一种基于CBR的特征属性权重选取与自修正方法*
2012-09-29王义祥邬群勇
王义祥,邬群勇
(福州大学 福建省空间信息工程研究中心,福建 福州350002)
案例特征属性权重反映了该属性相对于其他属性的重要程度,以及单个属性对问题解决的贡献程度[1-2]。案例特征属性权重向量的选取将直接影响到检索出案例的质量的好坏,并进一步影响到CBR推理的效率和质量,同时也决定了案例复用与修改的难易。
在传统的CBR系统中,特征属性的权重常采用专家主观赋权法[3],即特征属性的权重一般事先由领域专家根据经验进行主观判断给定,并且特征属性的权重一旦确定以后,便被永久地固定在系统中,一般很少改变。然而在许多场合下,特征属性对问题解决的贡献程度呈现着一定的波动性,即特征属性的权重会随着环境、时间等因素的变化而变化[4]。因此,需要对特征属性权重进行动态调整。
本文在分析现有案例特征属性权重调整方法存在问题的基础上,充分参考CBR的思想,提出了一种基于CBR的特征属性权重选取与自修正方法,充分利用权重分配的历史经验,指导当前权重问题的动态分配与调整。
1 特征属性权重选取基本方法
国内外学者对于特征属性权重选取做了大量研究,并提出了多种权重向量选取与调整方法[5-7],如Pull&Push、遗传算法、基于时序等。
1.1 Pull&Push调整法
Pull&Push调整[8-9]基于训练样本成功和失败的检索经验来调整特征属性权重。当源案例被正确检索出来,如果源案例与目标案例对应特征属性的属性值相同,系统将自动提高该属性的权重,否则系统将自动降低该属性的权重;当源案例被错误检索出来,如果源案例与目标案例对应特征属性的属性值不同,系统将自动提高该属性的权重,否则系统将自动降低该属性的权重。
特征属性权重采用下式来确定每次调整幅度的大小:
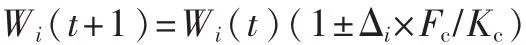
式中Wi表示权重,Fc表示一个案例被错误检索到的次数,Kc表示该案例被正确检索到的次数,当Kc增加时,Fc/Kc降低,使得W值变化的幅度越来越小,从而保证了权重不会无限地增加或减少。Δi表示每次调整的幅度,其值的大小可以根据实际需要调整。
1.2 基于遗传算法的权重向量调整法
基于遗传算法的权重向量调整[10]依据遗传算法自适应迭代寻优的思想,即从某一随机产生的或特定的初始群体出发,按照一定的操作规则,如选择、交叉、变异等,不断地迭代计算,并根据每一个个体的适应值,保留优良品种,淘汰次品,引导搜索过程向最优逼近。其是在领域专家指定初始权重的基础上对权重向量进行优化,使权重向量逐渐从不佳逼近最优。
在利用遗传算法调整权重向量时需要确定遗传参数设置、染色体编码、个体适应度评价以及遗传算子选择,实现较为复杂[11]。
1.3 基于时序的权重向量调整法
基于时序的权重向量调整[12]通过引入时间影响因子对案例的特征属性权重进行逐一调整。设一组时序相关序列 t1,t2,…,tn分别对应案例中 n个特征属性 p1,p2,…,pn,表示各特征属性对时间的敏感性(由领域专家指定),其中 ti∈[0,1],(i=1,2,…,n)。 ti=0 表示该特征属性值的变化与时间基本无关。随着特征属性值与时间相关性的增大,ti逐渐增大,最大为1。同时,定义时序调整系数 μ=η×ΔT,其中 ΔT为时间跨度,单位为年;η 为时间跨度系数,可取为1。
对于案例 C的第 i个属性权重调整为 Wi′=Wi×(1+ti×μ),其中 ti×μ 为时间影响因子,μ=η×ΔT,时间跨度 ΔT可由案例C与源案例S发生时间差值得到。为使同一案例中所有特征属性的权重之和仍为1,需要相应调整特征属性的权重:

以上这些调整方法基本都依赖于领域专家事先对特定问题给出一个经验参考权重向量,并在此基础上对其进行不断地重复累积调整,这种累积经验对于相似环境下的权重分配需求是有效的,但对于特殊环境下的权重分配需求就显得难以胜任。
2 基于CBR的特征属性权重选取与自修正方法
CBR核心思想是充分借鉴以往专家经验来指导新问题的求解[13-14]。在这种思想的启发下,对于特征属性权重的选取和调整问题,同样可以尝试用CBR的思想来解决。即将以往任何一次专家的属性权重分配经验作为案例存入历史权重库中,运用历史权重库中历史权重来指导目标权重的选取与调整。
根据事物发展的规律性和重现性,即相同或相似的问题具有相同或相似的解法,相同或相似的问题会重复发生,每一个权重分配案例都是某种特定需求环境下的成功经验记录,对将来类似问题具有重要的参考借鉴作用,同时历史权重分配经验直接以新案例的形式进行保存,避免了特定需求环境下的成功分配经验的二次修改难以适应原始需求环境。
历史权重库收集了以往各种不同需求的权重分配案例,积累了丰富的经验和知识,同时CBR具有自学习能力,随着权重库的不断积累,理想情况下将会覆盖到各种不同环境下的权重分配问题。因此,通过权重库来解决权重分配问题是可行的也是有效的,这样不仅能够满足相似环境下的权重分配需求,同时也可以处理特殊异常环境下的权重分配需求。
2.1 基于CBR的特征属性权重选取
参考 CBR 基本过程, 即 4R(Retrieve、Reuse、Revise、Retain)[13-14],基于CBR的特征属性权重自学习与调整策略可分为4个过程,如图 1所示。
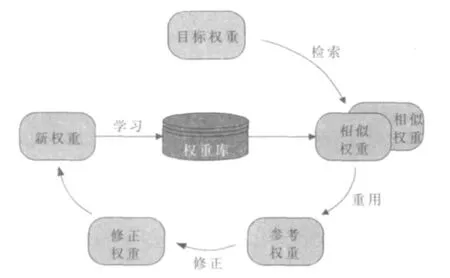
图1 基于CBR权重自学习与调整策略
(1)权重检索:根据目标权重和历史权重相似性度量标准,通过合适的检索匹配算法,从历史权重库中找出与目标权重最相似的权重。
(2)权重重用:将最相似的权重作为参考权重,指导目标权重的分配。
(3)权重修正:分析参考权重与目标权重间的差异部分,通过合适的权重修正策略,并结合实际情况,对参考权重加以调整与修正。
(4)权重学习:根据制定的学习策略,把新权重存储到权重库中。
基于CBR的特征属性权重选取思想的具体实现:
(1)结合领域应用背景,收集以往专家的特征属性权重分配经验,将其作为权重案例,存入历史权重库中以构建领域问题权重参考库;
(2)对于一个新的权重分配问题,制定局部权重相似性度量标准,选择合适的权重案例相似性检索算法,结合权重分配需求条件,对历史权重库进行相似性检索,找出相似度最高的历史权重,即为与目标权重最相似的权重;
(3)结合实际应用需要,采用合适的权重调整策略,对最相似权重进行修正,以适应新问题;
(4)将调整后的新权重存入历史权重库中以丰富权重库的经验,提高权重库解决问题的能力。
2.2 基于CBR的特征属性权重自修正
基于CBR相似性检索得到的参考权重,可能不完全适合于当前的权重分配需求,需要对其进行修正。一般特征属性权重修正规则和知识获取十分困难,而历史权重案例库中储备了丰富的实际经验和显性知识,同时也蕴含了大量的隐性知识,这些知识对于特征属性权重修正有一定的帮助。
基于CBR的特征属性权重自修正的基本思想是直接从权重案例库中得到权重修正知识。即首先从权重案例库中检索出与目标权重最相似的权重案例;通过比较目标权重和最相似的权重,得出存在差异的权重所对应的特征属性集合;根据这些差异特征属性集合对权重案例库进行聚类,得出一个新的权重案例库;最后从新的权重案例库中再次检索出和上次得到的最相似权重最接近的权重组合,将这个权重组合作为参考来指导当前的特征属性权重分配。
整个修正方法在权重修正过程中应用CBR思想,根据重用失败的原因,找到最终的解决方案,如图 2所示。整个属性权重修正过程不需要依赖领域知识。
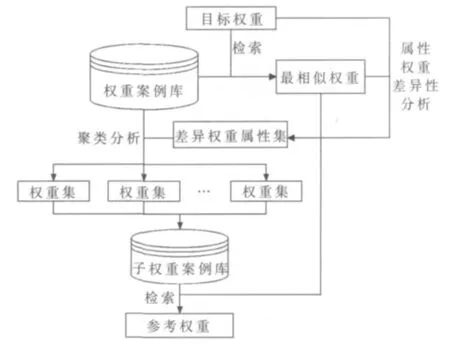
图2 基于CBR特征属性权重自修正
基于CBR的特征属性权重自修正算法描述如下:(1)假设权重案例库为 WC,目标权重为 A,先从权重案例库WC中检索出与A最相似的权重B。
(2)对A和 B进行特征属性权重差异性分析,找出两者之间的特征属性权重差异。假设A有m个特征属性,其中 i(0≤i≤m)个特征属性权重存在差异,如果 i=0,表示没有差异,算法结束。
(3)根据这些差异特征 D1,D2,…,Di对权重案例库进行聚类分析。即针对每一个差异特征,从权重案例库WC中找到和A中该特征属性的权重值相同的案例,将其聚成一类。这样可以得到分类 D1(C),D2(C),…,Di(C),其构成一个新权重案例库WCnew。
(4)从WCnew中检索出和B最相似的权重案例,并将其作为最佳权重分配参考方案。根据相似性的传递性原理,此权重案例不仅与目标权重A具有较高的相似性,同时兼顾了权重案例B中部分属性权重不能满足目标权重A分配的需求。
3 应用实例
本文提出的方法在突发性大气环境污染事故案例推理系统中进行了应用。突发性大气环境污染事故对事故现场环境依赖性特别强,不同环境背景下,各特征属性表现出来的重要程度存在很大的差异性。以往的固定属性权重难以满足特殊环境下属性权重分配的需要,而基于CBR的特征属性权重选取与自修正方法可以很好地解决不同环境条件下的特征属性权重分配需求。
在突发性环境污染事故案例推理系统中,对于特征属性权重的选取与调整的实现问题,首先收集以往权重分配经验并初步建立权重案例库;其次根据当前的环境条件,确定特征属性的重要程度,并给所关注特征属性分配一定的权重,对于非特别关注或重要程度难以确定的特征属性,其权重缺省为 0,即目标权重为 OC(0.2,-,-,0.15,0.15,0.15,-,-,0.2), 依据特征属性权重相似性检索算法,对权重库进行相似性检索。
基于指数法的单个特征属性权重相似度:
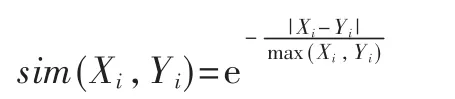
式中Xi、Yi分别表示案例特征属性 i的目标权重值和历史权重值。
基于简化K-NN法的整个权重向量相似度:

式中sim(OCXi,SCXi)表示对于案例特征属性 i目标权重和历史权重间的相似度,N为参与局部特征属性相似度计算的属性个数。
表1给出了目标权重与部分历史权重之间基于指数法和K-NN算法的相似性检索结果,其中历史权重案例6是与目标权重最相似的权重。
若历史权重案例6的权重分配满足当前权重分配的需要,直接将其作为目标权重分配问题的解决方案;若对历史权重案例6的权重分配结果不满意,则对其执行自修正操作。即对历史权重案例6的参考权重与目标权重进行差异性分析,得到差异属性集合{气象条件,应急措施},其对应的目标权重为{0.15,0.2};根据污染物质、应急决策两个特征属性的目标权重对权重库进行聚类分析,得到两个权重案例集{5,8}和{1,2,4,7},并构成一个新的子权重库{1,2,4,5,7,8};再次利用属性权重相似性检索算法,从子权重库中检索出与历史权重案例6中的参考权重最相似的权重,即为历史权重案例5,并将其作为当前目标权重分配问题的参考解决方案。
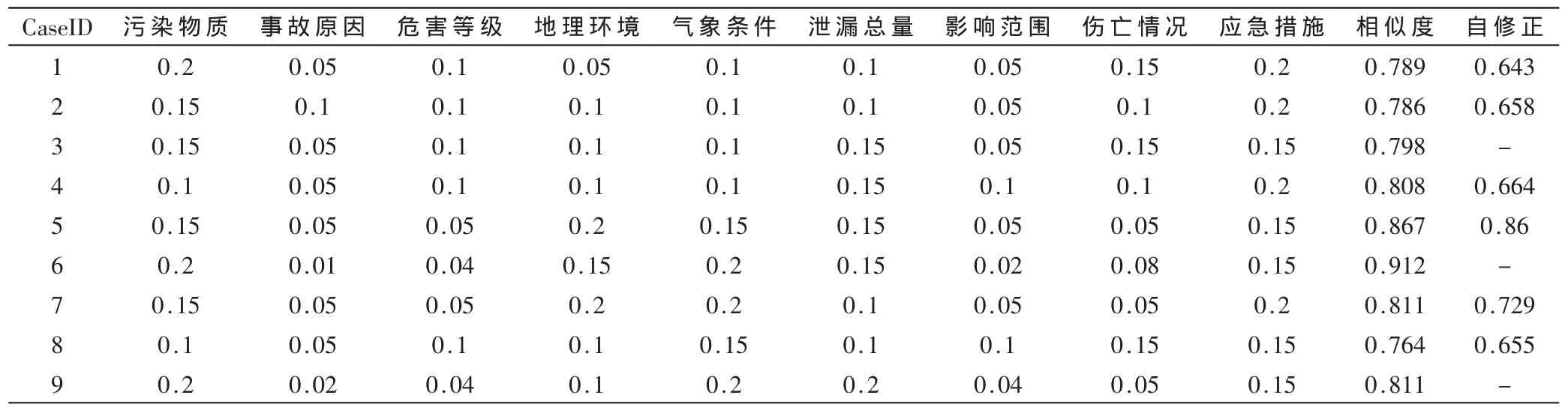
表1 特征属性权重相似性检索结果
依据相似性的传递性,历史权重案例5不仅与目标权重具有较高的相似性,同时弥补了历史权重案例6部分属性权重不能满足目标权重分配需求的不足。若对历史权重案例5不满意,可对其进行人工局部调整,并将调整结果存入到权重库中以备下次重用。
这样不仅解决了当前权重分配问题,同时也丰富了权重案例库的经验,扩大了权重案例库的覆盖面,增强了其解决问题的能力。
传统案例属性的静态权重已难以满足需要,而案例属性权重选取与动态调整是当前研究的一大难题,本文尝试借鉴CBR思想,提出了一种基于CBR的特征属性权重选取与自修正方法,为特征属性权重分配与调整提供了一种新的思路。基于CBR的特征属性权重选取与自修正方法直接援引以前积累的经验和知识来解决当前特征属性权重的选取与调整问题,具有操作实现简单、进行知识积累和重用等优点,特别适合特殊环境下复杂问题的特征属性权重选取与调整。
[1]LEAKE D B,KINLEY A,WILSON D.Learning to integrate multiple knowledge sources for case-based reasoning[C].Proceedings of the Fifteenth International Joint Conference on Artificial Intelligence,Morgan Kaufmann,San Francisco,1997:246-251.
[2]章曙光,蔡庆生.一种基于属性组合的权重向量选取模型[J].微机发展,2004,14(11):13-15.
[3]艾芳菊.基于实例推理系统中的权重分析[J].计算机应用,2005,25(5):1022-1025.
[4]AHA D W.The omnipresence of case-based reasoning in science and application[J].Knowledge-Based Systems,1998,11(5):261-273.
[5]SKALAK D B.Prototype and feature selection by sampling and random mutation hill climbing algorithms[C].Proceedings of the 1994 International Conference on Machine Learning,293-301.
[6]MOHRI T,TANAKA H.An optimal weighting criterion of case indexing for both numeric and symbolic attributes[C].AAAI Technical Report WS-94-01,Case-Based Reasoning:Papers from the 1994 Workshop.Menlo Park,CA:AAAI Press.
[7]LING C X,WANG H.Computing optimal attribute weight setting fot nearest neighbor algorithms[J].Artificial Intelligence Review,1997,11(1-5):255-272.
[8]SALZBERG S.A nearest hyperrectangle learning method[J].Machine Learning,1991(6):251-276.
[9]BONZANO A,CUNNINGHAM P,SMYTH B.Using introspective learning to improve retrieval in CBR:a case study in air traffic control[C].Proceedings of the 2nd International Conference on Case-Based Reasoning,Providence RI,USA:Springer,1997:291-302.
[10]SHIN K S,HAN I.Case-based reasoning supported by genetic algorithms for corporate bond rating[J].Expert Systems with Applications,1999(16):85-95.
[11]章曙光,汪淼,张永,等.一种基于遗传算法的权重向量选取模型[J].微机发展,2005,15(12):87-89.
[12]杨健,杨晓光,刘晓彬,等.一种基于K-NN的案例相似度权重调整算法[J].计算机工程与应用,2007,43(23):8-11.
[13]WATSON I,MARIR F.Case-based reasoning:a review[J].The knowledge engineering review,1994,9(4):327-354.
[14]CUNNINGHAM P,SMYTH B.Case-based reasoning in scheduling:reusing solution components[J].International Journal of Production Research,1997,35(11):2947-2962.
