。即首先从中文专利库中选取机械领域专利文献摘要作为翻译语料(中译英),该批资料的特点是专业术语多、内容关联度高、语言规范性强。同时选择近8万篇Derwent英文机械领域专利基于CMU工具进行语言模型的训练工作。
将20名专业翻译人员分为A、B2组,各包括5名英语能力等级为CET6和5名TEM8的专业译员。
应用时间为10工作日,分为2个阶段,每个阶段5个工作日,安排如下:

表1 A、B两组译员翻译安排
3.2 译文综合差错率计算方法
参考国家翻译服务标准:笔译部分(GB/T 19363.1-2003)采用如下译文差错率计算方法:
1)译文质量的差错类别
第Ⅰ类:对原文理解和译文表述存在核心语义差错或关键字词(数字)、句段漏译、错译。
第Ⅱ类:一般语义差错,非关键字词(数字)、句段漏译、错译,译文表述存在用词、语法错误或表述含混。
第Ⅲ类:专业术语不准确、不统一、不符合标准或惯例,或专用名词错译。
第Ⅳ类:计量单位、符号、缩略语等未按规(约)定译法。
2)综合差错率设置
译文综合差错率计算:
其中:
K——综合难度系数,取值范围(0.5 ~1.0)
CA——译文的使用目的系数
第Ⅰ类使用目的系数:CA=1;
第Ⅱ类使用目的系数:CA=0.75;
第Ⅲ类使用目的系数:CA=5;
第Ⅳ类使用目的系数:CA=0.25;
DⅠ、DⅡ、DⅢ、DⅣ——Ⅰ、Ⅱ、Ⅲ、Ⅳ类错误重复出现的次数,重复性错误按一次计算。
CⅠ、CⅡ、CⅢ、CⅣ—— Ⅰ、Ⅱ、Ⅲ、Ⅳ类错误的系数,取值如下:
CⅠ=3;CⅡ=1;CⅢ=0.5;CⅣ=0.25。
译文质量综合差错率低于1.5‰满足国家翻译质量标准。
3.3 实验结果及分析
A组和B组的译员每天完成译文后,都匿名提交给统一审校组按照译文综合差错率进行评分,以译文综合差错率的差异来验证自动评测系统的应用效果。连续观察2个阶段,A、B两组的综合差错率如下:
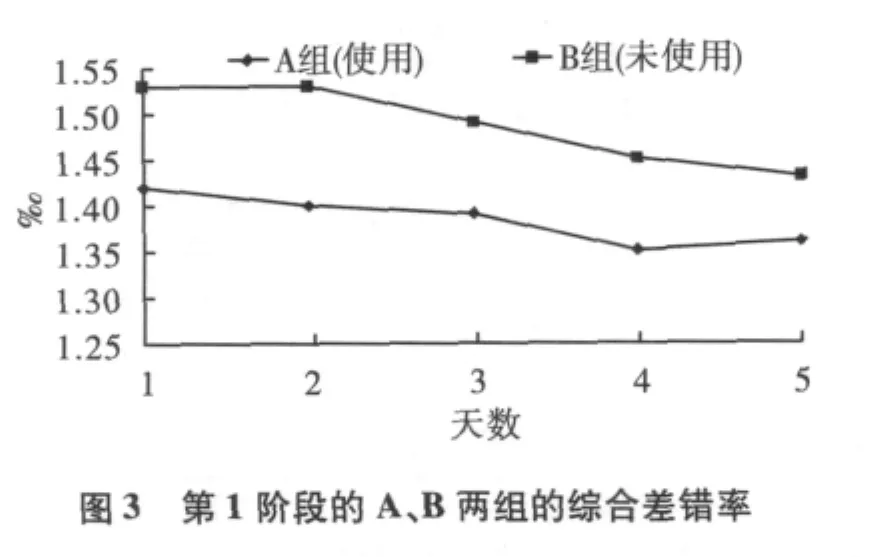
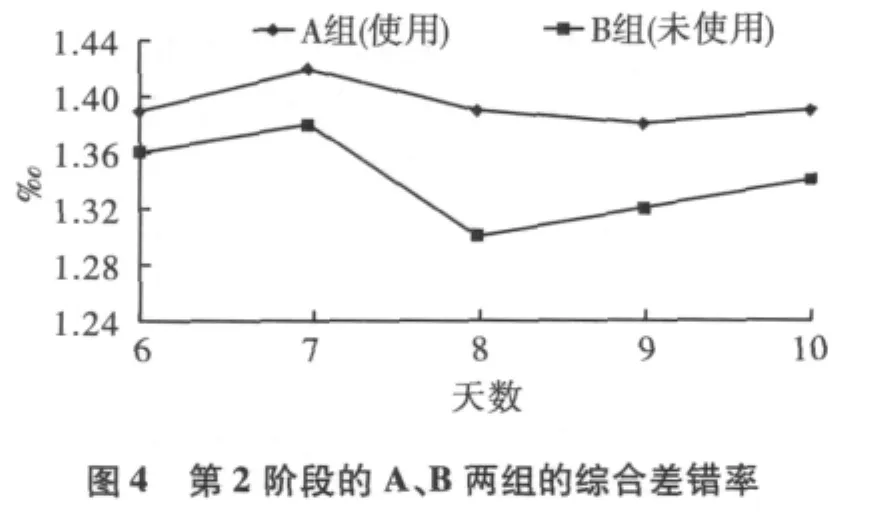
图3和图4中的数据表明,在两个测试阶段内,使用自动评测系统组的综和译文质量综合差错率都较未使用的组有明显下降。

表2 A、B两组平均综合差错率
表2中的数据还表明,A、B两组各自在使用自动评测系统时都较未使用时质量有明显提升。A组从使用到不使用质量差异不大,分析原因是A组在第一阶段通过使用自动评测系统已经学到了一些错误实例并转化成自身翻译能力,所以脱离系统后影响较小。
4 结论
大规模无参考译文质量自动评测方法可以对一篇给定的译文进行客观的打分,并且按实际需求的目标给出质量好坏的客观的定性评价,大大减轻翻译翻译和审校人员的工作量,提高翻译的总体质量和效率。
由于语言现象的多种多样,导致研究中所用到的统计模型的数据稀疏严重,如何平滑当前数据获得理想的目标语言模型,以及如何在现有的词对齐方法中进一步提高词对齐的正确率,是在实际应用中遇到的主要问题。
语法分析方面,如何正确的识别长距离的句法依存关系,提高句法分析的正确性,以及在没有给定参考译文的情况下,如何自动的做出合理的评价以及评价标准。
对于翻译质量衡量,无论是机器翻译还是人工翻译都没有绝对的标准答案,评价结果是相对的并存在一定的主观性。但在机器翻译性能评测以及大规模翻译项目质量控制等方面却有着重要的应用价值。随着技术的不断改进和完善也必将发挥越来越大的作用。
[1] Kishore Papieni,SalimRoukos,Todd Ward,et al.BLUE:a Method for Automatic Evaluation of Machine Translation[A].ACL 2002[C]:Philadelphia,2002:232-240.
[2] Coughlin,Deborah.Correlating automated and human assessments of machine translation quality[A].Proceedings of MT SummitIX[C].New Orleans,2003.
[3] Yu Shi-Wen.Automatic evaluation of output quality for machine translation systems[J].Machine Translation,1993(8):117 -126.
[4] Michael Gamon,Anthony Aue,Martine Smets.Sentence-level MT evaluation without reference translations:beyond language modeling[A].Proceedings of EAMT 2005[C].Budapest,2005.
[5] Callison-Burch,Chris and Raymond S.FLOURNOY.A program for automatically selecting the best output from multiple machine translation engines[A].Proceedings of MT Summit VIII[C].Santiago de Compostela,2001:63 -66.
[6] Andreas Stolcke.Srilm-an extensible language modeling toolkit[A].Speech Technology and Research LaboratorySRI International[C].Menlo Park,2002.
[7] Liu Yang,Sun Jiasong,Wang Zuoying.Comparison of several smoothing methods in statistical languagemodel[A].International Symposium on Chinese Spoken Language Processing ISCSLP 2000[C].Beijing,2000.
[8]宁伟,苗雪雷,胡永华,等.基于SVM 的无参考译文的译文质量评测[A].第四届全国机器翻译研讨会[C].北京,2008.
