基于知识图谱的国内外个性化推荐比较研究
2012-09-14武慧娟周兰萍
武慧娟,周兰萍,辛 跃
(东北电力大学经济管理学院,吉林 吉林 132012)
纵观国内外,针对个性化推荐研究的文献很多,本文借助Excel工具统计国内个性化推荐发展情况,借助Citespace科学知识图谱的方法,客观、科学的展示国外个性化推荐发展过程中的路线,追踪个性化推荐的研究热点,正确把握研究前沿,为进一步更好的对个性化推荐相关研究的开展提供理论意义和实践价值。
1 数据来源与研究方法
本文所引用的数据分为国外和国内两方面,国内数据来源于CNKI,通过主题词“个性化推荐”进行检索,结果为670条文献,对下载的数据进行清洗、过滤,最后得到666条文献;国外数据来源于美国科学情报研究所的科学引文索引扩展的Web of Science数据库,检索表达式为:主题词设为“personalized recommendation”,文献类型设为article,检索结果得到508条文献。检索时间均为2012年2月16日,由于2012年的数据不完整,所以国内和国外的2012年数据不作为研究内容。
本文采用定量与定性相结合的研究方法,利用Excel统计软件和Citespace[1]可视化软件进行统计分析,Citespace是美国德雷克塞尔大学陈超美团队开发的一款在科学文献中识别与可视化新趋势与新动态的Java应用程序,已成为信息分析领域中影响力较大的信息可视化软件。
2 国内外个性化推荐比较研究
2.1 发文量比较分析
将国内外的检索结果按年进行统计,可以发现国内国外对个性化推荐开始研究的时间不一样,国内开始于2001年,要晚于国外,而国外开始于1999。国内在2011年达到发文量最大148篇,同年,国外也达到最大93篇,研究热度都在不断升高,具体见表1所示。
由于表1中的数据不能够直观的显示国内外的发文量增长趋势,于是利用Excel绘制了图1,具体如图1所示。

图1 国内外发文量增长趋势比较
从图1可以看出,国内外发文量总体上呈上升趋势,国内从2001年开始,在2007年为55篇,2008年有所减少,发文量为51篇,然后2009年又呈上升趋势。国际从1999开始,在2004年达到小高峰49篇,然后有所下降,在2007年达到最低值33篇,然后又呈上升趋势。从总体发文量上看,国外为508,国内为666,国内较多,从每年的发文量上看,2006年为一个转折点,这年之前,国内落后于国外,这年以后,国内超越了国外,说明,经过学术徘徊期,国内的许多研究学者找到了个性化推荐研究的方向,进入研究的新轨道。
2.2 高被引文献比较分析
被引频次是反映期刊所发表论文被引用的情况,并直接反映期刊在科学发展和交流中所起的作用。其含义为:“指一定时期内,某种期刊上的文章被引用的绝对次数,也就是被引用的总次数”[2]。
(1)国内文献分析
将国内文献的检索结果按照被引频次排名,其中排前5位的文献见表2所示。

表2 国内个性化推荐被引频次前5名
(2)国外文献分析
将国外检索结果作为数据源输入Citespace中,其中time slicing设为1999-2012,years per slice设为1,表示按年进行时间切片;Term source选择title、abstract、Descriptors、identifiers 四个选项;Node type设为Cite Reference;选择适当的阀值,最后绘制的高被引文献知识图谱如图2所示,其中排名前5位的如表3所示。

表3 国外个性化推荐高被引文献
共被引频次最高文献的作者Marko B等提出引入基于内容和协作过滤两个算法,可以增强Fab推荐系统的各个方面[3]。排第二位和第三位的文献内容大致相同,都提出基于协作过滤的网络新闻开放式架构或应用,它主要利用其它人对同一类网络新闻的评价来更好的为某一用户进行信息过滤[4]。Adomavi-cius G等总结了目前现有的推荐模型:基于内容和基于协作过滤和混合三种,并提出为了改善推荐的性能,可以对现有的模型进行扩展,具体是增强对用户的理解、对推荐信息的前后关系进行整合、支持多层次的评定等级,以及形成更柔性化的推荐系统[5]。
对比国内外的共被引高频文献,可以发现,两者作为知识基础比较相似,都提出了基于内容、基于协作过滤和混合三种模式,不同的是:国内比较注重理论的研究:个性化技术、个性化推荐理论、推荐策略等;而国外更注重实践,针对目前应用问题,提出新模型。例如,David G的邮件推荐系统[6]。
2.3 研究热点比较分析
(1)国内文献分析
将检索到的666篇文献进行关键词统计分析,发现共有40个关键词,频次大于7的主题词如表4所示。由此可以看出,国内的研究热点集中在个性化推荐、协同过滤、电子商务、Web挖掘、关联规则等。

表4 国内个性化推荐高频次关键词表
(2)国外文献分析
将国外文献检索结果输入citespace中,将Node type设为Keyword,其他参数设置与图2绘制时相同,最后得到关键词共现图谱,其中关键词节点数为252,连线为522,具体如图3所示,排名前10位的关键词具体如表5所示。
对比国内外的关键词,两者基本相似,说明国内外对个性化推荐的研究有一定的共同方向,如国内外关于协同过滤都排第三,可见协同过滤是国内外共同高度关注的一个研究热点;但各自的研究侧重点可能不太相同,如国内在前14名的排名中,出现了关联规则、相似性、聚类、本体等关键词,国外都没有出现,但是国外前14名的排名中出现了信息过载、用户偏好等关键词,而国内没有出现,说明国内侧重于个性化推荐的技术的研究,或者将各种技术混合起来进行推荐,而国外侧重于考虑目前实际应用中遇到的信息过载、用户偏好等问题开展研究,经过实际调查、收集数据取得实证研究。

图3 国外个性化推荐关键词共现图谱

表5 国外个性化推荐高频次关键词
2.4 研究前沿分析
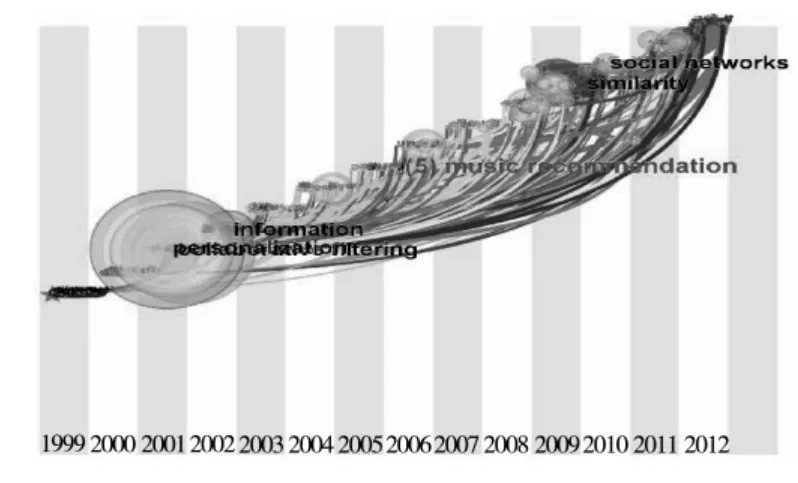
图4 国外个性化推荐关键词聚类时区图
为了确定国外个性化推荐的研究前沿,在高频关键词的基础之上,选用突变检测算法来检测关键词,同时选用timezone(时区图)聚类节点,其中红色的圆环表示突变率较高的关键词,点击相关节点就会出现标签,最后生成关键词聚类时区图,具体如图4所示。图4中的突变词主要有personal preference、social networks、similarity、accurate prediction、electronic program guide、computational cost等。其中,“personal preference”的国外频次为9,它的提出充分考虑个性化的偏好,提高了用户推荐信息的精准度,Chiu PoHuan等通过20000个实证用户,跟踪他们的浏览习惯和浏览历史,最后得出相关博客的点击率和在
某个感兴趣的博客上花费的时间是用户最关心的问题[7]。“social networks”的频次为5,基于社会化网络的推荐主要考虑了社会化群体的作用,以用户为中心,通过分析一个紧密联系的群体中个体之间的关系结构,考虑个体用户的偏好,从而为相互之间的信息传递提供基础,使得信息推荐更准确,更易于个体用户接受。Bonhard P等提出现有的基于协作等的信息推荐没有说明为何要推荐信息甲给用户甲,而不是推荐信息乙给用户甲,所提它提出以用户为中心,从社会网络的关系出发,告诉用户甲,他的朋友对信息甲的看法、行动[8]。
相比较之下,国内在2007年陆续开始了在信息推荐中用户偏好的研究,高琳琦针对新闻浏览者的偏好易变等特点,通过度量在线用户的点击和阅读行为,根据用户实际阅读的新闻,调整其关键字偏好,并采用模糊相似度来分析用户偏好结构与新闻结构的相似性,从而产生推荐[9]。国内于2006年陈君等的文献里开始了将社会网络应用在个性化信息推荐中研究,其中文献20中基于社会网络信息流模型,提出协同过滤算法SMRR,它综合考虑用户自身偏好和社会网络中其他成员的影响,使得SMRR的预测准确率明显高于原有算法[10]。
3 总 结
通过以上对国内外个性化推荐高被引文献、研究热点的对比分析和国外研究前沿的探索,可知对个性化推荐的研究国内开始于2001年,要晚于国外,而国外开始于1999,对比国内外的共被引高频文献,可以发现,两者作为知识基础比较相似,不同之处是国外更注重实践,针对目前应用问题,提出新模型;同时从国内外的关键词对比也可以发现,两者在协同过滤、电子商务、用户模型、数据挖掘等方面的研究基本相似,尤其是基于协同过滤模式的个性化推荐都引起了国内外学者们的密切关注,但各自的研究侧重点可能不太相同,国内侧重于关联规则、相似性、聚类、本体等方面的理论研究,而国外侧重于信息过载、用户偏好等实证研究;在研究前沿方面,通过我国于2006年开始社会化网络方面的研究等,但是与国外相比,缺乏实践与应用的研究,即缺乏对实际的个性化推荐过程中遇到的问题的分析与解决的研究。通过以上研究可以看出,要通过加强国内实际个性化推荐的应用研究,才能使各种理论和方法得以真正实现,真正解决各种各样用户所面临的问题,为我国的电子商务、企业、网民等推荐优质信息。
[1]Chen C.Citespace II.Detecting and visualizing emerging trendsand transient patterns in scientific literature[J].Journal of the American Society for Information Science and Tech-nology,2006,57(3):359 -377.
[2]钱荣贵.核心期刊与期刊评价[M].北京:中国传媒大学出版社,2006:14-14.
[3]Balabanovic M.,Shoham Y..Content-Based,Collaborative,Recommendation[J].Communicatiuns of the ACM.1997,40(3):66 -73.
[4]Konstan,J.,Miller,B.,Maltz,D.et al..GroupLens:Applying Collaborative Filtering to Usenet News[J].Communications of the ACM,1997,40(3):77 -87.
[5]Adomavicius,G.,Tuzhilin,A.,Carlson Sch..Toward the next generation of recommender systems:A survey of the state-of-the-art and possible extensions[J].Knowledge and Data Engineeri-ng,2005,17(6):734 -749.
[6]David Goldberg.Using Collaborative Filtering to Weave an Information Tapestry[J].Communi-cations of the ACM,1992,35(12):61 - 71.
[7]Chiu PoHuan,Kao Gloria Yi-Min,Lo ChiChun.Personalized blog content recommender system for mobile phone users[J].International Journal of Human Computer Studies,2010,68(8):496 -507.
[8]Bonhard P.;Sasse M.A.Knowing me,knowing you'using profiles and social networking to improve recommender systems[J].Bt Technology Journal,2006,24(3):84 -98.
[9]高琳琦.基于用户行为分析的自适应新闻推荐模型[J].图书情报工作,2007,51(6):77-80.
[10]万里,廖建新,王纯.基于社会网络信息流模型的协同过滤算法[J].吉林大学学报:工学版,2011,41(1):270-275.
